梁晓龙:一次基于Oracle数据库BS业务架构的全方位优化实践
Posted ABCLink社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了梁晓龙:一次基于Oracle数据库BS业务架构的全方位优化实践相关的知识,希望对你有一定的参考价值。
题记
很多复杂问题的实质都是简单的逻辑问题,甚至上升不到技术层面,静下心来与客户聊清楚业务逻辑,找到错误现象发生时候各个模块的表现特征,进行简单技术调整后,再观察再修补,这是处理一些综合问题的思路。所以文章题目起的再大再酷炫,解决问题的还是简单的技术细节。
猜想阶段
一个老牌传统行业客户出现了业务界面报错、中间件卡顿、数据库性能差的问题,最直接的表现是业务人员在登录业务系统进行操作时候出现加载缓慢、页面丢失的情况,导致业务人员对于系统诟病无数,影响业务正常进行的同时,也让业务小伙伴很抓狂。到现场后,主管业务系统的甲方同志素质好、形象佳、有才华、大高个、态度和蔼、乐呵呵。把问题描述的很清楚,这点让我们的工作比较容易开展起来。
基本痛点如下:
1、业务用户登录系统出现大量页面丢失问题。
2、 即使登录后,由于业务用户的连接,中间件出现大量粘滞进程,中间件的负载分担也不平衡,导致中间件某个节点宕机。
3、 数据库在查询时期出现卡顿。
一般对于遇到问题的初步做法,我的习惯可以概括为两个字:“瞎猜”。
对于这样的架构,首先映入眼帘的是这样的印象,由于客户采用的是B/S结构,而且整个架构当中并没有采用MQ等队列产品,这样设计的问题是容易在大量session加持下发生,将资源的争用延伸到数据库的后端,虽然在weblogic层面可以设置队列等待,但是weblogic 在等待队列超过一定时间后就会放弃重试,报出overload的错误,用weblogic 的连接池来限制数据库连接也不是专业的做法。所以,有没有可能大量的资源争夺放到了后端的数据库中产生了等待。这时候就涉及到了一个并发量的问题,如果是12306那样的并发,那基本上就可以确定问题,所有连接涌入数据库,数据库死导致中间件死导致页面丢失导致各种问题导致全死。问了下客户,基本连接为月底高峰时候每天300左右,平时很少,而且特别重要的一点是“并发少”,之前的峰值都是累计数值。那,应该是猜错了。
猜过了两个问题,还有个中间件的问题,中间件宕机的话,可能原因很多,中间件也会给出提示,比如内存溢出、连接池overload等。但是出现粘滞线程问题的话,大多是并不是线程问题,而是在对数据库连接的时候出现了返回内容量大、返回时间长的问题,其实看似是中间件问题,更多的是SQL优化的问题。
了解阶段
基本上能猜的差不多了,接下来就了解具体情况,首先是公司整体架构:
数据库架构优化
作为数据库工程师首先上数据库瞧一瞧,数据库各个节点采用了大内存服务器小内存数据库的做法,基本上传统行业的服务器都拥有这三个问题:一个是数据库所在服务器内存很大,但是数据库本身的所使用的内存却很小。另一个是,大面积使用memory_target的自动调节,一般情况下我们会将全局内存自动扩展关闭,而使用sga自动扩展+pga自动扩展的方式,有时候甚至会指定shared_pool的大小。最后一个是,trail_audit的打开,这个参数是负责数据库审计监控的,如果想用数据库级别的审计来控制登录行为,会对数据库有很大的性能影响,SYSAUX也会暴涨,其实一般企业用不到这个功能,能用的企业也不应该通过数据库这种方式或者建立数据库触发器的方式来记录数据库登录行为,如果出现问题,还是应该采用踢皮球的方式解决问题,这个属于业务优化缓解数据库性能,不用谢。以下为审计记录,audit_trail设置为none即可。
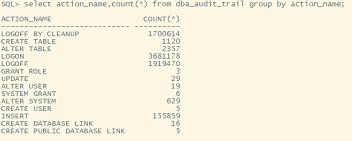
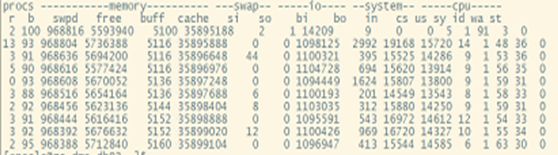
其中与内存小有关的还有个参数为”_small_table_threshold”,该隐含参数控制着数据库中直接路径读的比重,直接路径读是11g中的新特性,但是过多的直接路径读发起的段检查点将导致数据库IO比重加大,如何控制直接路径读与内存读取的比重是个难点,而超过”_small_table_threshold”的表将采用这种方式进行数据加载(之前的客户中,很多银行有因为网卡性能低,导致gc等待传递的问题,不知道是否可以考虑这种方式缓解性能压力呢?),通过“_serial_path_read”禁用直接路径读后,IO也出现了大幅度降低。可以给大家看下大量访问aud$,同时有直接路径读情况下的系统性能的表现:
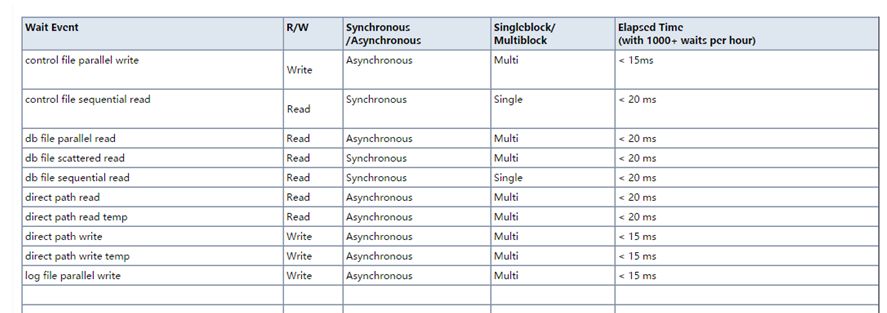
关于IO性能的基本指标,MOS上有现成的标准图,可以给大家附图:
数据库SQL优化
在SQL层面上,出现了大量的select..for update 语句引起的Enq行级别锁定,导致了长时间语句没有响应,这点与大量中间件粘滞进程是对应的,对于这种问题做了以下两点:
1、修改select …for update 为select ….for update nowait ,其实就业务逻辑设计而言,不应该出现这种锁定,因为一个业务代表着一行,出现锁定代表着自己锁定自己,那为什么会有这种问题呢,这源于SQL的执行时间,当业务用户点击保存后,中间件长期未返回记录,用户此时关闭浏览器或者由于网络原因丢失界面,用户认为数据未保存,再做一次提交时,由于上次保存操作还在继续从而发生了这种等待。等待引发了中间件粘滞,反而把中间件搞宕机了,形成了恶性循环。在我们未解决页面丢失等问题的时候,我们采用的nowait方式将保证中间件的稳定。
2、程序层面将超过5分钟执行时长的事件,进行事务回退,这步操作相当于是上一步的保险操作,在与业务与开发人员了解实际情况后,我们确定了5分钟这个数值,但是在编程层面由于采用了多线程编程,略微花费了一些时间。
3、SQL优化,许多SQL语句没有用到既有的索引,许多开发人员知道在条件上建立索引,却很少在连接条件中建立索引,而且对于未用窗口函数导致的多次自连接问题并不清楚,在进行了索引优化、窗口函数优化自连接后,SQL性能发生很大改善,这些SQL优化也属于简单的优化技巧,这里一笔带过。很多文章将SQL优化吹捧的很神圣,其实即使给你一条100行的SQL,你今天看看,明天试试索引,百度百度,跑一跑,也能估摸出个一二来,而且未来 Oracle数据库用不用人去参与优化真是未知数。技术不重要,思路很重要。
从客户端请求处,可以看到session_id 中多了F5的会话保持标签BIGip。
未修改前:

修改后:
遗留问题
经过一顿叮铃咣当后,我们发现中间件稳定了,业务那边的性能也提高了一些,但是有个问题一直没解决,就是偶尔页面丢失的问题,客户出现“网页无法找到”,多次刷新后,网页又找到了,这个问题我怀疑是网络的原因,尤其是防火墙部分的性能,由于对于业务影响不大,所以没有继续追查。
总结,本次调整涉及到的方面比较多,基本满足客户的需求和调整要求,整个调整过程中,用到的技术点都比较简单,没有高大深的问题,分析思路和方法也有很多瑕疵,并且许多细节问题无法一一在文章中列出,希望大家谅解。
作者简介
梁晓龙
海量数据售前工程师,原IBM售后工程师、项目经理,从事数据领域技术与管理工作,拥有多年项目实施与调优经验,并在大数据与算法领域有较深造诣,目前专注数据领域,擅长故障排插与调优
ABCLink 社区
人工智能 大数据 云计算
技术 | 管理 | 分享 | 互助
大咖云集,你不能缺席
以上是关于梁晓龙:一次基于Oracle数据库BS业务架构的全方位优化实践的主要内容,如果未能解决你的问题,请参考以下文章