家园小剧场|简单爬虫技术
Posted 南昌大学家园网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了家园小剧场|简单爬虫技术相关的知识,希望对你有一定的参考价值。
首先说明本文不是一个纯粹的技术文,在看之前先把,咳,节操丢掉。
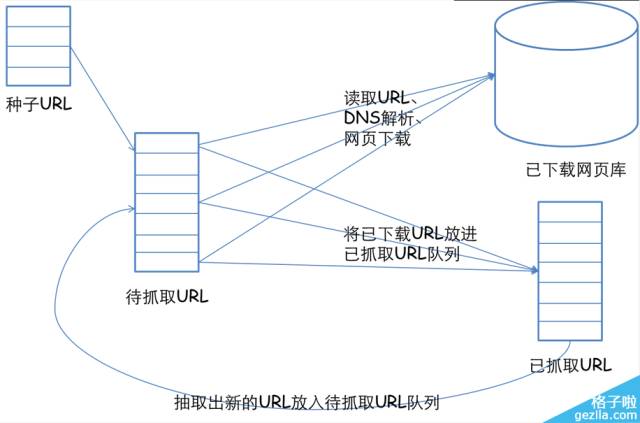
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者)
是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫
当然这些定义都不重要,重要的是你要知道,爬虫就是把你需要的信息摘取下来的程序。
而且当你对爬虫很了解的时候,你会发现什么网页都可以甚至去爬你女神的照片(希望我的女神不知道!?)
当然接下来我也会教你如何去做,那么现在就是见证奇迹的时刻,
想要写个爬虫,特别是对还没有掌握一门编程语言的同学可能相当困难。
本文是针对一些零基础的同学,所以我会讲的比较详细。
这里我推荐Sublime Text编辑器(也就是俗称的sb编辑器),
Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。
Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
至于如何安装,可以去官网下载:http://www.sublimetext.com/
既然是用Python编写,那当然要下载python啦,附上官网地:https://www.python.org/
不过在安装python之前,建议看看廖雪峰python教程,
包括如何配置环境,如何编写第一个python代码(hello,world)
像bs4,urllib,urllib2,re等等。
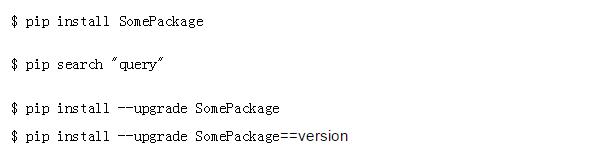
不过这都不需要太过关心,你这需要下个pip 就可以啦,再利用pip下载这些模块就可以了
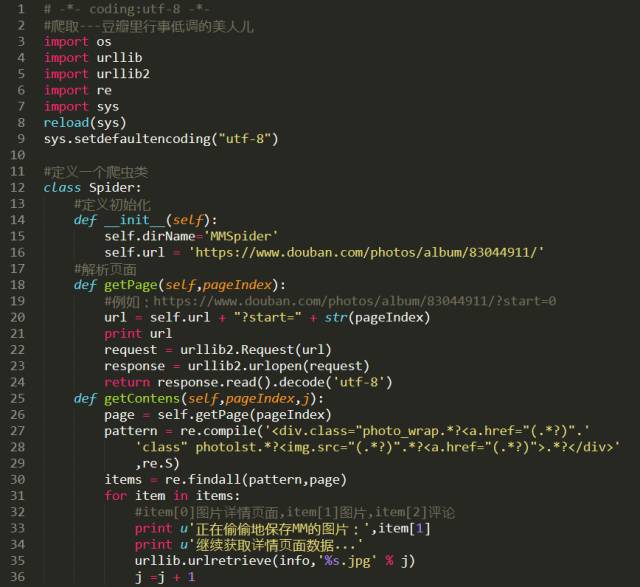
第一个简单爬虫,爬取百度页面信息,我相信很多人都是从这开始的。
urllib2(url,data,timeout)
urllib2它可以接受3个参数,其中第一个url参数是必须的,没它,你爬什么网页??
♦ response对象有一个read方法,可以返回获取到的网页内容,
♦ 在实际的操作中我们一般都是现请求网页,
然后网页接受请求,返回相应。
当然有些需要登录的才能看到信息(需要用到data参数,甚至要用到请求头headers)的网页和需要js加载的页面(需要模拟js加载),
这样直接操作是不行的,因为我们将要爬取的页面用不到这个,所以在此不讲解这些内容
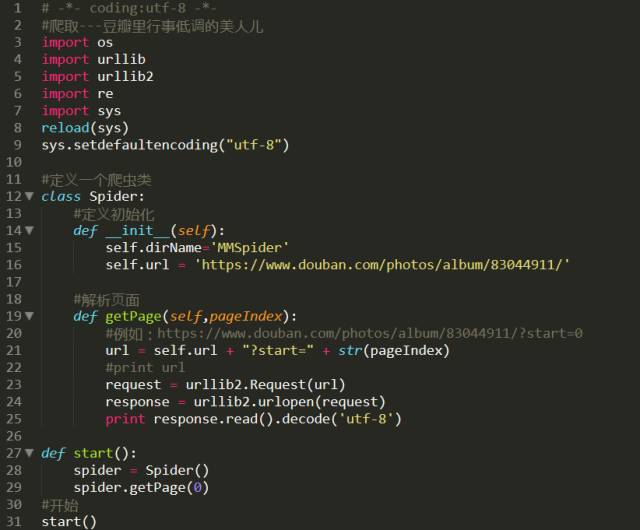
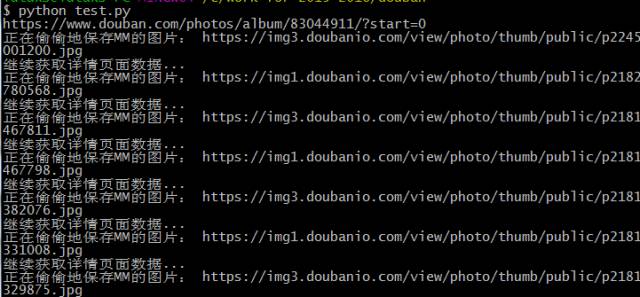
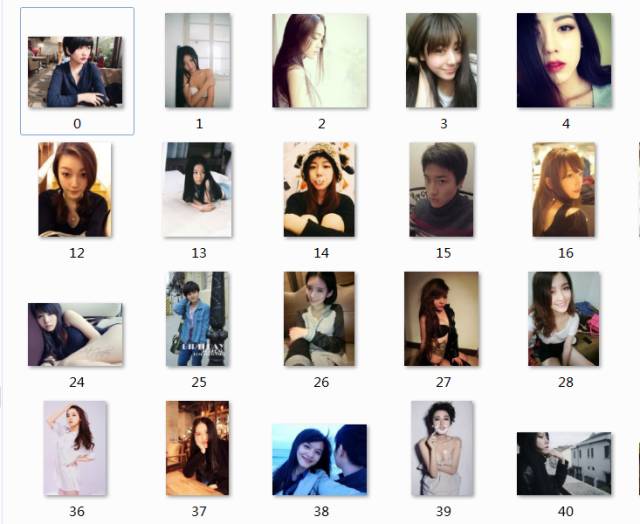
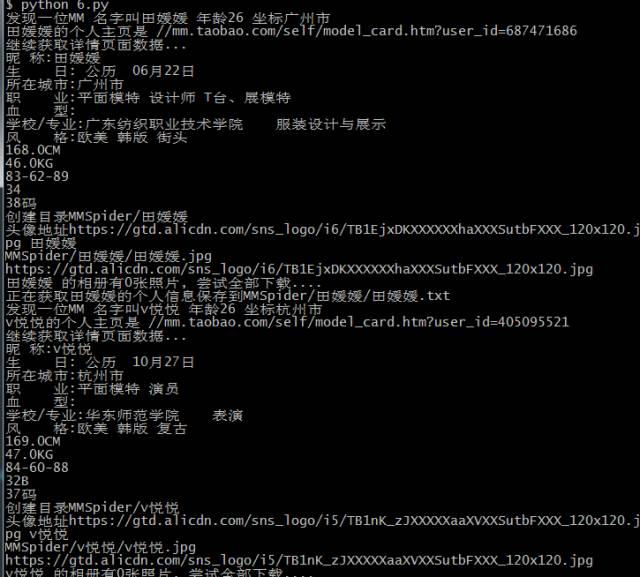
福利时间到啦,为了满足广大单身狗,和狼友们,我要写的是爬虫是爬取豆瓣MM照片
这里我找到的URL是 https://www.douban.com/photos/album/83044911/
这里为了代码的整洁和可视性,我们采用了def 函数的模式进行分布获取
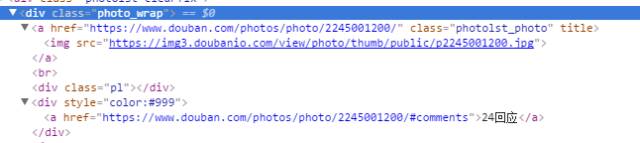
在获取到解析页面的时候,你指会发现图片放在一个<img>标签里,如何获取它呢?
连我自己都只会用简单的正则匹配,所以这里我会直接给出它的正则表达式。
如果实在是觉得很难,你也可以选择使用beautifulsoup里的匹配标签,相对来说他会好理解很多
你也可以自己写个爬取电影的小程序,
这样你可以避免那些烦人的小广告,
你也可以写个查询火车票的小应用,这样你可以在第一时间知道是否有回家的车票。
以上是关于家园小剧场|简单爬虫技术的主要内容,如果未能解决你的问题,请参考以下文章