你知道Oracle的Sequence序列吗?
Posted GitChat精品课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你知道Oracle的Sequence序列吗?相关的知识,希望对你有一定的参考价值。
1. sequence基本介绍
2. sequence性能问题
3. 18c的sequence新特性
4. 一些开发中sequence的使用经验
1. sequence基本介绍
下图是11g的《Reference》,对于create sequence语法的介绍,
可以知道,sequence有一系列参数,可以辅助序列的创建,实现各种需求,
INCREMENT BY:步长,不能为0,正值最大28位,表示升序,负值最大27位,表示降序。该参数的绝对值,必须小于MAXVALUE和MINVALUE之差。默认值为1。
START WITH:起始值,对于降序序列,默认值为序列的最大值,对于升序序列,默认值为序列的最小值。
MAXVALUE:最大值,正值最大28位,负值最大27位,MAXVALUE >= START WITH,MINVALUE > MAXVALUE。
NOMAXVALUE:对于升序序列,最⼤值为1028-1,对于降序序列,最⼤值为-1,该参数为默认值。
MINVALUE:最小值,正值最大28位,负值最大27位,MINVALUE <= START WITH,MINVALUE < MAXVALUE。
NOMINVALUE:对于升序序列,最小值为1,对于降序序列,最小值为-(1027 -1),该参数为默认值。
CYCLE:表示序列值到达最⼤或最⼩值后继续循环生成新值。
NOCYCLE:表示序列值到达最大或最小值后不会生成新值,该参数为默认值。
CACHE:表示在内存中缓存多少个序列值,最大28位,最小值为2,对于CYCLE=Y的序列,CACHE的值必须小于循环的序列值,CACHE允许的最大值必须小于如下公式:CEIL (MAXVALUE - MINVALUE)) / ABS (INCREMENT)如果数据库崩溃,还未提交的缓存序列,就会丢失。RAC下建议使用cache选项。
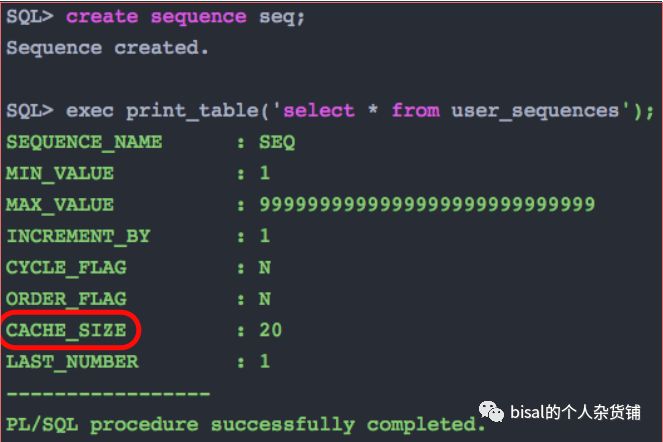
NOCACHE:不缓存序列值,如果不指定CACHE和NOCACHE,默认缓存20个的序列值。
ORDER:表示序列会按照请求的顺序,生成序列值,如果使用序列,作为时间戳,则此参数有用,但若作为主键,未必需要保证序列的顺序。如果用的RAC,ORDER是唯一可以保证按序创建序列值的方法,除此之外,序列都是按序产生的。
NOORDER:不需要保证序列按序创建,这是默认配置。
通常我们创建一个序列,会包含这些常用的参数,

要了解sequence背后,Oracle做了什么,可以执行10046事件,例如执行create sequence bisal_seq语句,10046的trace记录如下,会向seq$插入记录,从字段名称可以看出,存储的是sequence相应的参数值,
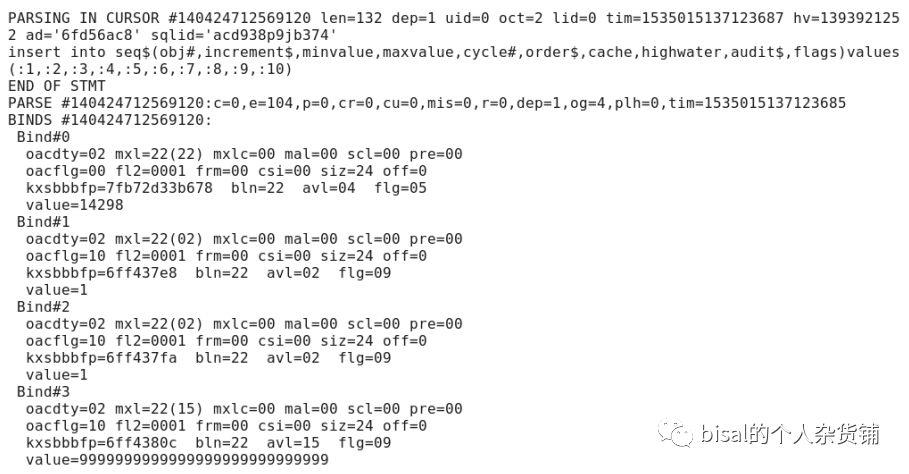
同样检索seq$,可以和上述trace对应起来,

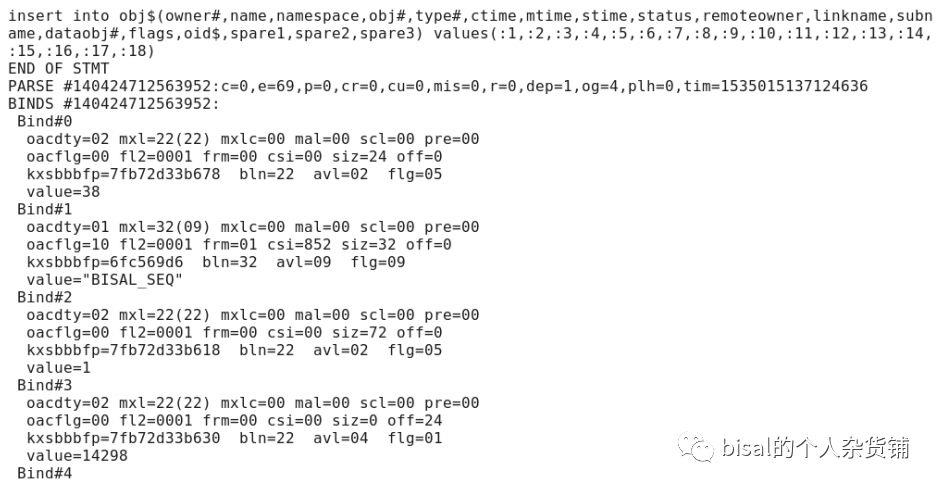
同时,会向obj$插入一条对象的记录,标记序列对象,
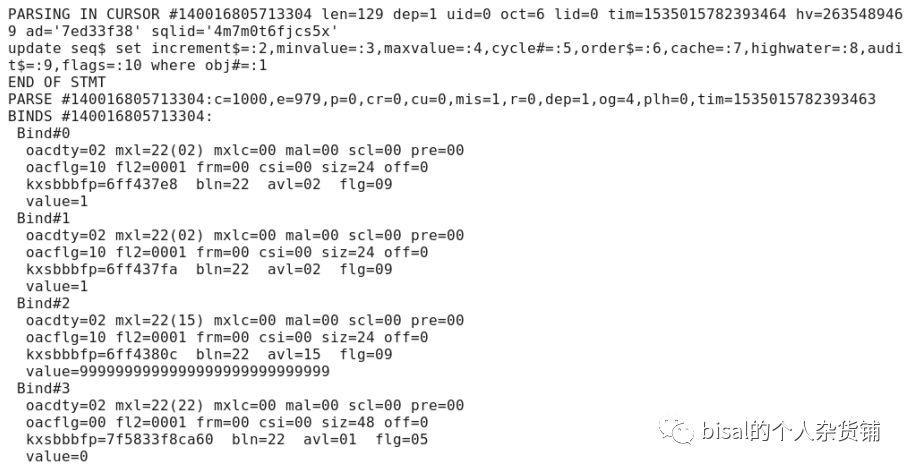
执行检索select bisal_seq.currval, bisal_seq.nextval from dual语句,会更新seq$,主要更新highwater高水位,因为序列要保证值唯一,
创建序列,不带任何参数,默认参数值如下,
问题1:cache存储的是什么?
有些人可能认为存储的是1,2,3...20,但实际存储的是目标值,例如20,其他值存储在缓存中。
问题2:缓存在什么位置?
序列值是基于会话读取的,但并不是存储在会话中,而是存在SGA。
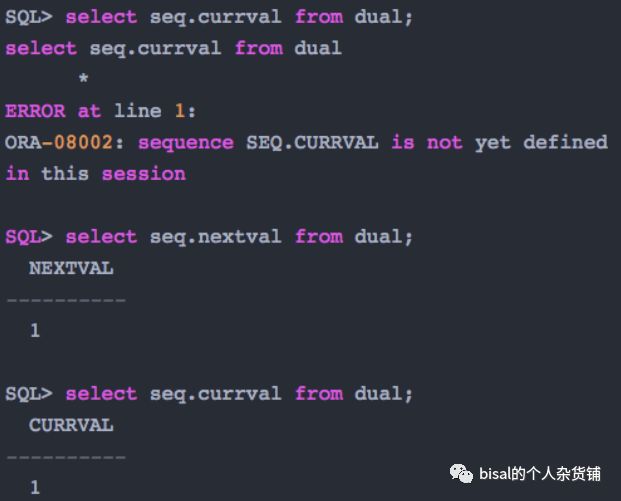
语法上,会话中首先要nextval,否则直接currval,会提示错误,使用nextval取出下一值,就可以用currval查看当前值了,
2. sequence性能问题
sequence是非常普通的Oracle对象,但如果使用不当,就可能会导致一些性能问题,如下介绍了三个场景。
场景1:RAC下,nocache选项创建频繁使用的sequence
从之前介绍中,我们了解了,当需要读取的sequence值,到达了当前cache的最大值,就会更新seq$的highwater,这样做的目的,就是为了保证序列值唯一。如果创建序列,不使用cache选项,相当于每次使用序列,都要更新seq$表。如果使用的是RAC,每个节点使用了序列,都要更新seq$,可能出现的场景,就是seq$表的数据块,会在实例之间频繁地传输,进而就可能产生一些gc相关的等待事件,造成性能问题。因此RAC下,对于频繁使用的序列,用nocache选项非常危险。
场景2:RAC下,order选项创建频繁使用的sequence
创建序列,可以采用order选项,为了可以按顺序产生序列值,在RAC下,由于存在多实例,为了保证不同节点间,序列产生的值是连续的,会使用特殊的全局锁(SV)来控制,序列当前值就是通过这个锁的流转来传送,实现跨实例串行化生成序列值,频繁使用序列,就可能会出现DFS lock handle、latch: gets resource hash list、row cache lock等待事件,造成性能问题,因此尤其对于RAC,用order选项创建频繁使用的sequence非常危险。
场景3:sequence作为主键或者唯一键
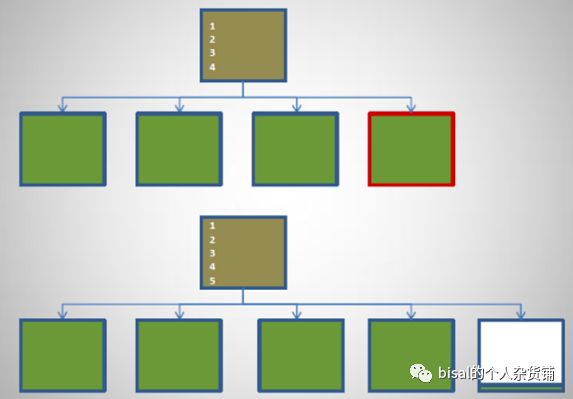
无论sequence无论作为主键还是唯一键,都会自动创建一个唯一索引,由于他的值是递增产生的,因此总会发生索引单向增长,如下图所示,对于递增的序列,总会在B树索引最右侧的索引块,插入新值,当数据块没有空间的时候,就会发生9-1分裂,创建新的数据块,因此争用总会发生在索引叶子节点的最右侧数据块上,
其实针对这问题,之前RWP的Andrew就有介绍,另外,我们系统设计初期的POC,碰见了相同的问题,有三种解决方案。
方案一:将索引重建为reverse-key index
这种方案,可以缓解索引热块的争用,但是随着数据量的增加,索引越大,对于范围检索,一次检索可能需要读取到buffer cache的索引数据块就会越多,一方面可能会产生磁盘IO方面的等待,另一方面可能会将其他表或索引的数据挤出内存,因此,很有可能只是从索引争用,转换成另一种资源的等待,没有从根本解决这个问题。
方案二:将索引重建为hash partition index
如果是单实例,这种方案会有效,因为他将原先争用的块数据,分散到了不同的数据块,但是,如果迁移RAC,由于频繁的使用,可能会出现索引数据块在节点间频繁的传输,而且随着节点数增加,传输的可能性就会越大,还是会产生性能的问题。
方案三:编码生成的智能主键
其实,我们所要解决的,就是这三个问题,
问题1:避免实例间传输
问题2:避免索引单向争用
问题3:保证序列取值不重复
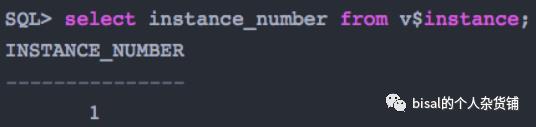
针对问题1,我们选择实例号,作为序列的开始,保证数据插入,会保存在节点的一边,
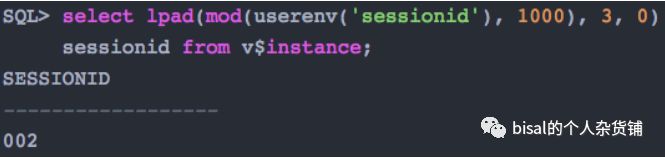
针对问题2,我们选择进程号取余,将索引的维护分散到同⼀实例的多个内存块上,
针对问题3,我们选择sequence,保证唯一,
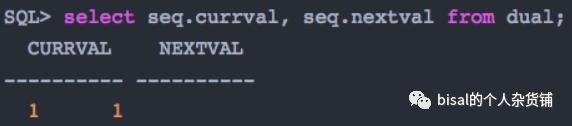
因此,我们的智能主键,算法如下,
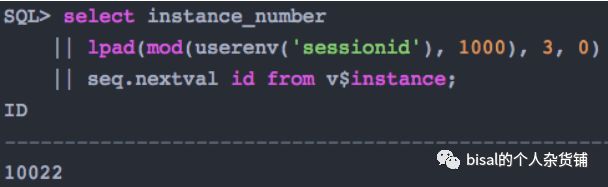
又或者可以这样,
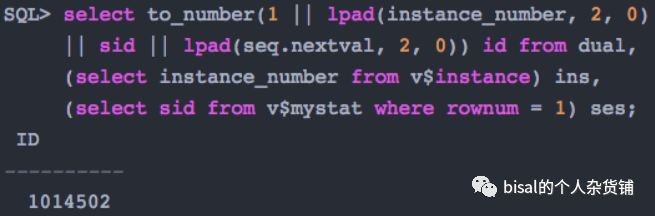
虽然SQL上略有区别,但是中心思想,是一致的,就是根据实例号、进程号、以及序列值,拼接出能避免实例间传输、避免索引单向的争用、以及保证唯一的主键值。
3. 18c的sequence新特性
上一节案例三,作为RWP的经典案例,智能主键的解决方案,已经整合进了Oracle 18c数据库层面,这个功能就是Scalable序列,即可伸缩序列,这个功能在12.2就已经引入,但是作为隐藏的功能,在18c中,才正式推广出来。
语法很简单,多了SCALE/NOSCALE/EXTEND/NOEXTEND这些参数,
CREATE | ALTER SEQUENCE sequence_name
…
SCALE [EXTEND | NOEXTEND] | NOSCALE当SCALE语句被指定时,一个6位数的数字被指定作为序列的前缀,末尾是正常的序列数字,两者联合成为新的序列:
scalable sequence number =
6 digit scalable sequence offset number
|| normal sequence number参数介绍如下,

指定了SCALE,偏移量的算法是:
(instance_id % 100)(_kqdsn_instance_digits) + 100
|| (session_id % 1000)(_kqdsn_cpu_digits)
|| seq(EXTEND/NOEXTEND确定是否固定宽度)其中隐藏参数_kqdsn_instance_digits和_kqdsn_cpu_digits,可以在会话级和实例级调整,默认这两个参数值为2和3。
EXTEND表示序列总长度=[X个数字+Y个数字],X默认值是6位数,Y是MAXVALUE指定的位数。对于EXTEND来说MAXVALUE代表的后面正常序列的长度,而不是可伸缩序列的总长度。
NOEXTEND(SCALE默认值)
表示序列总长度不能超过MAXVALUE定义的长度,由于前面默认是6位数+
正常的序列号,所以长度最少是7位数。对于NOEXTED来说MAXVALUE
代表的是可伸缩序列的总长度。
如果默认,会采用NOEXTEND,定义6位长度,则会提示错误,因为前面6位已经占满了,要么增加一位,要么改为EXTEND,
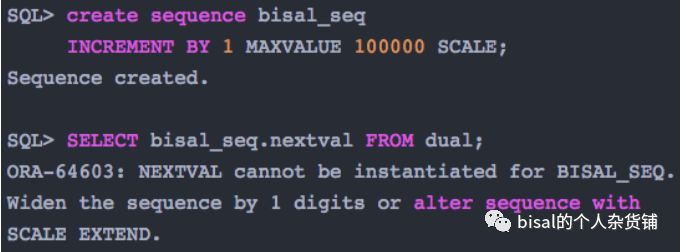
NOEXTEND,指定7位,则可以创建,
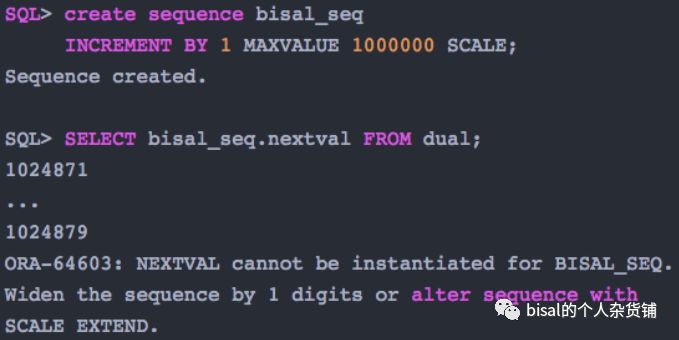
如果指定了EXTEND,则只需要指定序列的长度,
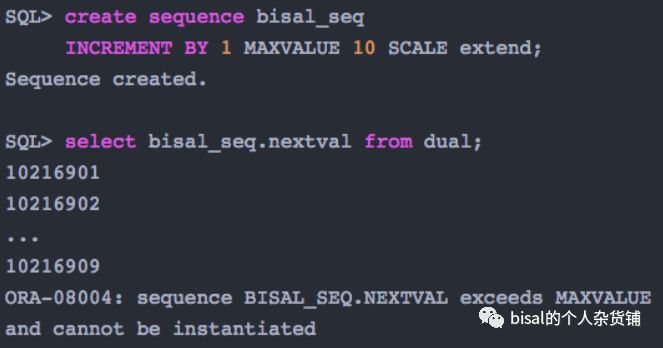
可以看出,使用SCALE参数,就可以实现原来编码才能实现的智能主键的功能,由于值分散开了,因此会降低索引的争用,从数据库层面,解决了实例间的传输、索引单向的争用、以及保证唯一的主键值。
4. 一些开发中sequence的使用经验
在开发中对于sequence的使用,会有一些技巧和经验,下面介绍两个我们日常开发可能碰见的需求场景,
第一个场景案例,是如何使用jdbc读取新插入Oracle的sequence值,这个案例来自于斗佛博客的介绍(https://blog.csdn.net/yzsind/article/details/6918506,版权归属斗佛),提出了五种读取sequence值的方法。
首先,作为准备工作,如下是得到数据库连接的公共代码,
public Connection getConnection() throws Exception{
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance();
Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:dbname", "username", "password");
return conn;
}方法一:
1. 先用select seq_t1.nextval as id from dual取到新的sequence值。
2. 然后将最新的值通过变量传递给插入的语句:insert into t1(id) values(?)
3. 最后返回开始取到的sequence值。
这种方法的优点很明显,就是代码简单直观,易理解,使用的人也最多,缺点是需要两次sql交互,性能不佳。
public int insertDataReturnKeyByGetNextVal() throws Exception {
Connection conn = getConnection();
String vsql = "select seq_t1.nextval as id from dual";
PreparedStatement pstmt =(PreparedStatement)conn.prepareStatement(vsql);
ResultSet rs=pstmt.executeQuery();
rs.next();
int id=rs.getInt(1);
rs.close();
pstmt.close();
vsql="insert into t1(id) values(?)";
pstmt =(PreparedStatement)conn.prepareStatement(vsql);
pstmt.setInt(1, id);
pstmt.executeUpdate();
System.out.print("id:"+id);
return id;
}
方法二:
1. 先用insert into t1(id) values(seq_t1.nextval)插入数据。
2. 然后使用select seq_t1.currval as id from dual返回刚才插入的记录生成的sequence值。
注:seq_t1.currval表示取出当前会话的最后生成的sequence值,由于是用会话隔离,只要保证两个SQL使用同一个Connection即可,对于采用连接池应用需要将两个SQL放在同一个事务内才可保证并发安全。另外如果会话没有生成过sequence值,使用seq_t1.currval语法会报错。
这种方法的优点,可以在插入记录后返回sequence,适合于数据插入业务逻辑不好改造的业务代码,缺点是需要两次sql交互,性能不佳,并且容易产生并发安全问题。
public int insertDataReturnKeyByGetCurrVal() throws Exception {
Connection conn = getConnection();
String vsql = "insert into t1(id) values(seq_t1.nextval)";
PreparedStatement pstmt =(PreparedStatement)conn.prepareStatement(vsql);
pstmt.executeUpdate();
pstmt.close();
vsql="select seq_t1.currval as id from dual";
pstmt =(PreparedStatement)conn.prepareStatement(vsql);
ResultSet rs=pstmt.executeQuery();
rs.next();
int id=rs.getInt(1);
rs.close();
pstmt.close();
System.out.print("id:"+id);
return id;
}
方法三:
采用pl/sql的returning into语法,可以用CallableStatement对象设置registerOutParameter取得输出变量的值。
这种方法的优点,是只要一次sql交互,性能较好,缺点是需要采用PL/SQL语法,代码不直观,使用较少。
public int insertDataReturnKeyByPlsql() throws Exception {
Connection conn = getConnection();
String vsql = "begin insert into t1(id) values(seq_t1.nextval) returning id into :1;end;";
CallableStatement cstmt =(CallableStatement)conn.prepareCall (vsql);
cstmt.registerOutParameter(1, Types.BIGINT);
cstmt.execute();
int id=cstmt.getInt(1);
System.out.print("id:"+id);
cstmt.close();
return id;
}
方法四:
采用PreparedStatement的getGeneratedKeys方法,conn.prepareStatement的第二个参数可以设置GeneratedKeys的字段名列表,变量类型是一个字符串数组。
注:对Oracle数据库这里不能像其它数据库那样用prepareStatement(vsql,Statement.RETURN_GENERATED_KEYS)方法,这种语法是用来取自增类型的数据。Oracle没有自增类型,全部采用的是sequence实现,如果传Statement.RETURN_GENERATED_KEYS则返回的是新插入记录的ROWID,并不是我们相要的sequence值。
这种方法的优点,是性能良好,只要一次sql交互,实际上内部也是将sql转换成oracle的returning into的语法,缺点是只有Oracle10g才支持,使用较少。
public int insertDataReturnKeyByGeneratedKeys() throws Exception {
Connection conn = getConnection();
String vsql = "insert into t1(id) values(seq_t1.nextval)";
PreparedStatement pstmt =(PreparedStatement)conn.prepareStatement(vsql,new String[]{"ID"});
pstmt.executeUpdate();
ResultSet rs=pstmt.getGeneratedKeys();
rs.next();
int id=rs.getInt(1);
rs.close();
pstmt.close();
System.out.print("id:"+id);
return id;
}
方法五:
和方法三类似,采用oracle特有的returning into语法,设置输出参数,但是不同的地方是采用OraclePreparedStatement对象,因为jdbc规范里标准的PreparedStatement对象是不能设置输出类型参数。
最后用getReturnResultSet取到新插入的sequence值,这种方法的优点,是性能最好,因为只要一次sql交互,oracle 9i也支持,缺点是只能使用Oracle jdbc特有的OraclePreparedStatement对象。
public int insertDataReturnKeyByReturnInto() throws Exception {
Connection conn = getConnection();
String vsql = "insert into t1(id) values(seq_t1.nextval) returning id into :1";
OraclePreparedStatement pstmt =(OraclePreparedStatement)conn.prepareStatement(vsql);
pstmt.registerReturnParameter(1, Types.BIGINT);
pstmt.executeUpdate();
ResultSet rs=pstmt.getReturnResultSet();
rs.next();
int id=rs.getInt(1);
rs.close();
pstmt.close();
System.out.print("id:"+id);
return id;
}
如下是五种方法的汇总,
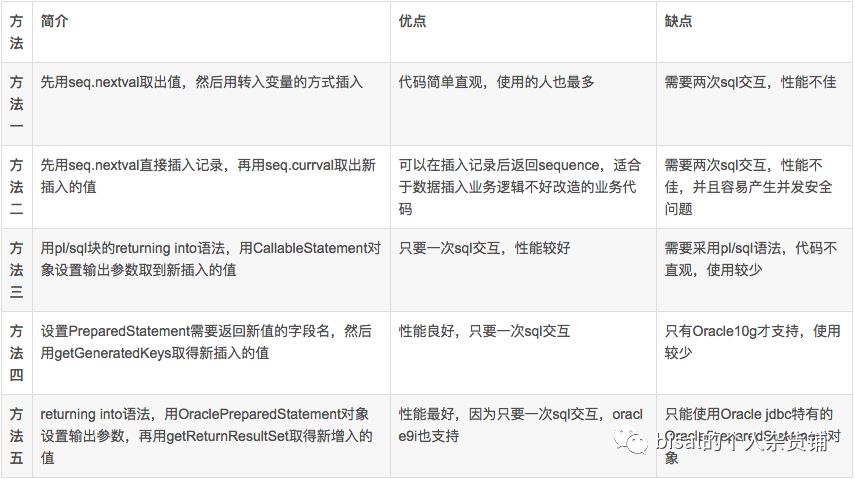
除了方案4,由于其只支持10g,我实际测试了其它几个方案,均为一次读取1000个序列值,经过测试,方法1和方法2,都因为两次交互,时间较长,方案3和方案5,由于一次交互,时间比较短,但是从可读性上,方案5要优于方案3,具体需要选择何种方案,就是实际的需求场景了,
第二个场景案例,在代码中,是如何一次性读取多个sequence值,例如假设场景,需要一次性取出5个sequence值,如何操作?
第一种方法,很直观的想法,就是for循环,一次读取一个值,循环5次,这种方法很简单,但是不高效,因为他需要和数据库交互5次,
for (int i = 0; i < 5; i++) {
select seq.nextval from dual;
}第二种方法,借助另一张表,实现次数的轮询,这种方法,仅需要交互一次,但是取决于all_objects(或者任意其他表)的数据量,比如只有1行,即使使用rownum<5,也没有作用,另一方面,如果这个序列,被频繁地使用,很有可能让这张表成为热表,
select seq.nextval from
(select 1 from all_objects where rownum <= 5);上述两种方法,各有各的缺点,第三种方法,使用了伪表,并通过层次查询connect by,实现了一次读取多个值,只交互了一次,并且没有借助外部表,相对来说,这种方法,更值得推荐,
select seq.nextval from dual connect by rownum <= 5;sequence虽然普通,但蕴含的知识,一点不少,记得eygle曾经说过,学习Oracle的一种方法,就是由点及面,其实对于任何知识的学习,这个方法都适用,通过上面对sequence各种问题的学习,充分了解、深入了解,才能让我们更好地使用他,不能仅限于“会用”的层面,这样才能不断地成长,才能遇见更好的自己。
以上是关于你知道Oracle的Sequence序列吗?的主要内容,如果未能解决你的问题,请参考以下文章