必看!超详细的SpringCloud底层原理
Posted java1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了必看!超详细的SpringCloud底层原理相关的知识,希望对你有一定的参考价值。
优质文章,第一时间送达
作者 | 止戈(Frank)
来源 | urlify.cn/QrmAr2
SpringCloud框架
针对这个架构图我分层介绍一下:
1、是web服务器的选型,这个我选择的是nginx+keepalived,haproxy也是一个选择,但是haproxy在反向代理处理跨域访问的时候问题很多。所以我们nginx有些地方做了keep-alive模式处理,减少了三次握手的次数,提高了连接效率。keepalived做nginx的负载,虚拟一个vip对外,两个nginx做高可用,nginx本身反向代理zuul集群。
2、api gateway,这里的zuul很多人诟病,说是速度慢推荐直接用nginx,这里我还是推荐使用zuul的,毕竟zuul含有拦截器和反向代理,在权限管理、单点登录、用户认证时候还是很有用的,而且zuul自带ribbon负载均衡,如果你直接用nginx,还需要单独做一个feign或者ribbon层,用来做业务集群的负载层,毕竟直接把接口暴露给web服务器太危险了。这里zuul带有ribbon负载均衡和hystrix断路器,直接反向代理serviceId就可以代理整个集群了。
3、业务集群,这一层我有些项目是分两层的,就是上面加了一个负载层,下面是从service开始的,底层只是单纯的接口,controller是单独一层由feign实现,然后内部不同业务服务接口互调,直接调用controller层,只能说效果一般,多了一次tcp连接。所以我推荐合并起来,因为做过spring cloud项目的都知道,feign是含有ribbon的,而zuul也含有ribbon,这样的话zuul调用服务集群,和服务集群间接口的互调都是高可用的,保证了通讯的稳定性。Hystrix还是要有的,没有断路器很难实现服务降级,会出现大量请求发送到不可用的节点。当然service是可以改造的,如果改造成rpc方式,那服务之间互调又是另外一种情况了,那就要做成负载池和接口服务池的形式了,负载池调用接口池,接口池互相rpc调用,feign client只是通过实现接口达到了仿rpc的形式,不过速度表现还是不错的。
4、redis缓存池,这个用来做session共享,分布式系统session共享是一个大问题。同时呢,redis做二级缓存对降低整个服务的响应时间,并且减少数据库的访问次数是很有帮助的。当然redis cluster还是redis sentinel自己选择。
5、eurake注册中心这个高可用集群,这里有很多细节,比如多久刷新列表一次,多久监测心跳什么的,都很重要。
6、spring admin,这个是很推荐的,这个功能很强大,可以集成turbine断路器监控器,而且可以定义所有类的log等级,不用单独去配置,还可以查看本地log日志文件,监控不同服务的机器参数及性能,非常强大。它加上elk动态日志收集系统,对于项目运维非常方便。
7、zipkin,这个有两种方式,直接用它自己的功能界面查看方式,或者用stream流的方式,由elk动态日志系统收集。但是我必须要说,这个对系统的性能损害非常大,因为链路追踪的时候会造成响应等待,而且等待时间非常长接近1秒,这在生产环境是不能忍受的,所以生产环境最好关掉,有问题调试的时候再打开。
8、消息队列,这个必须的,分布式系统不可能所有场景都满足强一致性,这里只能由消息队列来作为缓冲,这里我用的是Kafka。
9、分布式事物,我认为这是分布式最困难的,因为不同的业务集群都对应自己的数据库,互相数据库不是互通的,互相服务调用只能是相互接口,有些甚至是异地的,这样造成的结果就是网络延迟造成的请求等待,网络抖动造成的数据丢失,这些都是很可怕的问题,所以必须要处理分布式事物。我推荐的是利用消息队列,采取二阶段提交协议配合事物补偿机制,具体的实现需要结合业务,这里篇幅有限就不展开说了。
10、config配置中心,这是很有必要的,因为服务太多配置文件太多,没有这个很难运维。这个一般利用消息队列建立一个spring cloud bus,由git存储配置文件,利用bus总线动态更新配置文件信息。
11、实时分布式日志系统,logstash收集本地的log文件流,传输给elasticsearch,logstash有两种方式,1、是每一台机器启动一个logstash服务,读取本地的日志文件,生成流传给elasticsearch。2、logback引入logstash包,然后直接生产json流传给一个中心的logstash服务器,它再传给elasticsearch。elasticsearch再将流传给kibana,动态查看日志,甚至zipkin的流也可以直接传给elasticsearch。这个配合spring admin,一个查看动态日志,一个查看本地日志,同时还能远程管理不同类的日志级别,对集成和运维非常有利。
最后要说说,spring cloud的很多东西都比较精确,比如断路器触发时间、事物补偿时间、http响应时间等,这些都需要好好的设计,而且可以优化的点非常多。比如:http通讯可以使用okhttp,jvm优化,nio模式,数据连接池等等,都可以很大的提高性能。
还有一个docker问题,很多人说不用docker就不算微服务。其实我个人意见,spring cloud本身就是微服务的,只需要jdk环境即可。编写dockerfile也无非是集成jdk、添加jar包、执行jar而已,或者用docker compose,将多个不同服务的image组合run成容器而已。但是带来的问题很多,比如通讯问题、服务器性能损耗问题、容器进程崩溃问题,当然如果你有一套成熟的基于k8s的容器管理平台,这个是没问题的,如果没有可能就要斟酌了。而spring cloud本身就是微服务分布式的架构,所以个人还是推荐直接机器部署的,当然好的DevOps工具将会方便很多。
引言
面试中面试官喜欢问组件的实现原理,尤其是常用技术,我们平时使用了SpringCloud还需要了解它的实现原理,这样不仅起到举一反三的作用,还能帮助轻松应对各种问题及有针对的进行扩展。
以下是《Java深入微服务原理改造房产销售平台》课程讲到的部分原理附图,现在免费开放给大家,让大家轻松应对原理面试题。
服务注册发现组件Eureka工作原理
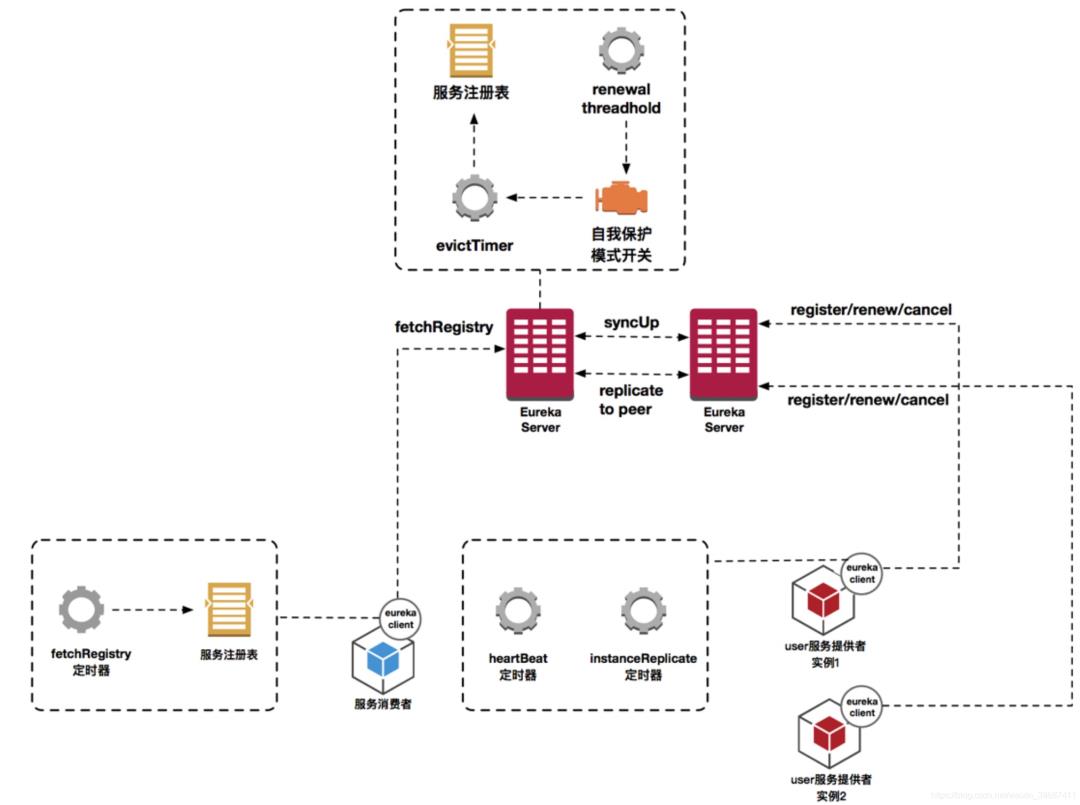
1、Eureka 简介:
Eureka 是 Netflix 出品的用于实现服务注册和发现的工具。Spring Cloud 集成了 Eureka,并提供了开箱即用的支持。其中, Eureka 又可细分为 Eureka Server 和 Eureka Client。
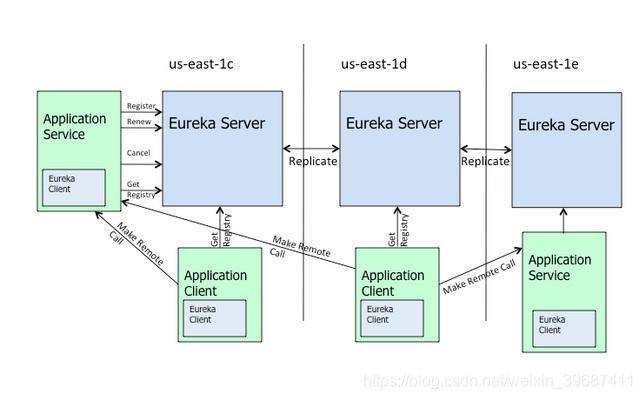
1.基本原理
上图是来自eureka的官方架构图,这是基于集群配置的eureka;
处于不同节点的eureka通过Replicate进行数据同步
Application Service为服务提供者
Application Client为服务消费者
Make Remote Call完成一次服务调用
当服务注册中心Eureka Server检测到服务提供者因为宕机、网络原因不可用时,则在服务注册中心将服务置为DOWN状态,并把当前服务提供者状态向订阅者发布,订阅过的服务消费者更新本地缓存。
服务提供者在启动后,周期性(默认30秒)向Eureka Server发送心跳,以证明当前服务是可用状态。Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,则认为服务宕机,注销该实例。
2.Eureka的自我保护机制
在默认配置中,Eureka Server在默认90s没有得到客户端的心跳,则注销该实例,但是往往因为微服务跨进程调用,网络通信往往会面临着各种问题,比如微服务状态正常,但是因为网络分区故障时,Eureka Server注销服务实例则会让大部分微服务不可用,这很危险,因为服务明明没有问题。
为了解决这个问题,Eureka 有自我保护机制,通过在Eureka Server配置如下参数,可启动保护机制
eureka.server.enable-self-preservation=true
它的原理是,当Eureka Server节点在短时间内丢失过多的客户端时(可能发送了网络故障),那么这个节点将进入自我保护模式,不再注销任何微服务,当网络故障回复后,该节点会自动退出自我保护模式。
自我保护模式的架构哲学是宁可放过一个,决不可错杀一千
作为服务注册中心,Eureka比Zookeeper好在哪里
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。在此Zookeeper保证的是CP, 而Eureka则是AP。
3.1 Zookeeper保证CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
3.2 Eureka保证AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
总结
Eureka作为单纯的服务注册中心来说要比zookeeper更加“专业”,因为注册服务更重要的是可用性,我们可以接受短期内达不到一致性的状况。不过Eureka目前1.X版本的实现是基于servlet的Java web应用,它的极限性能肯定会受到影响。期待正在开发之中的2.X版本能够从servlet中独立出来成为单独可部署执行的服务。
服务网关组件Zuul工作原理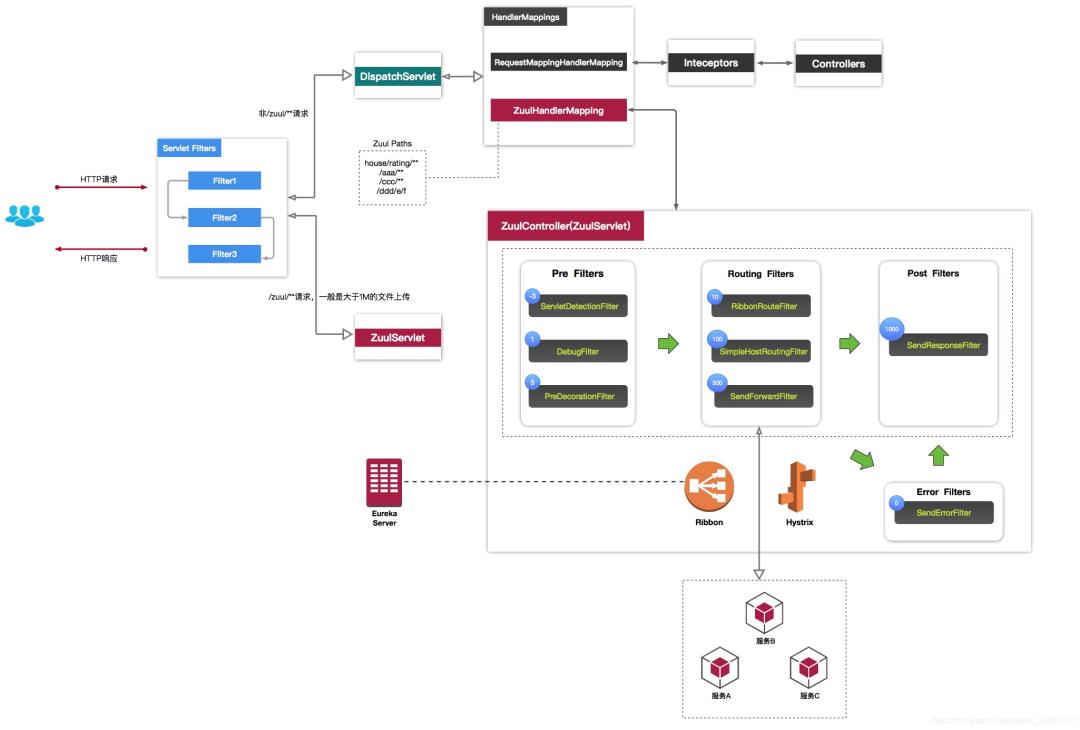
一、zuul是什么
zuul 是netflix开源的一个API Gateway 服务器, 本质上是一个web servlet应用。
Zuul 在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架。Zuul 相当于是设备和 Netflix 流应用的 Web 网站后端所有请求的前门。
zuul的例子可以参考 netflix 在github上的 simple webapp,可以按照netflix 在github wiki 上文档说明来进行使用。
二、zuul的工作原理
1、过滤器机制
zuul的核心是一系列的filters, 其作用可以类比Servlet框架的Filter,或者AOP。
zuul把Request route到 用户处理逻辑 的过程中,这些filter参与一些过滤处理,比如Authentication,Load Shedding等。
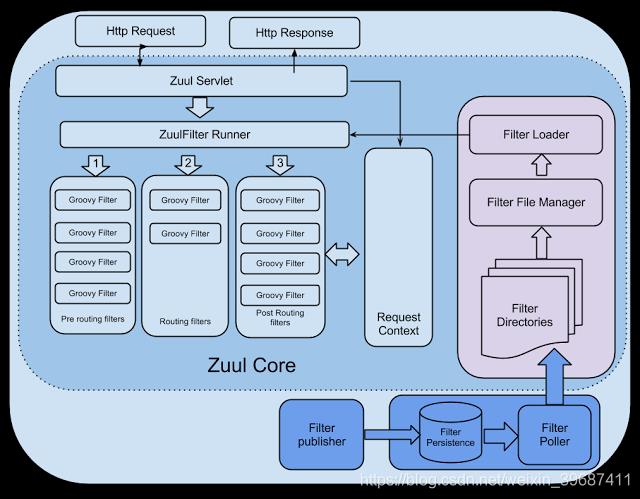
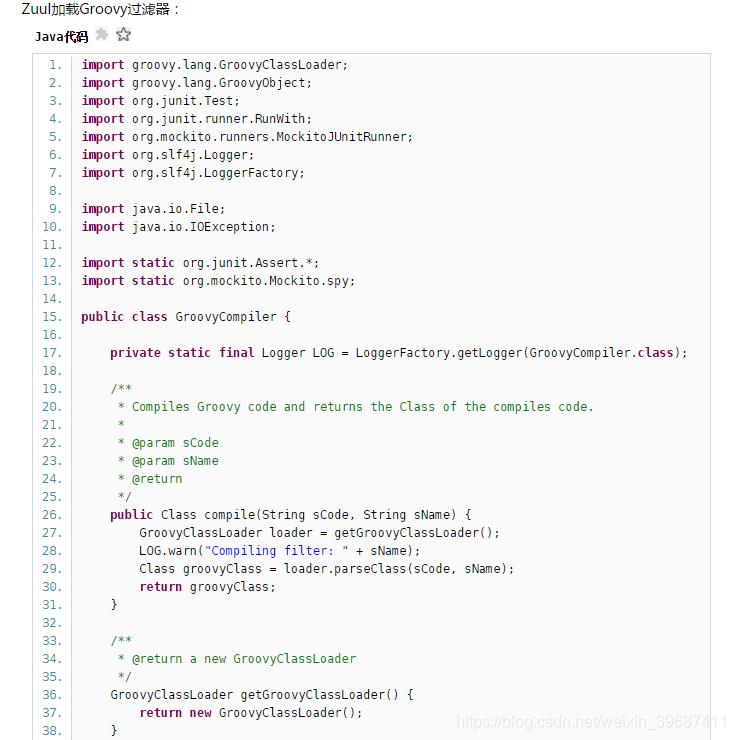
Zuul提供了一个框架,可以对过滤器进行动态的加载,编译,运行。
Zuul的过滤器之间没有直接的相互通信,他们之间通过一个RequestContext的静态类来进行数据传递的。RequestContext类中有ThreadLocal变量来记录每个Request所需要传递的数据。
Zuul的过滤器是由Groovy写成,这些过滤器文件被放在Zuul Server上的特定目录下面,Zuul会定期轮询这些目录,修改过的过滤器会动态的加载到Zuul Server中以便过滤请求使用。
下面有几种标准的过滤器类型:
Zuul大部分功能都是通过过滤器来实现的。Zuul中定义了四种标准过滤器类型,这些过滤器类型对应于请求的典型生命周期。
(1) PRE:这种过滤器在请求被路由之前调用。我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
(2) ROUTING:这种过滤器将请求路由到微服务。这种过滤器用于构建发送给微服务的请求,并使用Apache HttpClient或Netfilx Ribbon请求微服务。
(3) POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
(4) ERROR:在其他阶段发生错误时执行该过滤器。
内置的特殊过滤器
zuul还提供了一类特殊的过滤器,分别为:StaticResponseFilter和SurgicalDebugFilter
StaticResponseFilter:StaticResponseFilter允许从Zuul本身生成响应,而不是将请求转发到源。
SurgicalDebugFilter:SurgicalDebugFilter允许将特定请求路由到分隔的调试集群或主机。
自定义的过滤器
除了默认的过滤器类型,Zuul还允许我们创建自定义的过滤器类型。
例如,我们可以定制一种STATIC类型的过滤器,直接在Zuul中生成响应,而不将请求转发到后端的微服务。
2、过滤器的生命周期
Zuul请求的生命周期如图,该图详细描述了各种类型的过滤器的执行顺序。
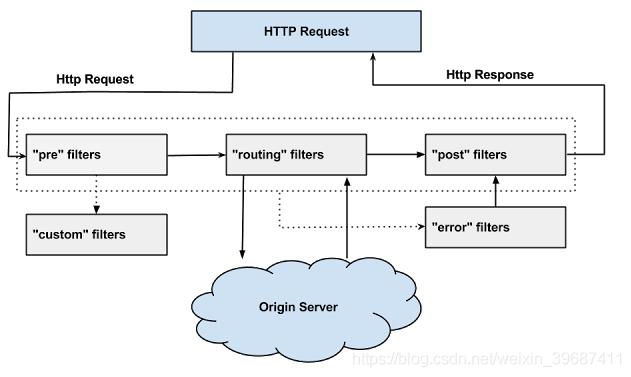
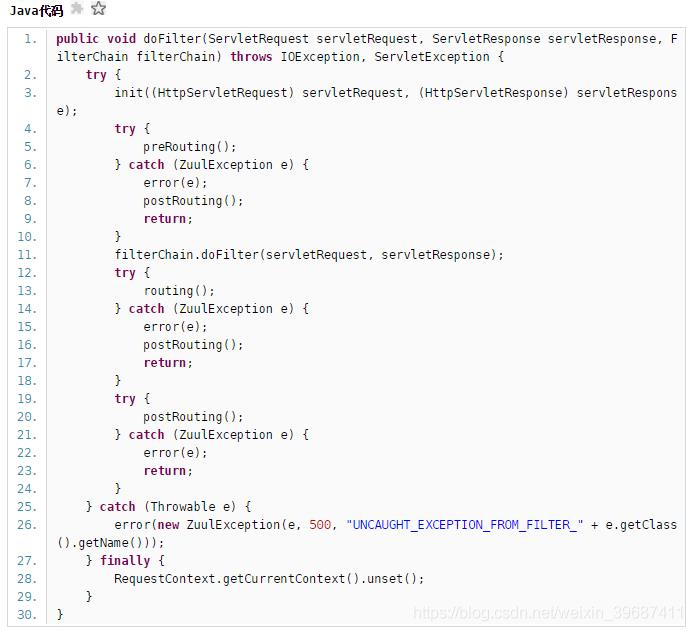
3、过滤器调度过程
4、动态加载过滤器

三、zuul 能做什么?
Zuul可以通过加载动态过滤机制,从而实现以下各项功能:
验证与安全保障: 识别面向各类资源的验证要求并拒绝那些与要求不符的请求。
审查与监控: 在边缘位置追踪有意义数据及统计结果,从而为我们带来准确的生产状态结论。
动态路由: 以动态方式根据需要将请求路由至不同后端集群处。
压力测试: 逐渐增加指向集群的负载流量,从而计算性能水平。
负载分配: 为每一种负载类型分配对应容量,并弃用超出限定值的请求。
静态响应处理: 在边缘位置直接建立部分响应,从而避免其流入内部集群。
多区域弹性: 跨越AWS区域进行请求路由,旨在实现ELB使用多样化并保证边缘位置与使用者尽可能接近。
除此之外,Netflix公司还利用Zuul的功能通过金丝雀版本实现精确路由与压力测试。
四、zuul 与应用的集成方式
1、ZuulServlet - 处理请求(调度不同阶段的filters,处理异常等)
ZuulServlet类似SpringMvc的DispatcherServlet,所有的Request都要经过ZuulServlet的处理
三个核心的方法preRoute(),route(), postRoute(),zuul对request处理逻辑都在这三个方法里
ZuulServlet交给ZuulRunner去执行。
由于ZuulServlet是单例,因此ZuulRunner也仅有一个实例。
ZuulRunner直接将执行逻辑交由FilterProcessor处理,FilterProcessor也是单例,其功能就是依据filterType执行filter的处理逻辑
FilterProcessor对filter的处理逻辑。
首先根据Type获取所有输入该Type的filter,List list。
遍历该list,执行每个filter的处理逻辑,processZuulFilter(ZuulFilter filter)
RequestContext对每个filter的执行状况进行记录,应该留意,此处的执行状态主要包括其执行时间、以及执行成功或者失败,如果执行失败则对异常封装后抛出。
到目前为止,zuul框架对每个filter的执行结果都没有太多的处理,它没有把上一filter的执行结果交由下一个将要执行的filter,仅仅是记录执行状态,如果执行失败抛出异常并终止执行。
2、ContextLifeCycleFilter - RequestContext 的生命周期管理
ContextLifecycleFilter的核心功能是为了清除RequestContext;请求上下文RequestContext通过ThreadLocal存储,需要在请求完成后删除该对象。
RequestContext提供了执行filter Pipeline所需要的Context,因为Servlet是单例多线程,这就要求RequestContext即要线程安全又要Request安全。
context使用ThreadLocal保存,这样每个worker线程都有一个与其绑定的RequestContext,因为worker仅能同时处理一个Request,这就保证了Request Context 即是线程安全的由是Request安全的。

3、GuiceFilter - GOOLE-IOC(Guice是Google开发的一个轻量级,基于Java5(主要运用泛型与注释特性)的依赖注入框架(IOC)。Guice非常小而且快。)
4、StartServer - 初始化 zuul 各个组件 (ioc、插件、filters、数据库等)

5、FilterScriptManagerServlet - uploading/downloading/managing scripts, 实现热部署
Filter源码文件放在zuul 服务特定的目录, zuul server会定期扫描目录下的文件的变化,动态的读取\编译\运行这些filter,
如果有Filter文件更新,源文件会被动态的读取,编译加载进入服务,接下来的Request处理就由这些新加入的filter处理。

http://www.cnblogs.com/lexiaofei/p/7080257.html
跨域时序图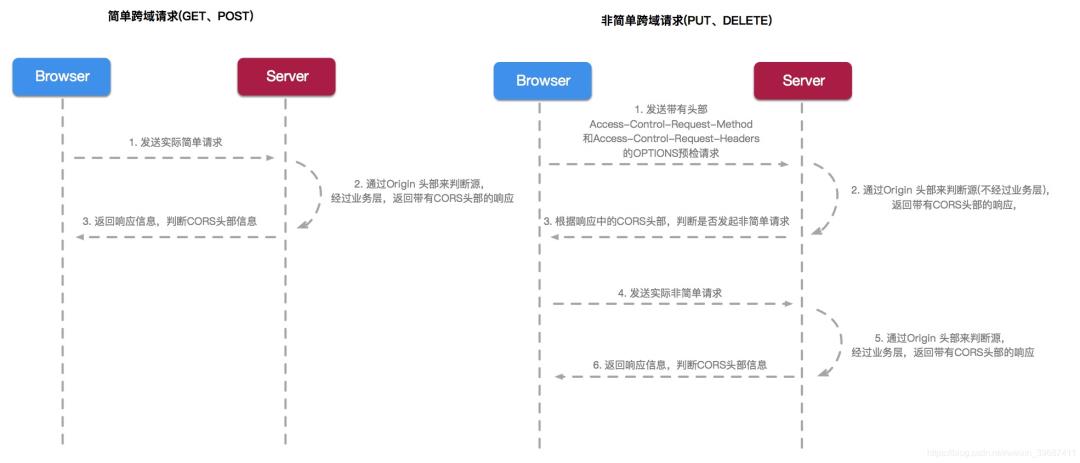
Ribbon工作原理
Ribbon 是netflix 公司开源的基于客户端的负载均衡组件,是Spring Cloud大家庭中非常重要的一个模块;Ribbon应该也是整个大家庭中相对而言比较复杂的模块,直接影响到服务调度的质量和性能。全面掌握Ribbon可以帮助我们了解在分布式微服务集群工作模式下,服务调度应该考虑到的每个环节。
本文将详细地剖析Ribbon的设计原理,帮助大家对Spring Cloud 有一个更好的认知。
一. Spring集成下的Ribbon工作结构
先贴一张总览图,说明一下Spring如何集成Ribbon的,如下所示:
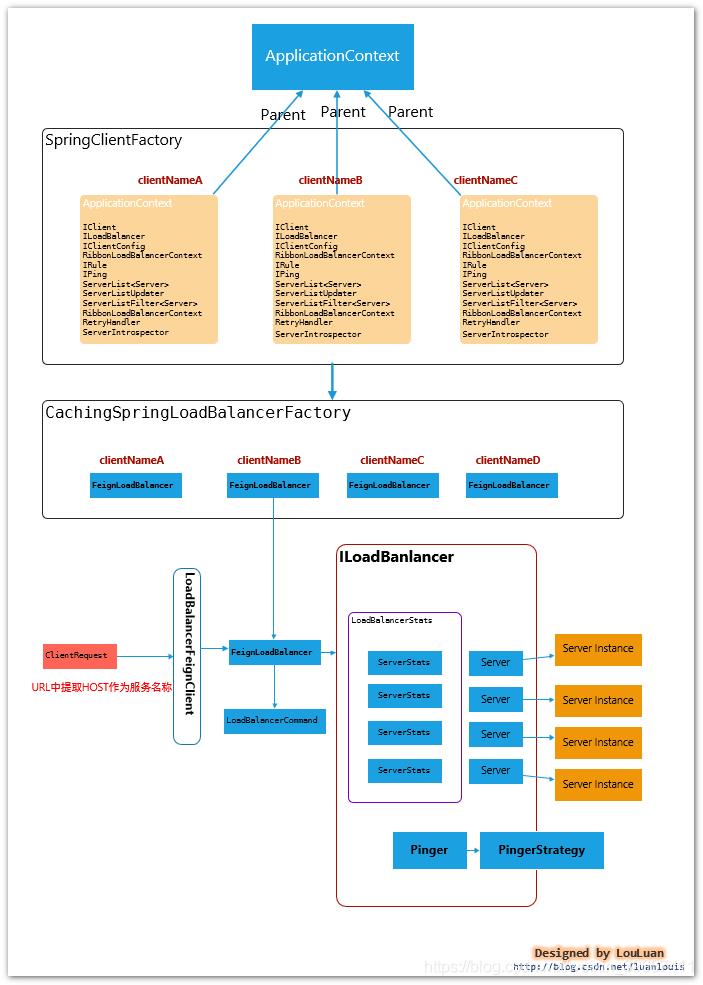
Spring Cloud集成模式下的Ribbon有以下几个特征:
Ribbon 服务配置方式
每一个服务配置都有一个Spring ApplicationContext上下文,用于加载各自服务的实例。
比如,当前Spring Cloud 系统内,有如下几个服务:
和Feign的集成模式
在使用Feign作为客户端时,最终请求会转发成 http://<服务名称>/的格式,通过LoadBalancerFeignClient, 提取出服务标识<服务名称>,然后根据服务名称在上下文中查找对应服务的负载均衡器FeignLoadBalancer,负载均衡器负责根据既有的服务实例的统计信息,挑选出最合适的服务实例
二、Spring Cloud模式下和Feign的集成实现方式
和Feign结合的场景下,Feign的调用会被包装成调用请求LoadBalancerCommand,然后底层通过Rxjava基于事件的编码风格,发送请求;Spring Cloud框架通过 Feigin 请求的URL,提取出服务名称,然后在上下文中找到对应服务的的负载均衡器实现FeignLoadBalancer,然后通过负载均衡器中挑选一个合适的Server实例,然后将调用请求转发到该Server实例上,完成调用,在此过程中,记录对应Server实例的调用统计信息。
/**
* Create an {@link Observable} that once subscribed execute network call asynchronously with a server chosen by load balancer.
* If there are any errors that are indicated as retriable by the {@link RetryHandler}, they will be consumed internally by the
* function and will not be observed by the {@link Observer} subscribed to the returned {@link Observable}. If number of retries has
* exceeds the maximal allowed, a final error will be emitted by the returned {@link Observable}. Otherwise, the first successful
* result during execution and retries will be emitted.
*/
public Observable<T> submit(final ServerOperation<T> operation) {
final ExecutionInfoContext context = new ExecutionInfoContext();
if (listenerInvoker != null) {
try {
listenerInvoker.onExecutionStart();
} catch (AbortExecutionException e) {
return Observable.error(e);
}
}
// 同一Server最大尝试次数
final int maxRetrysSame = retryHandler.getMaxRetriesOnSameServer();
//下一Server最大尝试次数
final int maxRetrysNext = retryHandler.getMaxRetriesOnNextServer();
// Use the load balancer
// 使用负载均衡器,挑选出合适的Server,然后执行Server请求,将请求的数据和行为整合到ServerStats中
Observable<T> o =
(server == null ? selectServer() : Observable.just(server))
.concatMap(new Func1<Server, Observable<T>>() {
@Override
// Called for each server being selected
public Observable<T> call(Server server) {
// 获取Server的统计值
context.setServer(server);
final ServerStats stats = loadBalancerContext.getServerStats(server);
// Called for each attempt and retry 服务调用
Observable<T> o = Observable
.just(server)
.concatMap(new Func1<Server, Observable<T>>() {
@Override
public Observable<T> call(final Server server) {
context.incAttemptCount();//重试计数
loadBalancerContext.noteOpenConnection(stats);//链接统计
if (listenerInvoker != null) {
try {
listenerInvoker.onStartWithServer(context.toExecutionInfo());
} catch (AbortExecutionException e) {
return Observable.error(e);
}
}
//执行监控器,记录执行时间
final Stopwatch tracer = loadBalancerContext.getExecuteTracer().start();
//找到合适的server后,开始执行请求
//底层调用有结果后,做消息处理
return operation.call(server).doOnEach(new Observer<T>() {
private T entity;
@Override
public void onCompleted() {
recordStats(tracer, stats, entity, null);
// 记录统计信息
}
@Override
public void onError(Throwable e) {
recordStats(tracer, stats, null, e);//记录异常信息
logger.debug("Got error {} when executed on server {}", e, server);
if (listenerInvoker != null) {
listenerInvoker.onExceptionWithServer(e, context.toExecutionInfo());
}
}
@Override
public void onNext(T entity) {
this.entity = entity;//返回结果值
if (listenerInvoker != null) {
listenerInvoker.onExecutionSuccess(entity, context.toExecutionInfo());
}
}
private void recordStats(Stopwatch tracer, ServerStats stats, Object entity, Throwable exception) {
tracer.stop();//结束计时
//标记请求结束,更新统计信息
loadBalancerContext.noteRequestCompletion(stats, entity, exception, tracer.getDuration(TimeUnit.MILLISECONDS), retryHandler);
}
});
}
});
//如果失败,根据重试策略触发重试逻辑
// 使用observable 做重试逻辑,根据predicate 做逻辑判断,这里做
if (maxRetrysSame > 0)
o = o.retry(retryPolicy(maxRetrysSame, true));
return o;
}
});
// next请求处理,基于重试器操作
if (maxRetrysNext > 0 && server == null)
o = o.retry(retryPolicy(maxRetrysNext, false));
return o.onErrorResumeNext(new Func1<Throwable, Observable<T>>() {
@Override
public Observable<T> call(Throwable e) {
if (context.getAttemptCount() > 0) {
if (maxRetrysNext > 0 && context.getServerAttemptCount() == (maxRetrysNext + 1)) {
e = new ClientException(ClientException.ErrorType.NUMBEROF_RETRIES_NEXTSERVER_EXCEEDED,
"Number of retries on next server exceeded max " + maxRetrysNext
+ " retries, while making a call for: " + context.getServer(), e);
}
else if (maxRetrysSame > 0 && context.getAttemptCount() == (maxRetrysSame + 1)) {
e = new ClientException(ClientException.ErrorType.NUMBEROF_RETRIES_EXEEDED,
"Number of retries exceeded max " + maxRetrysSame
+ " retries, while making a call for: " + context.getServer(), e);
}
}
if (listenerInvoker != null) {
listenerInvoker.onExecutionFailed(e, context.toFinalExecutionInfo());
}
return Observable.error(e);
}
});
}
从一组ServerList 列表中挑选合适的Server
/**
* Compute the final URI from a partial URI in the request. The following steps are performed:
* <ul>
* <li> 如果host尚未指定,则从负载均衡器中选定 host/port
* <li> 如果host 尚未指定并且尚未找到负载均衡器,则尝试从 虚拟地址中确定host/port
* <li> 如果指定了HOST,并且URI的授权部分通过虚拟地址设置,并且存在负载均衡器,则通过负载就均衡器中确定host/port(指定的HOST将会被忽略)
* <li> 如果host已指定,但是尚未指定负载均衡器和虚拟地址配置,则使用真实地址作为host
* <li> if host is missing but none of the above applies, throws ClientException
* </ul>
*
* @param original Original URI passed from caller
*/
public Server getServerFromLoadBalancer(@Nullable URI original, @Nullable Object loadBalancerKey) throws ClientException {
String host = null;
int port = -1;
if (original != null) {
host = original.getHost();
}
if (original != null) {
Pair<String, Integer> schemeAndPort = deriveSchemeAndPortFromPartialUri(original);
port = schemeAndPort.second();
}
// Various Supported Cases
// The loadbalancer to use and the instances it has is based on how it was registered
// In each of these cases, the client might come in using Full Url or Partial URL
ILoadBalancer lb = getLoadBalancer();
if (host == null) {
// 提供部分URI,缺少HOST情况下
// well we have to just get the right instances from lb - or we fall back
if (lb != null){
Server svc = lb.chooseServer(loadBalancerKey);// 使用负载均衡器选择Server
if (svc == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Load balancer does not have available server for client: "
+ clientName);
}
//通过负载均衡器选择的结果中选择host
host = svc.getHost();
if (host == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Invalid Server for :" + svc);
}
logger.debug("{} using LB returned Server: {} for request {}", new Object[]{clientName, svc, original});
return svc;
} else {
// No Full URL - and we dont have a LoadBalancer registered to
// obtain a server
// if we have a vipAddress that came with the registration, we
// can use that else we
// bail out
// 通过虚拟地址配置解析出host配置返回
if (vipAddresses != null && vipAddresses.contains(",")) {
throw new ClientException(
ClientException.ErrorType.GENERAL,
"Method is invoked for client " + clientName + " with partial URI of ("
+ original
+ ") with no load balancer configured."
+ " Also, there are multiple vipAddresses and hence no vip address can be chosen"
+ " to complete this partial uri");
} else if (vipAddresses != null) {
try {
Pair<String,Integer> hostAndPort = deriveHostAndPortFromVipAddress(vipAddresses);
host = hostAndPort.first();
port = hostAndPort.second();
} catch (URISyntaxException e) {
throw new ClientException(
ClientException.ErrorType.GENERAL,
"Method is invoked for client " + clientName + " with partial URI of ("
+ original
+ ") with no load balancer configured. "
+ " Also, the configured/registered vipAddress is unparseable (to determine host and port)");
}
} else {
throw new ClientException(
ClientException.ErrorType.GENERAL,
this.clientName
+ " has no LoadBalancer registered and passed in a partial URL request (with no host:port)."
+ " Also has no vipAddress registered");
}
}
} else {
// Full URL Case URL中指定了全地址,可能是虚拟地址或者是hostAndPort
// This could either be a vipAddress or a hostAndPort or a real DNS
// if vipAddress or hostAndPort, we just have to consult the loadbalancer
// but if it does not return a server, we should just proceed anyways
// and assume its a DNS
// For restClients registered using a vipAddress AND executing a request
// by passing in the full URL (including host and port), we should only
// consult lb IFF the URL passed is registered as vipAddress in Discovery
boolean shouldInterpretAsVip = false;
if (lb != null) {
shouldInterpretAsVip = isVipRecognized(original.getAuthority());
}
if (shouldInterpretAsVip) {
Server svc = lb.chooseServer(loadBalancerKey);
if (svc != null){
host = svc.getHost();
if (host == null){
throw new ClientException(ClientException.ErrorType.GENERAL,
"Invalid Server for :" + svc);
}
logger.debug("using LB returned Server: {} for request: {}", svc, original);
return svc;
} else {
// just fall back as real DNS
logger.debug("{}:{} assumed to be a valid VIP address or exists in the DNS", host, port);
}
} else {
// consult LB to obtain vipAddress backed instance given full URL
//Full URL execute request - where url!=vipAddress
logger.debug("Using full URL passed in by caller (not using load balancer): {}", original);
}
}
// end of creating final URL
if (host == null){
throw new ClientException(ClientException.ErrorType.GENERAL,"Request contains no HOST to talk to");
}
// just verify that at this point we have a full URL
return new Server(host, port);
}
三. LoadBalancer–负载均衡器的核心
LoadBalancer 的职能主要有三个:
维护Sever列表的数量(新增、更新、删除等)
维护Server列表的状态(状态更新)
当请求Server实例时,能否返回最合适的Server实例
本章节将通过详细阐述着这三个方面。
3.1 负载均衡器的内部基本实现原理
先熟悉一下负载均衡器LoadBalancer的实现原理图: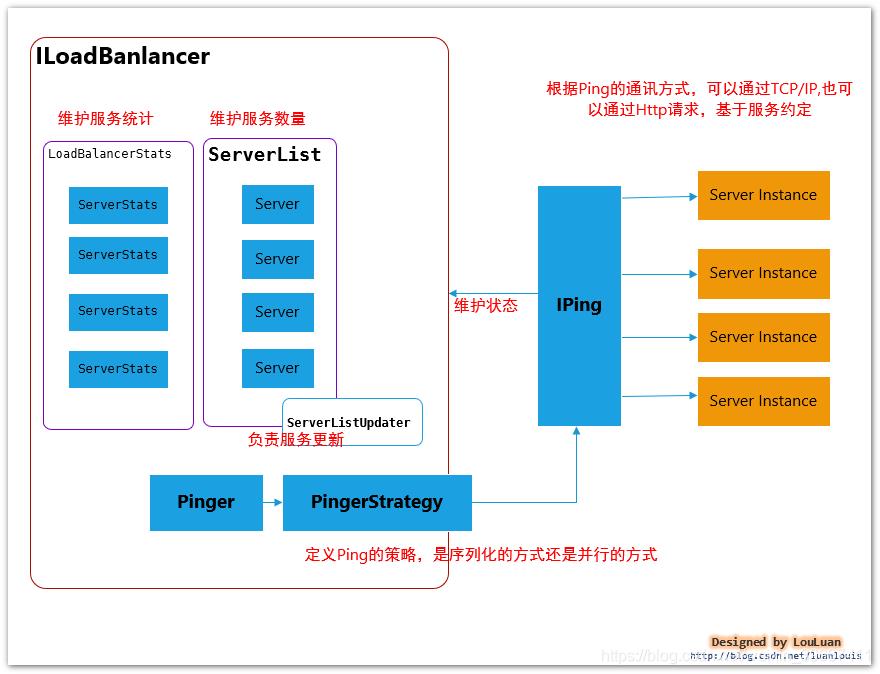
Eureka与Ribbon整合工作原理
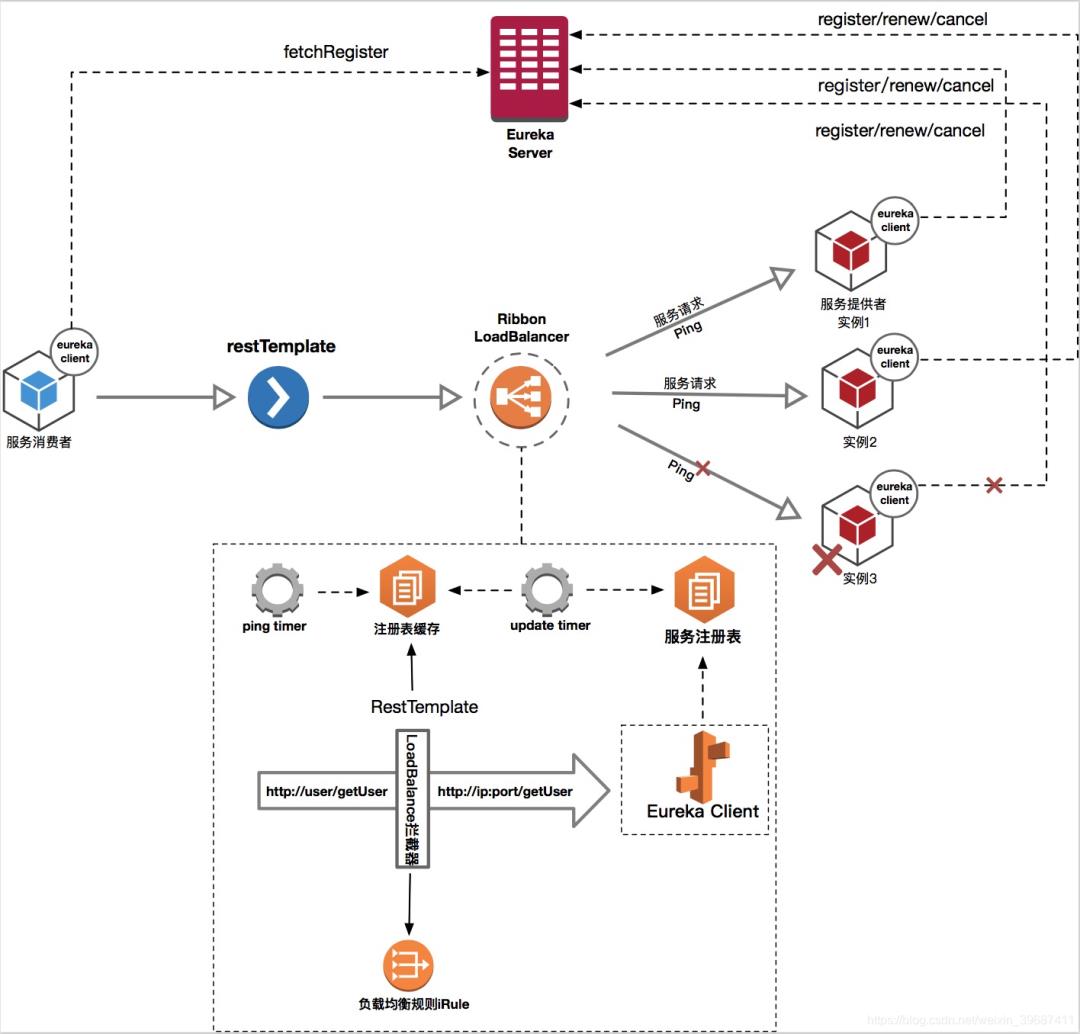
Eurek进行服务的注册与发现(请看之前的笔记[Spring Cloud Eureka搭建注册中心])
ribbon进行RestTemplate负载均衡策略(下期写ribbon实现负载均衡以及手写负责均衡)
hystrix 实现熔断机制以及通过dashboard查看熔断信息(有时间写hystrix dashboard详解)
项目结构如下(不包含Eureka服务注册与发现),另外部署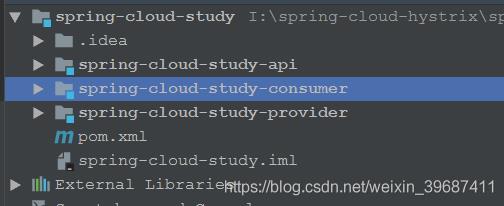
spring-cloud-study-provider 作为服务提供者将服务注册到Eureka集群
spring-cloud-study-api 作为项目api提供基础类库支持 spring-cloud-study-consumer
作为服务消费者从Eureka集群获取提供者信息,并进行消费,集成了Eureka,ribbon, hystrix, hystrix
dashboard
Eureka主要实现服务的注册与发现(请看之前的笔记[Spring Cloud Eureka搭建注册中心]),这里不在重复
消费端eureka配置
eureka:
client:
register-with-eureka: false
fetch-registry: true
service-url:
defaultZone: http://eureka-server.com:7001/eureka/,http://eureka-client1.com:7002/eureka/,http://eureka-client2.com:7003/eureka/
服务提供方eureka配置
eureka:
client:
service-url:
defaultZone: http://eureka-server.com:7001/eureka/,http://eureka-client1.com:7002/eureka/,http://eureka-client2.com:7003/eureka/
register-with-eureka: true
fetch-registry: false
instance:
instance-id: spring-cloud-study-provider # 调用服务时需要此名称(全部大写)
prefer-ip-address: true
ribbon实现负载均衡,默认采用:轮询。
引用jar
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.3.1.RELEASE</version>
</dependency>
在RestTemplat加入LoanBalance注释即可
@Configuration
public class RestConfigBean {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate()
{
return new RestTemplate();
}
}
hystrix 实现熔断机制以及通过dashboard进行监控
引入jar依赖
org.springframework.cloud spring-cloud-starter-hystrix 1.3.1.RELEASE org.springframework.cloud spring-cloud-starter-hystrix-dashboard 1.3.1.RELEASE com.netflix.hystrix hystrix-metrics-event-stream 1.5.12 com.netflix.hystrix hystrix-javanica 1.5.12
启动hystrix有及hystrix dashboard
@SpringBootApplication
@EnableDiscoveryClient #启用eureak服务发现
@EnableHystrix # 启用hystrix熔断
@EnableHystrixDashboard # 启用hystrix dashboard服务监控
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}
重要步骤
先启动eureka服务器,这边启动三台,模拟集群, 访问
http://eureka-server.com:7001/
http://eureka-client1.com:7002/
http://eureka-client2.com:7003/
http://eureka-server.com:7001/
http://eureka-client1.com:7002/
http://eureka-client2.com:7003/
启动服务提供者,从eureka集群获取服务提供者信息,并进行服务消费,启动成功后,进行测试
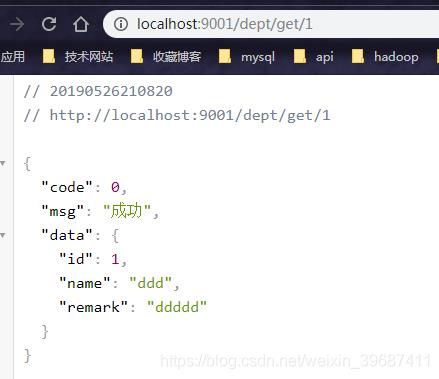
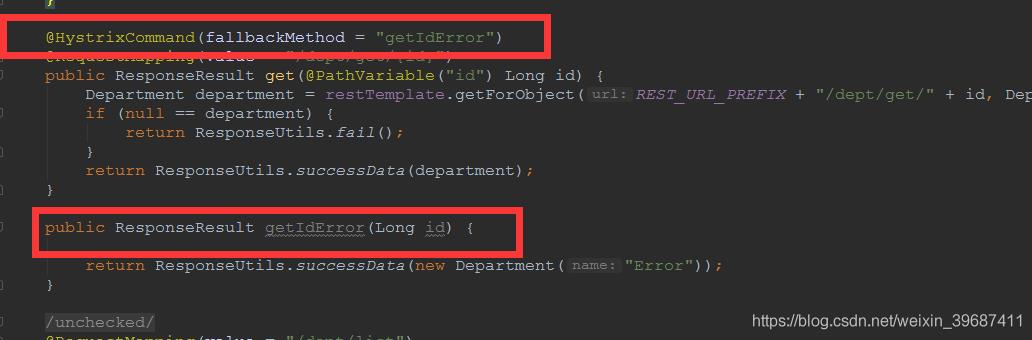

title:随便输入 点击 按钮提交 访问:
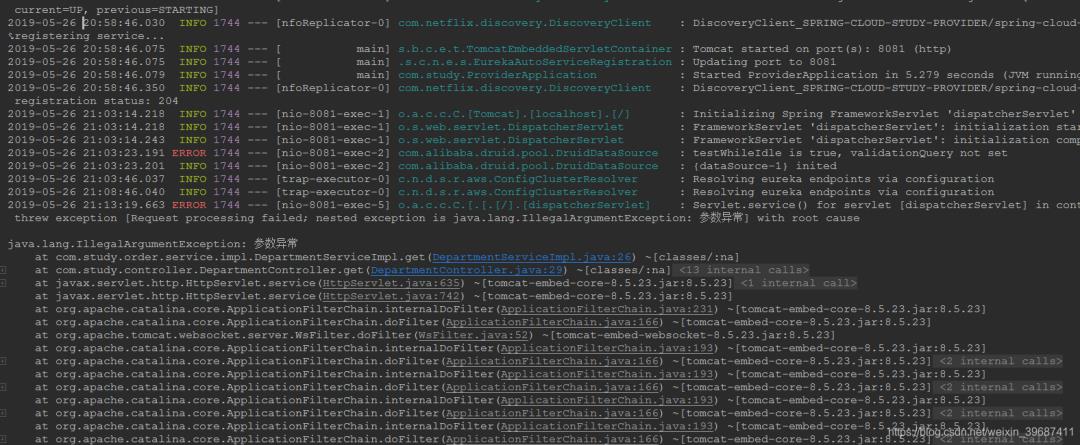
http://localhost:9001/dept/get/2, 服务提供者控制台将出现异常
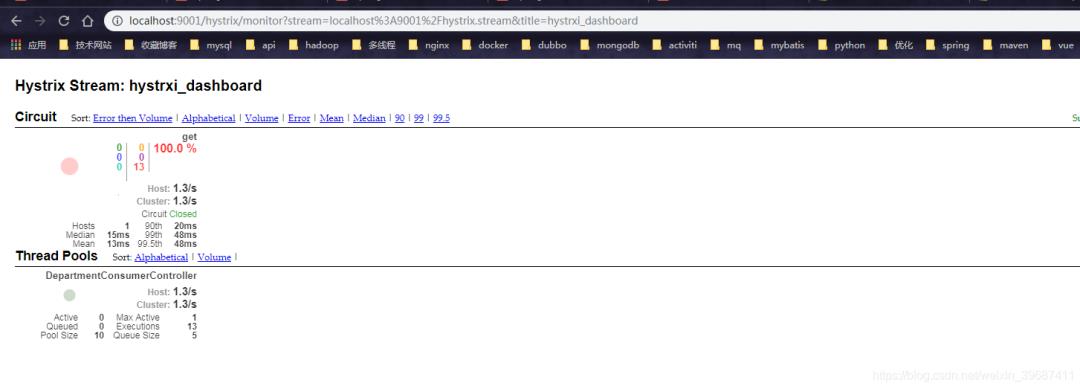
查询hystrix dashboard页面,刷新
解决分布式一致性
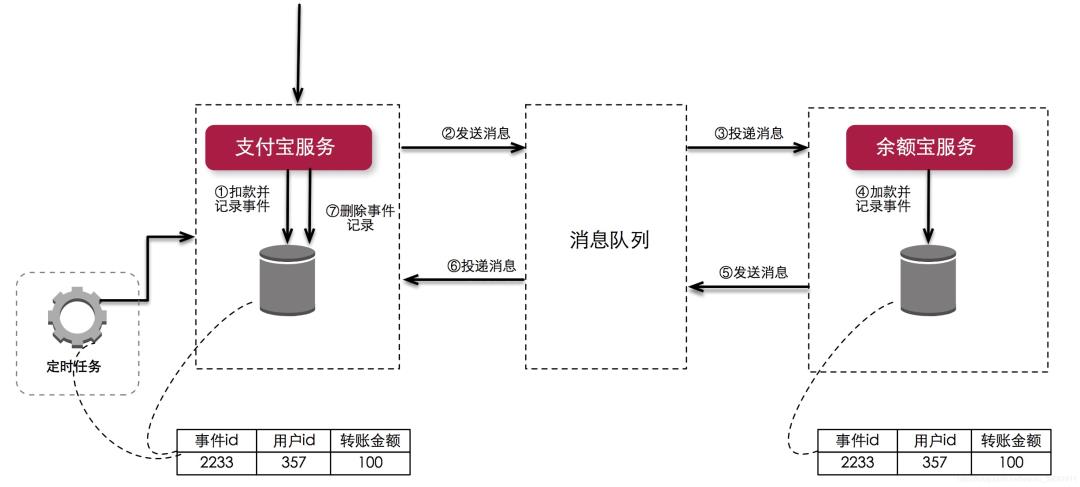
主要内容包括4部分:
传统分布式事务不是微服务中一致性的最佳选择
微服务架构中应满足数据最终一致性原则
微服务架构实现最终一致性的三种模式
对账是最后的终极防线。
我们先来看一下第一部分,传统使用本地事务和分布式事务保证一致性
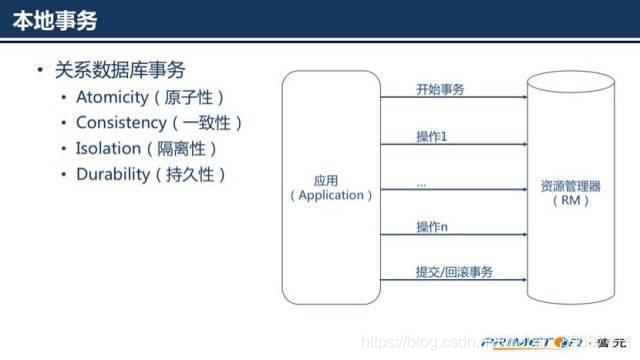
传统单机应用一般都会使用一个关系型数据库,好处是应用可以使用 ACID transactions。为保证一致性我们只需要:开始一个事务,改变(插入,删除,更新)很多行,然后提交事务(如果有异常时回滚事务)。更进一步,借助开发平台中的数据访问技术和框架(如Spring),我们需要做的事情更少,只需要关注数据本身的改变。随着组织规模不断扩大,业务量不断增长,单机应用和数据库已经不足以支持庞大的业务量和数据量,这个时候需要对应用和数据库进行拆分,就出现了一个应用需要同时访问两个或两个以上的数据库情况。开始我们用分布式事务来保证一致性,也就是我们常说的两阶段提交协议(2PC)。
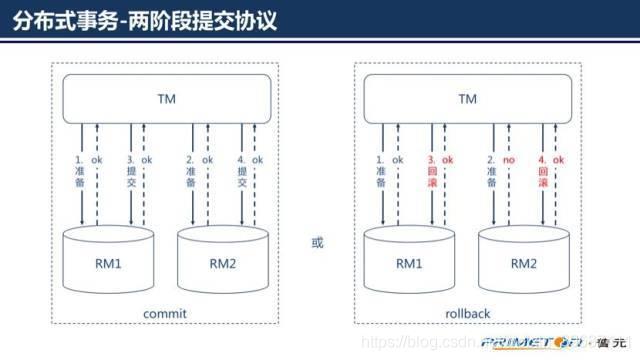
本地事务和分布式事务现在已经非常成熟,相关介绍很丰富,此处不多作讨论。我们下面来讨论以下为什么分布式事务不适用于微服务架构。
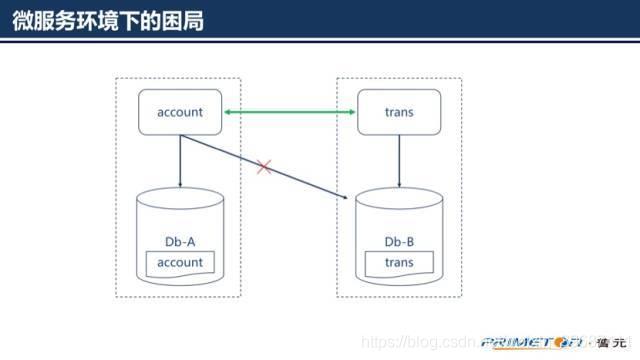
首先,对于微服务架构来说,数据访问变得更加复杂,这是因为数据都是微服务私有的,唯一可访问的方式就是通过API。这种打包数据访问方式使得微服务之间松耦合,并且彼此之间独立非常容易进行性能扩展。
其次,不同的微服务经常使用不同的数据库。应用会产生各种不同类型的数据,关系型数据库并不一定是最佳选择。例如,某个产生和查询字符串的应用采用Elasticsearch的字符搜索引擎;某个产生社交图片数据的应用可以采用图数据库,例如,Neo4j;基于微服务的应用一般都使用SQL和NoSQL结合的模式。但是这些非关系型数据大多数并不支持2PC。可见在微服务架构中已经不能选择分布式事务了。
依据CAP理论,必须在可用性(availability)和一致性(consistency)之间做出选择。如果选择提供一致性需要付出在满足一致性之前阻塞其他并发访问的代价。这可能持续一个不确定的时间,尤其是在系统已经表现出高延迟时或者网络故障导致失去连接时。
依据目前的成功经验,可用性一般是更好的选择,但是在服务和数据库之间维护数据一致性是非常根本的需求,微服务架构中应选择满足最终一致性。

当然选择了最终一致性,就要保证到最终的这段时间要在用户可接受的范围之内。那么我们怎么实现最终一致性呢?

从一致性的本质来看,是要保证在一个业务逻辑中包含的服务要么都成功,要么都失败。那我们怎么选择方向呢?保证成功还是保证失败呢?我们说业务模式决定了我们的选择。实现最终一致性有三种模式:可靠事件模式、业务补偿模式、TCC模式。
可靠事件模式属于事件驱动架构,当某件重要事情发生时,例如更新一个业务实体,微服务会向消息代理发布一个事件。消息代理会向订阅事件的微服务推送事件,当订阅这些事件的微服务接收此事件时,就可以完成自己的业务,也可能会引发更多的事件发布。1. 如订单服务创建一个待支付的订单,发布一个“创建订单”的事件
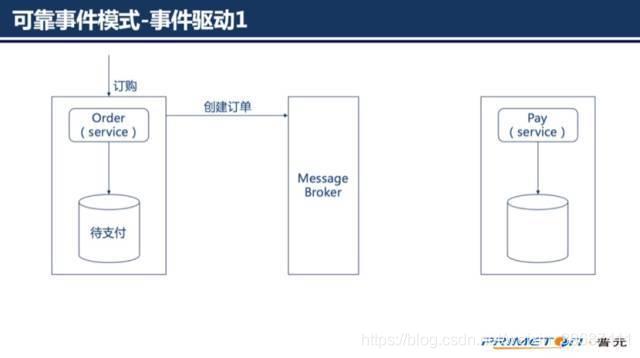
支付服务消费“创建订单”事件,支付完成后发布一个“支付完成”事件
订单服务消费“支付完成”事件,订单状态更新为待出库。
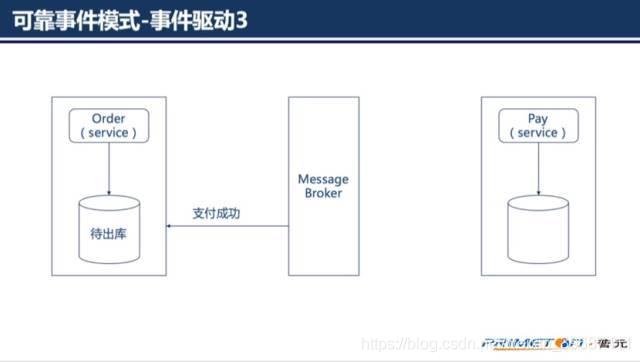
从而就实现了完成的业务流程。但是这并不是一个完美的流程。
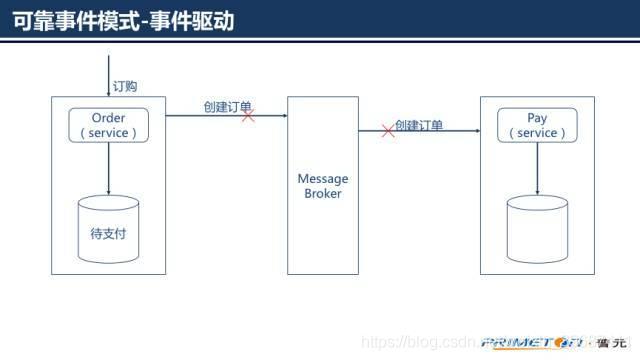
这个过程可能导致出现不一致的地方在于:某个微服务在更新了业务实体后发布事件却失败;虽然微服务发布事件成功,但是消息代理未能正确推送事件到订阅的微服务;接受事件的微服务重复消费了事件。

可靠事件模式在于保证可靠事件投递和避免重复消费,可靠事件投递定义为:(a)每个服务原子性的业务操作和发布事件
(b)消息代理确保事件传递至少一次。避免重复消费要求服务实现幂等性,如支付服务不能因为重复收到事件而多次支付。
因为现在流行的消息队列都实现了事件的持久化和at least once的投递模式,(b)特性(消息代理确保事件投递至少一次)已经满足,今天不做展开。
下面分享的内容主要从可靠事件投递和实现幂等性两方面来讨论,我们先来看可靠事件投递。首先我们来看一个实现的代码片段,这是从某生产系统上截取下来的。
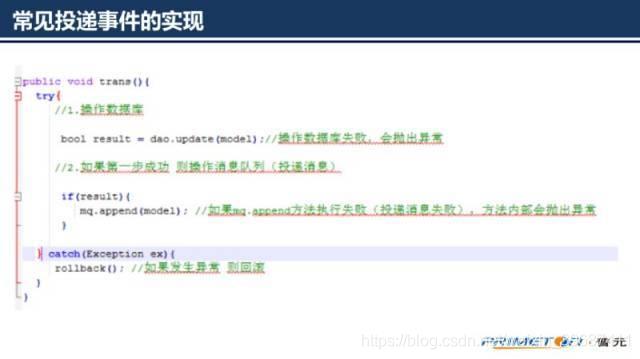
根据上述代码及注释,初看可能出现3种情况:
操作数据库成功,向消息代理投递事件也成功
操作数据库失败,不会向消息代理中投递事件了
操作数据库成功,但是向消息代理中投递事件时失败,向外抛出了异常,刚刚执行的更新数据库的操作将被回滚从上面分析的几种情况来看,貌似没有问题。但是仔细分析不难发现缺陷所在,在上面的处理过程中存在一段隐患时间窗口。
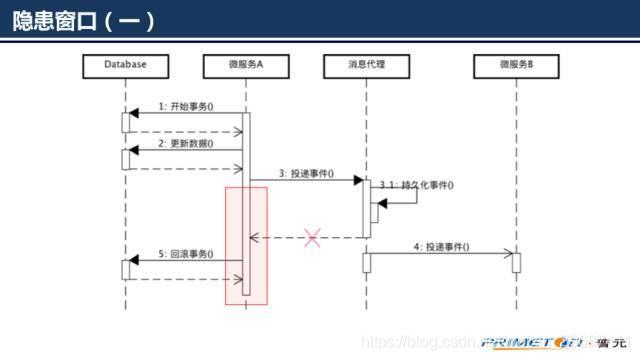
微服务A投递事件的时候可能消息代理已经处理成功,但是返回响应的时候网络异常,导致append操作抛出异常。最终结果是事件被投递,数据库确被回滚。
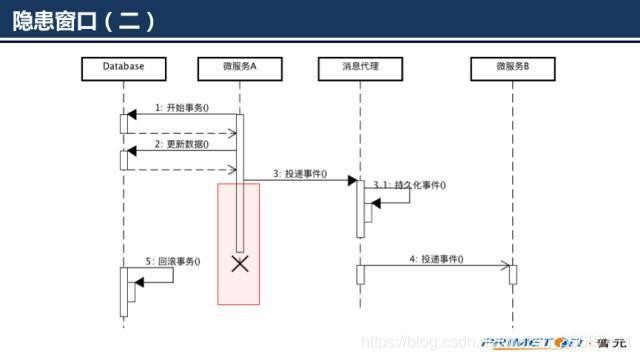
在投递完成后到数据库commit操作之间如果微服务A宕机也将造成数据库操作因为连接异常关闭而被回滚。最终结果还是事件被投递,数据库却被回滚。这个实现往往运行很长时间都没有出过问题,但是一旦出现了将会让人感觉莫名很难发现问题所在。下面给出两种可靠事件投递的实现方式:
一.本地事件表
本地事件表方法将事件和业务数据保存在同一个数据库中,使用一个额外的“事件恢复”服务来恢复事件,由本地事务保证更新业务和发布事件的原子性。考虑到事件恢复可能会有一定的延时,服务在完成本地事务后可立即向消息代理发布一个事件。
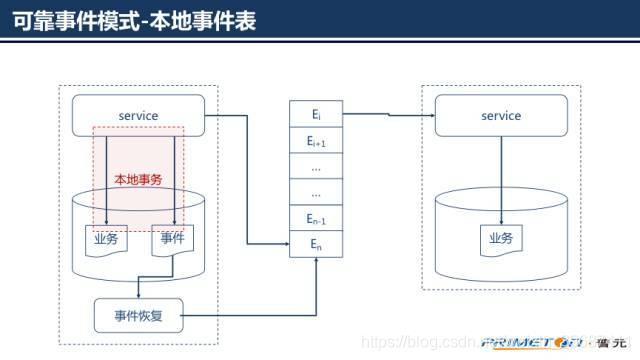
微服务在同一个本地事务中记录业务数据和事件
微服务实时发布一个事件立即通知关联的业务服务,如果事件发布成功立即删除记录的事件
事件恢复服务定时从事件表中恢复未发布成功的事件,重新发布,重新发布成功才删除记录的事件其中第2条的操作主要是为了增加发布事件的实时性,由第三条保证事件一定被发布。本地事件表方式业务系统和事件系统耦合比较紧密,额外的事件数据库操作也会给数据库带来额外的压力,可能成为瓶颈。
二、外部事件表
外部事件表方法将事件持久化到外部的事件系统,事件系统需提供实时事件服务以接受微服务发布事件,同时事件系统还需要提供事件恢复服务来确认和恢复事件。
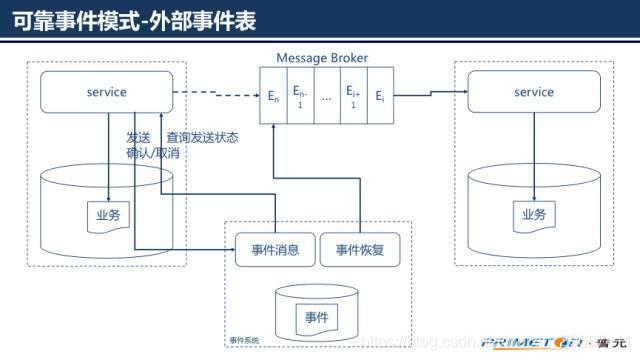
业务服务在事务提交前,通过实时事件服务向事件系统请求发送事件,事件系统只记录事件并不真正发送
业务服务在提交后,通过实时事件服务向事件系统确认发送,事件得到确认后事件系统才真正发布事件到消息代理
业务服务在业务回滚时,通过实时事件向事件系统取消事件
如果业务服务在发送确认或取消之前停止服务了怎么办呢?事件系统的事件恢复服务会定期找到未确认发送的事件向业务服务查询状态,根据业务服务返回的状态决定事件是要发布还是取消该方式将业务系统和事件系统独立解耦,都可以独立伸缩。但是这种方式需要一次额外的发送操作,并且需要发布者提供额外的查询接口介绍完了可靠事件投递再来说一说幂等性的实现,有些事件本身是幂等的,有些事件却不是。

如果事件本身描述的是某个时间点的固定值(如账户余额为100),而不是描述一条转换指令(如余额增加10),那么这个事件是幂等的。我们要意识到事件可能出现的次数和顺序是不可预测的,需要保证幂等事件的顺序执行,否则结果往往不是我们想要的。如果我们先后收到两条事件,(1)账户余额更新为100,(2)账户余额更新为120。
1.微服务收到事件(1)
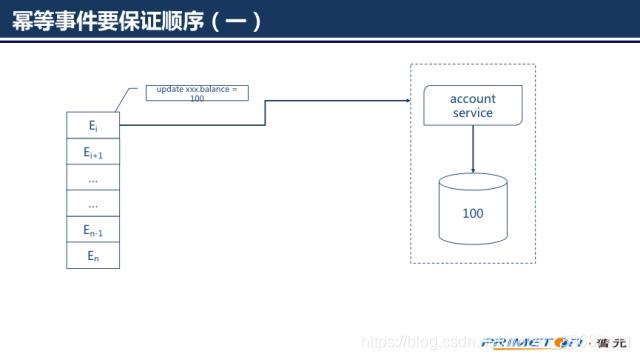
2.微服务收到事件(2)
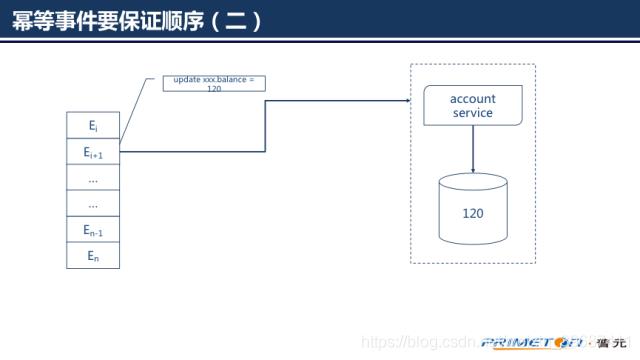
微服务再次收到事件1
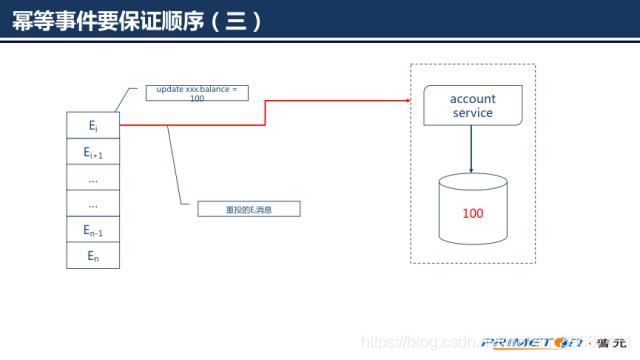
显然结果是错误的,所以我们需要保证事件(2)一旦执行事件(1)就不能再处理,否则账户余额仍不是我们想要的结果。
为保证事件的顺序一个简单的做法是在事件中添加时间戳,微服务记录每类型的事件最后处理的时间戳,如果收到的事件的时间戳早于我们记录的,丢弃该事件。如果事件不是在同一个服务器上发出的,那么服务器之间的时间同步是个难题,更稳妥的做法是使用一个全局递增序列号替换时间戳。
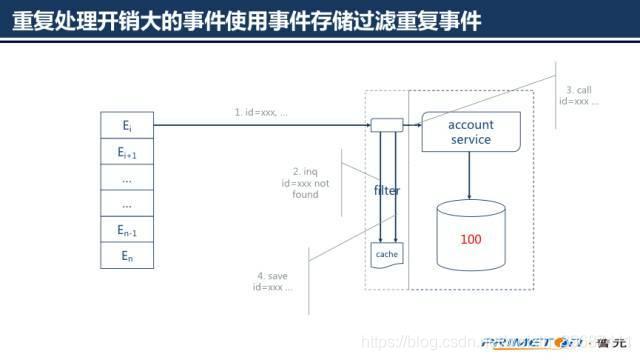
对于本身不具有幂等性的操作,主要思想是为每条事件存储执行结果,当收到一条事件时我们需要根据事件的id查询该事件是否已经执行过,如果执行过直接返回上一次的执行结果,否则调度执行事件。
重复处理开销大事件使用事件存储过滤重复事件
在这个思想下我们需要考虑重复执行一条事件和查询存储结果的开销。重复处理开销小的事件重复处理如果重复处理一条事件开销很小,或者可预见只有非常少的事件会被重复接收,可以选择重复处理一次事件,在将事件数据持久化时由数据库抛出唯一性约束异常。
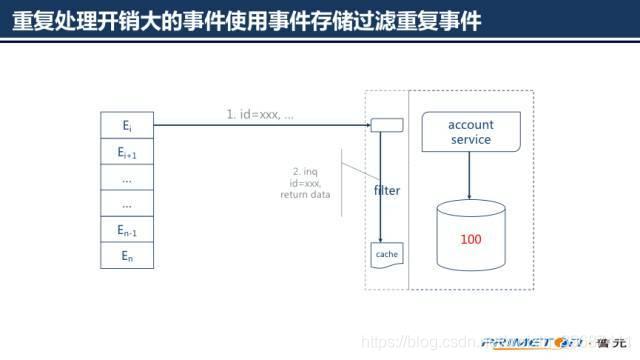
如果重复处理一条事件的开销相比额外一次查询的开销要高很多,使用一个过滤服务来过滤重复的事件,过滤服务使用事件存储存储已经处理过的事件和结果。
当收到一条事件时,过滤服务首先查询事件存储,确定该条事件是否已经被处理过,如果事件已经被处理过,直接返回存储的结果;否则调度业务服务执行处理,并将处理完的结果存储到事件存储中。
一般情况下上面的方法能够运行得很好,如果我们的微服务是RPC类的服务我们需要更加小心,可能出现的问题在于,(1)过滤服务在业务处理完成后才将事件结果存储到事件存储中,但是在业务处理完成前有可能就已经收到重复事件,由于是RPC服务也不能依赖数据库的唯一性约束;(2)业务服务的处理结果可能出现位置状态,一般出现在正常提交请求但是没有收到响应的时候。
对于问题(1)可以按步骤记录事件处理过程,比如事件的记录事件的处理过程为“接收”、“发送请求”、“收到应答”、“处理完成”。好处是过滤服务能及时的发现重复事件,进一步还能根据事件状态作不同的处理。
对于问题(2)可以通过一次额外的查询请求来确定事件的实际处理状态,要注意额外的查询会带来更长时间的延时,更进一步可能某些RPC服务根本不提供查询接口。此时只能选择接收暂时的不一致,时候采用对账和人工接入的方式来保证一致性。
补偿模式
为了描述方便,这里先定义两个概念:
业务异常:业务逻辑产生错误的情况,比如账户余额不足、商品库存不足等。
技术异常:非业务逻辑产生的异常,如网络连接异常、网络超时等。
补偿模式使用一个额外的协调服务来协调各个需要保证一致性的微服务,协调服务按顺序调用各个微服务,如果某个微服务调用异常(包括业务异常和技术异常)就取消之前所有已经调用成功的微服务。
补偿模式建议仅用于不能避免出现业务异常的情况,如果有可能应该优化业务模式,以避免要求补偿事务。如账户余额不足的业务异常可通过预先冻结金额的方式避免,商品库存不足可要求商家准备额外的库存等。
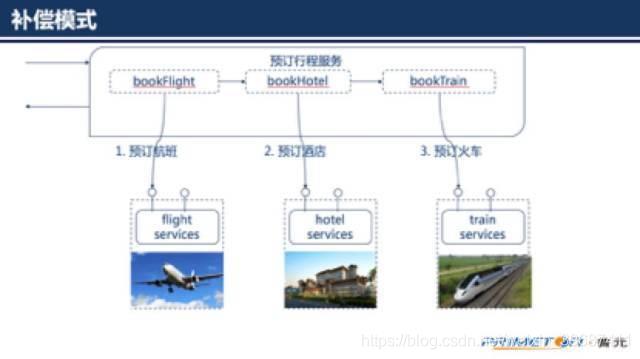
我们通过一个实例来说明补偿模式,一家旅行公司提供预订行程的业务,可以通过公司的网站提前预订飞机票、火车票、酒店等。
假设一位客户规划的行程是,
(1)上海-北京6月19日9点的某某航班,
(2)某某酒店住宿3晚,
(3)北京-上海6月22日17点火车。在客户提交行程后,旅行公司的预订行程业务按顺序串行的调用航班预订服务、酒店预订服务、火车预订服务。最后的火车预订服务成功后整个预订业务才算完成。
如果火车票预订服务没有调用成功,那么之前预订的航班、酒店都得取消。取消之前预订的酒店、航班即为补偿过程。
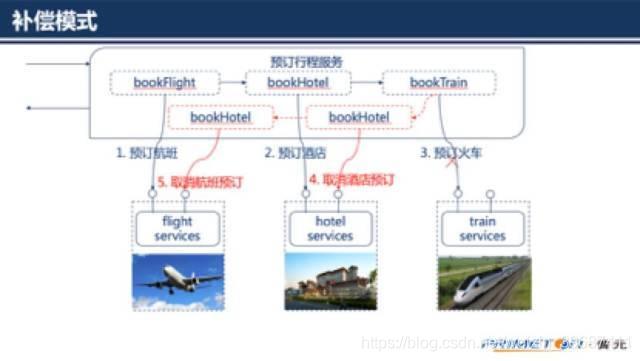
为了降低开发的复杂性和提高效率,协调服务实现为一个通用的补偿框架。补偿框架提供服务编排和自动完成补偿的能力。
要实现补偿过程,我们需要做到两点:
首先要确定失败的步骤和状态,从而确定需要补偿的范围。
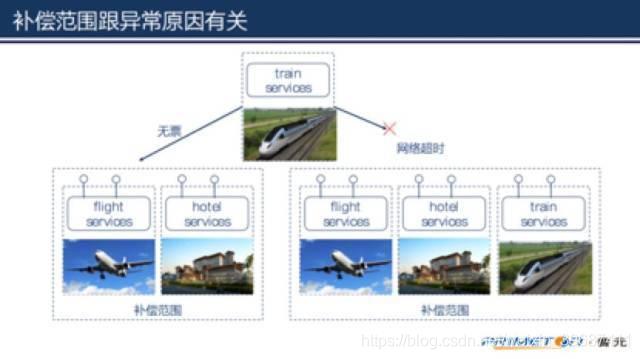
在上面的例子中我们不光要知道第3个步骤(预订火车)失败,还要知道失败的原因。如果是因为预订火车服务返回无票,那么补偿过程只需要取消前两个步骤就可以了;但是如果失败的原因是因为网络超时,那么补偿过程除前两个步骤之外还需要包括第3个步骤。
其次要能提供补偿操作使用到的业务数据。
比如一个支付微服务的补偿操作要求参数包括支付时的业务流水id、账号和金额。理论上说实际完成补偿操作可以根据唯一的业务流水id就可以,但是提供更多的要素有益于微服务的健壮性,微服务在收到补偿操作的时候可以做业务的检查,比如检查账户是否相等,金额是否一致等等。
做到上面两点的办法是记录完整的业务流水,可以通过业务流水的状态来确定需要补偿的步骤,同时业务流水为补偿操作提供需要的业务数据。
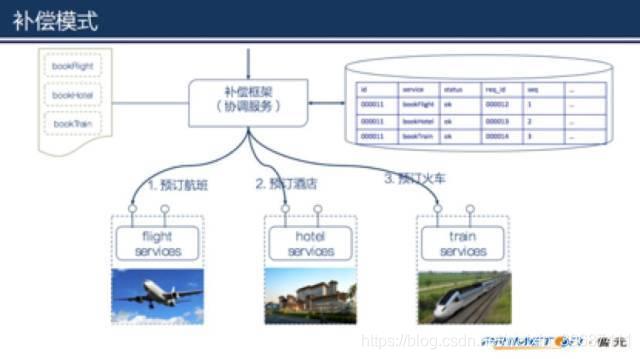
当客户的一个预订请求达到时,协调服务(补偿框架)为请求生成一个全局唯一的业务流水号。并在调用各个工作服务的同时记录完整的状态。
记录调用bookFlight的业务流水,调用bookFlight服务,更新业务流水状态
记录调用bookHotel的业务流水,调用bookHotel服务,更新业务流水状态
记录调用bookTrain的业务流水,调用bookTrain服务,更新业务流水状态
当调用某个服务出现异常时,比如第3步骤(预订火车)异常
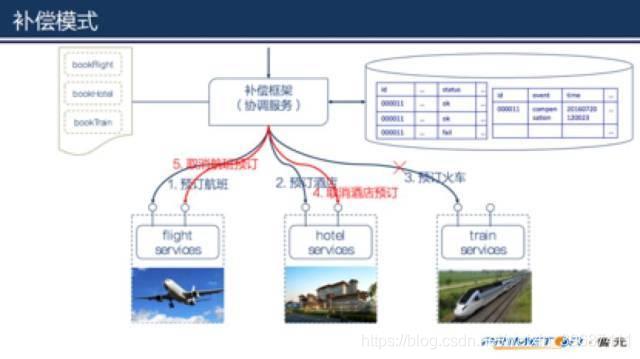
协调服务(补偿框架)同样会记录第3步的状态,同时会另外记录一条事件,说明业务出现了异常。然后就是执行补偿过程了,可以从业务流水的状态中知道补偿的范围,补偿过程中需要的业务数据从记录的业务流水中获取。
对于一个通用的补偿框架来说,预先知道微服务需要记录的业务要素是不可能的。那么就需要一种方法来保证业务流水的可扩展性,这里介绍两种方法:大表和关联表。
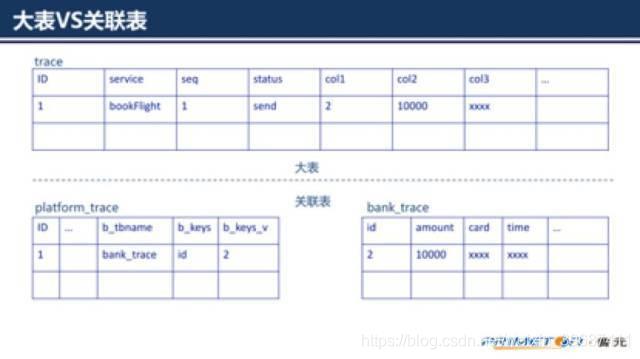
大表顾明思议就是设计时除必须的字段外,还需要预留大量的备用字段,框架可以提供辅助工具来帮助将业务数据映射到备用字段中。
关联表,分为框架表和业务表,技术表中保存为实现补偿操作所需要的技术数据,业务表保存业务数据,通过在技术表中增加业务表名和业务表主键来建立和业务数据的关联。
大表对于框架层实现起来简单,但是也有一些难点,比如预留多少字段合适,每个字段又需要预留多少长度。另外一个难点是如果向从数据层面来查询数据,很难看出备用字段的业务含义,维护过程不友好。
关联表在业务要素上更灵活,能支持不同的业务类型记录不同的业务要素;但是对于框架实现上难度更高,另外每次查询都需要复杂的关联动作,性能方面会受影响。
有了上面的完整的流水记录,协调服务就可以根据工作服务的状态在异常时完成补偿过程。但是补偿由于网络等原因,补偿操作并不一定能保证100%成功,这时候我们还要做更多一点。
通过重试保证补偿过程的完整。从而满足最终一致性。
补偿过程作为一个服务调用过程同样存在调用不成功的情况,这个时候需要通过重试的机制来保证补偿的成功率。当然这也就要求补偿操作本身具备幂等性。
关于幂等性的实现在前面做过讨论。
重试策略
如果只是一味的失败就立即重试会给工作服务造成不必要的压力,我们要根据服务执行失败的原因来选择不同的重试策略。
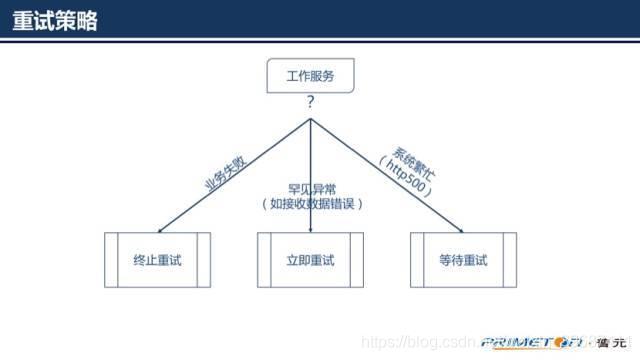
如果失败的原因不是暂时性的,由于业务因素导致(如业务要素检查失败)的业务错误,这类错误是不会重发就能自动恢复的,那么应该立即终止重试。
如果错误的原因是一些罕见的异常,比如因为网络传输过程出现数据丢失或者错误,应该立即再次重试,因为类似的错误一般很少会再次发生。
如果错误的原因是系统繁忙(比如http协议返回的500或者另外约定的返回码)或者超时,这个时候需要等待一些时间再重试。
重试操作一般会指定重试次数上线,如果重试次数达到了上限就不再进行重试了。这个时候应该通过一种手段通知相关人员进行处理。
对于等待重试的策略如果重试时仍然错误,可逐渐增加等待的时间,直到达到一个上限后,以上限作为等待时间。
如果某个时刻聚集了大量需要重试的操作,补偿框架需要控制请求的流量,以防止对工作服务造成过大的压力。
另外关于补偿模式还有几点补充说明:
微服务实现补偿操作不是简单的回退到业务发生时的状态,因为可能还有其他的并发的请求同时更改了状态。一般都使用逆操作的方式完成补偿。
补偿过程不需要严格按照与业务发生的相反顺序执行,可以依据工作服务的重用程度优先执行,甚至是可以并发的执行。
有些服务的补偿过程是有依赖关系的,被依赖服务的补偿操作没有成功就要及时终止补偿过程。
如果在一个业务中包含的工作服务不是都提供了补偿操作,那我们编排服务时应该把提供补偿操作的服务放在前面,这样当后面的工作服务错误时还有机会补偿。
设计工作服务的补偿接口时应该以协调服务请求的业务要素作为条件,不要以工作服务的应答要素作为条件。因为还存在超时需要补偿的情况,这时补偿框架就没法提供补偿需要的业务要素。
补偿模式就介绍到这里,下面介绍第三种模式:TCC模式(Try-Confirm-Cancel)
一个完整的TCC业务由一个主业务服务和若干个从业务服务组成,主业务服务发起并完成整个业务活动,TCC模式要求从服务提供三个接口:Try、Confirm、Cancel。
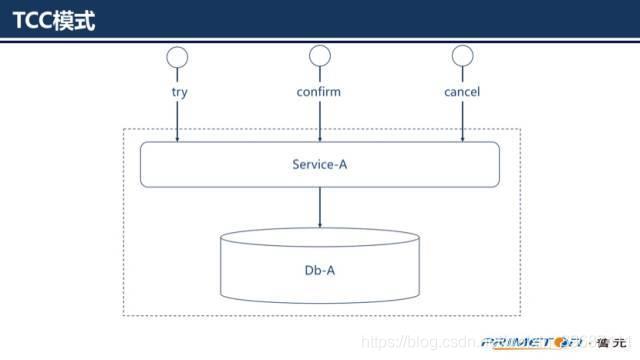
Try:完成所有业务检查 预留必须业务资源2) Confirm:真正执行业务 不作任何业务检查 只使用Try阶段预留的业务资源 Confirm操作满足幂等性3) Cancel:释放Try阶段预留的业务资源 Cancel操作满足幂等性整个TCC业务分成两个阶段完成。
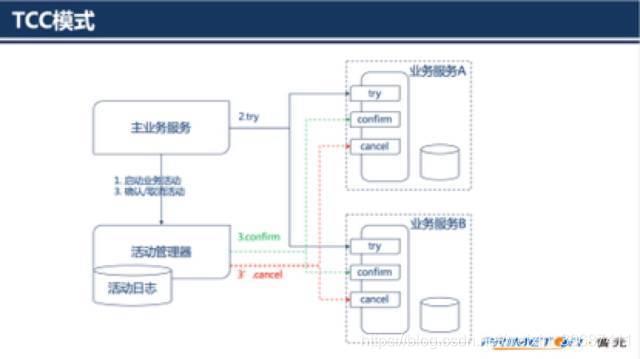
第一阶段:主业务服务分别调用所有从业务的try操作,并在活动管理器中登记所有从业务服务。当所有从业务服务的try操作都调用成功或者某个从业务服务的try操作失败,进入第二阶段。
第二阶段:活动管理器根据第一阶段的执行结果来执行confirm或cancel操作。如果第一阶段所有try操作都成功,则活动管理器调用所有从业务活动的confirm操作。否则调用所有从业务服务的cancel操作。
需要注意的是第二阶段confirm或cancel操作本身也是满足最终一致性的过程,在调用confirm或cancel的时候也可能因为某种原因(比如网络)导致调用失败,所以需要活动管理支持重试的能力,同时这也就要求confirm和cancel操作具有幂等性。
在补偿模式中一个比较明显的缺陷是,没有隔离性。从第一个工作服务步骤开始一直到所有工作服务完成(或者补偿过程完成),不一致是对其他服务可见的。另外最终一致性的保证还充分的依赖了协调服务的健壮性,如果协调服务异常,就没法达到一致性。
TCC模式在一定程度上弥补了上述的缺陷,在TCC模式中直到明确的confirm动作,所有的业务操作都是隔离的(由业务层面保证)。另外工作服务可以通过指定try操作的超时时间,主动的cancel预留的业务资源,从而实现自治的微服务。
TCC模式和补偿模式一样需要需要有协调服务和工作服务,协调服务也可以作为通用服务一般实现为框架。与补偿模式不同的是TCC服务框架不需要记录详细的业务流水,完成confirm和cancel操作的业务要素由业务服务提供。
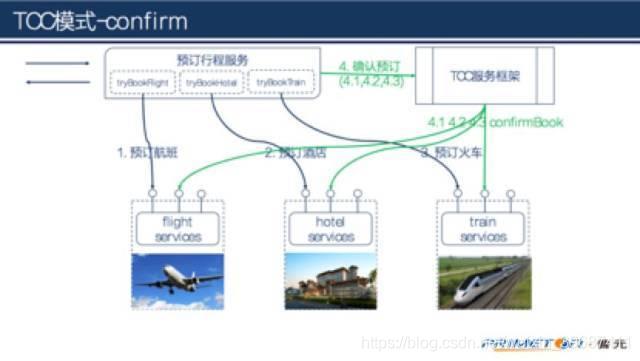
在第4步确认预订之前,订单只是pending状态,只有等到明确的confirm之后订单才生效。
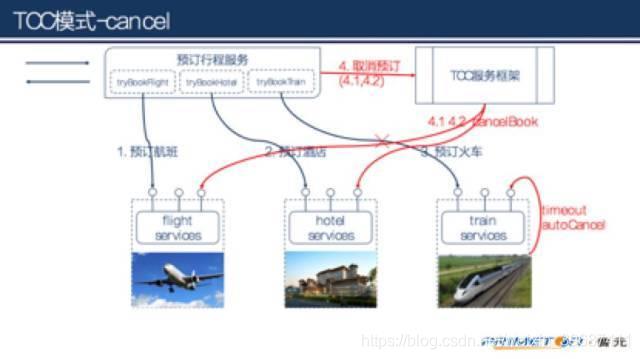
如果3个服务中某个服务try操作失败,那么可以向TCC服务框架提交cancel,或者什么也不做由工作服务自己超时处理。
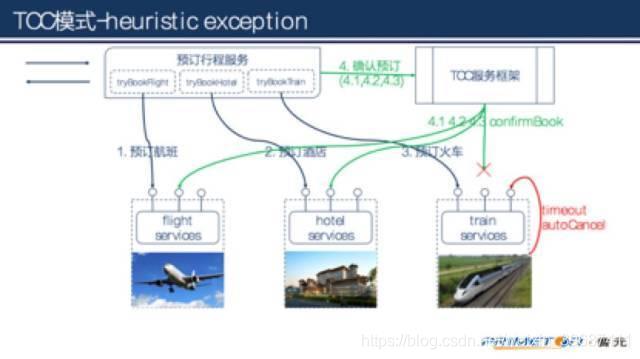
TCC模式也不能百分百保证一致性,如果业务服务向TCC服务框架提交confirm后,TCC服务框架向某个工作服务提交confirm失败(比如网络故障),那么就会出现不一致,一般称为heuristic exception。
需要说明的是为保证业务成功率,业务服务向TCC服务框架提交confirm以及TCC服务框架向工作服务提交confirm/cancel时都要支持重试,这也就要confirm/cancel的实现必须具有幂等性。如果业务服务向TCC服务框架提交confirm/cancel失败,不会导致不一致,因为服务最后都会超时而取消。
另外heuristic exception是不可杜绝的,但是可以通过设置合适的超时时间,以及重试频率和监控措施使得出现这个异常的可能性降低到很小。如果出现了heuristic exception是可以通过人工的手段补救的。
如果有些业务由于瞬时的网络故障或调用超时等问题,通过上文所讲的3种模式一般都能得到很好的解决。但是在当今云计算环境下,很多服务是依赖于外部系统的可用性情况,在一些重要的业务场景下还需要周期性的对账来保证真实的一致性。比如支付系统和银行之间每天日终是都会有对账过程。
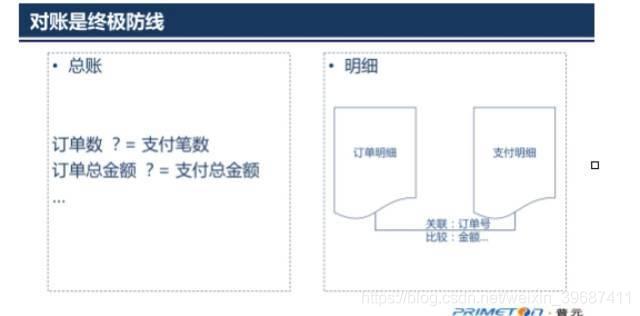
以上就是今天分享的内容,主要介绍的是微服务架构中需要满足最终一致性原则以及实现最终一致性的3种模式。
级联故障流程
图片描述
断路器组件Hystrix工作原理
1、Netflix Hystrix断路器是什么?
Netflix Hystrix是SOA/微服务架构中提供服务隔离、熔断、降级机制的工具/框架。Netflix Hystrix是断路器的一种实现,用于高微服务架构的可用性,是防止服务出现雪崩的利器。
2、为什么需要断路器?
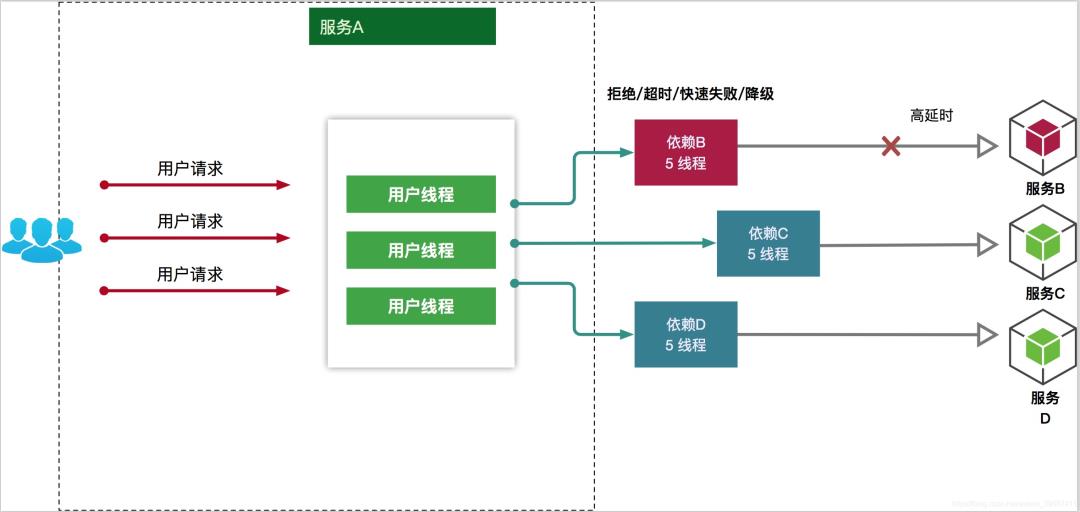
在分布式架构中,一个应用依赖多个服务是非常常见的,如果其中一个依赖由于延迟过高发生阻塞,调用该依赖服务的线程就会阻塞,如果相关业务的QPS较高,就可能产生大量阻塞,从而导致该应用/服务由于服务器资源被耗尽而拖垮。
另外,故障也会在应用之间传递,如果故障服务的上游依赖较多,可能会引起服务的雪崩效应。就跟数据瘫痪,会引起依赖该数据库的应用瘫痪是一样的道理。
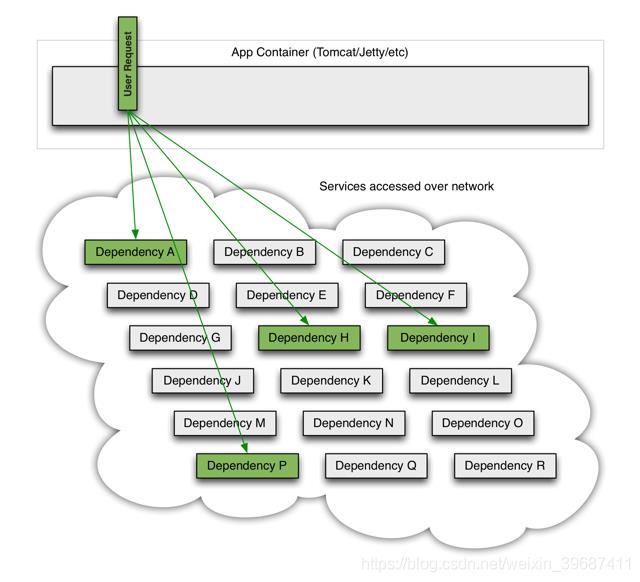
当一个应用依赖多个外部服务,一切都正常的情况下,如下图:
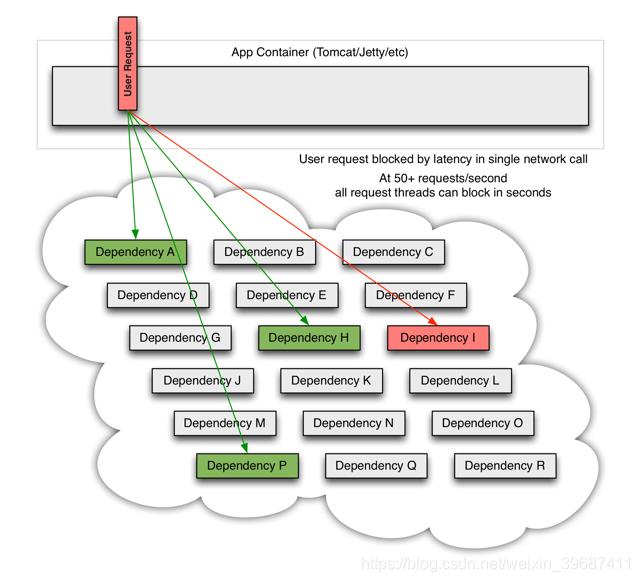
如果其中一个依赖发生延迟,当前请求就会被阻塞
出现这种情况后,如果没有应对措施,后续的请求也会被持续阻塞
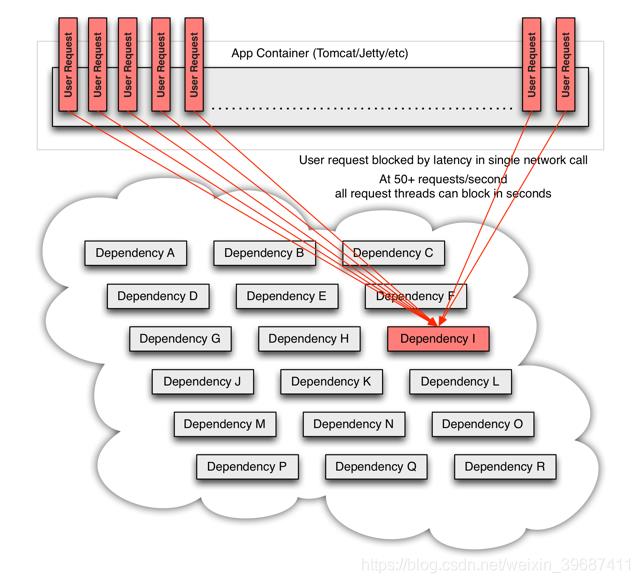
每个请求都占用了系统的CPU、内存、网络等资源,如果该应用的QPS较高,那么该应用所以的服务资源会被快速消耗完毕,直至应用死掉。如果这个出问题的依赖(Dependency I),不止这一个应用,亦或是受影响的应用上层也有更多的依赖,那就会带来我们前面所提到的服务雪崩效应。
所以,为了应对以上问题,就需要有支持服务隔离、熔断等操作的工具
二、Hystrix 简介
1、Hystrix具备哪些能力/优点?
在通过网络依赖服务出现高延迟或者失败时,为系统提供保护和控制
可以进行快速失败,缩短延迟等待时间和快速恢复:当异常的依赖回复正常后,失败的请求所占用的线程会被快速清理,不需要额外等待
提供失败回退(Fallback)和相对优雅的服务降级机制
提供有效的服务容错监控、报警和运维控制手段
2、Hystrix 如何解决级联故障/防止服务雪崩?
Hystrix将请求的逻辑进行封装,相关逻辑会在独立的线程中执行
Hystrix有自动超时策略,如果外部请求超过阈值,Hystrix会以超时来处理
Hystrix会为每个依赖维护一个线程池,当线程满载,不会进行线程排队,会直接终止操作
Hystrix有熔断机制:在依赖服务失效比例超过阈值时,手动或者自动地切断服务一段时间
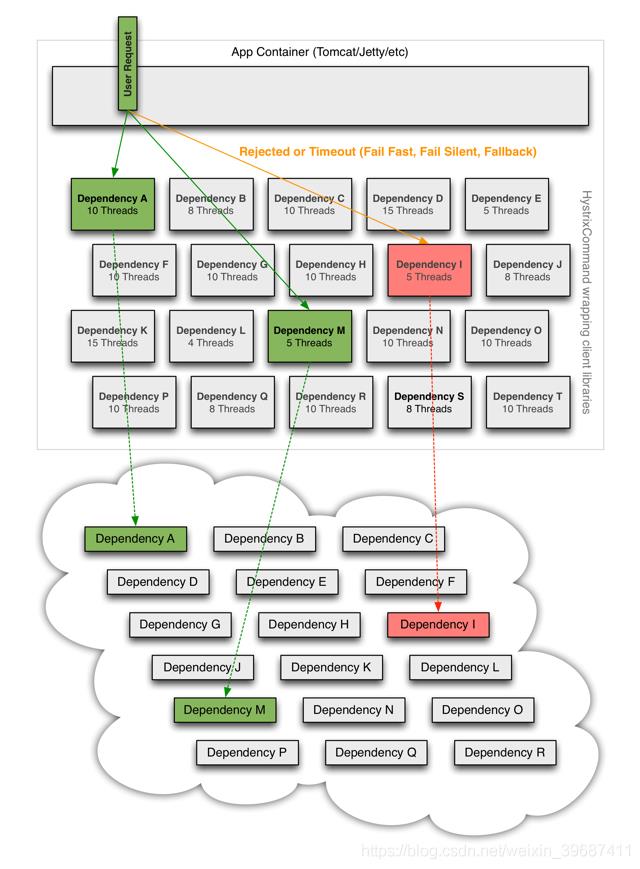
所以,当引入了Hystrix之后,当出现某个依赖高延迟的时候:
三、Hystrix 工作原理
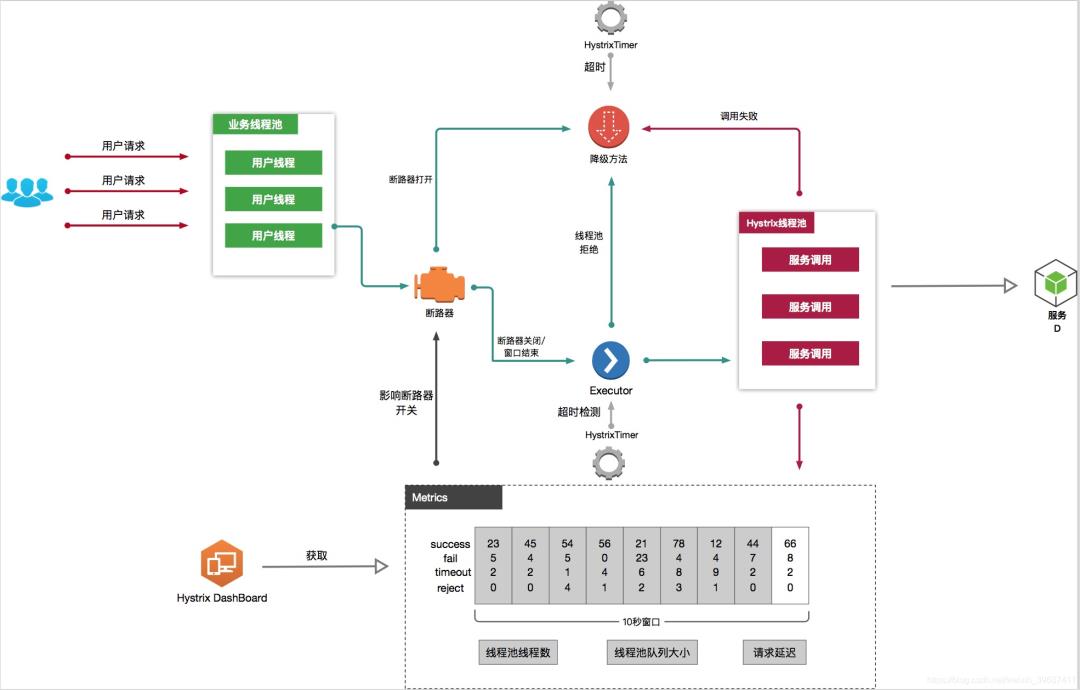
1、Hystrix工作流
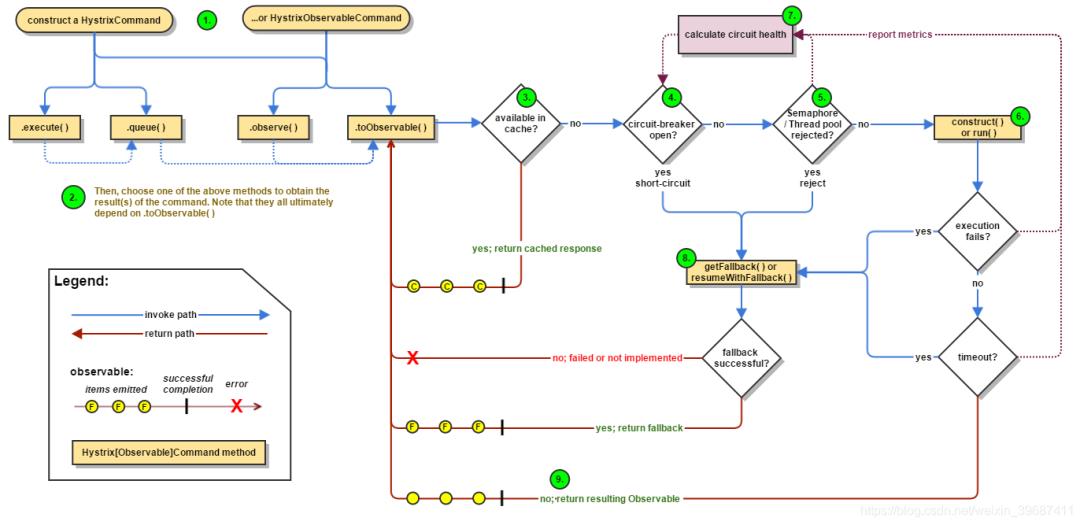
1、创建HystrixCommand 或者 HystrixObservableCommand 对象
2、执行命令execute()、queue()、observe()、toObservable()
3、如果请求结果缓存这个特性被启用,并且缓存命中,则缓存的回应会立即通过一个Observable对象的形式返回
4、检查熔断器状态,确定请求线路是否是开路,如果请求线路是开路,Hystrix将不会执行这个命令,而是直接执行getFallback
5、如果和当前需要执行的命令相关联的线程池和请求队列,Hystrix将不会执行这个命令,而是直接执行getFallback
6、执行HystrixCommand.run()或HystrixObservableCommand.construct(),如果这两个方法执行超时或者执行失败,则执行getFallback()
7、Hystrix 会将请求成功,失败,被拒绝或超时信息报告给熔断器,熔断器维护一些用于统计数据用的计数器。
这些计数器产生的统计数据使得熔断器在特定的时刻,能短路某个依赖服务的后续请求,直到恢复期结束,若恢复期结束根据统计数据熔断器判定线路仍然未恢复健康,熔断器会再次关闭线路。
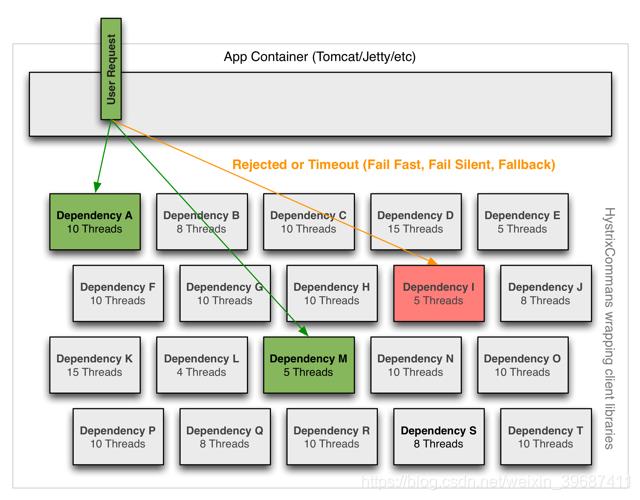
依赖隔离
Hystrix采用舱壁隔离模式隔离相互之间的依赖关系,并限制对其中任何一个的并发访问。
线程&线程池
客户端(通常指Web应用)通过网络请求依赖时,Hystrix会将请求外部依赖的线程与会将App容器(Tomcat/Jetty/…)线程隔离开,以免请求依赖出现延迟时影响请求线程。
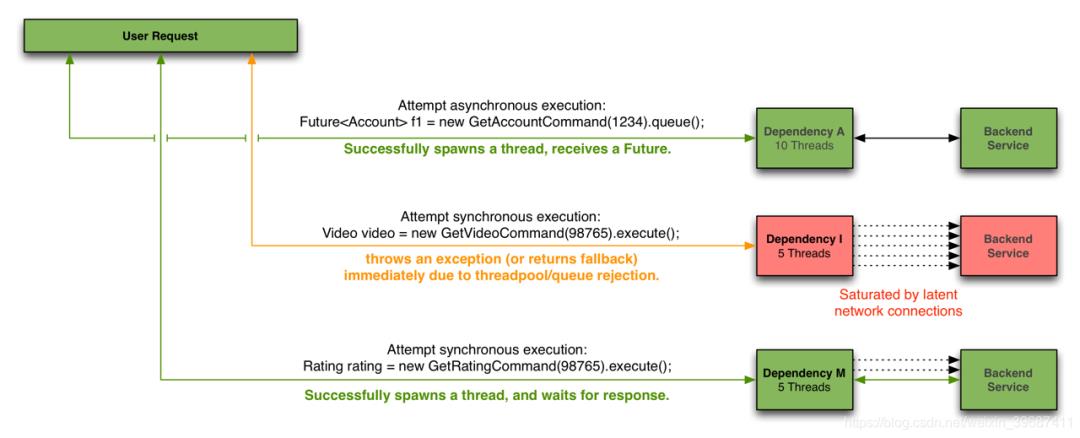
Hystrix会为每个依赖维护一个线程池,当线程满载,不会进行线程排队,会Return fallback或者抛出异常
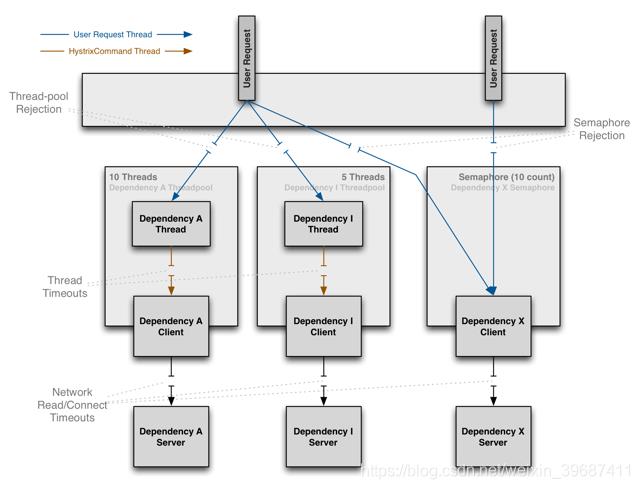
可能会有人有疑问,为什么不依赖于HTTP Client去做容错保护(快速失败、熔断等),而是在访问依赖之外通过线程&线程池隔离的方式做这个断路器(Hystrix)。
主要是以下几个方面:
不同的依赖执行的频率不同,需要分开来对待
不同的依赖可能需要不同的Client的工具/协议来访问,比如我们可能用HTTP Client,可能用Thrift Client。
Client在执行的过程中也可能会出现非网络异常,这些都应该被隔离
Client的变化会引起断路器的变化
所以,Hystrix这样设计的好处是:
断路器功能与不同的Client Library隔离
不同依赖之间的访问互不影响
当发生大量异常时,不会造成App Container的响应线程排队,并且当异常的依赖恢复正常后,失败的请求所占用的线程会被快速清理,不需要额外等待
为不支持异步的依赖提供了异步的可能
这样做的成本是,多了一些线程上的资源消耗(排队,调度和上下文切换),不过从官方给到的数据上可能,这个消耗完全可以接受。目前Netflix每天有100亿+的Hystrix命令执行,平均每个应用实例都有40+个线程池。每个线程池有5-20个线程 依然运行良好(不过这里 ken.io 不得不吐槽下,官方没有透露单个实例硬件配置)
官方给了一组测试数据,在单个应用实例60QPS,且每秒钟有350个Hystix子线程(350次Hystrix Command执行)的情况下。Hystrix的线程成本通常为0-3ms,如果CPU使用率超过90%,这个线程成本为有所上升约为9ms。相对于网络请求的时间消耗,这个成本完全可以接受。
四、备注
本文参考
https://github.com/Netflix/Hystrix/wiki
分布式追踪Sleuth工作原理
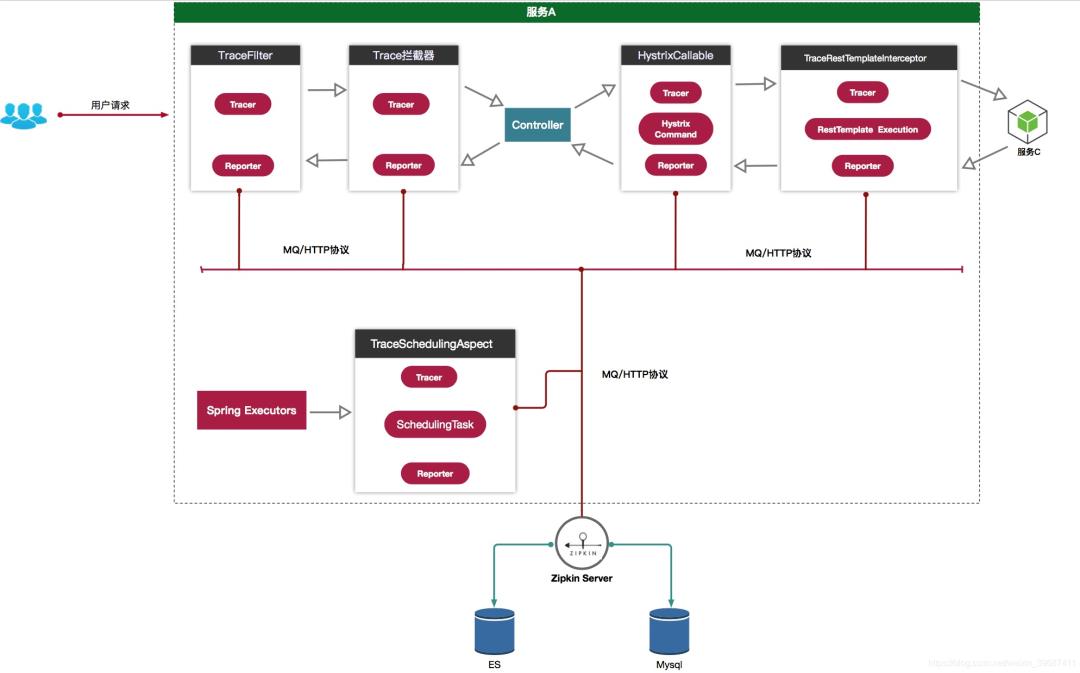
一、概述
在单体应用时代,接口缓慢能够被迅速定位和发现,而随着分布式微服务的流行,服务之间的调用关系越来越复杂,错中复杂的调用关系使得我们想找到某一个接口的效率缓慢变得非常困难,而分布式服务调用跟踪组件就解决了这个 问题。Sleuth是SprinCloud在分布式系统中提供追踪解决方案,zipkin是基于Google Dapper的分布式链路调用监控系统。先介绍下有关的专业术语,
sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网 络延迟
ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服 务端需要的处理请求时间
cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳 便可得到客户端从服务端获取回复的所有所需时间
二、功能开发实现
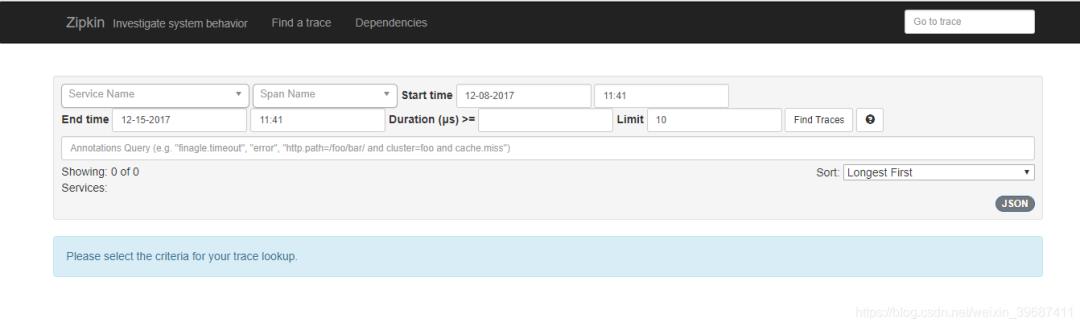
1.创建zipkin-server服务
zipkin-server主要作用是使用ZipkinServer 的功能,收集调用数据链,并提供展示页面供用户使用。创建普通的SpringBoot项目zipkin-server,在pom.xml文件中增加如下依赖
<dependencies>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
在ZipKinServerApplication主方法上添加@EnableZipkinServer注解,启用ZipkinServer功能。
@EnableZipkinServer
@SpringBootApplication
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
修改配置文件
spring.application.name=zipkin-server
server.port=9107
启动服务,可以看到链路监控页面,此时没有收集到任何链路调用记录。
2.给原先服务增加链路追踪支持
给eureka-provider、eureka-consumer、gateway三个服务增加如下依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
该依赖内部包含了两个依赖,等于同时引入了spring-cloud-starter-sleuth,spring-cloud-sleuth-zipkin两个依赖。
修改配置文件
#配置zipkin
#指定zipkin的服务端,用于发送链路调用报告
spring.zipkin.base-url=http://10.17.5.50:9107
采样率,值为[0,1]之间的任意实数,这里代表100%采集报告。
spring.sleuth.sampler.percentage=1
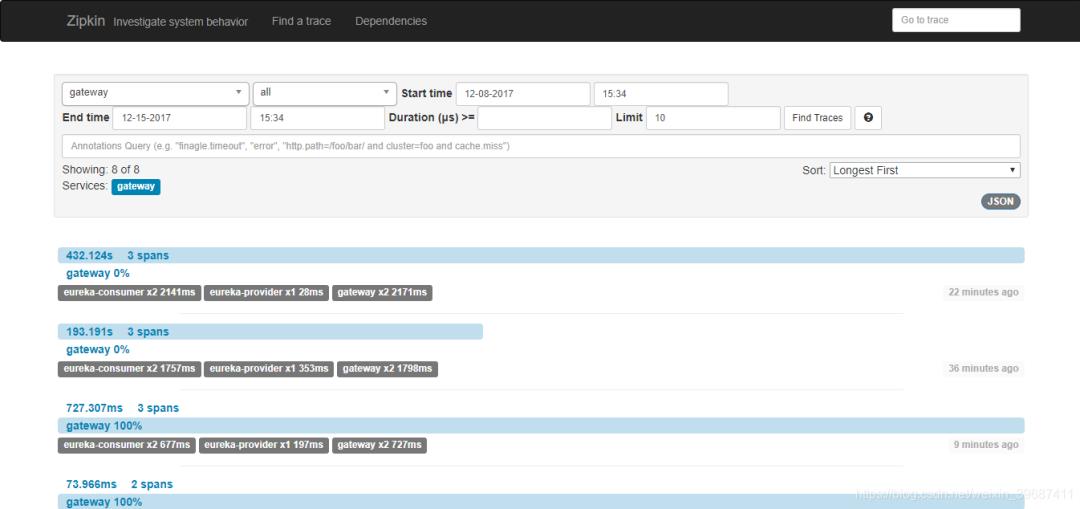
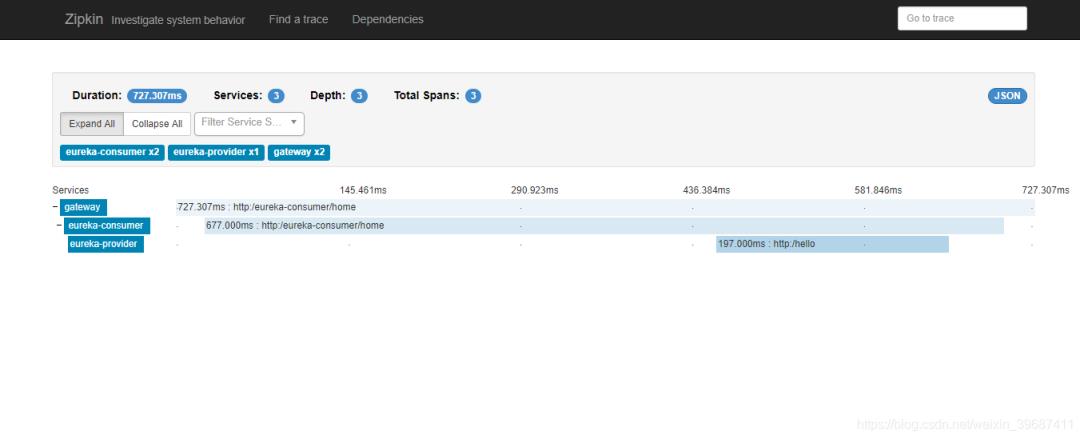
重新部署启动服务,调用zuul接口,观察zipkin-server页面,生成调用链路
三、小结
本文还只是基本的链路分析,如果生产上使用,还需要把监控内容持久化、把监控内容发送从http模式切换到MQ等改造,这些内容下次再详细介绍。
github地址:https://github.com/gengkangkang/springcloud.git
SpringBoot自动配置工作原理
Spring Boot的配置文件
初识Spring Boot时我们就知道,Spring Boot有一个全局配置文件:application.properties或application.yml。
我们的各种属性都可以在这个文件中进行配置,最常配置的比如:server.port、logging.level.* 等等,然而我们实际用到的往往只是很少的一部分,那么这些属性是否有据可依呢?答案当然是肯定的,这些属性都可以在官方文档中查找到:
https://docs.spring.io/spring-boot/docs/2.1.0.RELEASE/reference/htmlsingle/#common-application-properties
(所以,话又说回来,找资料还得是官方文档,百度出来一大堆,还是稍显业余了一些)
除了官方文档为我们提供了大量的属性解释,我们也可以使用IDE的相关提示功能,比如IDEA的自动提示,和Eclipse的YEdit插件,都可以很好的对你需要配置的属性进行提示,下图是使用Eclipse的YEdit插件的效果,Eclipse的版本是:STS 4。
以上,是Spring Boot的配置文件的大致使用方法,其实都是些题外话。
那么问题来了:这些配置是如何在Spring Boot项目中生效的呢?那么接下来,就需要聚焦本篇博客的主题:自动配置工作原理或者叫实现方式。
工作原理剖析
Spring Boot关于自动配置的源码在spring-boot-autoconfigure-x.x.x.x.jar中:
当然,自动配置原理的相关描述,官方文档貌似是没有提及。不过我们不难猜出,Spring Boot的启动类上有一个@SpringBootApplication注解,这个注解是Spring Boot项目必不可少的注解。那么自动配置原理一定和这个注解有着千丝万缕的联系!
@EnableAutoConfiguration
@SpringBootApplication是一个复合注解或派生注解,在@SpringBootApplication中有一个注解@EnableAutoConfiguration,翻译成人话就是开启自动配置,其定义如下:
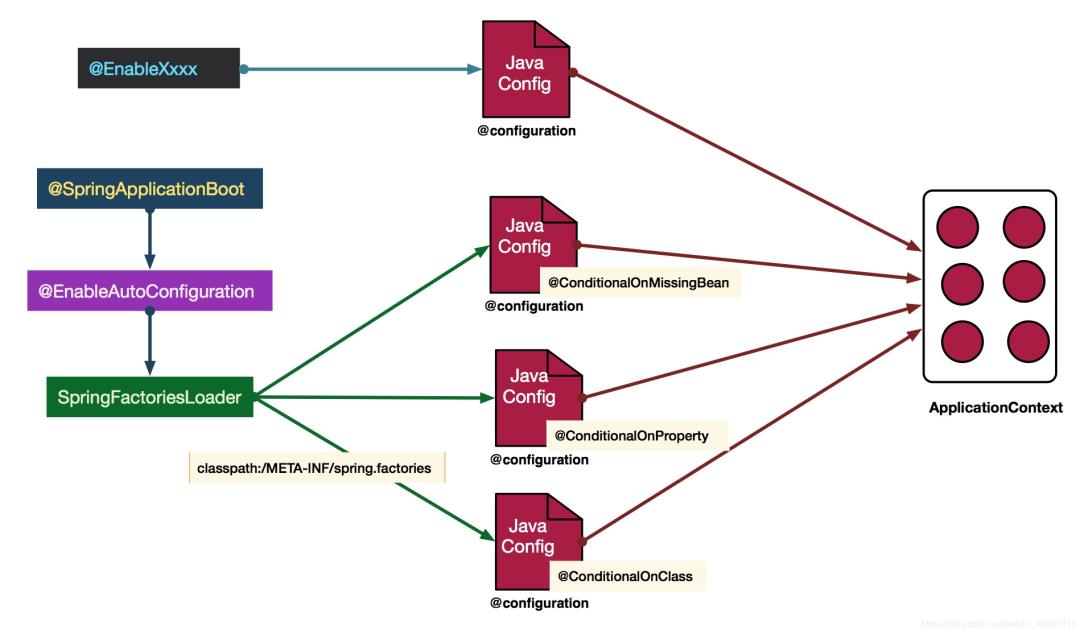
而这个注解也是一个派生注解,其中的关键功能由@Import提供,其导入的AutoConfigurationImportSelector的selectImports()方法通过SpringFactoriesLoader.loadFactoryNames()扫描所有具有META-INF/spring.factories的jar包。spring-boot-autoconfigure-x.x.x.x.jar里就有一个这样的spring.factories文件。
这个spring.factories文件也是一组一组的key=value的形式,其中一个key是EnableAutoConfiguration类的全类名,而它的value是一个xxxxAutoConfiguration的类名的列表,这些类名以逗号分隔,如下图所示:
这个@EnableAutoConfiguration注解通过@SpringBootApplication被间接的标记在了Spring Boot的启动类上。在SpringApplication.run(…)的内部就会执行selectImports()方法,找到所有JavaConfig自动配置类的全限定名对应的class,然后将所有自动配置类加载到Spring容器中。
自动配置生效
每一个XxxxAutoConfiguration自动配置类都是在某些条件之下才会生效的,这些条件的限制在Spring Boot中以注解的形式体现,常见的条件注解有如下几项:
@ConditionalOnBean:当容器里有指定的bean的条件下。
@ConditionalOnMissingBean:当容器里不存在指定bean的条件下。
@ConditionalOnClass:当类路径下有指定类的条件下。
@ConditionalOnMissingClass:当类路径下不存在指定类的条件下。
@ConditionalOnProperty:指定的属性是否有指定的值,比如@ConditionalOnProperties(prefix=”xxx.xxx”, value=”enable”, matchIfMissing=true),代表当xxx.xxx为enable时条件的布尔值为true,如果没有设置的情况下也为true。
以ServletWebServerFactoryAutoConfiguration配置类为例,解释一下全局配置文件中的属性如何生效,比如:server.port=8081,是如何生效的(当然不配置也会有默认值,这个默认值来自于org.apache.catalina.startup.Tomcat)。
在ServletWebServerFactoryAutoConfiguration类上,有一个@EnableConfigurationProperties注解:开启配置属性,而它后面的参数是一个ServerProperties类,这就是习惯优于配置的最终落地点。
在这个类上,我们看到了一个非常熟悉的注解:@ConfigurationProperties,它的作用就是从配置文件中绑定属性到对应的bean上,而@EnableConfigurationProperties负责导入这个已经绑定了属性的bean到spring容器中(见上面截图)。那么所有其他的和这个类相关的属性都可以在全局配置文件中定义,也就是说,真正“限制”我们可以在全局配置文件中配置哪些属性的类就是这些XxxxProperties类,它与配置文件中定义的prefix关键字开头的一组属性是唯一对应的。
至此,我们大致可以了解。在全局配置的属性如:server.port等,通过@ConfigurationProperties注解,绑定到对应的XxxxProperties配置实体类上封装为一个bean,然后再通过@EnableConfigurationProperties注解导入到Spring容器中。
而诸多的XxxxAutoConfiguration自动配置类,就是Spring容器的JavaConfig形式,作用就是为Spring 容器导入bean,而所有导入的bean所需要的属性都通过xxxxProperties的bean来获得。
可能到目前为止还是有所疑惑,但面试的时候,其实远远不需要回答的这么具体,你只需要这样回答:
Spring Boot启动的时候会通过@EnableAutoConfiguration注解找到META-INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConfiguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如:server.port,而XxxxProperties类是通过@ConfigurationProperties注解与全局配置文件中对应的属性进行绑定的。
通过一张图标来理解一下这一繁复的流程:
图片来自于王福强老师的博客:https://afoo.me/posts/2015-07-09-how-spring-boot-works.html
总结
综上是对自动配置原理的讲解。当然,在浏览源码的时候一定要记得不要太过拘泥与代码的实现,而是应该抓住重点脉络。
一定要记得XxxxProperties类的含义是:封装配置文件中相关属性;XxxxAutoConfiguration类的含义是:自动配置类,目的是给容器中添加组件。
而其他的主方法启动,则是为了加载这些五花八门的XxxxAutoConfiguration类。
粉丝福利:实战springboot+CAS单点登录系统视频教程免费领取
以上是关于必看!超详细的SpringCloud底层原理的主要内容,如果未能解决你的问题,请参考以下文章