Netty专题源码剖析netty核心基础ByteBuf
Posted 饥饿小猪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netty专题源码剖析netty核心基础ByteBuf相关的知识,希望对你有一定的参考价值。
在面试的时候,当面试问到netty的时候问到:你知道jdk nio中的ByteBuffer与netty 中的ByteBuf有什么区别吗?来看看面试者的基础掌握的如何!你能准确回到出来个所以然吗?
说到jdk我先说说我身边使用jdk nio的情况;
我现在公司就有个游戏项目是jdk nio2一行一行实现的通讯架构,一直在线上运营,目前该架构单服承载最高的时候达到3000多人,没发现有什么性能瓶颈,当然人数可能还会继续增加,只要提高服务器配置,或者选择增加新的服务器去负载均衡;
我们都知道jdk nio臭名昭著的epoll bug,它会导致Selector空轮询,最终导致CPU 100%。官方声称在JDK1.6版本的update18修复了该问题;当然我没有遇到这个bug,希望后面也不要遇到(祈祷),而netty的设计就很自然的避免了这个问题;不用担心这个bug出现;
这篇文章就是由浅入深解读ByteBuf家族,从而彻底掌握ByteBuf各知识点。
一、先来比较下jdk nio中的ByteBuffer与netty 中的ByteBuf
JDK NIO 劣势:
1、ByteBuffer给开发者的第一感觉就是他的API太少了,程序员的很多需求都不能满足,只能自己去实现或者做一下封装;
2、ByteBuffer 长度固定,不能动态收缩拓展,如果存很长的数据时候,就容易越界报错,例如:
3、ByteBuffer 读写操作的时候只有一个索引,操作起来flip(),rewind(),让人蛋疼,小白操作很容易混乱,这一点Mina IoBuffer和ByteBuffer同病相怜;
相反netty 的ByteBuf解决上面的所有的痛点;丰富的API,支持动态收缩拓展,并且读写索引分开,不用操作字节的时候,那么蛋疼;
二、ByteBuf实现原理以及如何使用
Netty ByteBuf提供了2个指针变量分别用于顺序读取,和顺序写入,readerIndex是读索引,writerIndex是写索引,二者划分ByteBuf缓冲区关系:
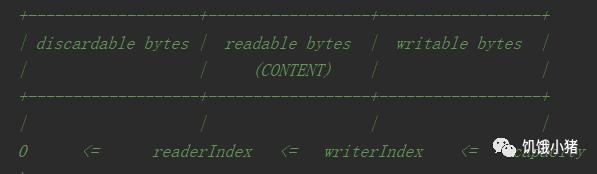
capacity:
缓冲区的容量。
readerIndex:
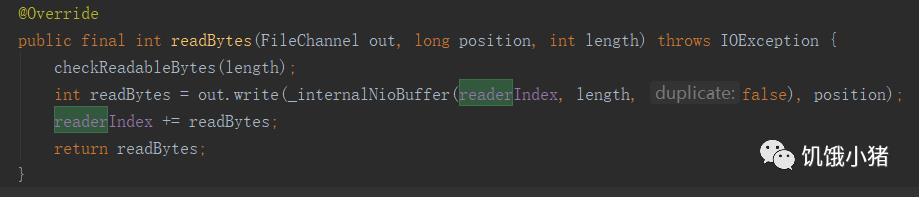
读取字节,改变readerIndex位置,或者下面的方法去初始化readerIndex
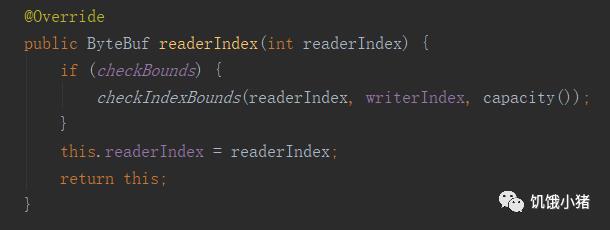
设置当前读的位置。可以使用readerIndex()和readerIndex(int)方法获取、设置readerIndex值。每次调用readXXX方法都会导致readerIndex向writerIndex移动,直到等于writerIndex为止。
writerIndex:
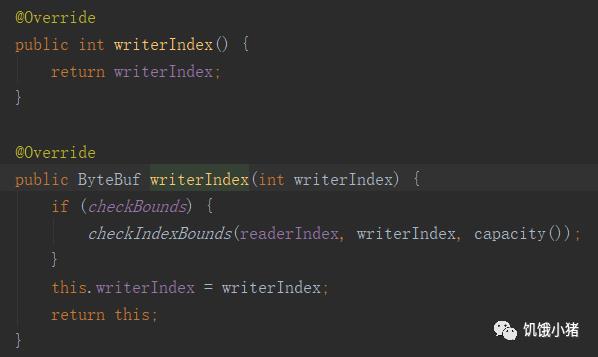
设置写的当前位置。可以使用writerIndex()和writerIndex(int)方法获取、设置writeIndex的值。每次调用writeXXX方法都会导致writeIndex向capacity移动,直到等于capacity为止。
discardable bytes:
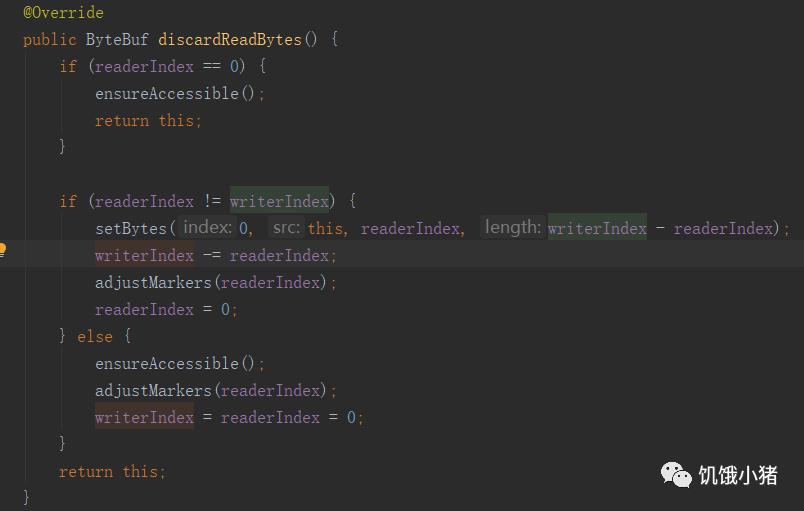
表示读取之后丢弃,节约空间资源。0--readerIndex之间的数据, 长度是readerIndex - 0,调用discardReadBytes会丢弃这部分数据,把readerIndex--writerIndex之间的数据移动到ByteBuf的开始位置(0);
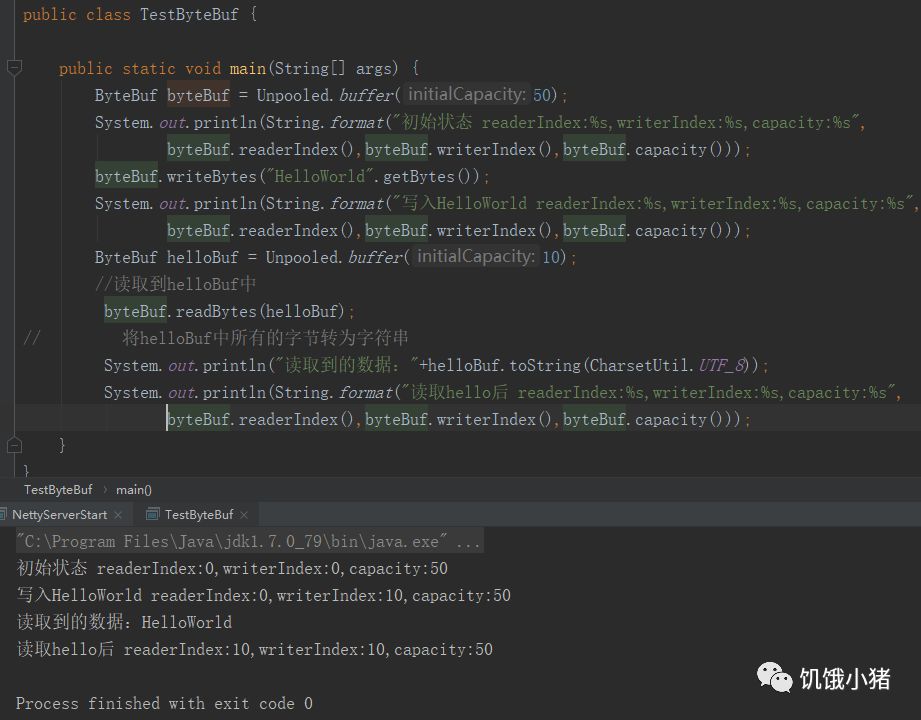
使用案例展示:
三、ByteBuf缓冲分类
1、Heap buffer(堆缓冲区):
就是将数据存在JVM堆空间中,在没有被池化的情况可以快速分配和释放。
优点:由于数据是存储在JVM堆中,因此可以快速的创建与快速的释放,并且它提供了直接访问内部字节数组的方法。
缺点:每次读写数据时,都需要先将数据复制到直接缓冲区中再进行网路传输。
2、Direct buffer(直接缓冲区):
直接缓冲区,在堆外直接分配内存空间,直接缓冲区并不会占用堆的容量空间,因为它是由操作系统在本地内存进行的数据分配。
优点:在使用Socket进行数据传递时,性能非常好,因为数据直接位于操作系统的本地内存中,所以不需要从JVM将数据复制到直接缓冲区中 。
缺点:因为Direct Buffer是直接在操作系统内存中的,所以内存空间的分配与释放要比堆空间更加复杂,而且速度要慢一些。
注意:
如果你的数据包含在一个在堆上的分配的缓冲区中,那么事实上,在通过套接字发送他之前,jvm将会在内部把你的缓冲区复制到一个直接缓冲区中;这样分配释放就比较浪费资源;
建议:
直接缓冲区并不支持通过字节数组的方式来访问数据。对于后端业务的消息编解码来说,推荐使用HeapByteBuf;对于I/O通信线程在读写缓冲区时,推荐使用DirectByteBuf;
3、Composite Buffer 复合缓冲区:
可以拥有以上两种的缓冲区,通过一种聚合视图来操作底层持有的多种类型Buffer。这种缓冲,jdk nio是没有这种特性的。
四、源码解读ByteBuf家族
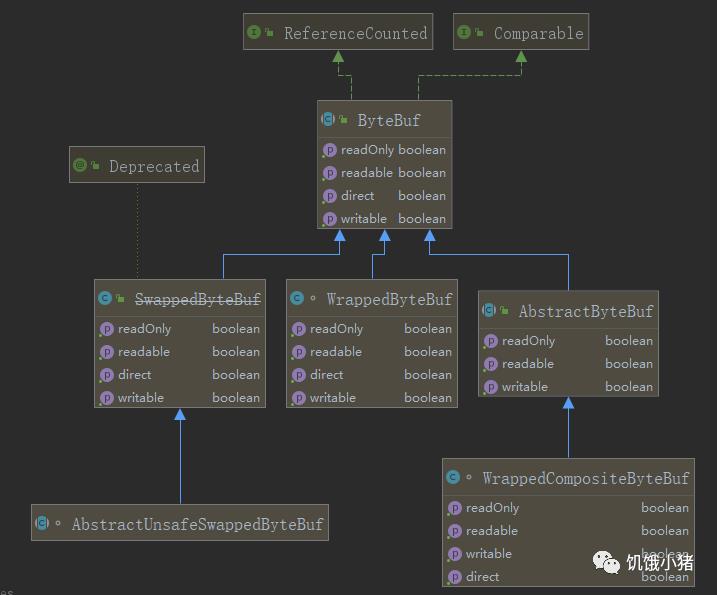
先看下ByteBuf的接口和他的三个不同方向的实现抽象类,下面还有具体实现类后面再具体列出来讲解,先介绍下这几个ByteBuf的顶级接口和抽象父类:
(Deprecated 的SwappedByteBuf官方已经不赞成去使用了,是不安全缓冲接口)
1、ReferenceCounted:引用计数器接口。
Netty 4开始,对象的生命周期由它们的引用计数(reference counts)管理,而不是由垃圾收集器(garbage collector)管理了。ByteBuf是最值得注意的,它使用了引用计数来改进分配内存和释放内存的性能。ByteBuf利用引用计数来改进分配和回收性能;
只要引用计数大于 0,就能保证对象不会被释放。当活动引用的数量减少到0 时,该实例就会被释放;是由最后访问(引用计数)对象的那一方来负责将它释放。
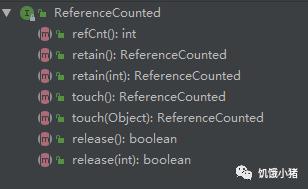
(1)、如果一个对象实现了ReferenceCounted接口,被初始化的时候,计数为1。
(2)、retain()方法能够增加计数,release() 方法能够减少计数,如果计数被减少到0则对象会被显示回收,再次访问被回收的这些对象将会抛出异常。
(3)、如果一个对象实现了ReferenceCounted,并且包含有其他对象也实现来ReferenceCounted,当这个对象计数为0被回收的时候,所包含的对象同样会通过release()释放掉。
2、Comparable:排序接口。
ByteBuf:定义了一下是否可读写的属性以及定义了一些读写操作的抽象接口,供子类继承实现。
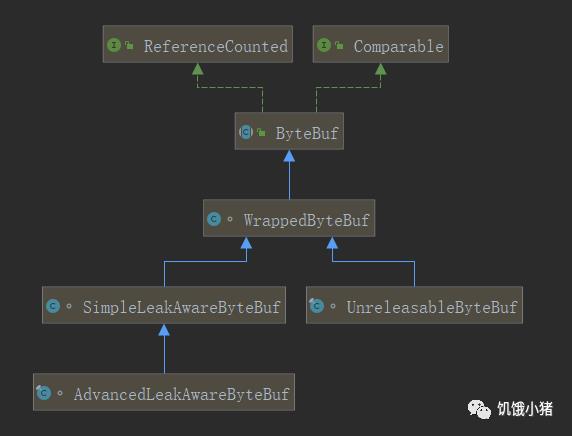
3、WrappedByteBuf:用于装饰ByteBuf对象,主要有AdvancedLeakAwareByteBuf、SimpleLeakAwareByteBuf和UnreleasableByteBuf三个子类。
(1)、WrappedByteBuf使用装饰者模式装饰ByteBuf对象
(2)、AdvancedLeakAwareByteBuf用于对所有操作记录堆栈信息,方便监控内存泄漏;
(3)、SimpleLeakAwareByteBuf只记录order(ByteOrder endianness)的堆栈信息;
(4)、UnreleasableByteBuf用于阻止修改对象引用计数器refCnt的值。
4、AbstractByteBuf: 抽象继承ByteBuf, 是ByteBuf缓冲的默认实现接口.
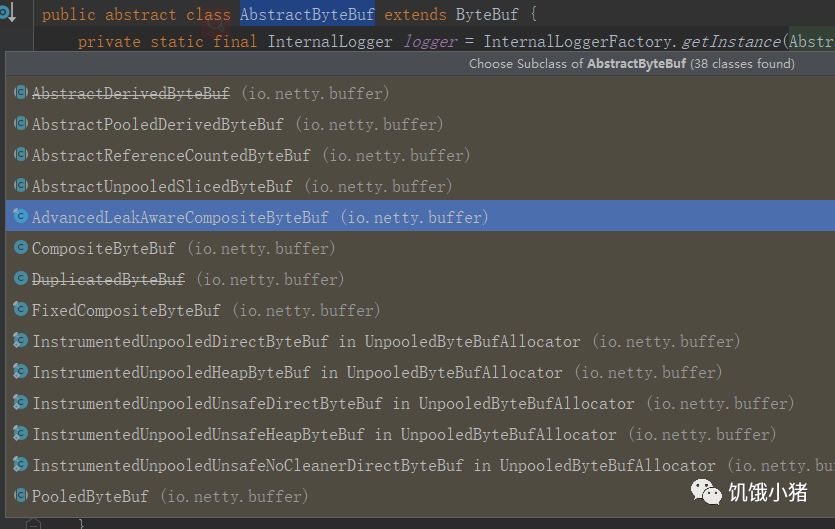
子类很多,我们上面说的三种缓冲策略的类实现都是最终继承实现AbstracByteBuf,而AbstractByteBuf本身并没有具体去对不同ByteBuf缓冲区去做具体实现,而是由子类去实现,原因很简单父类不知道子类去实现堆内存还是直接内存,还是复合缓冲区;只是提供一个抽象接口而已;
再看看AbstractByteBuf源码中属性:
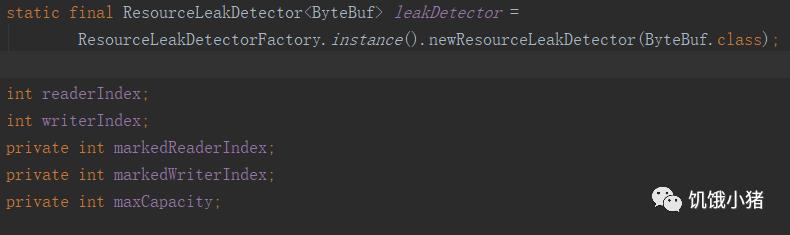
定义了读,写索引和读写索引的标记,以及最大容量,leakDetectro:是监测内存是否泄漏,是static类型,说明是共享公共的对象;
AbstractByteBuf直接子类 AbstractDerivedByteBuf:提供派生ByteBuf的默认实现,主要有DuplicatedByteBuf、ReadOnlyByteBuf和SlicedByteBuf。
(1)、DuplicatedByteBuf:使用装饰者模式创建ByteBuf的复制对象,使得复制后的对象与原对象共享缓冲区的内容,但是独立维护自己的readerIndex和writerIndex。
(2)、ReadOnlyByteBuf:使用装饰者模式创建ByteBuf的只读对象,该只读对象与原对象共享缓冲区的内容,但是独立维护自己的readerIndex和writerIndex,之后所有的写操作都被限制;
(3)、SlicedByteBuf:使用装饰者模式创建ByteBuf的一个子区域ByteBuf对象,返回的ByteBuf对象与当前ByteBuf对象共享缓冲区的内容,但是维护自己独立的readerIndex和writerIndex,允许写操作。
(4)、其实还可以按照另外一个维度去理解,一个是池化的ByteBuf一个是非池化的ByteBuf(用完就销毁);即PooledByteBuf_ 和UnpooledByteBuf_;
以上三种缓冲官方已经Deprecated不推介使用;
这也不推介使用那也不推介使用,那我们用哪些类去操作缓冲呢?
我们用AbstractByteBuf直接子类AbstractReferenceCountedByteBuf,该抽象类的子类实现的缓冲类;
上面我们看到很多实现类,而且没有一个被Deprecated的;这里只重点介绍几个常用的;
(1)、UnpooledDirectByteBuf:
在堆外进行内存分配的非内存池ByteBuf,内部持有ByteBuffer对象,相关操作委托给ByteBuffer实现。
(2)、UnpooledHeapByteBuf:
基于堆内存分配非内存池ByteBuf,即内部持有byte数组。
(3)、UnpooledUnsafeDirectByteBuf:
和另外一个类UnpooledDirectByteBuf差不多相同,区别在于UnpooledUnsafeDirectByteBuf内部使用基于PlatformDependent相关操作实现ByteBuf,依赖平台。
(4)、ReadOnlyByteBufferBuf:
只读ByteBuf,内部持有ByteBuffer对象,相关操作委托给ByteBuffer实现,该ByteBuf限内部使用;
(5)、FixedCompositeByteBuf:
用于将多个ByteBuf组合在一起,形成一个虚拟的只读ByteBuf对象,不允许写入和动态扩展。内部使用Object[]将多个ByteBuf组合在一起,一旦FixedCompositeByteBuf对象构建完成,则不会被更改。
(6)、CompositeByteBuf:
用于将多个ByteBuf组合在一起,形成一个虚拟的ByteBuf对象,支持读写和动态扩展。内部使用List<Component>组合多个ByteBuf。一般使用使用ByteBufAllocator的compositeBuffer()方法,Unpooled的工厂方法compositeBuffer()或wrappedBuffer(ByteBuf... buffers)创建CompositeByteBuf对象。
(7)、PooledByteBuf<T>:
基于内存池的ByteBuf,主要为了重用ByteBuf对象,提升内存的使用效率;适用于高负载,高并发的应用中。主要有PooledDirectByteBuf,PooledHeapByteBuf,PooledUnsafeDirectByteBuf三个子类,PooledDirectByteBuf是在堆外进行内存分配的内存池ByteBuf,PooledHeapByteBuf是基于堆内存分配内存池ByteBuf,PooledUnsafeDirectByteBuf也是在堆外进行内存分配的内存池ByteBuf,区别在于PooledUnsafeDirectByteBuf内部使用基于PlatformDependent相关操作实现ByteBuf,具有平台相关性。
就到这里了,感谢读者认真读完;差不多就netty的ByteBuf家族有了初步的了解了,后面博客我会对三种缓冲(直接缓冲,复合缓冲,堆缓冲)进行具体源码剖析,和大家一起学习一起探讨;如有些的不对的地方,请积极指出,以便及时纠正。
以上是关于Netty专题源码剖析netty核心基础ByteBuf的主要内容,如果未能解决你的问题,请参考以下文章
Day477&478&479.Netty核心源码 -netty