ORACLE 窥视索引内部结构(上)
Posted Oracle一体机用户组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ORACLE 窥视索引内部结构(上)相关的知识,希望对你有一定的参考价值。
作者简介
孙显鹏,Oracle 十年从业经验,拥有11G ocp认证,精通内部原理,擅长调优,解决疑难问题,致力于帮助客户解决生产过程过出现的性能问题,提高生产效率!爱好书法!
准备环境和测试数据:
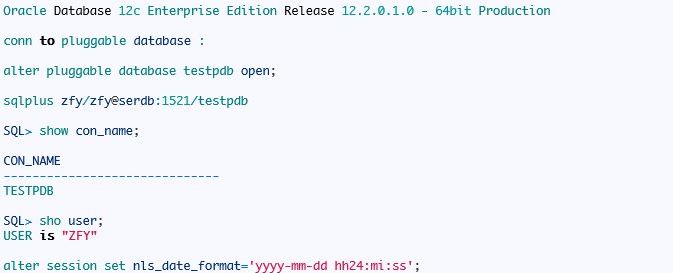
这里我们首先建立一个测试表和复合索引,看看复合索引的内部存储:
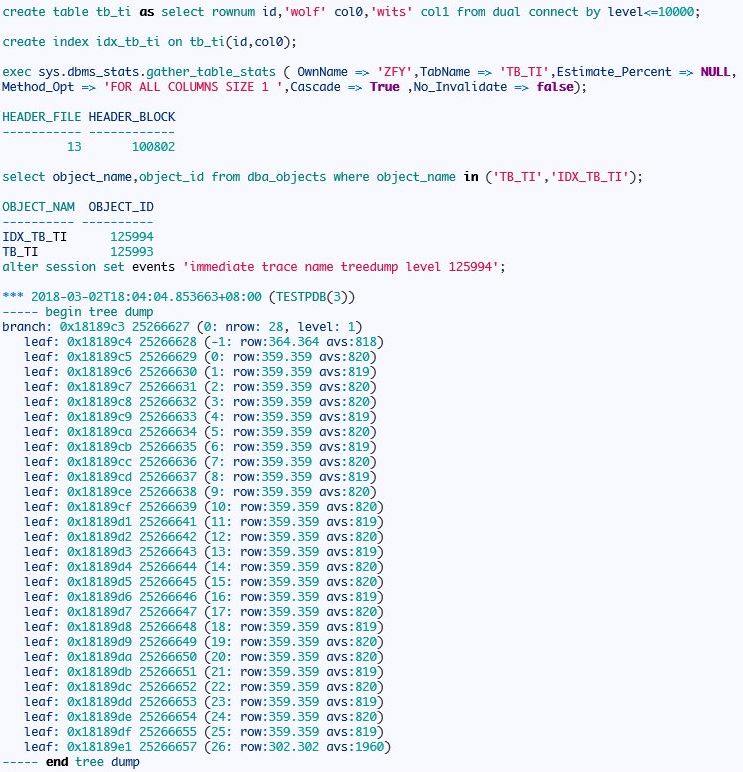
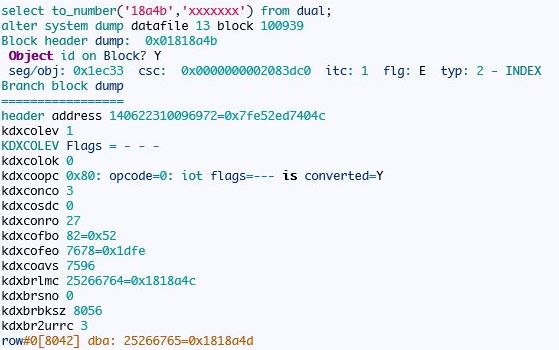
首先分析枝节点
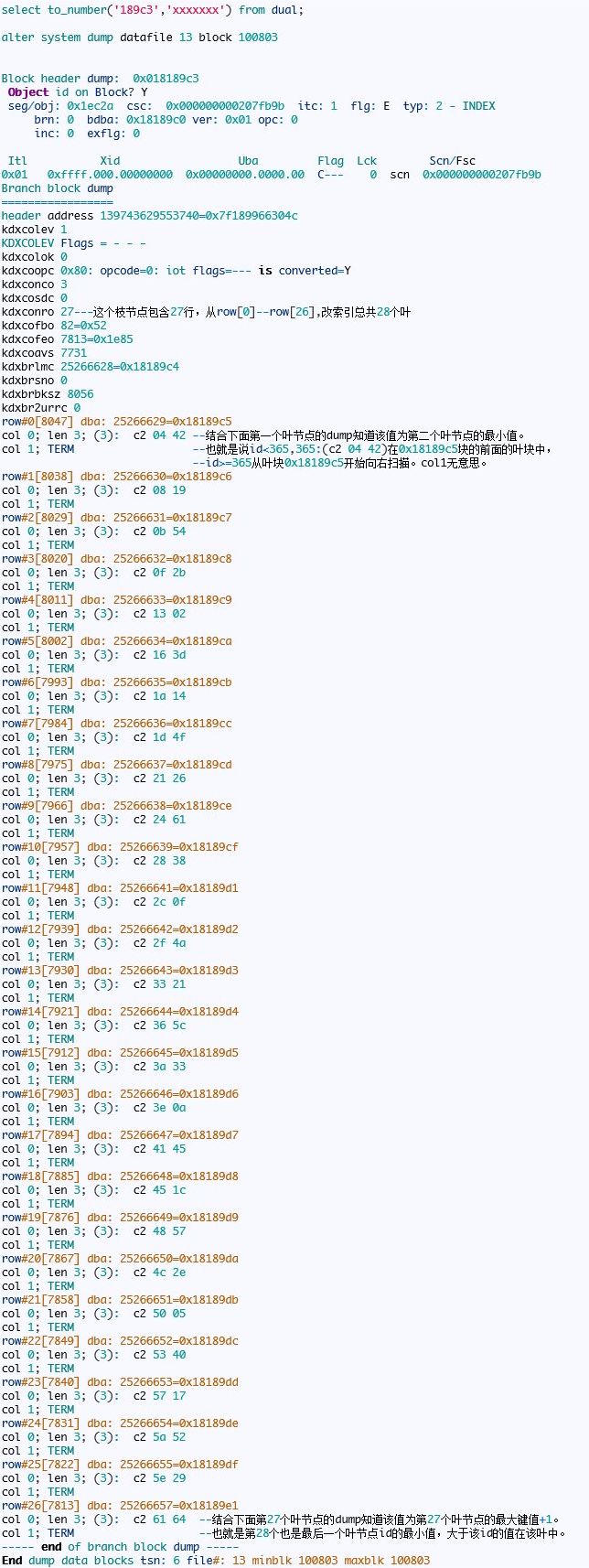
然后打印第一个叶节点的信息:
该索引的BLEVEL=1那么也就是说根节点同时也是枝节点
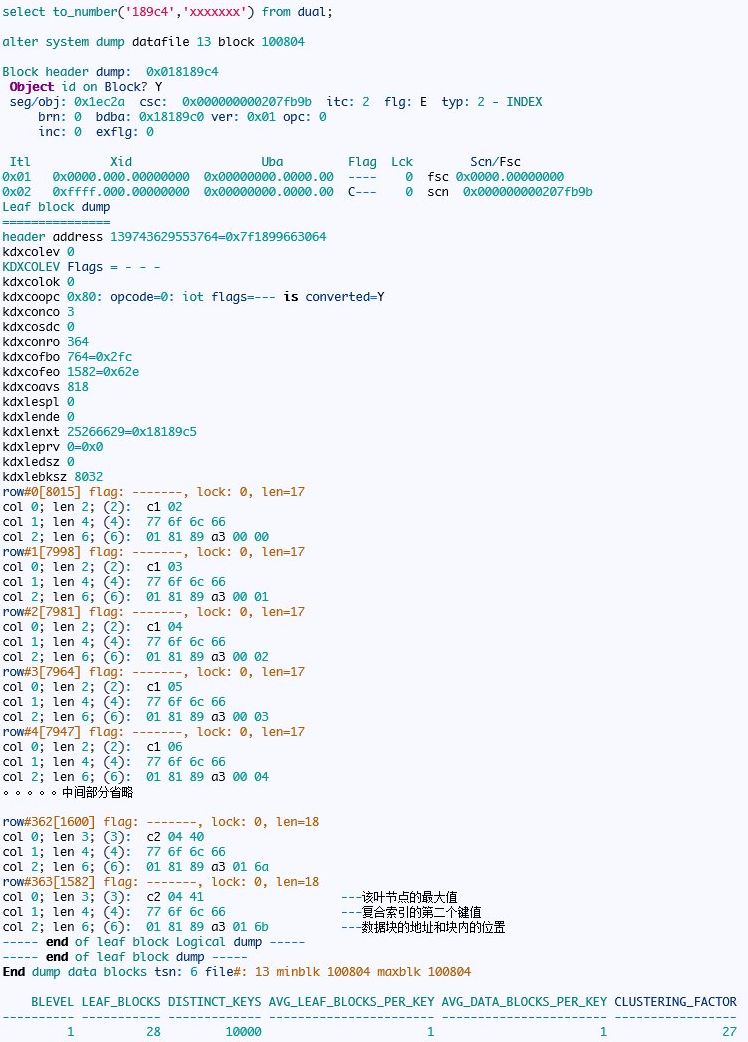
然后打印第27个叶节点的信息:
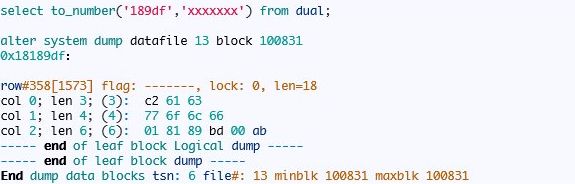
从上面的分析我们可以知道,复合索引的分支节点只存储一个键值的信息,叶节点中存在所有列的信息。
你可以依据上面的信息画出该复合索引的逻辑图,根节点就是分支节点里面存储了27个行,分别指向不同的叶。
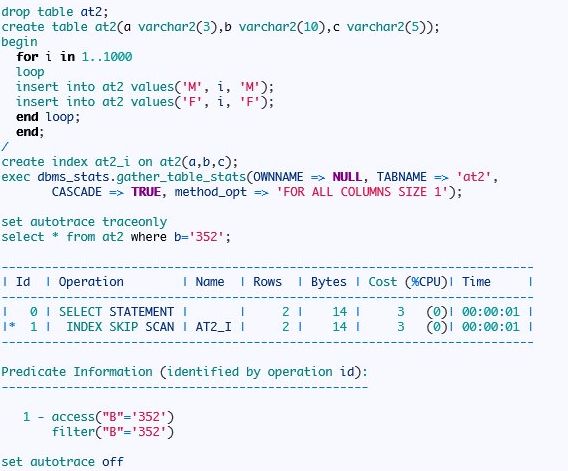
跳跃扫描:
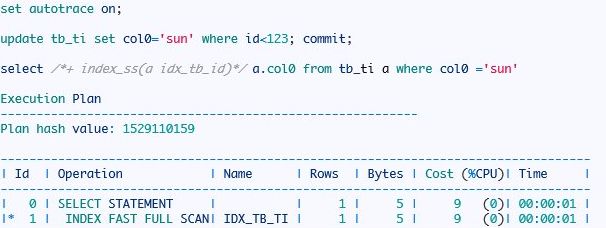
ORACLE 选择了索引快速全表扫描,并不是我们期待的跳跃扫描。
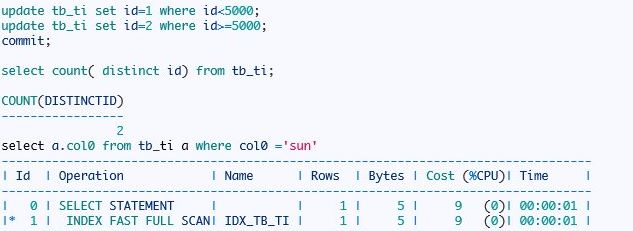
ORACLE 还是选择了索引快速全表扫描;
接下来我们重新构造表结构:
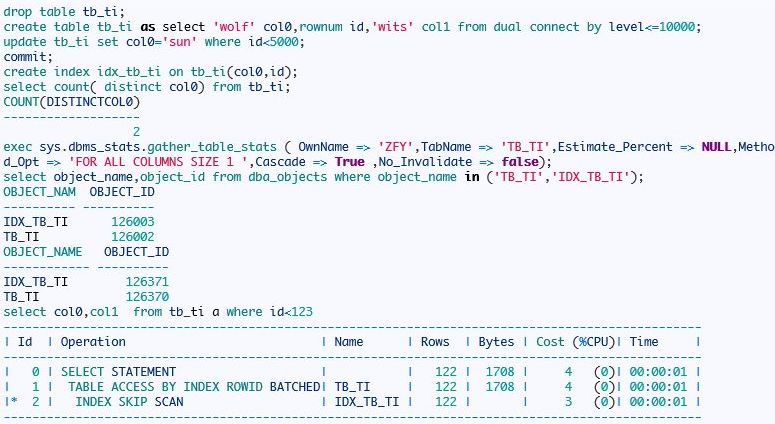
现在走了跳跃扫描,因为前导列的值较集中只有两个不同值,且第二个列值选择性很好,所以选择跳跃扫描,从这里看出来跳跃扫描的方式,接下来我们验证实际oracle扫描那些块
先打出索引结构:

接下来看看分支节点:
col 0; len 4;(4): 73 75 6e 20 –这里和上面的复合索引列值不同了,因为第一个索引第二个列值都一样oracle没有存储该值,这里两个列值都存储了,第一个就是前导列,第二个就是id的范围值,前面已经说了这里就不详细说明了。
这里需要重点说明,7375 6e 这三个值为’sun’,后面的20表示’ ‘就是一个空字符串,这个你可以dump看看。
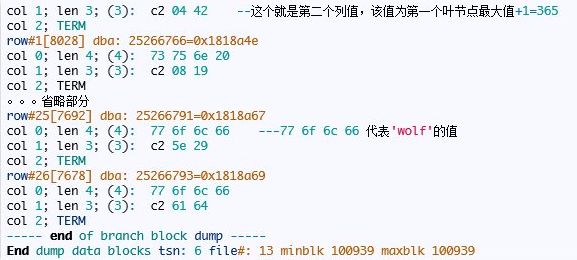
接下来看看索引叶块信息:

接下来跟踪索引跳跃扫描:
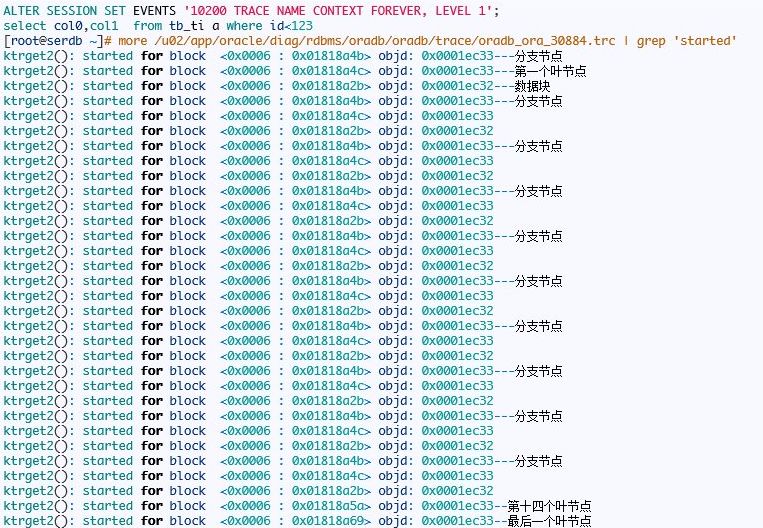
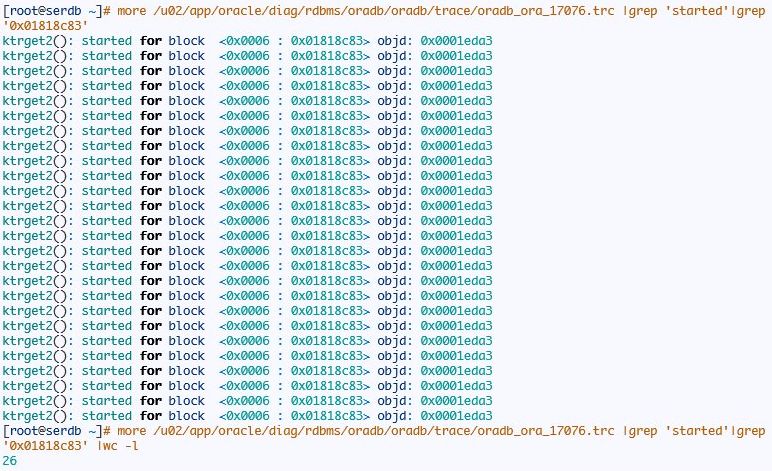
关于为什么多出一个或者两个逻辑读这里不讨论,我觉得这个影响不大,至于为什么默认的arraysize=15这个oracle自己作出的符合大多数应用的场景吧,arraysize不能设置太大对客户端的持续响应时间是有影响的。另外我们也看到oracle访问了第十四个叶块就是col0=’WOLF’的第一个叶节点,而且还访问了最后一个叶节点。
有种说法oracle将SQL:
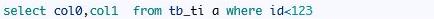
改写为:

其实这个说法是不对的。我们从谓词信息能看出来:

oracle只是通过索引访问access(“ID”<123)并且过滤filter(“ID”<123),并没有联合前导列去过滤。
下面我们看看oracle官方怎么解释跳跃扫描:
Index skip scans improve index scans against non-prefix columns since it is often faster to scan index blocks than scanning table data blocks. A non-prefix index is an index which does not contain a key column as its first column. This concept is easier to understand if one imagines a prefix index to be similar to apartitioned table. In a partitioned object the partition key (in this case the leading column) defines which partition data is stored within. In the index case every row underneath each key (the prefix column) would be ordered under that key. Thus in a skip scan of a prefixed index, the prefixed value is skipped and the non-prefix columns are accessed as logical sub-indexes. The trailing columns are ordered within the prefix column and so a ‘normal’ index access can be done ignoring the prefix.In this case a composite index is split logically into smaller subindexes. The number of logical subindexes depends on the cardinality of the initial column. Hence it is now possible to use the index even if the leading column is not used in a where clause.
可以将复合索引想象成分区表,前导列就是分区键,在索引中前导列的键值是按列值排序的,那么接下来的键值也是排序的,那么忽略了前导列,还是一个正常的索引,叫做子索引,也就是按照这个子索引然后去访问,那么既然使用子索引那么子索引的前导列需要选择率非常高查询效率才会更高。另外既然想象为分区键,那么分区键你不能选择不同值非常高的列作为分区键。所以说跳跃扫描的前导列需要符合像分区键一样,不同值较少的列。
索引全扫描:
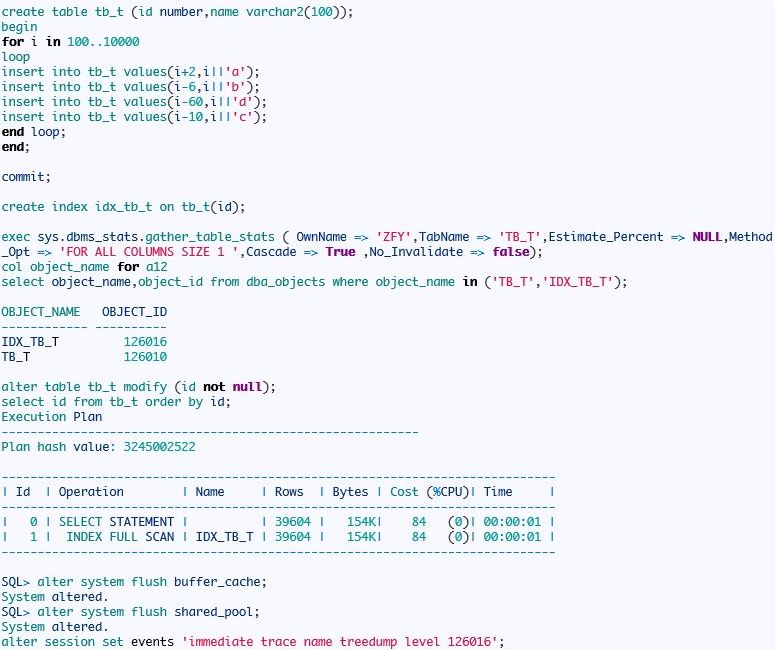
首先打印索引结构:

看看扫描方式:
从上面的信息可以看到索引全扫描是从最左边叶节点开始一直扫描到最右边的叶节点。因为索引值是排序的,所以where条件中存在order by 时oracle采取了索引全扫描。注意索引全扫描条件比较苛刻,id列存在非null约束时我们的案例才能成功的。比如另外一种情况如,id 列没有非null约束,我们只查询id列,且条件中存在 id is not null和 order by id 时:
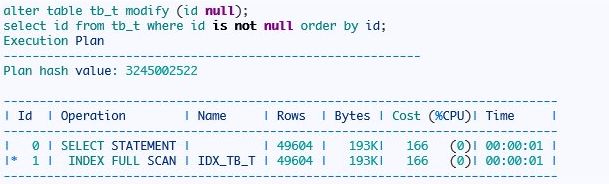
当然还有复合索引采用全扫描的,大家可以自己试验。我这里只介绍内部扫描方式。
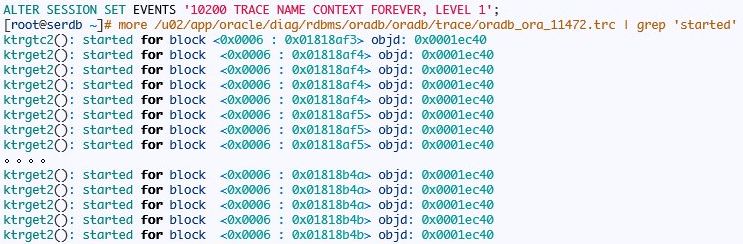
接下来我们看看索引快速全扫描:
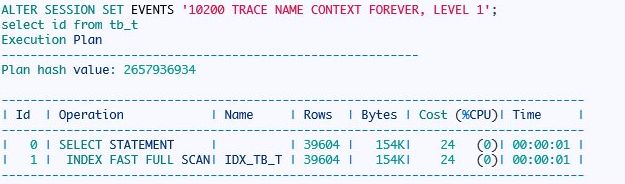

在trace文件中我们可以看到下面信息:
所以索引快速全表扫描采取散列读,依次读取多个叶块,但不能保证键值有序,这里的有序性需要注意。
原创文章,版权归本文作者所有,如需转载请注明出处
喜欢本文请长按下方的二维码订阅Oracle一体机用户组
以上是关于ORACLE 窥视索引内部结构(上)的主要内容,如果未能解决你的问题,请参考以下文章