你敢在Oracle 12c R2上做大表truncate吗?
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你敢在Oracle 12c R2上做大表truncate吗?相关的知识,希望对你有一定的参考价值。
作者介绍
郭远胜,中国移动通信集团湖南有限公司系统支撑中心技术专家,主导了湖南移动业务支撑中心数据库双中心建设、数据标准化建设等项目。
魏斌,新炬网络数据库专家,Oracle 11G、12C OCM,具有10年运营商数据库运维经验,在trouble shooting、数据库优化等方面有着丰富的经验。
一、背景
笔者所处的省份正在做生产全网段的Oracle 12c升级,在正式割接前搭建了准生产环境用于应用测试,前期应用功能测试均正常,在进行二次模割对历史数据进行清理的时候,数据库发生了hang以及节点重启的问题。
What?数据清理居然导致了数据库节点hang和实例重启?那以后谁敢在生产做数据清理呀?请听笔者仔细道来。
主机:IBM 750
操作系统为:AIX 7.2
数据库版本:Oracle 2-nodes RAC 12.2.0.1
二、故障处理过程
5月中旬晚间,笔者正在过周末,突然收到准生产库有断连告警,检查发现该准生产节点2实例在20:03宕掉。检查发现集群曾多次尝试拉起节点2,节点2均无法拉起。尝试手动拉库,发现问题依旧,且节点1再次hang住,最终通过停止节点1实例,再次尝试拉起节点2,故障恢复。
分析节点2的alert日志信息可知,节点2实例在20:03:22被踢出集群,开始重构。
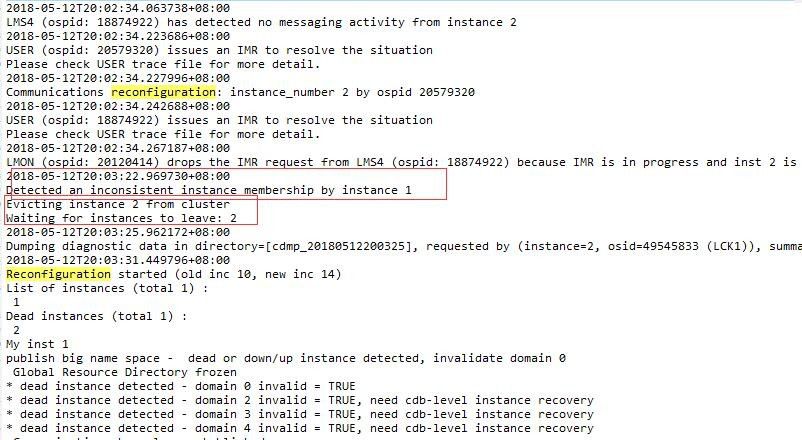
节点2被踢出后,集群尝试拉起实例进行reconfig,但因IPC超时,均无法于节点1进行通信。
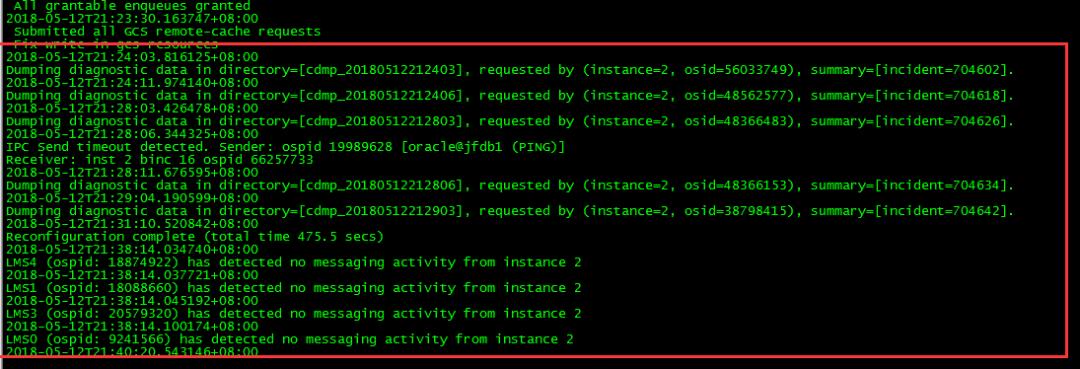
查看私网ping日志信息,在节点2实例宕掉前有丢包现象,在20:03:00丢包率达到100%,因此节点2被踢掉。

节点2重启之后私网间断性丢包率100%,IPC超时导致节点2一直持续到21:38都没有完成最终的启动过程:
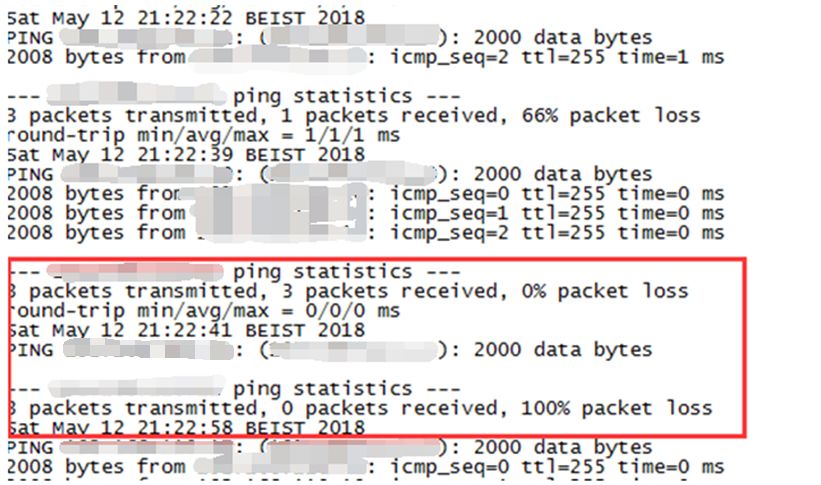
查看节点2 oswatch记录的主机负载信息,在节点2发生重启前,内存使用率均稳定,CPU十分空闲,但查看netstat发下故障时段出现很多“fragments dropped after timeout”。
xxdb2_netstat_xx.dat
589101635 fragments dropped after timeout
589112000 fragments dropped after timeout
589114416 fragments dropped after timeout
...
600709972 fragments dropped after timeout
600874894 fragments dropped after timeout
根据nmon生成的图可以看到,节点2在20:03第一次重启前、21:22第二次重启前、21:42重启前均出现私网流量暴增现象,私网流量最高达到了600M/s。

通过对比数据库日志,发现节点1主机的私网流量突增时,除第一次外,均与集群重拉数据库实例时间一致。
第一次私网流量突增的时候数据库在做什么?
由于节点2实例发生了重启,节点1在hang后也发生了重启,相关日志均有所缺失,故只能通过与应用侧沟通当时的操作。应用侧反馈只是做历史数据清理的truncate操作,操作过程中前面比较快,中间有一个大表truncate卡了比较久,而且数据库感觉非常缓慢。
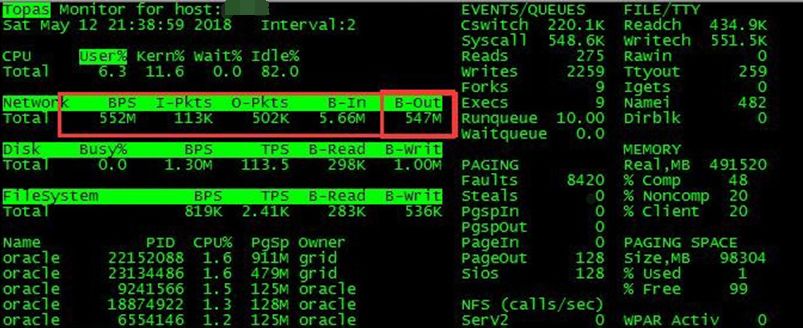
21点37分左右,手动拉起实例,topas发现节点1在21:38左右网络BPS有552M/s,而且大部分都是OUT。
三、进一步分析
故障过程分析完后,有三个疑问需要解答:
通过与应用沟通,应用在20点左右在节点1对历史数据进行truncate时,truncate缓慢,PL/SQL卡死,一个truncate为什么会导致私网流量上涨?
当时所有操作都是在节点1进行的,节点2完全无任何操作,私网流量为什么会上涨?
节点2实例一启动,节点1私网流量为什么就突增?
基于这3个疑问,通过故障模拟收集SYSTEM DUMP日志、LMON、LMS等日志进行进一步分析:
模拟场景一:查询测试大表,使其加载进buffer cache,然后flush buffer cache。
测试结果:flush期间观察网卡发送流量,发送超500M/s,达到网卡瓶颈,持续时间和flush buffer cache基本相同,实例1报大量的ipc timeout,同时实例2会发生重启。怀疑是由于本身网卡的带宽很高,数据库在通过私网将内存中的数据同步到另外一个节点时,速度非常快,但是接收端的网卡处理不了这么高的流量,大部分流量在达到数据库LMS进程之前就已经被丢弃。于是发送端LMS进程就会不停地重传数据,继而私网流量会持续很高,由于接收端节点一直处理不了网络数据,导致两端LMS进程无法正常通信,最终导致数据库实例重启。
模拟场景二:创建30G普通表带主键索引在节点1进行truncate操作。
测试结果:故障重现,主机私网流量出现突增,节点2因私网通信中断导致LMS进程无法通信,节点2实例发生重启,手动尝试拉起节点2,节点1实例hang。怀疑与主键索引有关。
模拟场景三:创建30G普通表不带主键索引在节点1进行truncate操作。
测试结果:故障重现,主机私网流量出现突增,节点2因私网通信中断导致LMS进程无法通信,节点2实例发生重启,手动尝试拉起节点2,节点1实例hang。排除索引造成故障。
模拟场景四:创建30G分区表带主键索引在节点1进行truncate操作。
测试结果:故障重现,主机私网流量出现突增,节点2因私网通信中断导致LMS进程无法通信,节点2实例发生重启,手动尝试拉起节点2,节点1实例hang。排除故障与表的类型相关。
模拟场景五:创建1G普通表在节点1进行truncate操作。
测试结果:故障未重现,私网流量未出现明显增长。
通过分析故障模拟过程收集到的相关dump日志信息,具体分析过程如下:
1)System dump能看到都是'ges remote message'和'gcs remote message'空闲等待:
22: LMD0 ospid 10813886 sid 2223 ser 59320, waiting for 'ges remote message' (DEAD)
23: LMS0 ospid 9241566 sid 2324 ser 32079, waiting for 'gcs remote message' (DEAD)
24: LMS1 ospid 18088660 sid 2425 ser 11170, waiting for 'gcs remote message' (DEAD)
25: LMS2 ospid 6554146 sid 2526 ser 11170, waiting for 'gcs remote message' (DEAD)
26: LMS3 ospid 20579320 sid 2627 ser 62832, waiting for 'gcs remote message' (DEAD)
27: LMS4 ospid 18874922 sid 2728 ser 6615, waiting for 'gcs remote message' (DEAD)
28: LMD1 ospid 20186206 sid 2829 ser 55624, waiting for 'ges remote message' (DEAD)
29: LMD2 ospid 18809386 sid 2930 ser 5230, waiting for 'ges remote message' (DEAD)
30: RMS0 ospid 20251878 sid 3031 ser 51837, waiting for 'rdbms ipc message' (DEAD)
2)LMS进程trace发现tickets已使用光了,导致LMS/LMD进程无法相互通信,实例因没有响应而被驱逐。
tkt_total=1000 (min=1000) avl=750 sp_rsv=250 max_sp_rsv=250
tkt_total=2000 (min=1000) avl=0 sp_rsv=0 max_sp_rsv=250 <=================================avl =0
tkt_total=2000 (min=1000) avl=0 sp_rsv=0 max_sp_rsv=250 <=================================avl =0
tkt_total=2000 (min=1000) avl=0 sp_rsv=0 max_sp_rsv=250 <=================================avl =0
tkt_total=2000 (min=1000) avl=0 sp_rsv=0 max_sp_rsv=250 <=================================avl =0
tkt_total=2000 (min=1000) avl=0 sp_rsv=0 max_sp_rsv=250 <=================================avl =0
我们查看_lm_tickets的默认值是1000,正常情况下这个值是足够的,再结合私网流量突增在前,tickets耗尽在后,所以确认主因是私网流量突增,tickets耗尽只是被影响的。
这里可能有人并不理解什么是ticket,这里为大家简单介绍一下Oracle ticket消息机制, Oracle为了保证在实例之间传输的消息的平衡和对传输的消息的几率,控制彼此之间的合理流量而引入的一个消息机制,RAC通过ticket对彼此之间传输的流量和几率进行控制。
一个节点发送一则消息队列的同时会带着一个ticket到对端,对端的ticket会增加。本地的ticket会减少,本地节点会根据可用的buffer和已经收到的信息以及发送的请求ticket的信息(null-req)计算本地可用的tickets。当本地没有ticket可用,本地的LMS/LMD就会进入消息等待队列,并持续地检查ticket latch里的信息,判断是否有可用的ticket的信息可用。直到对端发送回message,并带回可用的tickets后,本地才能再继续发送消息到对端。如果实例间ticket短缺,就会引发LMS/LMD之间消息传输超时出现的故障。
通过视图GV$GES_TRAFFIC_CONTROLLER来获取每个节点上的avalible的ticket的数量,或者可以通过隐含参数_lm_tickets来进行控制,该参数默认值是1000,对于繁忙的OLTP系统,可以修改该参数值。
通过网络日志抓取分析私网流量突增的情况,我们在流量突增的节点1收集tcpdump信息,发现有端口的HAIP通信的TOP1进程是LMS进程,但大部分都是不带端口通信,且无法跟踪到进程。正常情况下基本上是带端口通信的。
# tcpdump -i en11 -n -w tcp.out
tcpdump: listening on en11, link-type EN10MB (Ethernet), capture size 262144 bytes
1802074 packets captured
3858360 packets received by filter
2056233 packets dropped by kernel
#
# tcpdump -a -r tcp.out|grep -i udp |awk '{print $3}'|sort|uniq -c|sort -nr|head -n 10
reading from file tcp.out, link-type EN10MB (Ethernet)
tcpdump: pcap_loop: truncated dump file; tried to read 1514 captured bytes, only got 1137
1384536 169.254.35.65
135829 169.254.35.65.51661
132783 169.254.35.65.51667
119029 169.254.35.65.51664
15490 169.254.35.65.51670
12240 169.254.35.65.51657
481 169.254.35.65.51642
425 169.254.105.87
137 169.254.105.87.15994
136 169.254.35.65.25978
#
# netstat -Aan|grep 169.254.35.65.51661
f1000f0041c06400 udp4 0 0 169.254.35.65.51661 *.*
#
# rmsock f1000f0041c06400 inpcb
The socket 0xf1000f002ff9a808 is being held by proccess 25887552 (oracle).
#
# ps -ef |grep 25887552
root 9110166 25560256 0 22:54:56 pts/9 0:00 grep 25887552
oracle 25887552 1 80 17:45:16 - 13:09 ora_lms2_xxdb1
通过分析节点1 awr报告,发现节点1覆盖故障时段的AWR中的CR块很少。
awrrpt_1_833_834.html:
gc cr blocks received 28 0.02 0.01
gc current block receive time 114 0.06 0.02
gc current blocks received 737 0.41 0.14
awrrpt_2_833_834.html:
gc cr blocks received 540 0.30 540.00
gc cr block receive time 384 0.38 384.00
gc cr blocks received 2 0.00 2.00
CR块这么少,但私网流量很高,故障分析进行到这里,基本可以确定是触发未知Bug导致。
经测试,该问题属于普遍存在,影响环境均为12.2 RAC,主机环境包括AIX平台、X86平台等。
通过联系Oracle MOS后台,多次反复沟通,最终确认触发Bug 28111583。
临时workaroud:
alter system set "_lm_tickets"=1000 scope=spfile;
alter system set "_ksxp_ipclw_enabled"=0 scope=spfile;
据了解,官方正在抓紧研发补丁,在本文编写过程中,已经发布了Linux版本的补丁。
四、总结
Truncate动作会更新段的1、2、3级位图块信息,并且在所有的节点实例上扫描 buffer cache,把该对象的CR buffers置为invalidation,并把该对象的dirty block写到磁盘,节点实例之间走HAIP相互通信。在存在垮节点访问的情况下做truncate,私网可能会有波动,但不至于很大。
但是在当前环境下,节点2完全空闲的情况下,节点2内存中理论上不存在buffer cache,这时候在节点1做truncate操作,导致私网流量突增情况,看起来不可思议,但却真实发生了,看来在12c升级的道路上需要一路打怪,方能成正果。
编辑曰:你升级到12.2了么,有什么令人崩溃的事,快来留言吧!
近期热文
近期活动
以上是关于你敢在Oracle 12c R2上做大表truncate吗?的主要内容,如果未能解决你的问题,请参考以下文章
Oracle12c 的安装教程图解(安装系统:windows 2008R2)