EventLoop在浏览器和node中的区别
Posted 厚朴HOPE工作室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EventLoop在浏览器和node中的区别相关的知识,希望对你有一定的参考价值。
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到javascript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
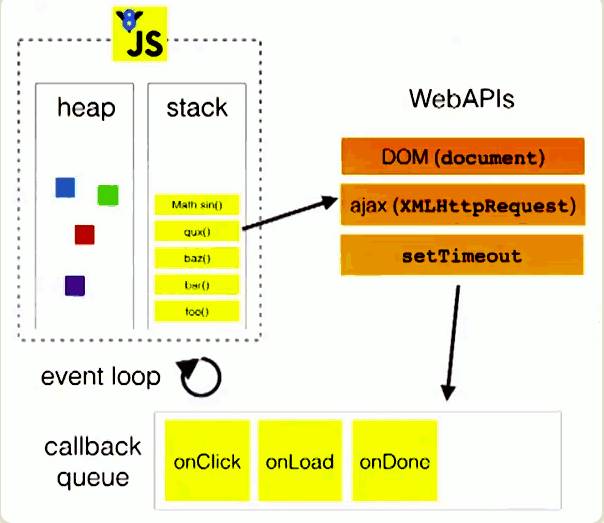
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
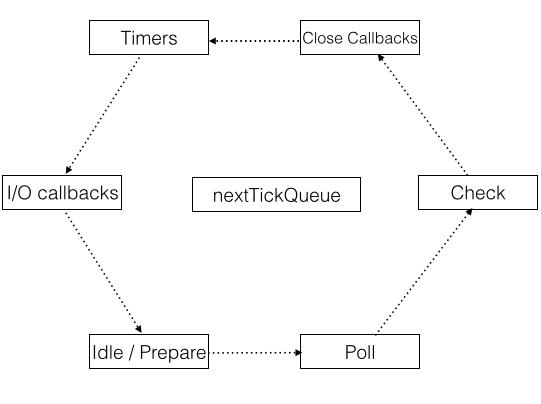
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到JavaScript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到JavaScript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到JavaScript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到JavaScript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到JavaScript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到JavaScript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
最近在学习node,看了一些关于node的eventLoop的文章之后得出自己的一些结论,跟大家分享一下,如果有错误的地方,也希望大家指出,多多指教!
说到JavaScript的异步,绕不开的就是EventLoop,这是JavaScript实现异步的基础,而浏览器端的EventLoop和node的又有很大的不同,下面,就让我们来探讨一下他们之间的区别。
浏览器EventLoop
异步
浏览器端的异步主要包含下面几个方面:
setTimeout
setInterval
事件
Ajax
基本模型
上面的很好的解释了浏览器端的异步是如何实现的,下面先看一个代码片段来理解一下:
(function() {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
//输出结果
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
我们都知道JavaScript是单线程的,但是这个单线程的意思是执行代码是单线程的,这个单线程就是上图的stack,所有的同步代码都是在这里执行的。而异步操纵只会在同步操作执行完之后才会开始执行。上面这段代码的执行经历下面这些过程:
代码从上往下执行,先打印出“this is a msg from call back ”,
解析到第一个setTimeout,而且这个setTimeout没有给出具体的时间参数,那么此时就会默认时间参数是0(需要注意的是0代表立即将setTimeout的回调函数加入到事件队列中,而是由一定的最小时间限制的),在经过最小时间限制后,就会将setTimeout的回调函数加入到事件队列中。
另外一个同步操作,打印出“this is just a message”
接下来是另外一个setTimeout的回调函数被加入到事件队列中,最后的同步操作打印出“this is the end”。
stack按照加入callbackQueue的回调函数的顺序从callbackQueue中拿出回调函数执行,首先是打印"this is a msg from call back",然后是打印"this is a msg from call back1"
这就是浏览器端的EventLoop的整个执行过程,这个过程相对来说还是比较简单易懂的。
node的EventLoop
基本模型
我们可以看到,node的EventLoop的模型要比浏览器端的复杂很多,下面让我们来一步步进行讲解。
phase
上图中的每一个矩形代表的是事件队列的每一个阶段(官网上叫“phase”),他们具体负责的工作为:
Timers:执行setTimeout()和setInterval()绑定的回调函数
I/O callback:执行除了close callbacks、timers以及setImmediate()绑定的回调函数
idle,prepare:只在内部使用
poll:检索新的I/O 事件,并且这个node在适当的时机在这个地方阻塞
check:执行setImmediate()绑定的回调函数
close callbacks:执行关闭事件绑定的回调函数
每个phase代表不同的时期,eventLoop每次轮询都会从timers开始将EventLoop里面的回调函数推导主线程中执行,直到执行完这个phase里面的回调函数或者是执行的数量达到允许的最大值(在每个循环周期中允许执行的函数数目是有限的)后才会进入到下一个phase,按照这样的顺序直到这个周期结束后再进入下个周期。当然,这里面还有很多细节,待会会详细讨论。
这里就可以看出node的EventLoop和浏览器端的EventLoop的很大的不同:浏览器端没有阶段的区分,只会按照回调函数进入事件队列的顺序进行执行,node则会按照不同类型的回调函数在不同阶段有区别地执行。
timers
setTimeout()和setInterval实际上和浏览器端的作用原理是一样的,在指定的时间后将绑定的回调函数添加到事件队列中,而且,当事件设置为0时,也不是立即就将回调函数添加到事件队列的timers中,下面这段是引用官网的说明:
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
下面看看官网的这个例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
让我们来分析一下上面这段代码的是如何执行的:
代码从上向下解析,遇到第一个异步操作-setTimeout,于是将在100ms后将setTimeout绑定的函数添加到timers中
继续向下解析,执行函数someAsyncOperation,函数someAsyncOperation首先读取文件,这个过程花费了95ms
由于在执行执行同步代码的时候没有回调函数添加到事件队列中,所以在进入poll阶段时事件队列还是空的,此时poll会等待到有新的事件被触发。
在文件读取结束后将其绑定的回调函数添加到事件队列中,poll将回调函数推到主线程里面执行,由于这个函数要执行10ms,在执行到5ms时setTimeout绑定的回调函数会被添加到timers中去
等到fs.read()绑定的函数执行完毕后poll检测到timers中有绑定的函数,而且check和close callback,就会进入下个阶段,由于下两个阶段(check和close callback)都没有绑定函数,那么就会重新回到timers,此时timers中有函数就推进主线程中执行,所以,最后输出的结果是延迟了105ms
但是,现在有一个问题,如果fs.read()要执行很长时间,那岂不是导致阻塞了吗?答案是:否;
timers其实是受到poll影响的,如果fs.read()执行的时间太长,超过了timers设定的时间,EventLoop会将timers绑定的函数推到主线程中执行(下面讲解poll的时候会解释),这样避免了阻塞问题
poll
首先,上面的这段话说明了poll具有两个功能:
执行那些时间到达的计时器绑定的函数
处理轮询队列中的事件
也就是说通过setTimeout绑定的回调函数有可能会在两个阶段被推到主线程中执行:timers和poll(下面会给出例子解释),但是timers绑定的函数能够在poll阶段被执行的条件是:计时器计时结束(下面会有例子解释)
poll的这个阶段回调函数执行还分多种情况:
当事件队列进入poll阶段,同时没有计时器计时结束时,如果poll不是空的,那么就先执行poll里面的回调函数。如果poll是空的同时没有setimmedaite绑定的回调函数,那么EventLoop会直接停留在poll阶段,直到有新的回调函数被加入到事件队列中。如果有setImmediate绑定的函数,则会进入到下个阶段check。
如果事件队列进入到poll阶段并且poll是空的,且有计时器计时结束,事件队列会回到timers,然后执行timers绑定的函数
下面看一个例子:
function foo(){
for (var i = 0; i < 10e7; i++) {
}
setTimeout(function(){
console.log("setTimeout");
},0);
for (var i = 0; i < 10e7; i++) {
}
setImmediate(function(){
console.log("setImmediate");
});
}
foo();
//setTimeout
//setTimmediate
先看上面这个例子,前面一个for循环之后,EventLoop已经到达poll阶段,这个时候poll是空的,而且此时还没有setImmediate绑定的函数,等到第一个for循环结束,进入第二个for循环,在执行for循环期间setTimeout计时器计时结束,EvenLoop重新回到timers,等到第二个for循环结束后事件队列将setTimeout的绑定的函数推进主线程执行,然后进入check阶段,执行setImmediate绑定的函数。
大概的内容就这样,如果大家有什么觉得不对的地方,欢迎提出来一起讨论么谢谢!
参考文章:
setImmediate() vs nextTick() vs setTimeout(fn,0) – in depth explanation
The Node.js Event Loop, Timers, and process.nextTick()
以上是关于EventLoop在浏览器和node中的区别的主要内容,如果未能解决你的问题,请参考以下文章