深入并行:从数据倾斜到布隆过滤深度理解Oracle的并行
Posted 数据和云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入并行:从数据倾斜到布隆过滤深度理解Oracle的并行相关的知识,希望对你有一定的参考价值。
陈焕生
Oracle Real-World Performance Group 成员,senior performance engineer,专注于 OLTP、OLAP 系统 在 Exadata 平台和 In-Memory 特性上的最佳实践。个人博客 http://dbsid.com 。
编辑手记:感谢陈焕生授权我们发布他的精品文章,Sidney撰写这个系列的文章时间跨度也有两年,下篇刚刚出炉,我们先从他去年投稿的第一篇开始。
上一篇请阅读:
数据倾斜是指某一列上的大部分数据都是少数热门的值(Popular Value)。Hash join 时, 如果 hash join 的右边连接键上的数据是倾斜的, 数据分发导致某个 PX 进程需要处理所有热门的数据, 拖长sql 执行时间, 这种情况称为并行执行倾斜。
为了演示数据倾斜和不同分发的关系, 新建两个表, customer_skew 包含一条 c_custkey=-1 的记录, lineorder_skew 90%的记录, 两亿七千万行记录 lo_custkey=-1.

Replicate 方式,不受数据倾斜的影响
测试 sql 如下:
select /*+ monitor parallel(4) */
sum(lo_revenue)
from
lineorder_skew, customer_skew
where
lo_custkey = c_custkey;
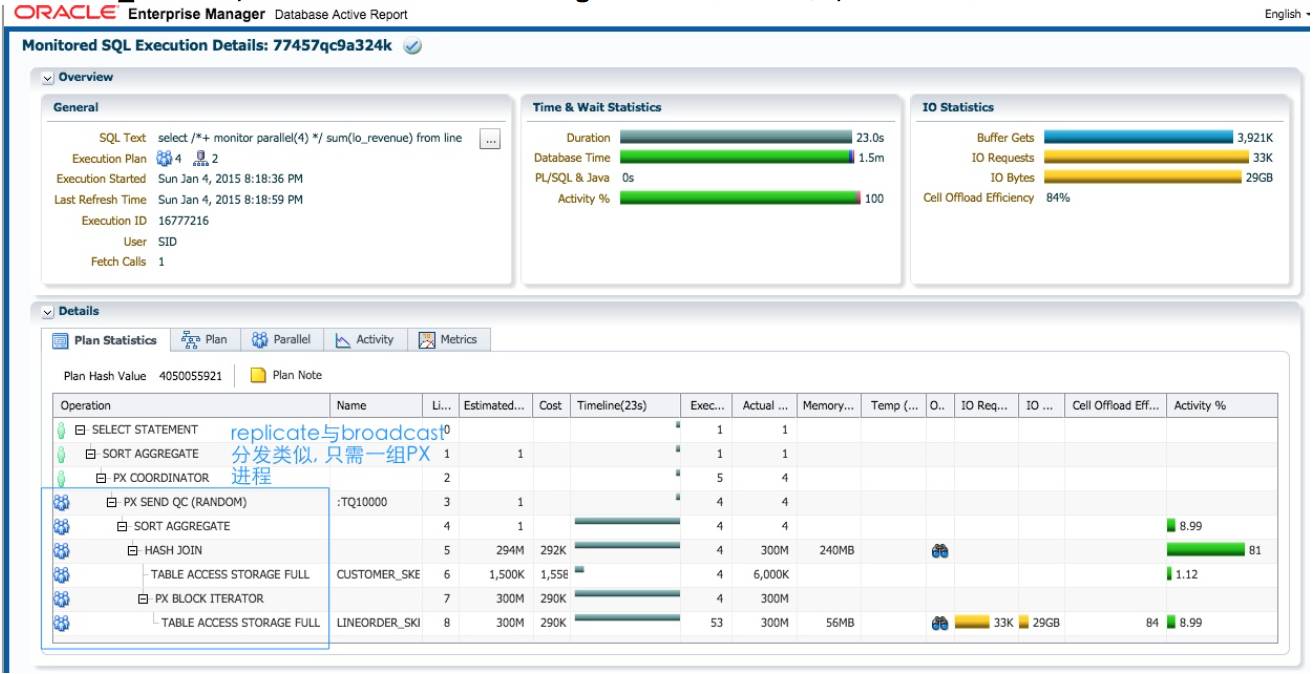
4个蓝色的PX进程消耗的dbtime是平均的,对于replicate方式, lineorder_skew的数据倾斜并 没有造成 4 个 PX 进程的执行倾斜。
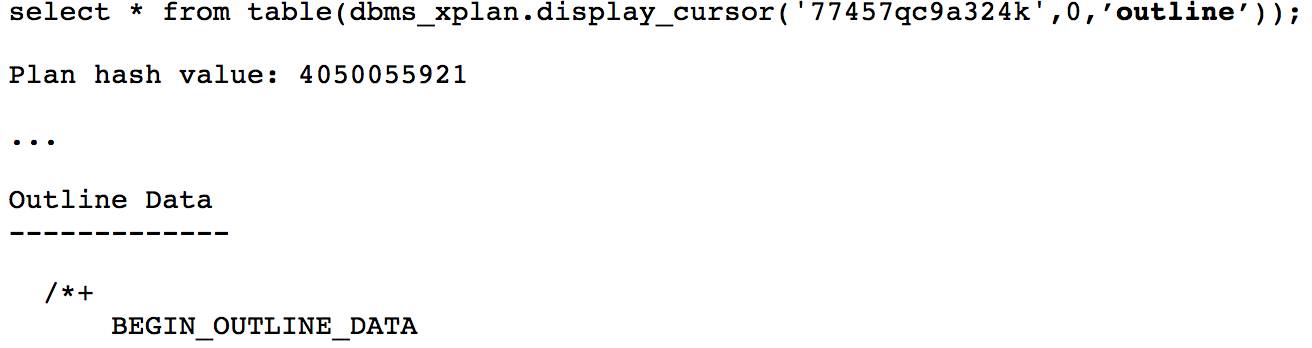
当优化器使用 replicate 方式时, 可以通过执行计划中 outline 中的 hint PQ_REPLICATE 确认. 以下 部分 dbms_xplan.display_cursor 输出没有显示, 只显示 outline 数据。

Hash 分发,数据倾斜造成执行倾斜
通过 hint 使用 hash 分发, 测试 sql 如下:

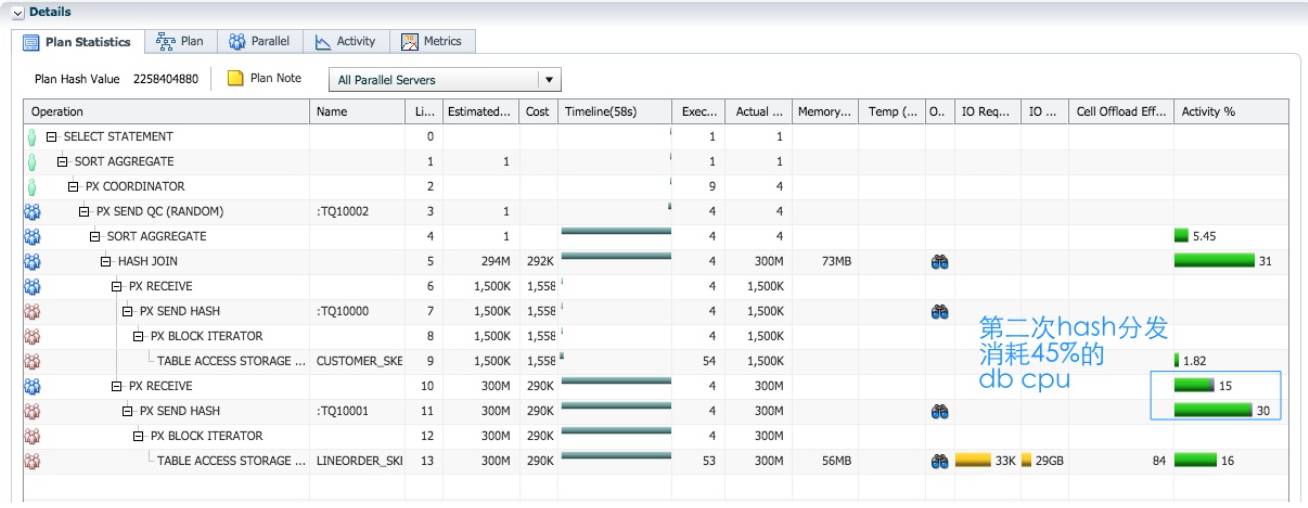
使用 hash 分发, SQL 执行时间为 58 秒, db time 2.1 分钟. 对于 replicate 时 sql 执行时间 23 秒, db time 1.5 分钟. 有趣的是, 整个 sql 消耗的 db time 只增加了 37 秒, 而执行时间确增加了 35 秒, 意 味着所增加的 db time 并不是平均到每个 PX 进程的. 如果增加的 db time 平均到每个 PX 进程, 而 且并行执行没有倾斜的话, 那么 sql 执行时间应该增加 37/4, 约 9 秒, 而不是现在的 35 秒。
红色的 PX 进程作为生产者, 分别对 customer_skew 和 lineorder_skew 完成并行扫描并通过 table queue0/1, hash 分发给蓝色的 PX 进程. 对 lineorder_skew 的分发, 占了 45%的 db cpu.

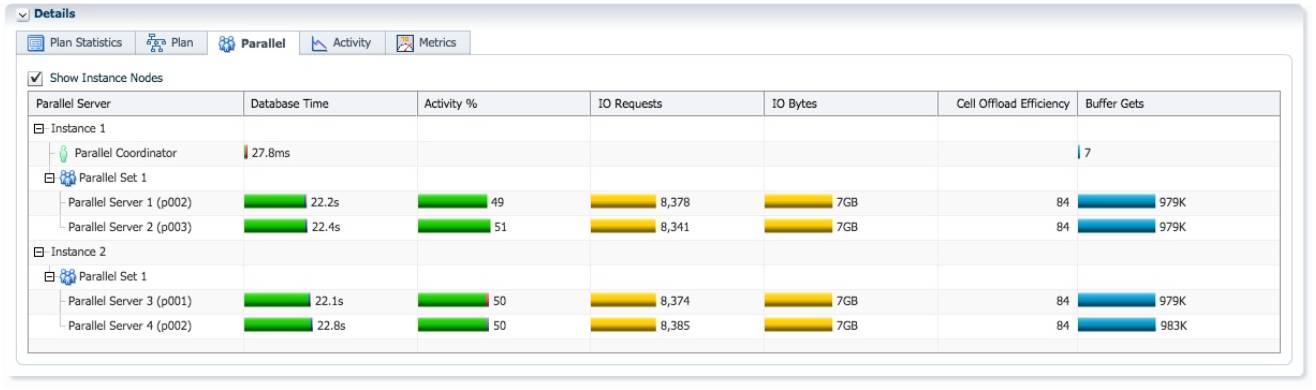
实例2的蓝色 PX 进程p001消耗了57.1秒的db time, sql执行时间58秒,这个PX进程在sql执 行过程中一直是活跃状态. 可以预见, lineorder_skew 所有 lo_custkey=-1 的数据都分发到这个进 程处理. 而作为生产者的红色 PX 进程, 负责扫描 lineorder_skew 并进行分发, 它们的工作量是平均的。
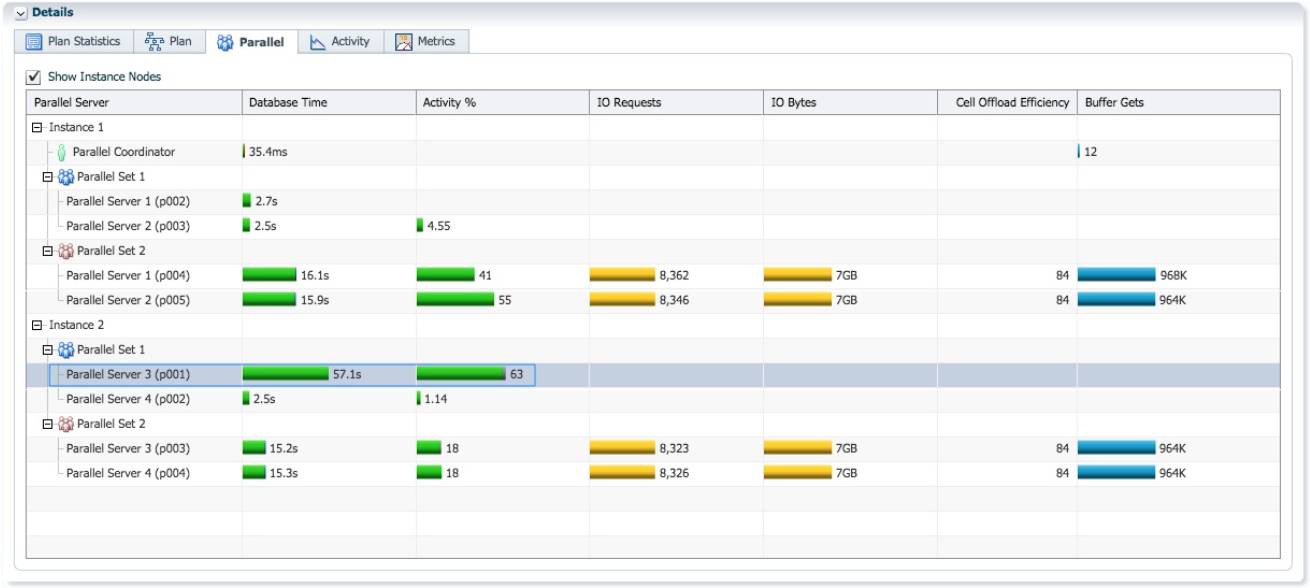
大部分时候 AAS=2, 只有实例 2 的 p001 进程不断的从 4 个生产者接收数据并进行 hash join.
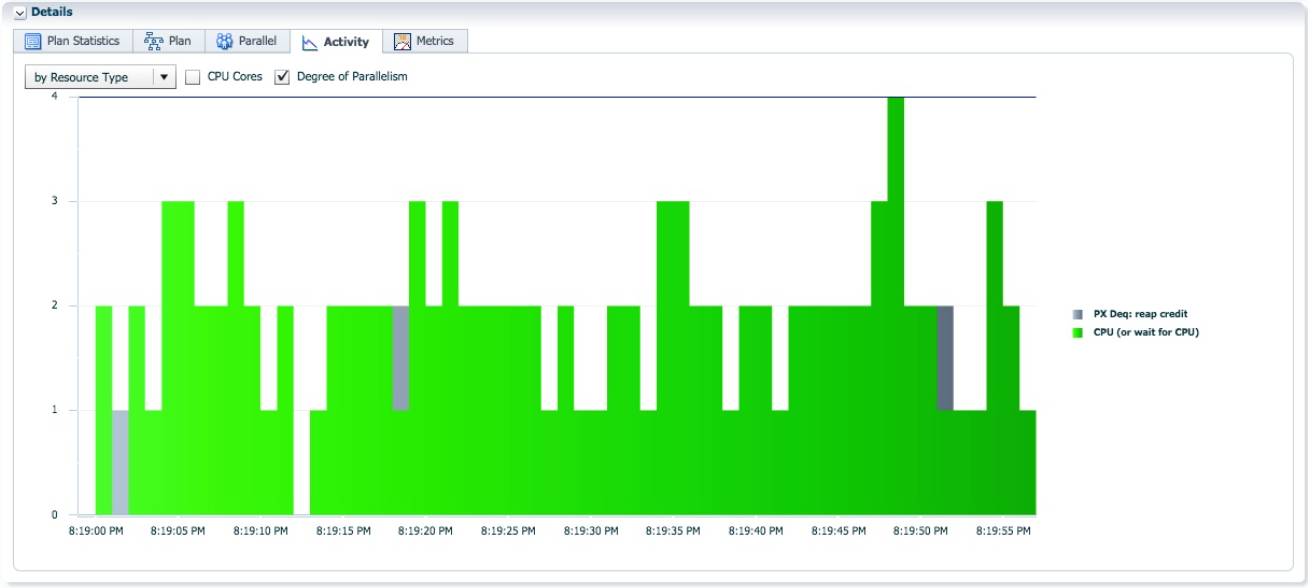
从 V$PQ_TQSTAT 视图我们可以确认, 对 hash join 右边分发时, 通过 table queue 1, 作为消费者的 实例 2 的 P001, 接收了两亿七千多万的数据. 这就是该 PX 进程在整个 sql 执行过程中一直保持活跃的原因。
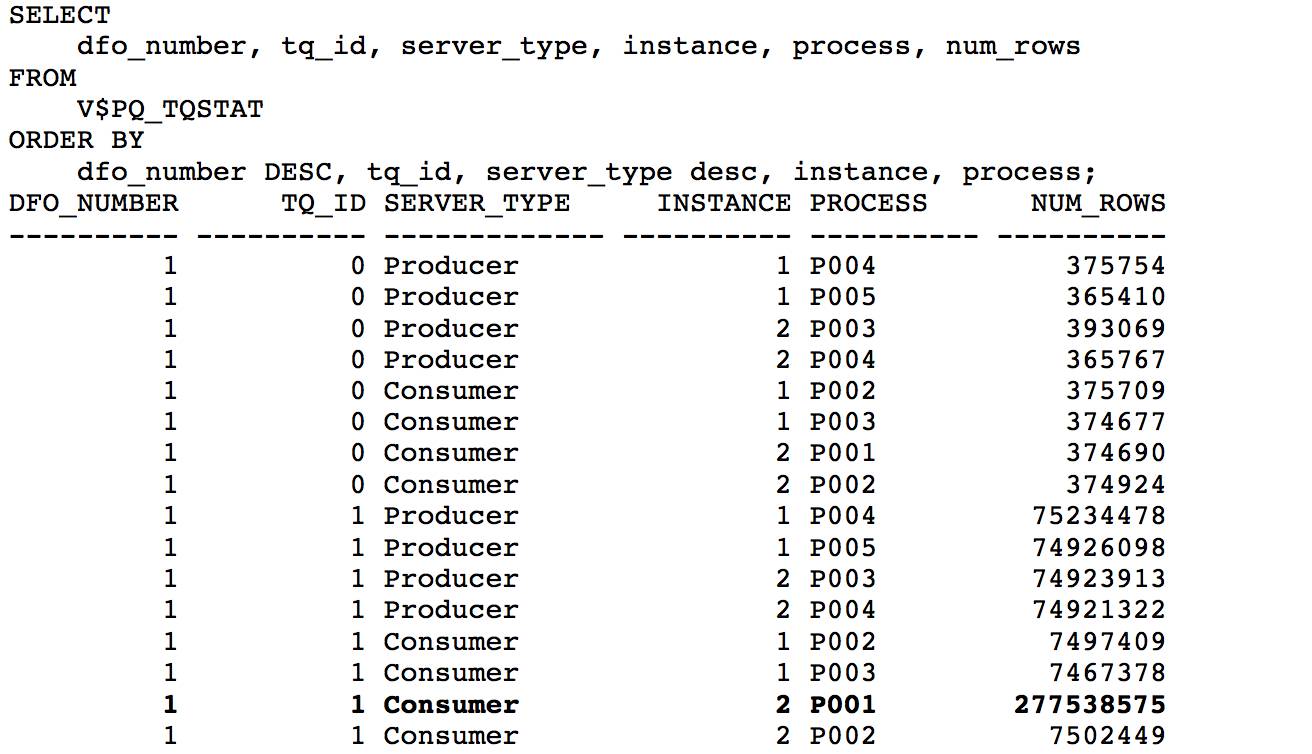

12c 的 sql monitor 报告作了增强, 并行执行倾斜时, 包含了消耗最大的 PX 进程的采样信息. 在plan statistics 页面, 下拉菜单选择’Parallel Server 3(instance 2, p001)’, 从执行计划的第 10 行, ‘PX RECEIVE’, 以及 Actual Rows 列的数据 278M, 也可以确认实例 2 的 p001 进程接收了两亿七千多万 数据。
小结
对于实际的应用, 处理数据倾斜是一个复杂的主题. 比如在倾斜列上使用绑定变量进行过滤, 绑定变量窥视(bind peeking)可能造成执行计划不稳定. 本节讨论了数据倾斜对不同分发方式的带来影响:
通常, replicate 或者 broadcast 分发不受数据倾斜的影响.
对于 hash 分发, hash join 两边连接键的最热门数据, 会被分发到同一 PX 进程进行 join 操作, 容易造成明显的并行执行倾斜.
12c 引入 adaptive 分发, 可以解决 hash 分发时并行执行倾斜的问题. 我将在下一篇文章 “深入理解 Oracle 的并行执行倾斜(下)”演示 adaptive 分发这个新特性。
到目前为止, 所有的测试只涉及两个表的连接. 如果多于两个表, 就需要至少两次的 hash join, 数据分发次数变多, 生产者消费者的角色可能互换, 执行计划将不可避免变得复杂. 执行路径变长,为了保证并行执行的正常进行, 执行计划可能会插入相应的阻塞点, 在 hash join 时 , 把符合 join条件的数据缓存到临时表, 暂停数据继续分发. 本节我使用一个三表连接的 sql 来说明连续 hash join 时, 不同分发方式的不同行为。
使用 Broadcast 分发,没有阻塞点。
测试三个表连接的 sql 如下, 加入 part 表, 使用 hint 让优化器两次 hash join 都使用 broadcast 分发。Replicate SQL 查询性能类似。


SQL 执行时间为 42 秒,db time 为 2.6 分钟。
AAS=(sql db time) / (sql 执行时间) = (2.6*60) / 42 =3.7, 接近 4, 说明 4 个 PX 进程基本一直保持活跃。

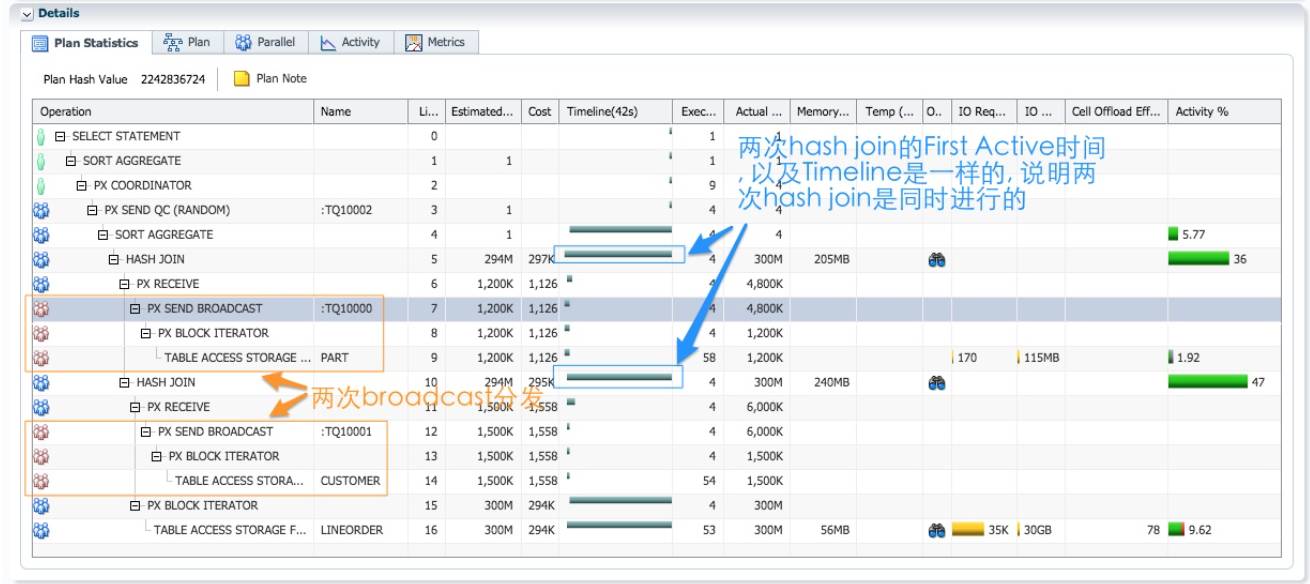
执行计划是一颗完美的右深树, 这是星型模型查询时执行计划的典型形式. 生产者对两个维度进 行 broadcast 分发, 消费者接受数据之后准备好两次 hash join 的 build table, 最后扫描事实表, 并 进行 hash join. 我们通过跟随 table queue 顺序的原则, 阅读这个执行计划。
红色 PX 进程作为生产者并行扫描 part, 通过 table queue 0 广播给每个蓝色的消费者 PX 进程 (第 7~9 行). 每个蓝色的 PX 进程接收 part 的完整数据(第 6 行), 1.2M 行记录, 并准备好第 5 行 hash join 的 build table.
红色 PX 进程作为生产者并行扫描 customer, 通过 table queue 1 广播 broadcast 给每个蓝色的消费者 PX 进程(第 12~14 行). 每个蓝色的 PX 进程接收 customer 的完整数据(第 11 行), 1.5M 行记录, 并准备好第 10 行 hash join 的 build table.
蓝色的 PX 进程并行扫描事实表 lineorder, 对每条符合扫描条件(如果 sql 语句包含对 lineorder 的过滤条件)的 3 亿行记录, 进行第 10 行的 hash join, 对于每一条通过第 10 行的hash join 的记录, 马上进行第 5 行的 hash join, 接着再进行聚合. 从 sql monitor 报告的Timeline 列信息, 对 lineorder 的扫描和两个 hash join 操作是同时进行的. 执行计划中没有阻 塞点, 数据在执行路径上的流动不需要停下来等待. 大部分的 db cpu 消耗在两次 hash join 操 作. 最优化的执行计划, 意味着经过每个 hash join 的数据越少越好. 对于这类执行计划, 你需 要确保优化器把最能过滤数据的 join, 放在最接近事实表的位置执行。
连续 hash 分发, 执行计划出现阻塞点
使用以下 hints, 强制 SQL 使用 hash 分发。
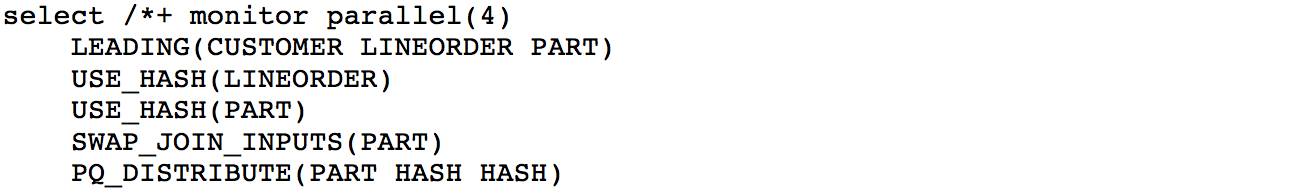

SQL 执行时间为 1.5 分钟, db time 为 8.1 分钟. 相对于增加了 14GB 的 IO 操作。

连续两次 hash join 都使用 HASH 分发, 每次 hash join 左右两边都需要分发, PX 进程之间发生 4 次 数据分发. 执行计划中最显著的地方来自第 12 行的 HASH JOIN BUFFERED, 这是一个阻塞性的操 作. 下面, 我们依然通过跟随 table queue 顺序的原则, 阅读执行计划, 并解析为什么出现 HASH JOIN BUFFERED 这个阻塞操作, 而不是一般的 HASH JOIN.
蓝色的 PX 进程作为生产者, 并行扫描 customer, 通过 table queue 0, hash 分发给作为消费者 的红色 PX 进程(第 14~16 行). 每个红色的 PX 进程接收了 1/4 的 customer 的数据(第 13 行),大约为 370k 行记录, 并准备好第 12 行’HASH JOIN BUFFERED’的 build table. 与 broadcast 分发 区别的是, 此时执行计划是从第 16 行, 扫描靠近 lineorder 的 customer 开始的, 而不是从第一 个没有’孩子’的操作(第 9 行扫描 part)开始的. 这是 hash 分发和串行执行计划以及 broadcast分发不同的地方.
蓝色的 PX 进程作为生产者, 并行扫描 lineorder, 通过 table queue 1, hash 分发作为消费者的 红色 PX 进程(第 18~20 行). 每个红色 PX 进程接收了 1/4 的 lineorder 数据(第 17 行), 大约75M 行记录. 每个红色 PX 进程在接收通过 table queue 1 接收数据的同时, 进行第 12 行的hash join, 并把 join 的结果集在 PGA 中作缓存, 使数据暂时不要继续往上流动. 如果结果集过 大的话, 需要把数据暂存到临时空间, 比如我们这个例子, 用了 7GB 的临时空间. 你可以理解 为把 join 的结果集暂存到一个临时表. 那么, 为什么执行计划需要在这里插入一个阻塞点, 阻 止数据继续往上流动呢?
这里涉及生产者消费者模型的核心: 同一棵 DFO 树中, 最多只能有两组 PX 进程, 一个 数据分发要求两组 PX 进程协同工作; 这意味着同一时刻, 两组 PX 进程之间, 最多只能 存在一个活跃的数据分发, 一组作为生产者发送数据, 一组作为消费者接收数据, 每个PX 进程只能扮演其中一种角色, 不能同时扮演两种角色。 当红色的 PX 进程通过 table queue 1 向蓝色的 PX 进程分发 lineorder 数据, 同时, 蓝色的 PX 进程正在接收 lineorder 数据,并进行 hash join. 观察 timeline 列的时间轴信息, 第 12, 17~20 行是同时进行的. 但是此时红色 的 PX 进程不能反过来作为生产者, 把 hash join 的结果分发给蓝色进程, 因为此时有两个限制:
蓝色的 PX 进程作为生产者, 正忙着扫描 lineorder; 此时, 无法反过来作为消费者, 接收来自红色 PX 进程的数据.
第 5 行 hash jon 操作的 build table 还没准备好, 这时表 part 甚至还没被扫描.
红色的 PX 进程作为生产者, 并行扫描 part, 通过 table queue 2, 分发给作为消费者的蓝色 PX进程(第 7~9 行). 每个蓝色 PX 进程接收了 1/4 的 part 数据(第 6 行), 大概 300k 行记录, 并准备 好第 5 行 hash join 的 build table.
红色的 PX 进程作为生产者, 把在第 12 行”HASH JOIN BUFFERED”操作, 存在临时空间的对于customer 和 lineorder 连接的结果集, 读出来, 通过 table queue 3, 分发给蓝色的 PX 进程(第11~12 行). “HASH JOIN BUFFERED”这个操作使用了 7GB 的临时空间, 写 IO 7GB, 读 IO 7GB, IO总量为 14GB.
每个蓝色的 PX 进程作为消费者, 接收了大约 75M 行记录. 对于通过 table queue 3 接收到的 数据, 同时进行第 5 行的 hash join, 并且通过 join 操作的数据进行第 4 行的聚合操作. 当 table queue 3 上的数据分发结束, 每个蓝色的 PX 进程完成 hash join 和聚合操作之后, 再把各自的 聚合结果, 一行记录, 通过 table queue 4, 分发给 QC(第 3~5 行). QC 完成最后的聚合, 返回给客户端.
所以 Oracle 需要在第 12 行 hash join 这个位置插入一个阻塞点, 变成 HASH JOIN BUFFER 操作,把 join 的结果集缓存起来. 当蓝色的 PX 进程完成对 lineorder 的扫描和分发, 红色的 PX 进程 完成第 12 行的 hash join 并把结果完全暂存到临时空间之后. Table queue 2 的数据分发就开 始了.
小结
因为使用星型模型测试, 这个例子 使用 Broadcast 分发或者 replicate 才是合理的. 实际应用中, 连 续的 hash 分发并不一定会出现 HASH JOIN BUFFERED 这个阻塞点, 如果查询涉及的表都较小, 一 般不会出现 HASH JON BUFFERED. 即使执行计划中出现 BUFFER SORT, HASH JOIN BUFFERED 等阻 塞操作, 也不意味着执行计划不是最优的. 如果 sql 性能不理想, HASH JOIN BUFFERED 操作消耗了 大部分的 CPU 和大量临时空间, 通过 sql monitor 报告, 你可以判断这是否是合理的:
检查 estimated rows 和 actual rows 这两列, 确定优化器对 hash Join 左右两边 cardinality 估算 是否出现偏差, 所以选择 hash 分发.
同样检查 hash join 操作的 estimated rows 和 actual rows 这两列, 优化器对 hash join 结果集cardinality 的估算是否合理. 优化器会把 hash join 的两边视为独立事件, 对 join 结果集cardinality 的估算可能过于保守, estimate rows 偏小. 对于星型模型的一种典型情况: 如果多 个维度表参与连接, 执行路径很长, 一开始维度表的分发方式为 broadcast, 事实表不用分发,经过几次 join 之后, 结果集 cardinality 下降很快, 后续 hash join 两边的 estimated rows 接近,导致优化器选择 hash 分发.
通过检查每个 join 所过滤的数据比例, 确定优化器是否把最有效过滤数据的 join 最先执行,保证在执行路径上流动的数据量最少.
布隆过滤在并行执行计划中的使用非常普遍, 我将在本章节解释这一数据结构及其作用. 从 11.2版本开始, 串行执行的 sql 也可以使用布隆过滤。
关于布隆过滤
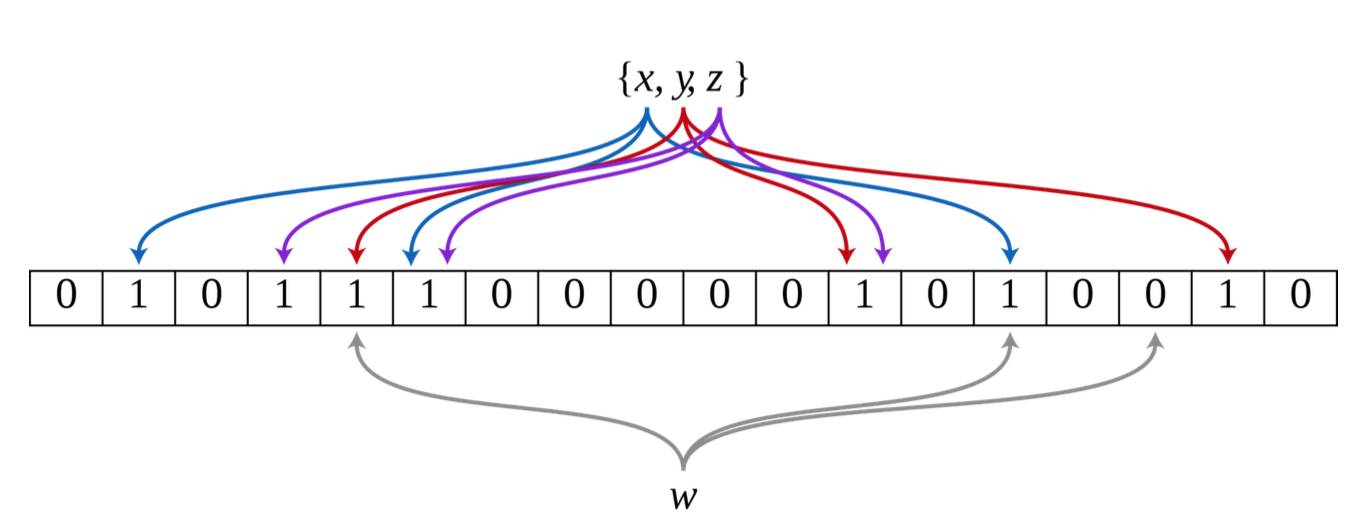
布隆过滤是一种内存数据结构, 用于判断某个元素是否属于一个集合. 布隆过滤的工作原理图2如下:
(引用自维基百科: http://en.wikipedia.org/wiki/Bloom_filter)
如图, 布隆过滤是一个简单的 bit 数组, 需要定义两个变量:
m: 数组的大小, 这个例子中, m=18.
k: hash 函数的个数, 这个例子中, k=3,
一个空的布隆过滤所有 bit 都为 0. 增加一个元素时, 该元素需要经过三个 hash 函数计算, 得到 3个 hash 值, 把数组中这三个位置都置为 1. 集合{x,y,z}的 3 个元素, 分布通过三次 hash 计算, 把数 组 9 个位置设置为 1. 判断某个元素是否属于一个集合, 比如图中的 w, 只需对 w 进行三次 hash计算产生三个值, 右边的位置在数组中不命中, 该位置为 0, 可以确定, w 不在{x,y,z}这个集合.由于存在 hash 碰撞, 布隆过滤的判断会过于乐观(false positive), 可能存在元素不属于{x,y,z}, 但是 通过 hash 计算之后三个位置都命中, 被错误认定为属于{x,y,z}. 根据集合元素的个数, 合理的设置 数组大小 m, 可以把错误判断的几率控制在很小的范围之内。
布隆过滤对 hash join 性能的改进
布隆过滤的优势在于使用的很少内存, 就可以过滤大部分的数据. 如果 hash join 的左边包含过滤 条件, 优化器可能选择对 hash join 左边的数据集生成布隆过滤, 在扫描 hash join 右边时使用这个 布隆布隆作为过滤条件, 第一时间把绝大部分不满足 join 条件数据排除. 减少数据分发和 join 操 作所处理的数据量, 提高性能.
使用布隆过滤时的性能
对 customer 使用 c_nation=’CHINA’条件, 只计算来自中国地区的客户订单的利润总和. 我们观察 使用布隆过滤和不使用布隆过滤时性能的差别.
SQL 执行时间为 1 秒, db time 为 7.9 秒. 优化器默认选择 replicate 的方式. 执行计划中多了 JOIN FILTER CREATE 和 JOIN FILTER USE 这两个操作. SQL 的执行顺序为每个 PX 进程重复扫描 customer表(第7行),对符合c_nation=’CHINA’数据集, 60K(240K/4)行记录,在c_custkey列生成布隆过 滤:BF0000(第 6 行 JOIN FILTER CREATE). 在扫描 lineorder 时使用这个布隆过滤(第 8 行 JOIN FILTER USE). 虽然 lineorder 总行数为 300M, sql 没有过滤条件, 只使用布隆过滤, 扫描之后只返回 28M 行 记录, 其他 272M 行记录被过滤掉了. 每个 PX 进程在 hash join 操作时, 只需处理 60K 行 customer记录和 7M(28M/4)行 lineorder 记录的连接, 大大降低 join 操作的成本. 对于 Exadata, Smart Scan支持布隆过滤卸载到存储节点, 存储节点扫描 lineorder 时, 使用布隆过滤排除 272M 行记录, 对于 符合条件的数据, 把不需要的列也去掉. Cell offload Efficiency=98%, 意味着只有 30GB 的 2%从存 储节点返回给 PX 进程. 如果不使用布隆过滤, Cell Offload Efficieny 不会高达 98%, 我们将在下个 例子看到. 对于非 Exadata 平台, 由于没有 Smart Scan 特性, 数据的过滤操作需要由 PX 进程完成,布隆过滤的效果不会这么明显. 12C 的新特性 Database In-memory, 支持扫描列式存储的内存数 据时, 使用布隆过滤。
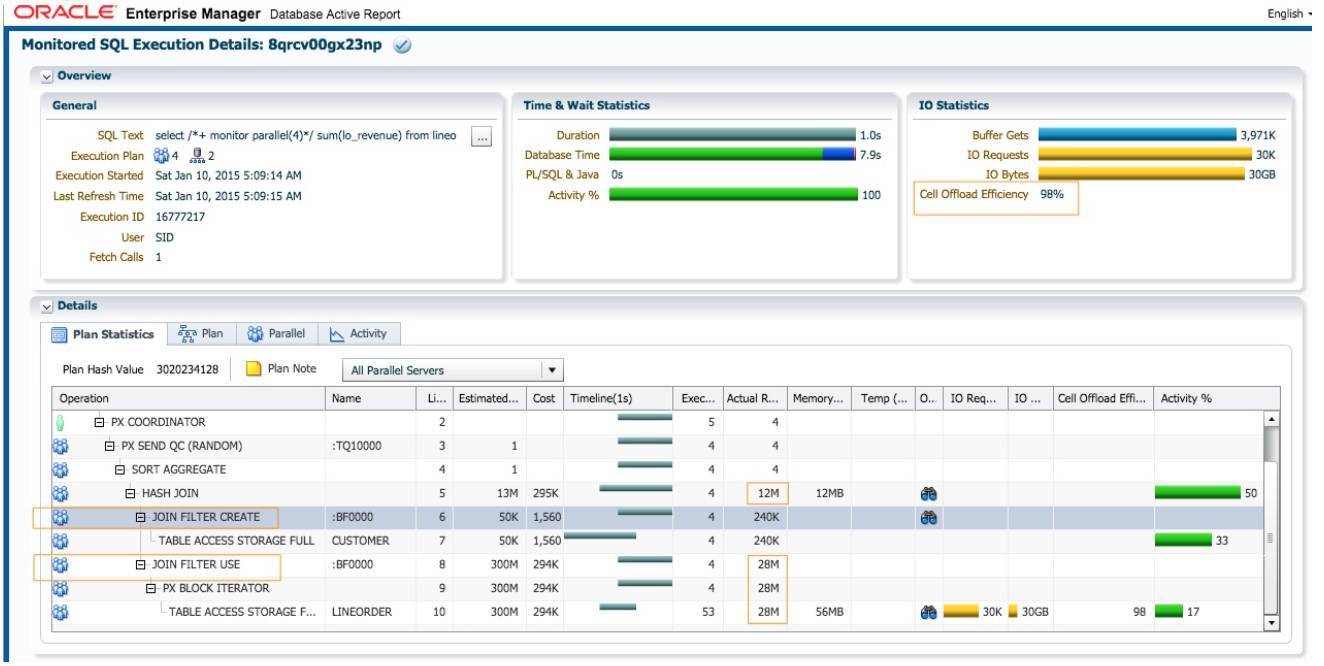
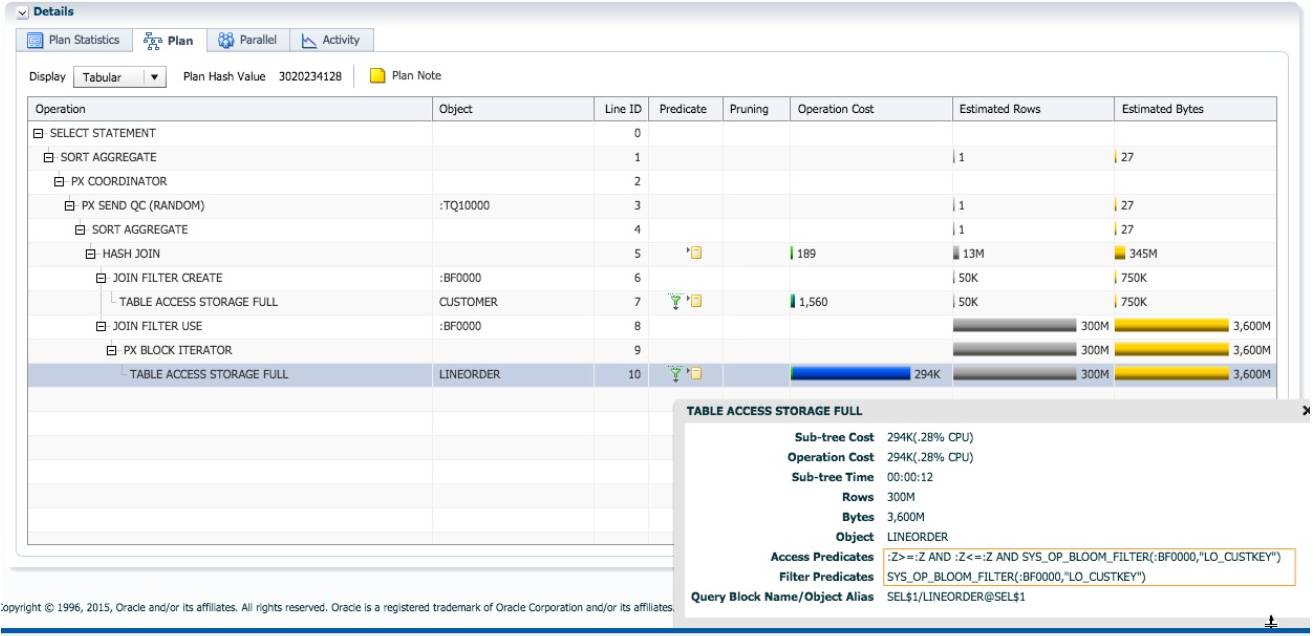
执行计划中出现第 10 行对 LINEORDER 的扫描时, 使用了布隆过滤条件: SYS_OP_BLOOM_FILTER(:BF0000,"LO_CUSTKEY")
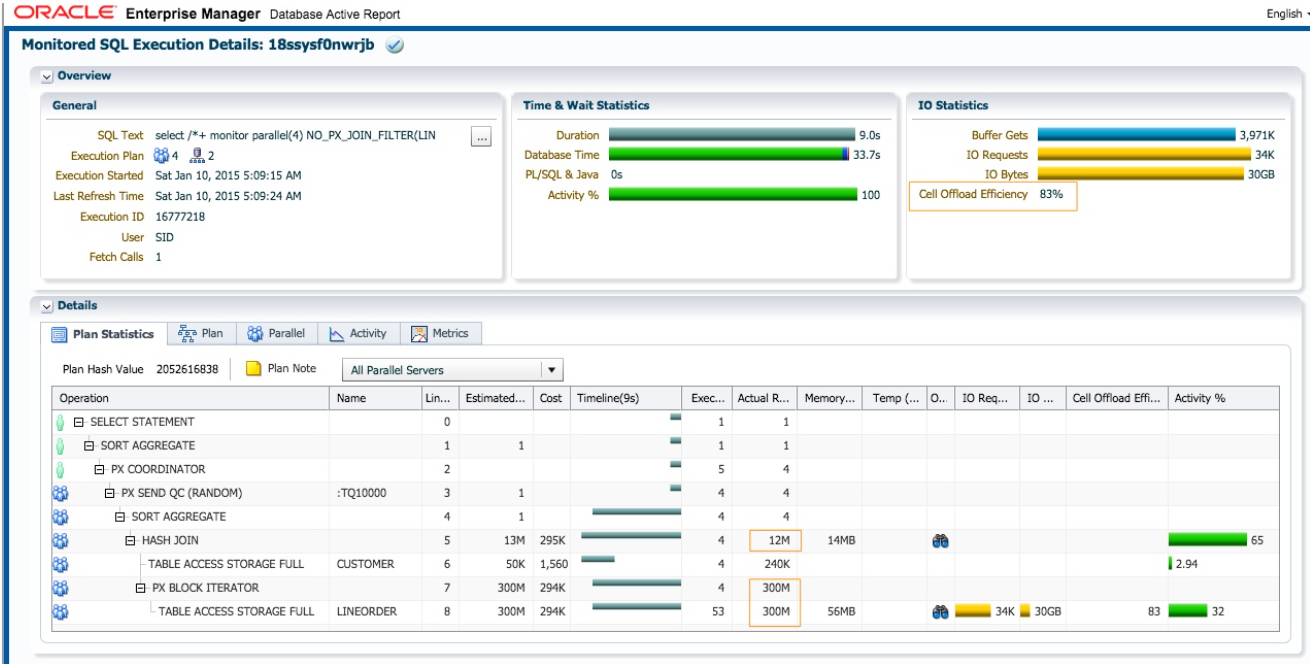
不使用布隆过滤时的性能
接着, 我们通过 hint NO_PX_JOIN_FILTER, 禁用布隆过滤, 观察此时的 sql 执行性能.

SQL 执行时间为 9 秒, db time 为 33.7 秒. 比使用布隆过滤时, 性能下降明显. 优化器依然选择replicate 的方式, 执行计划中没有 PX JOIN CREATE 和 PX JOIN USE 操作. db time 增加为原来 4 倍的 原因:
1. 当 PX 扫描 lineorder 时, 返回 300M 行记录. 没有布隆过滤作为条件, 每个 PX 进程需要从 存储节点接收 75M 行记录。
2. 进行第 5 行的 hash join 操作时, 每个 PX 进程需要连接 60k 行 customer 记录和 75M 行lineorder 记录. Join 操作的成本大幅增加。
由于没有布隆过滤, Cell Offload Efficiency 下降为 83%.
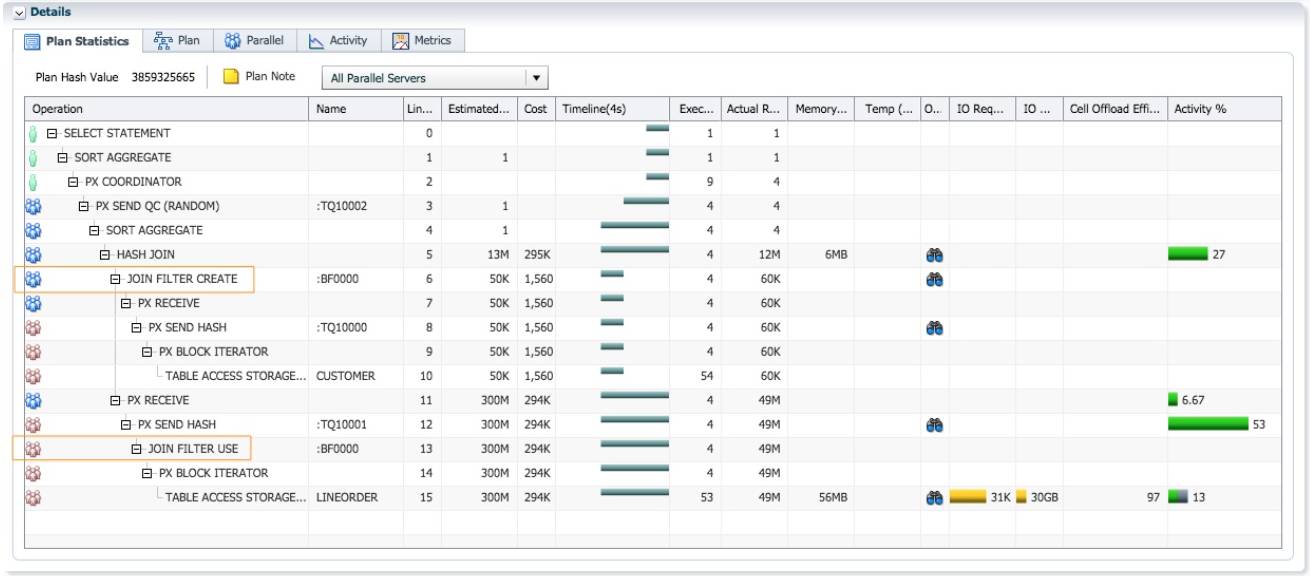
HASH 分发时布隆过滤的生成, 传输, 合并与使用
我们通过 hint 强制使用 hash 分发, 观察此时 sql 执行计划中布隆过滤的生成和使用.

此时 sql 执行时间为 4 秒, db time 为 19.4 秒. 执行计划第 6 行为 JOIN FILTER CREATE; 第 13 行为JOIN FILTER USE. 此例, PX 进程分布在多个 RAC 两个实例, Hash 分发时涉及布隆过滤的生成,传输,合并和使用, 较为复杂, 具体过程如下:
布隆过滤的产生: 4 个蓝色的 PX 进程作为消费者, 通过 table queue 0 , 接收红色的 PX 进程hash 分发的 customer 数据, 每个蓝色的 PX 进程接收 15K 行记录. 接收 customer 记录的同时,实例 1 的两个蓝色 PX 进程在 SGA 共同生成一个布隆过滤, 假设为 B1; 实例 2 的两个蓝色 PX进程在 SGA 共同生成一个布隆过滤, 假设为 B2. 因为位于 SGA 中, 布隆过滤 B1 对于实例 1 的 两个红色的 PX 进程是可见的, 同样, B2 对于实例 2 的两个红色 PX 进程也是可见的.
布隆过滤的传输: 当红色的 PX 进程完成对 hash join 左边 customer 的扫描, 就会触发布隆过 滤B1/B2的传输.实例1的红色PX进程把B1发给实例2的蓝色PX进程;实例2的红色PX进程把B2发给实例1的蓝色PX进程.
布隆过滤的合并: 实例 1 的蓝色 PX 进程合并 B1 和接收到的 B2; 实例 2 的蓝色 PX 进程合并B2 和接收到的 B1. 合并之后, 实例 1 和 2 产生相同布隆过滤.
布隆过滤的使用: 实例 1 和 2 的 4 个红色的 PX 进程作为生产者, 并行扫描 lineorder 时使用 合并之后的布隆过滤进行过滤. Lineorder 过滤之后为 49M 行记录, 此时的布隆过滤似乎没有replicate 时的有效. Cell Offloadload Efficiency 为 97%.
如果并行执行只在一个实例, 则红色的 PX 进程不需要对布隆过滤进行传输, 蓝色的 PX 进程也无 需对布隆过滤进行合并。
因为 hash join 的成本大大降低了, 对于 lineorder 49M 行记录的 hash 分发, 成为明显的平均, 占53%的 db time.

小结
本节阐述了布隆过滤的原理, 以及在 Oracle 中的一个典型应用: 对 hash join 性能的提升. 布隆过 滤的本质在于把 hash join 的连接操作提前了, 对 hash join 右边扫描时, 就第一时间把不符合 join条件的大部分数据过滤掉. 大大降低后续数据分发和 hash join 操作的成本.
不同的分布方式, 布隆过滤的生成和使用略有不同:
对于 broadcast 分发和 replicate, 每个 PX 进程持有 hash join 左边的完整数据, 对连接键生成 一个完整的布隆过滤, 扫描 hash join 右边时使用. 如果 sql 涉及多个维度表, 维度表全部使用broadcast 分发, 优化器可能对不同的维度表数据生成多个的布隆过滤, 在扫描事实表时同时使用.
对于 hash 分发, 作为消费者的 PX 进程接收了 hash join 左边的数据之后, 每个 PX 进程分别对 各自的数据集生成布隆过滤, 再广播给作为生产者的每个 PX 进程, 在扫描 hash join 右边时使用.
真实世界中, 优化器会根据统计信息和 sql 的过滤条件自动选择布隆过滤. 通常使用布隆过滤使 都会带来性能的提升. 某些极端的情况, 使用布隆过滤反而造成性能下降, 两个场景:
当 hash join 左边的数据集过大, 比如几百万行, 而且连接键上的唯一值很多, 优化器依然选择使用布隆过滤. 生成的布隆过滤过大, 无法在 CPU cache 中完整缓存. 那么使用布隆过滤时, 对于 hash join 右边的每一行记录, 都需要到内存读取布隆过滤做判断, 导致性能问题。
如果 Join 操作本身无法过滤数据, 使用布隆过滤时 hash join 右边的数据都会命中. 优化器可 能无法意识到 join 操作无法过滤数据, 依然选择使用布隆布隆. 如果 hash join 右边数据集很大, 布隆过滤可能会消耗明显的额外 cpu.
现实世界中, 由于使用不当, 并行操作无法并行, 或者并行执行计划效率低下, 没有获得期望的性 能提升. 本节举几个典型例子.
在 sql 中使用 rownum, 导致出现 PX SEND 1 SLAVE 操作, 所有数据都需要分发到一个 PX 进程,以给每一行记录赋值一个唯一的 rownum 值, 以及 BUFFER SORT 等阻塞操作.
使用用户自定义的 pl/sql 函数, 函数没有声明为 parallel_enable, 导致使用这个函数的 sql 无法并行.
并行 DML 时, 没有 enable parallel dml, 导致 DML 操作无法并行.
Rownum, 导致并行执行计划效率低下
在’数据倾斜对不同分发方式的影响’小节中, 我们新建一个表 lineorder_skew 把 lineorder 的lo_custkey 列 90%的值修改为-1. 因为 lo_custkey 是均匀分布的, 我们可以通过对 lo_custkey 列求模, 也可以通过对 rownum 求模, 把 90%的数据修改为-1. 使用如下的 case when 语句:
1. case when mod(lo_orderkey, 10) > 0 then -1 else lo_orderkey end lo_orderkey
2. case when mod(rownum, 10) > 0 then -1 else lo_orderkey end lo_orderkey
通过以下的建表 sql 来测试两种用法时的 sql 执行性能, 并行度为 16.
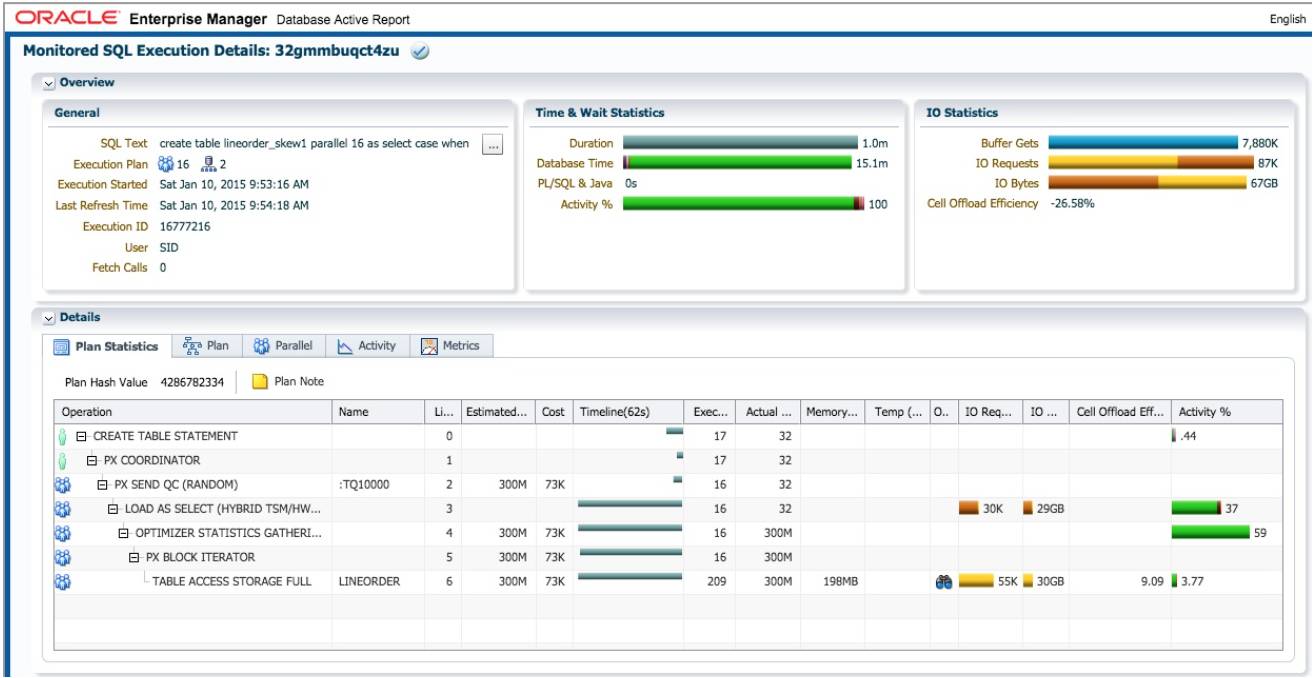
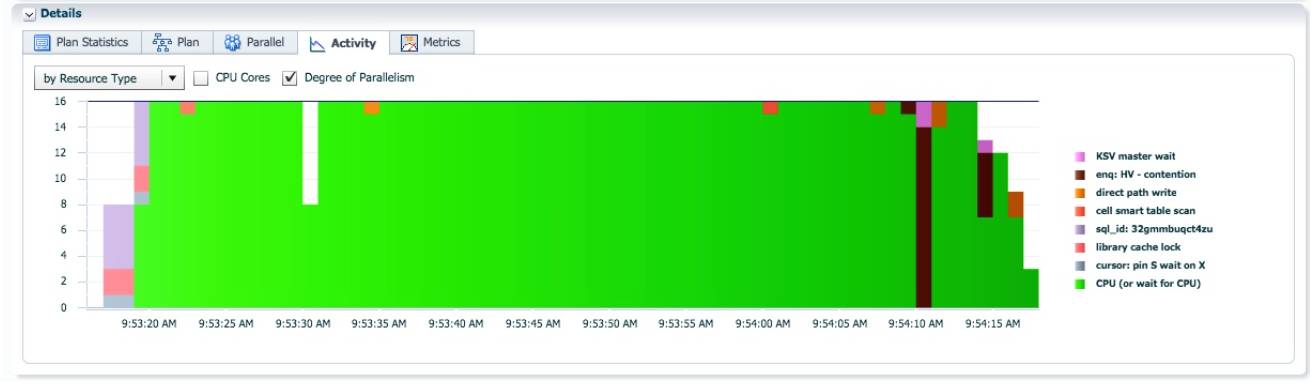
大部分时间, AAS=16.
使用 rownum 时, create table 执行时间为 22.3 分钟, db time 为 38.4 分钟. SQL 的执行时间为使用lo_orderkey 时的 22 倍。

执行计划中出现两组PX进程, PXSEND1SLAVE和BUFFERSORT两个操作在之前的测试没有出现 过. 根据跟随 table queue 顺序的原则, 我们来阅读这个执行计划:
蓝色的 PX 进程并行扫描 lineorder, 通过 table queue 0 把所有数据分发给一个红色的 PX 进程 (第 10~12 行). 因为 rownum 是一个伪列, 为了保证每一行记录拥有一个唯一行号, 对所 有数据的 rownum 赋值这个操作只能由一个进程完成, 为 rownum 列赋值成为整个并 行执行计划的串行点. 这就是出现 PX SEND 1 SLAVE 操作, 性能急剧下降的原因. 这个例 子中, 唯一活跃的红色 PX 进程为实例 1 p008 进程. Lineorder 的 300M 行记录都需要发送到实 例 1 p008 进程进行 rownum 赋值操作, 再由这个进程分发给 16 个蓝色的 PX 进程进行数据并行插入操作.
实例 1 p008 进程接收了 16 个蓝色 PX 进程分发的数据, 给 rownum 列赋值(第 8 行 count 操作)之后, 需要通过 table queue 1 把数据分发给蓝色的 PX 进程. 但是因为通过 table queue 0 的数 据分发的还在进行, 所以执行计划插入一个阻塞点 BUFFER SORT(第 7 行), 把 rownum 赋值之 后的数据缓存到临时空间, 大小为 31GB.
Table queue 0 的数据分发结束之后, 实例 1 p008 把 31GB 数据从临时空间读出, 通过 table queue 1 分发给 16 个蓝色的 PX 进程进行统计信息收集和插入操作.
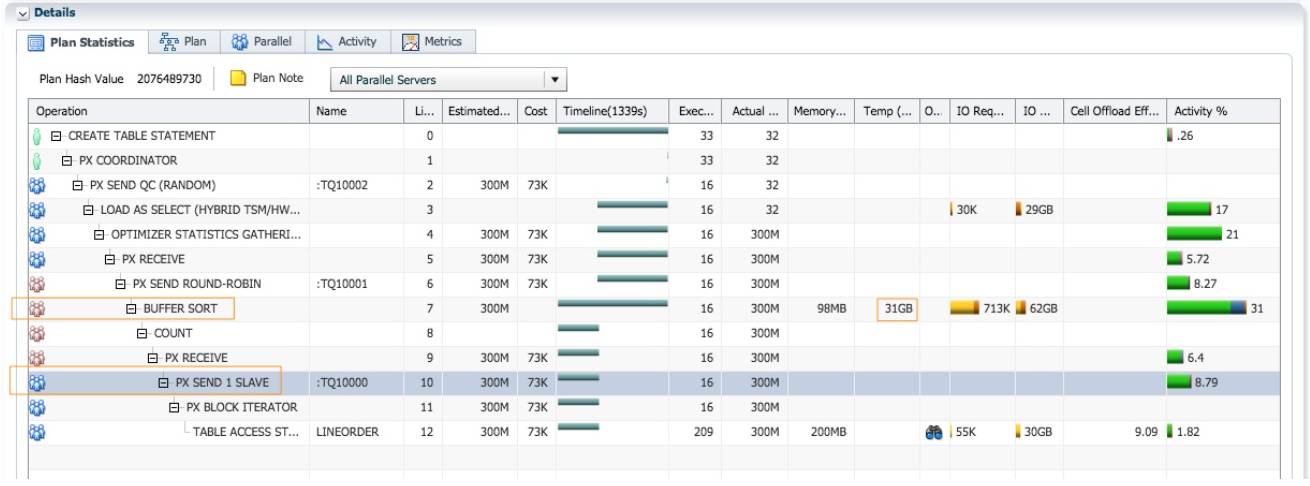
红色的 PX 进程只有实例 1 p008 是活跃的. 消耗了 16.7 分钟的 db time. 对于整个执行计划而言,两次数据分发也消耗了大量的 db cpu. 通过 Table queue 0 把 300M 行记录从 16 个蓝色的 PX 进 程分发给 1 个红色的 PX 进程. 通过 Table queue 1 把 300M 行记录从 1 个红色的 PX 进程分发给16 个蓝色的 PX 进程。
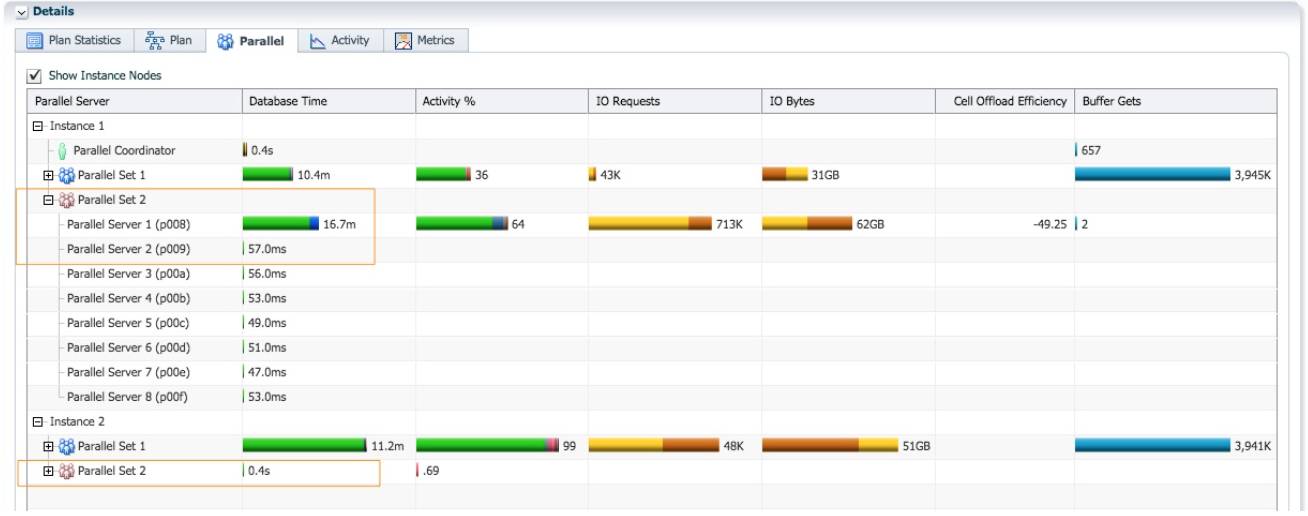
虽然 DoP=16, 实际 AAS=1.5, 意味着执行计划效率低下。
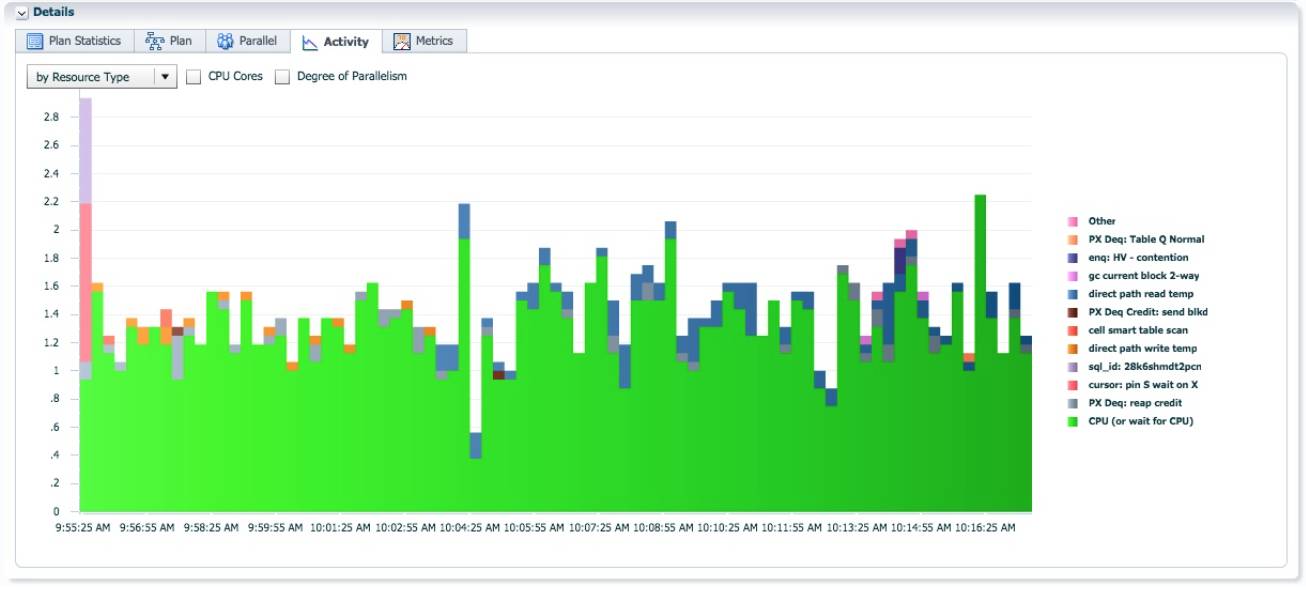
现实世界中, 在应用中应该避免使用 rownum. Rownum 的生成操作会执行计划的串行点, 增加无 谓的数据分发. 对于使用 rownum 的 sql, 提升并行度往往不会改善性能, 除了修改 sql 代码, 没有 其他方法。
自定义 PL/SQL 函数没有设置 parallel_enable,导致无法并行
Rownum 会导致并行执行计划出现串行点, 而用户自定义的 pl/sql 函数, 如果没有声明为parallel_enable, 会导致 sql 只能串行执行, 即使用 hint parallel 指定 sql 并行执行. 我们来测试一下,创建 package pk_test, 包含函数 f, 返回和输入参数一样的值. 函数的声明中没有 parallel_enable,不支持并行执行。

以下例子中在 where 语句中使用函数 pk_test.f, 如果在 select 列表中使用函数 pk_test.f, 也会导致执行计划变成串行执行。

查询执行时间为 54 秒, db time 也为 54 秒。虽然我们指定使用 Dop=4 并行执行, 执行计划实际是串行的。
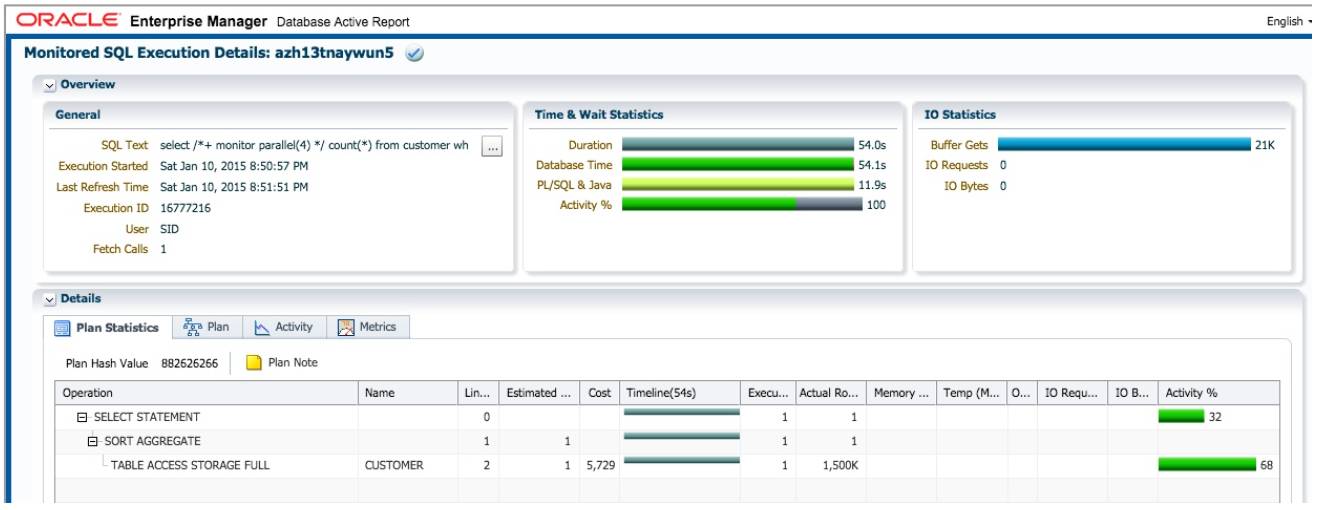
在函数的声明时设置 parallel_enable, 表明函数支持并行执行, 再次执行 sql.

此时查询的执行时间为 12 秒, db time 为 46.4 秒. 并行执行如期发生, 并行度为 4.
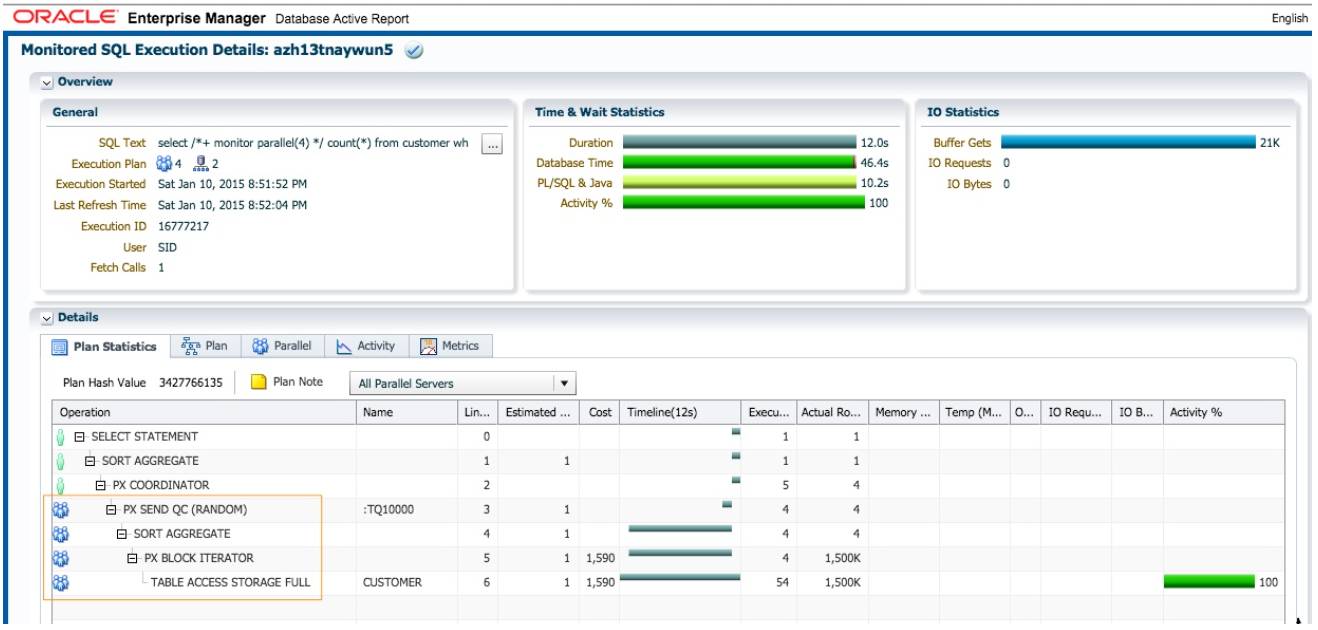
除非有特殊的约束, 创建自定义 pl/sql 函数时, 都应该声明为 parallel_enable. pl/sql 函数声明时没 有设置 parallel_enable 导致无法并行是一个常见的问题, 我曾在多个客户的系统中遇到. 在 11g中, 这种情况发生时, 执行计划中可能会出现 PX COORDINATOR FORCED SERIAL 操作, 这是一个明 显的提示; 或者你需要通过 sql monitor 报告定位这种问题. 仅仅通过 dbms_xplan.display_cursor检查执行计划是不够的, 这种情况执行计划的 note 部分, 还是会显示 DoP=4.
并行 DML, 没有 enable parallel dml, 导致 DML 操作无法并行.
这是 ETL 应用中常见的问题, 没有在 session 级别 enable 或者 force parallel dml, 导致 dml 操作无 法并行. 使用 customer 的 1.5M 行数据演示一下.
建一个空表 customer_test:
create table customer_test as select * from customer where 1=0;
我们使用并行直接路径插入的语句作为例子. 分别执行两次 insert, 第一次没有 enable parallel dml, insert 语句如下:
insert /*+ append parallel(4) */ into customer_test select * from customer;
Insert 语句执行时间 9 秒. 虽然整个语句的并行度为 4, 但是执行计划中, 第 2 行直接路径插入操 作 LOAD AS SELECT 是串行执行的。
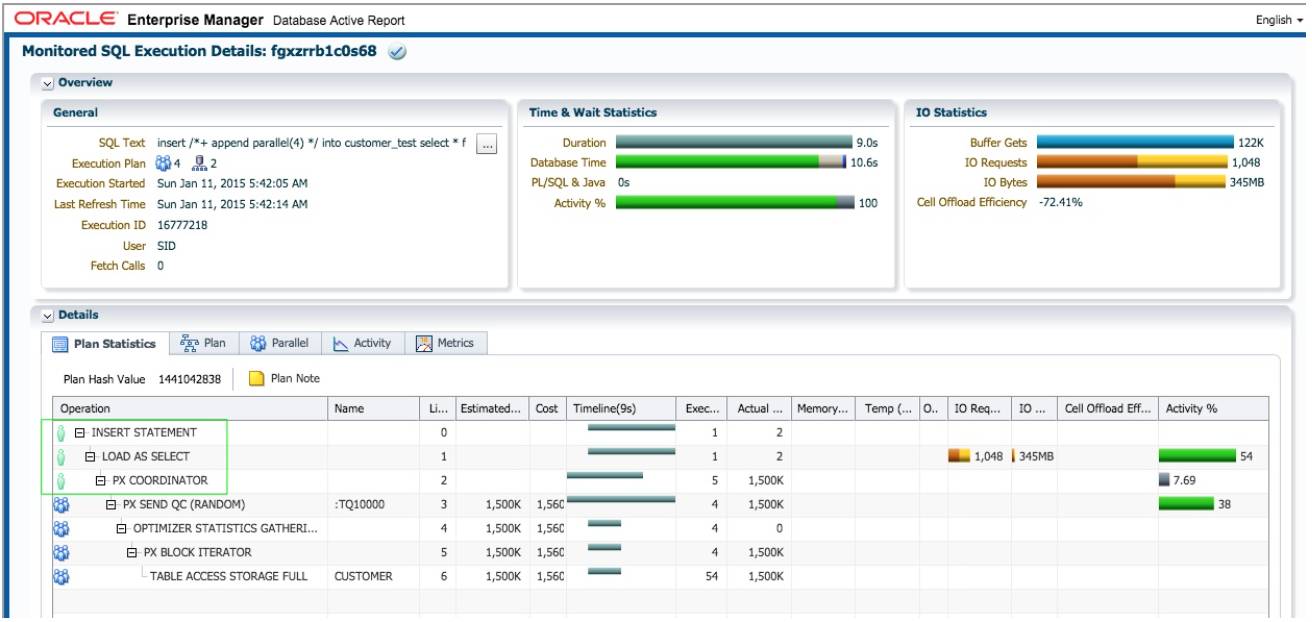
此时执行计划的 Note 部分会显示 PDML 没有启用:
Note
-----
- PDML is disabled in current session
启用 parallel dml 之后, 重新执行 insert 语句.
alter session enable parallel dml;
此时 insert 语句执行时间为 3 秒, 执行计划中第三行, LOAD AS SELECT 操作是可以并行的.
小结
我列举了使用并行执行时, 常见的三种问题:
使用 rownum.
自定义 pl/sql 函数没有声明 parallel_enable.
并行 DML 时没有 enable parallel dml.
希望通过以上三个例子, 希望读者对调试并行执行计划有一个更直观的感受. 处理并行执行的问 题, sql monitor 报告是最好的分析工具. 对于并行 DDL 和 DML, Oracle 本身有一些限制, 可以参见官方文档, 比如:
表上的触发器或者外键约束可能导致 DML 无法并行.
包含 LOB 字段的非分区表, 不支持并行 DML 和 DDL; 包含 LOB 字段的分区表, 只支持分区间的并行 DML 和 DDL.
远程表(通过 db link) 不支持并行 DML; 临时表不支持并行 update, merge, delete.
这篇长长的文章更像是我在 Real-World Performance Group 的工作总结. 在大量实际项目中, 我们 发现很多开发或者 DBA 并没有很好理解并行执行的工作原理, 设计和使用并行执行时, 往往也没 取得最佳的性能. 对于并行执行, 已经有很多的 Oracle 书籍和网上文章讨论过, 在我看来, 这些内 容更偏重于并行执行原理的解释, 缺乏实际的使用案例. 我希望在本文通过真实的例子和数据,以最简单直接的方式, 向读者阐述 Oracle 并行执行的核心内容, 以及在现实世界中, 如果规避最 常见的使用误区.也希望本文所使用 sql monitor 报告分析性能问题的方法, 对读者有所启示! 如果 现在你对以下并行执行的关键点, 都胸有成竹的话, 我相信现实世界中 Oracle 的并行执行问题都 不能难倒你。
• Oracle 并行执行为什么使用生产者-消费者模型.
• 如何阅读并行执行计划.
• 不同的数据分发方式分别适合什么样的场景.
• 使用 partition wise join 和并行执行的组合提高性能.
• 数据倾斜会对不同的分发方式带来什么影响.
• 由于生产者-消费者模型的限制, 执行计划中可能出现阻塞点.
• 布隆过滤是如何提高并行执行性能的.
• 现实世界中, 使用并行执行时最常见的问题.
下一篇文章, 我将介绍 12c 的新特性, adaptive 分发.
本文目前的内容和质量, 源于对初稿的多次审校和迭代.
本文的两个难点, 1) 连续 hash 分发时出 现阻塞点; 2) hash 分发时使用布隆过滤的具体过程, 得到了我英国同事 Mike Hallas 的解答和确认.我的同事董志平对初稿的做了详细的审校, 指出多处纰漏. 本文的一些内容是在他的建议下增加 的, 比如 Partition Wise Join 时, DoP 大于分区数时 partition wise join 会失效, 比如 replicate 方式为 什么不能完全替代 broadcast 分发. 我的同事徐江和李常勇, 我的朋友蒋健阅读初稿之后, 也提供了诸多反馈, 在此一并感谢!
关注本微信(OraNews)回复关键字获取
2016DTCC, 2016数据库大会PPT;
DBALife,"DBA的一天"精品海报大图;
12cArch,“Oracle 12c体系结构”精品海报;
DBA01,《Oracle DBA手记》第一本下载;
YunHe,“云和恩墨大讲堂”案例文档下载;
以上是关于深入并行:从数据倾斜到布隆过滤深度理解Oracle的并行的主要内容,如果未能解决你的问题,请参考以下文章