红色警报——Oracle宕机潮来临,快快行动起来!
Posted twt企业IT社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了红色警报——Oracle宕机潮来临,快快行动起来!相关的知识,希望对你有一定的参考价值。
作者:黄远邦(小y),就职于北京中亦安图科技股份有限公司,任数据库团队技术总监。 长期活跃于国内多家银行总行生产数据中心,提供Oracle第三方服务,解决过无数疑难问题,在业内具有极佳的口碑。
红色警报!
2月14日,情人节前夕,某数据中心一套Oracle 11.2.0.4 RAC宕了!
隔了几天,又有一套RAC宕了!
几天后,紧接着又有一套RAC宕了!
作为运维的你,听到其他客户出现这样的宕机潮时,是不是心底会泛起一阵莫名的恐慌?
那么问题来了,贵司的数据中心到会不会也将出现类似的宕机潮呢?
这些故障是什么原因引起的呢?
这股宕机潮会继续疯狂延续下去么?
如果不能及时找到问题真相,那么小y相信,这股宕机潮还会继续延续下去!
贵中心的Oracle数据库也许正在越来越接近宕机了!可怕的是,你可能还没有察觉到……
这绝对不是危言耸听!
这是在一家超大型数据中心发生的真实故障,在不到两周的时间里,三套不同Oracle数据库先后出现了实例异常终止的情况!
无独有偶,小y服务的其他客户那也陆续出现了宕机的前兆!好在及时发现并处理。
眼看宕机潮来临,看小y如何化繁为简,帮助客户一起解开问题的真相。
真相揭开后,您也许不难发现,这是一个共性的问题!
因此小y不敢怠慢,赶紧拿出来与大家分享,拉响了这次红色警报!
小y将带领大家一起去经历一场数据中心Oracle数据库宕机潮的分析之旅。
01
问题来了
小y,出事了,今天有个系统,早上RAC宕了一个节点,晚上又宕了一个节点,操作系统没有重启,只是数据库实例crash掉了!目前已经开了SR,但现在原因还没确定,领导很重视这个问题,明天你能过来一趟一起查下么?领导希望明天就能查清问题原因。
对了,这是一套11.2.0.4 RAC,打了最新的PSU的!
来电的是国内一家超大型的国有银行,本身就拥有一批水准很高的ORACLE DBA。
通常找到小y的问题,都是些奇奇怪怪的复杂问题,如果只懂数据库,而对操作系统/中间件/存储等方面缺乏足够的了解的话,很多时候是无法解决他们的复杂问题的。
看来,一场硬仗,在所难免……
2
分析过程
2.1 先看看数据库alert日志
第二天早上,到了客户现场,首先客户向我介绍了昨天发生故障的情况。
2月12日早上9点左右,11.2.0.4的RAC节点1宕了,晚上22点,节点2 宕了。
客户帮助登陆到系统后,小y首先检查了数据库的alert日志,如下图所示:
不难看到:
2017/2/12 8:53:49,由于数据库的后台进程ASMB与ASM实例通讯失败,ASMB进程终止了数据库实例,因此,小y需要继续检查ASM的alert日志,以便查看asm实例是否先出现了问题,才导致数据库crash了。
2.2 紧接着查看ASM alert日志
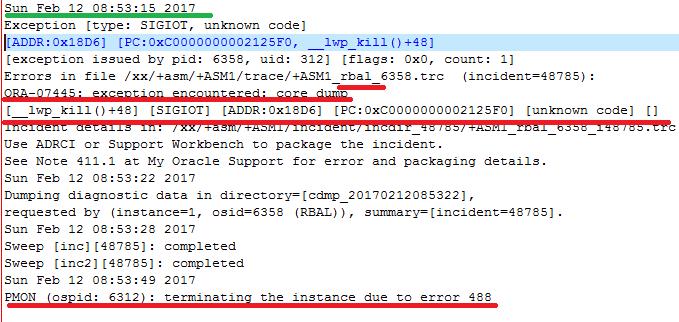
不难看到:
在数据库crash前的几十秒之前, 8:53:15,ASM实例的rbal后台进程,遇到了ORA-07445的错误,rbal进程core dump,因此pmon进程终止了ASM实例。
也就是说,ASM实例rbal进程出现ORA-7445错误,导致ASM实例终止,由于数据库实例依赖ASM实例,因此数据库实例被终止。ASM实例具体的ORA-7445错误是:
小y刚一开始看到这个错误的时候,无奈的摇了摇头,遇上麻烦了!
为什么小y会有如此感慨呢?资深的DBA,也许看到这个错误时,可能会同样的感慨!
因为这个错误出错的调用lwp_kill是一个太普通不过的调用了,在该函数core Dump的原因可能有一万种,甚至都不止,metalink上不可能记录所有的可能…..
不过,小y还是很有信心的,只要调整到修正学院派模式,未知问题也可以很快查清。
不错,只要集中精力分析出这个ORA-7445 [__lwp_kill()+48] [SIGIOT]错误的原因,也就解开了宕机潮系列问题的真相。
2.3 不妙的开始
看到这里,小y和之前看过该问题的几个工程师做了一下简单的沟通。
沟通的结果是两个字,不妙。
之前他们几个比较资深的工程师已经看过该问题,也在metalink上找过是否有类似的问题,结果显示,通过call stack匹配,一样的case有过一些,但case没有直接的结论,客户已经开了一个SR到gcs,目前正在分析中……
客户希望今天出一个大概的结果,时间紧急。
客户他们了解小y的习惯,再紧急,也会先抽空去抽上一根烟…
小y和客户打了个招呼后,下楼抽烟去了。
2.4 正经地科普一下
趁着抽烟的缝隙,小y捋了一下思路。
也许有些同学对上面的有些术语比较困惑,什么是call stack,什么是ora-600和ora-7445错误。小y发现,很多DBA都是人云亦云,这里,小y稍微给大家科普下。
知识点1:什么是ORA-600错误?
有同学会说,ORA-7445错误和ORA-600错误一样,属于ORACLE内部错误。
以小y来看,这么理解其实并不准确!ORA-600错误是内部错误,但7445错误则不尽然!
ORA-600是ORACLE源码中捕获的异常,通常发生在某个特定的函数,相对比较具体,通常是ORACLE BUG。
知识点2:什么是ORA-7445错误?
ORA-7445错误和ORA-600错误就不一样了。
当 ORACLE进程在运行过程中收到来自操作系统一个严重的信号signal,则会报ORA-7445错误。操作系统自身会捕获进程的一些非法的操作,例如当一个进程尝试往无效的内存位置去写,出于保护操作系统的目的,操作系统将会向进程发送一个严重的信号,常见的例如SIGBUS和SIGSEGV信号,所以会看到进程core Dump现象的出现。
ORA-7445错误可以发生在代码的任意位置,出错的精确位置需要通过core文件来定位。
从这段话不难看出,ORA-7445错误的可能性较多,本质是操作系统向进程发送一个严重的信号,那么原因既可能是数据库的BUG,也有很大可能是来自操作系统的某些异常。
这也就是ORA-7445错误的分析比ORA-600错误更难的原因。
知识点3:什么是call stack?
我们在谈论bug或缺陷defect的时候,都会有一个疑问,这个BUG的触发条件是什么呢?
BUG通常都是某一种特殊的场景下触发的,call stack就是函数的调用轨迹,这个调用轨迹就表示了BUG的具体触发场景。
这就是小y前面提到的,在小y之前,他们已经通过核对call stack去匹配BUG了。
只不过可惜的是,MOS上出现过相同call stack的case没有最后下结论,因此无法参考……
2.5 从call stack开始查找真相
小y接下来打开出现ORA-7445错误的rbal进程的trace文件,找到call stack部分,如下所示
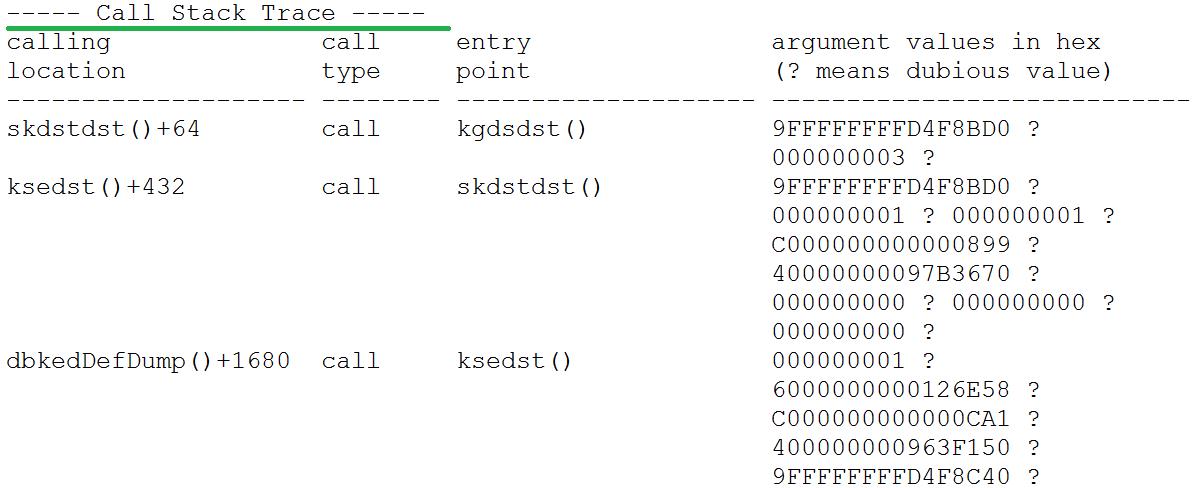

首先找到ORA-7445错误的第一个中括号出现的函数,即lwp_kill。
也就是说rbal进程core dump是在__lwp_kill这个系统调用中发生的。
Lwp就是Light Weight process即轻量级进程,kill就是终止。
细心的同学,可以看到,lwp_kill前面带了两个下划线,说明不是oracle代码中自己调用的函数,而是函数内部调用的函数,属于递归的函数了。
那么小y是如何知道这些调用是什么意思的呢?
其实很简单,这些都是来自操作系统的标准调用,度娘或者google一下就好了。
Trace文件中,call stack的调用是从下往上看,下面的函数先执行,上面的函数后执行。
这个错误太普遍了!是一个广义的错误!很多地方异常,都可能调用lwp_kill来终止进程。
因此分析这个函数,没有什么意义,我们需要继续往下看,如下图所示

1) 调起lwp_kill的函数是pthread_kill,这个函数的作用向某个线程传递一个信号,也是一个递归函数,继续往下看
2) _raise,向正在执行的程序发送一个信号,raise调起了pthread_kill
3) abort()函数,从名字看就是终止, abort()函数会导致进程的异常终止,除非来自操作系统的进程终止信号即SIGABRT信号被捕捉并且信号处理句柄没有返回
4) _assert(),其作用是如果它的条件返回错误,则终止程序执行,简单来说就是程序做某件事情,遇到了错误,需要终止程序执行。
到这里,不难看到,函数的调用轨迹是
这段call stack,用大白话来说,就是:
rbal进程在执行过程中遇到了错误,因此终止了rbal进程。
那么到底遇到了什么错误呢?为什么需要继续往下看其他call stack
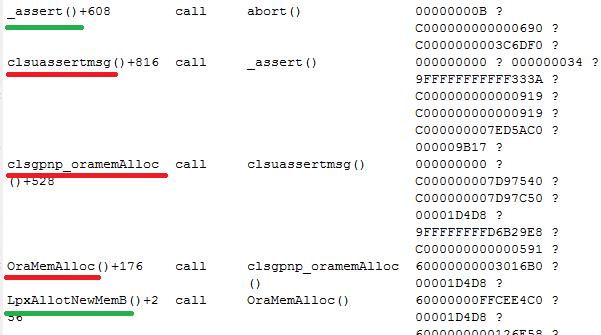
不难看到:
_Assert()是一个递归的调用,将其调起来的函数是clsuassertmsg。
这个函数不带下划线,是oracle代码中自己的函数名,显然在度娘或google就查不到了……
那么不妨就跟着小y来猜一猜吧。
拆开来看,即clsu+assertMsg,也就是遇到了某个错误,assert表示遇到了某个错误。
再往下看,是clsgpnp_oramemAlloc,不难看出,oramemAlloc就是分配内存,和gpnp相关模块分配内存有关系。
结合前面的call stack,我们来总结一下:
Rbal进程在执行clsgpnp_oramemAlloc函数来进行分配内存的时候遇到了某个错误,因此发生了coreDump,也就是ORA-7445错误,继而导致ASM和数据库实例先后crash。
2.6 为什么内存无法分配呢?
到这里,我们实际上已经知道了,oracle在执行到clsgpnp_oramemAlloc这处代码的时候,出现了错误,具体是什么错误呢?这个才是关键啊!但是,有办法知道是什么错误么?
oracle为我们抛出了一个lwp_kill的ORA-7445错误,但是我们真正关心的是clsgpnp_oramemAlloc这个函数到底遇到了什么错误!
如果trace里要告诉我们是什么错误,那有多好啊!太可惜了!?
很多人也许分析到了这里,就陷入僵局了!
实际上小y只读了几分钟的trace文件,就找到问题的真相了。
大家不妨也停下来思考下一两分钟,如果是你,你会怎么往下查……
2.7 慢慢接近真相
小y的方法很简单,用正常人的思维/生活化的语言来分析就可以。
表面上,出现core dump时的调用是lwp_kill,但真正出现问题的oracle函数是clsgpnp_oramemAlloc。显然,我们需要知道这个函数去分配内存的时候到底报了什么错误!!记住,需要证据,而不是猜!
有人会说,我们在trace中以clsgpnp_oramemAlloc关键字查找不就可以了么?
可惜的是,那你也许这么查找,最终会发现一无所获…
是你错了么?
不是的!是你方法不对!
小y采用的方法是将clsgpnp_oramemAlloc关键字截取前半截(一会您就知道为什么了)。
这里查找clsgpnp_oram关键字,结果如下

可以看到:
真正出现问题的oracle函数是clsgpnp_oramemAlloc,
这个函数去分配内存的时候报了无法分配120K内存的错误!failed to allocate 120024 bytes.
看到这张图,大家理解为什么需要截断真正错误的函数名来作为查找的关键字了吧!
因为函数名字换行了,如果以整个函数作为关键字,则可能查找不到!
这算是小y为大家贡献的一点小技巧和经验提示吧。
这里,也许也有人说:为什么不能直接猜clsgpnp_oramemAlloc这个函数去分配内存的时候报的错误呢?最可能的不就是无法分配内存么?
确实如此,但也不仅如此。
因为分配内存出错,可能性太多了,绝不是你想象的无法分配内存的那几种可能!
还记得小y以前文章中曾经提到过的修正学院派模式么?
如果采用猜的方法,结果是无法说服客户和自己,无法形成完整的证据链,是“野路子”的典型表现之一。小y这些年面试过不少人,结果不理想,绝大部分人其实都是野路子,野路子的解决问题,典型的就是在解决问题时东一榔头,西一棒子,靠运气。而不是学院派的步步为营。面对复杂问题时,野路子就会抓襟见肘了。
2.8 真相浮出水面
Oracle的函数clsgpnp_oramemAlloc,去分配内存的时候报了无法分配120K内存的错误!failed to allocate 120024 bytes.
到这里,相信大家一定跃跃欲试了!想试试自己的身手,毕竟看到了这个错误后,问题被进一步缩小范围了!
1) 是不是机器内存不足导致clsgpnp_oramemAlloc函数无法分配内存?
答案是NO,首先从监控数据/oswatcher中可以看到,机器内存还很富余。
2)是不是 操作系统ulimit内存方面设置的比较小呢?
答案是NO,ulimit配置正常
难道我们方向错了?
小y说过,如果只懂数据库,而对操作系统/中间件/存储等方面缺乏足够的了解的话,很多时候是无法解决大型数据中心那些复杂问题的。
查看宕机前的RBAL进程的内存消耗,如下图所示

这是一个HPUX 11.31 ia64的操作系统(实际上该问题与操作系统无关),
我们调出glance的历史,不难看到,Res Mem达到了4209480K,即4G左右。
听到4G这个词,是不是想到了些什么呢?没错,像是一个限制!
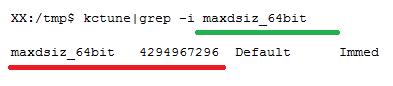
从上图可以看到,操作系统的maxdsize_64bit参数设置的正是4G,即单个进程的data最大只能到4G!
为什么RBAL进程内存用那么多内存?
显然,RBAL进程存在内存泄露的情况。正常而言,rbal进程的内存在100M以上。
我们通过检查历史数据,确认了rbal进程存在内存该情况!
是什么触发rbal进程内存泄露呢?
通过分析和比对,发现该库数据库有一个和其他数据库不一样的地方:
ASM alert日志中频繁的发生voting File relocation的情况,如下所示。
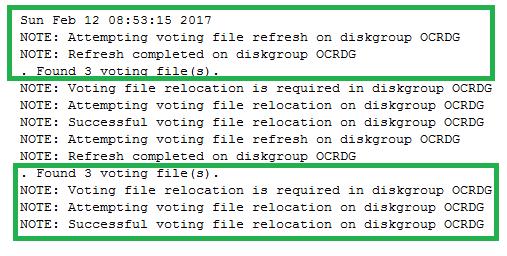
最终,在解决了voting File relocation的情况后,rbal进程的内存不再继续增加,问题得到了根本解决。之后,客户自己也申请到了一个patch.
2.9 宕机潮事件还原
通过阅读ORA-7445的call stack,小y化繁为简,还原了事件的发生过程。
1、为什么ASM rbal进程出现 ORA-7445[lwp_kill]错误后进程core Dump?
因此ASM实例 rbal后台进程存在内存泄露,当内存泄露到OS对单个进程的限制之后,进程无法分配内存而crash,继而先后导致asm实例和数据库实例crash
2、为什么会导致宕机潮
因为rbal进程内存泄露的速度差不多,在一个维护日中启动的多套数据库,经过小一年的时间后,也就差不多同时到了OS对单个进程的限制,因此先后发生了“宕机潮”
事实上,在第一套出现宕机的时候,小y已经协助客户查明了ASM rbal进程内存泄露的问题,只是没来得及全面梳理和整改所有系统,在此期间又先后发生了另外两套RAC的宕机。
3、一定会出现宕机么?
不一定,如果操作系统对单个系统的使用没有上限,则不会出现宕机,但会出现rbal进程将整个系统内存耗尽的情况,如果不及时监控,可能导致性能和无法telnet/ssh的情况。
简而言之,同一个问题,但在不同的OS配置下会表现出不同的故障现象!
4、rbal进程core dump一定是出现在clsgpnp_oramemAlloc整个函数么?
显然,如果内存泄露到了OS单个进程的限制,无论哪个需要分配内存的函数,都可能遇到无法分配内存继而coreDump的情况!因此,答案是不一定。这就是一个故障,可能有多个不同故障现象,但本质都是一回事!
5、rbal进程内存泄露只发生在HPUX么?
NO!我们不仅在HPUX上发现了该问题,其他客户的AIX环境下,RBAL进程的内存已经使用了8G,并且还在持续上升。这个问题不区分平台,目前确认受到影响的版本是11.2.0.4!其他版本我们还在陆续确认。
--------
红色警报响起!
11.2.0.4,一套Oracle RAC宕了!
隔了几天,另外一套RAC也宕了!
没过几天,紧接着又有一套其他RAC宕了!
详细原因请细读上面“宕机潮事件还原”章节的分析
1、小y在这里向大家郑重提示一个较大的风险:
Oracle 11.2.0.4版本的RAC,ASM的rbal后台进程存在内存泄露的情况,将可能导致宕机潮,目前已经有多个客户出现该情况,影响了包括HPUX/AIX/LINUX等在内的操作系统。
2、建议
建议按照下列方法全面梳理是否存在该情况,并增加进程一级内存使用情况的监控。
1) ps –elf|grep –i asm_rbal或者ps aux,正常而言在100M以上,通过比对ASM的其他后台进程即可知晓
2) select * from v$version
3) 查看asm alert 日志中是否出现下列信息
如果检查有类似问题,可以点击阅读原文,联系小y,小y也将在后续分享解决方法。
以上是关于红色警报——Oracle宕机潮来临,快快行动起来!的主要内容,如果未能解决你的问题,请参考以下文章
Go Fun共享汽车北三环大明宫(办公家具)商城站点今日开通