有意思的大数据利用爬虫技术能做到哪些很酷很有趣很有用的事情?
Posted 小象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有意思的大数据利用爬虫技术能做到哪些很酷很有趣很有用的事情?相关的知识,希望对你有一定的参考价值。

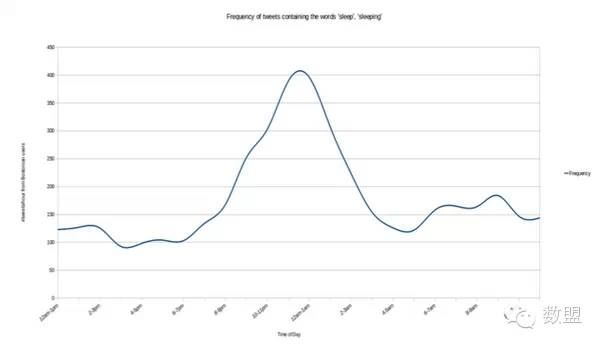
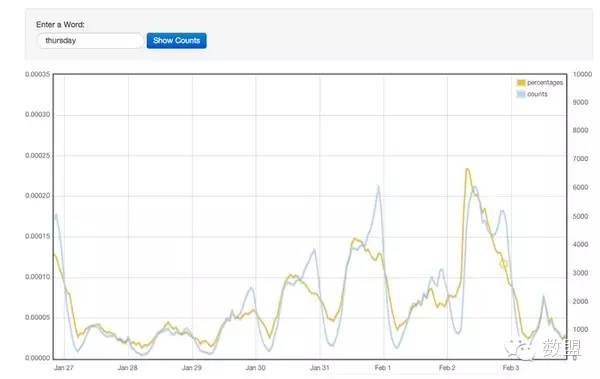
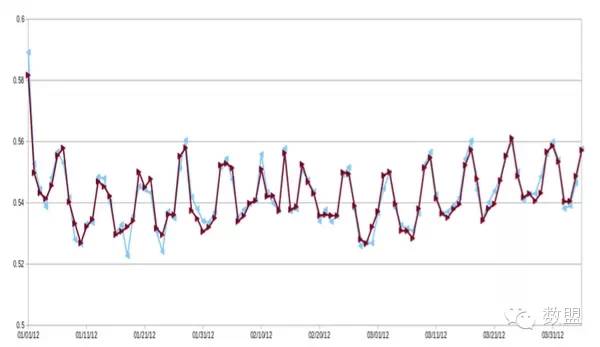
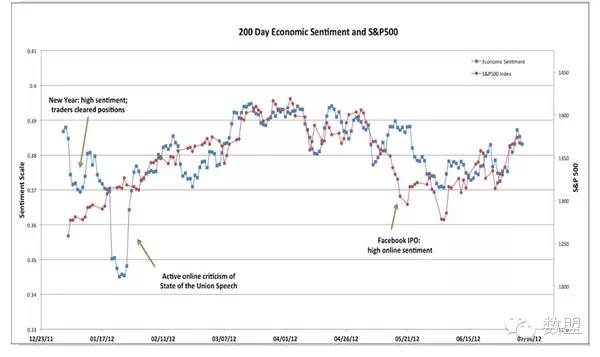
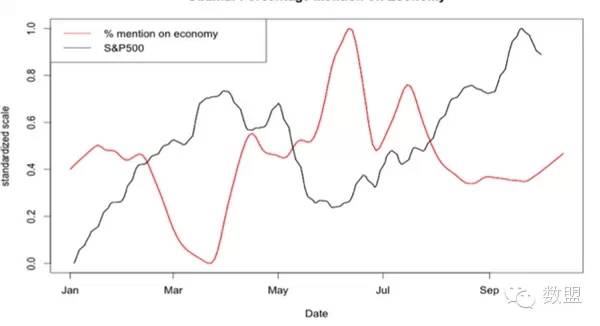
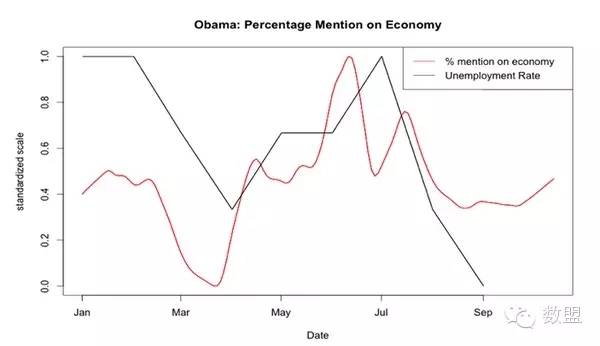
来源:知乎日报
以上是关于有意思的大数据利用爬虫技术能做到哪些很酷很有趣很有用的事情?的主要内容,如果未能解决你的问题,请参考以下文章
Posted 小象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有意思的大数据利用爬虫技术能做到哪些很酷很有趣很有用的事情?相关的知识,希望对你有一定的参考价值。
来源:知乎日报
以上是关于有意思的大数据利用爬虫技术能做到哪些很酷很有趣很有用的事情?的主要内容,如果未能解决你的问题,请参考以下文章