惊喜不断,Oracle也有了自己Sharding
Posted 恒生DBA公社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了惊喜不断,Oracle也有了自己Sharding相关的知识,希望对你有一定的参考价值。
【new friends】点击标题下面蓝色字“恒生DBA公社”关注。
【old friends】点击右上角,转发或分享本页面内容。
关注福利:
关注恒生DBA公社,回复18c,即可得到Oracle 18c outline官方手册
前 言
在12cR2之前的版本中,我们会用一些昂贵的机器让Oracle数据库得到高性能,比如IBM的小型机P780, E880, Exadata一体机等等。那有没有这样一种可能性,Oracle可以依靠堆积几台相对廉价的机器,实现海量数据的处理,应用性能的提升呢?
有需求就有市场,随着互联网行业的发展,随着越来越多客户上了12C,Oracle也不断推陈出新,为了满足这个需求,Oracle 就带给了我们一个大大的惊喜:sharding(数据分片)
什么是sharding(数据分片)?
Oracle sharding(数据分片) 是oracle 12.2新推出的功能,sharding技术可以在数据层将数据平行的分配到多个独立的数据库中。
每个数据库都位于独立的服务器上,具有专用的本地资源(CPU,内存,磁盘等),是一种shared-nothing的方式。每个独立的的数据库称为shard,所有的shard构成了一个逻辑数据库(SDB)。
简单来说,sharding近似于分区表,不过每个分区都存储在了单独的数据库之中,真正意义上实现了分区的隔离。
可能有的小伙伴发现这不是MongoDB的分片功能吗? 没错,Oracle sharding和MongoDB分片功能原理基本相同,可见Oracle也在不断学习其他类型数据库的优势。
Oracle sharding(数据分片)有哪些组件?
Shard database(SDB):SDB是由多个物理独立的数据库组成的数据库池,是一个逻辑上的数据库。
Shard:SDB中每个物理独立的的数据库都称为一个shard,每个shard具有相同的表结构,但存储着不同的数据集
Shard catalog:是一个数据库,存储着SDB的配置信息,提供shard自动部署、集中管理、跨shard查询等核心功能。
Global service:数据库的服务(service),用于访问SDB中的数据
Shard director:可以根据客户端请求分配对应shard的监听,起到路由的作用
GDSCTL:命令行管理接口
重点了解oracle sharding的核心:Sharded table
被分片的表称为sharded table,也是oraclesharding的核心。
sharded table的集合称为表家族(Table Family)。
所谓表家族就是指sharded table之间是父-子关系,一个表家族中没有任何父表的表叫做根表(root table),每个表家族中只能有一个根表。
在12.2,在一个SDB中只支持一个表家族。在表家族中的所有sharded table都按照相同的sharding key(主键)来分片,主要是由root table的sharding key决定的。表家族(Table Family)中有相同sharding key的数据存储在同一个Chunk中,这样方便以后的数据移动。
下面就通过Oracle提供的demo来介绍一下sharded table中的重点内容
父-子关系?
表家族有两种方式可以形成父子关系
1.主外键关联的方式

Customers为根表,orders和lineItems通过外键(CustId)与cutomers关联,形成了表家族
2. 建表时通过parent关键字指定父表
CREATE SHARDED TABLE Orders
( OrderNo NUMBER
, CustId VARCHAR2(60) NOT NULL,
, OrderDate DATE
)
PARENT customers --指定父表customers
PARTITION BY CONSISTENT HASH (CustId)
TABLESPACE SET TSP_SET_1
PARTITIONS AUTO
;
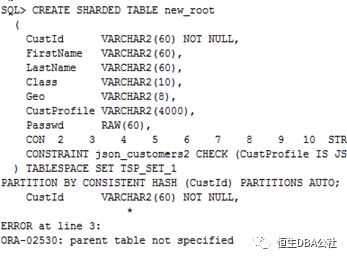
一个SDB中只支持一个表家族且只能有一个根表
SDB中已经存在根表customers,再创建新的根表new_root就会报错
Chunk?
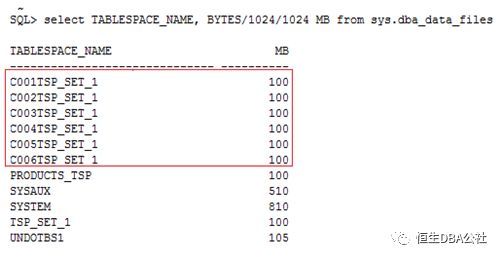
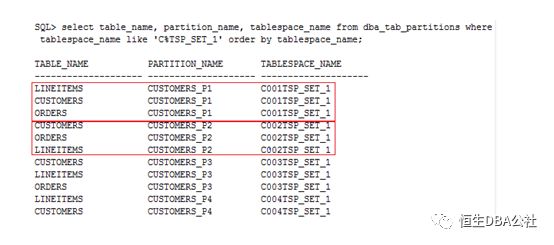
在SDB中表家族的一组分区会存放在一个chunk中,如customers、orders、lineItems三张表中都有CustId 为1~100的数据,如果以CustId 作为分区条件,那么这些数据就会存储在同一个chunk中。
Chunk不会跨shard存储,同时也是re-sharding时的最小单位,这样有效的避免了cross shard join的发生
chunk的概念虽然是新提出的,但是其物理上就是在shard上自动创建的表空间,chunk的数量是在创建shard catalog指定的,在部署完成后会按照数量平均分配在各个shard中
Shard1
Shard2
Oracle Sharding的路由选择
直接路由:
应用程序初始化时,在应用层/中间件层建立连接池,连接池获取所有shard节点的sharding key范围,并且保存在连接池中,形成shard topology cache(拓扑缓存),Cache提供了一个快速的方法直接将请求路由到具体的shard。
客户端请求时指定shard key,直接从连接池获取连接,这种情况下不经过shard director/catalog数据库,直接连接到对应的shard。
如:
Sqlplus app_schema/oracle@'(description=(address=(protocol=tcp)(host=db1)(port=1522))(connect_data=(service_name=sharding_director.shdb.oradbcloud)(region=region1)(SHARDING_KEY=james.parker@x.bogus)))'
代理路由:
如果客户端执行select或者DML时不指定shard key或者执行聚合操作(比如 group by),那么请求发送到Catalog数据库,根据matadata信息,SQL编译器决定访问哪些shards。
总结
Oracle Sharding的优势
失败隔离: 由于Shard是一种shared-nothing技术,每个shard使用独立的硬件,因此一个shard节点出现故障,只会影响到这个shard存放的数据,而不会影响到其他shard。
按照地理位置分布数据:可以选择根据地理位置不同,将数据存储在不同的shard。
滚动升级:选择不同时间升级不同的shard。比如同一时间只升级一个或一部分shard,那么只有这些升级的shard中存储的数据受到影响,其他的shard不受到影响,可以继续提供服务。
云部署:Shard非常适合部署在cloud。
Oracle Sharding的问题
Sharding本身是没有高可用架构的,如果一个shard库宕机很可能引起整个SDB出现问题,所以oracle建议sharding搭配DG或OGG使用,这无疑会加大硬件及维护成本
Sharding其实相当于升级版的分区表,如果数据量没有达到一定规模,使用sharding的优势不会很明显
以上是关于惊喜不断,Oracle也有了自己Sharding的主要内容,如果未能解决你的问题,请参考以下文章