精算下午茶爬虫技术详解
Posted 精算下午茶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精算下午茶爬虫技术详解相关的知识,希望对你有一定的参考价值。
***阅读指引***
本文略长。约4700字。
本文假设读者没有任何相关经验。会从最基本的概念谈起,没基础也能看懂。
本文专注于讨论定向爬取。本文探讨的场景是“我知道自己想爬哪个网页,也知道自己想爬什么内容”。
本文将分期发布,本期着重介绍爬虫原理与必要知识。下期再以案例的形式介绍具体实现。
***一些需要事先呈现的Q&A***
Q:什么是爬虫?
A:笔者版定义——“一类自动从网页中截取关键信息的程序”。
Q:爬虫合规合法吗?
A:目前还没有专门针对爬虫行为的法律或规范。一般来说,互联网上的公开信息本来就是共享的,爬虫程序只是在更高效的收集信息,并无违规之处。
但不合理的爬虫行为可能会对网站造成不良影响,比如频繁的请求发送会增加服务器负担等等。因此一些站点会采取各式各样的反爬手段。(所以爬虫程序需要一些“演技”来躲避侦测)
另外,有的网站会主动发布“爬虫指引”,规定什么样的爬虫行为在该网站是允许的。
Q:有哪些典型的爬虫应用案例?
A:讲最典型的吧。搜索引擎(百度Google等)都会使用爬虫。它们先利用爬虫爬下整个互联网,把信息整理好后放到数据库中。用户查询时,再在数据库中进行检索。
Q:作为“精算从业者”或“保险从业者”,用爬虫能干嘛?
A:说下我们做过的小应用,都很简单。更多、更有价值的应用场景就需要读者们的脑洞了。
应用1:监控各交易对手信用评级信息。
应用2:获取同业万能结算利率。
应用3:获取同业产品信息,形成产品库。
***本文的提纲***
下面上干货!
***工具篇***
Fiddler协议调试工具
是什么?
一个原谅色的小软件。

有什么用?
监听本地计算机与远端网页服务器之间的通信内容,协助我们对目标网站进行逆向工程。(没错,就像谍战片里的窃听器)
怎么用?
后面会具体讲。
Chrome开发者工具
是什么?
打开Chrome浏览器,按F12,跳出来的就是它。
有什么用?
帮助我们阅读网页源代码。当然,它功能很多,但我们只会用到最基本的。
怎么用?
只需要用到两个简单功能:
1、单击右键,选择“查看网页源代码”;
2、单击右键,选择“检查”。(查看某个页面元素对应的源代码片段)
IE浏览器也有类似功能,操作方式也基本一样,能达到同样的目的。
Python
是什么?
当前最适用于开发爬虫应用的编程语言。
有什么用?
用来编写爬虫程序。
怎么用?
下载并安装Anaconda,它集成了开发环境、运行环境、常用第三方包等。之后便可以肆意编程和运行了。
***预备知识篇之通信协议(HTTP)***
什么是HTTP
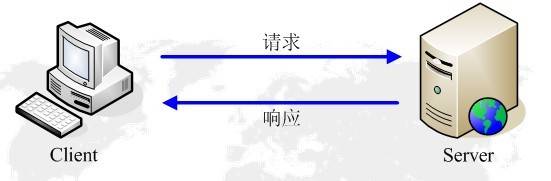
HTTP = Hyper Text Transfer Protocol,超文本传输协议。如其名,它是一种通信规范。就像我们写书信要讲究格式一样(要有称呼、落款之类的),互联网上的两台计算机在传递超文本信息时也要遵循一定的规则,否则它们将无法相互理解。
什么是“超文本”
就是在普通文本的基础上,附加了排版、样式、超链接、多媒体等多种内容的网状文本。在本文的语境下,可以理解为就是指网页。
这跟爬虫有何关系
爬虫程序需要按照通信协议与网页服务器进行交流,以获得信息。具体的策略是,模仿浏览器与网页服务器之间的互动过程,浏览器怎么跟网页服务器互动,爬虫程序就照着做。
如何通信
如同我们写书信一样。客户端(浏览器或爬虫程序)向网页服务器发送请求(写信),然后网页服务器收到请求后作出响应(回信)。这样一来一回,便完成了一次通信。
请求与响应的三要素
HTTP请求包含三个要素:
请求方法
请求报头
请求正文
HTTP响应同样包含三个要素:
响应状态
响应报头
响应正文
利用Fiddler查看通信过程
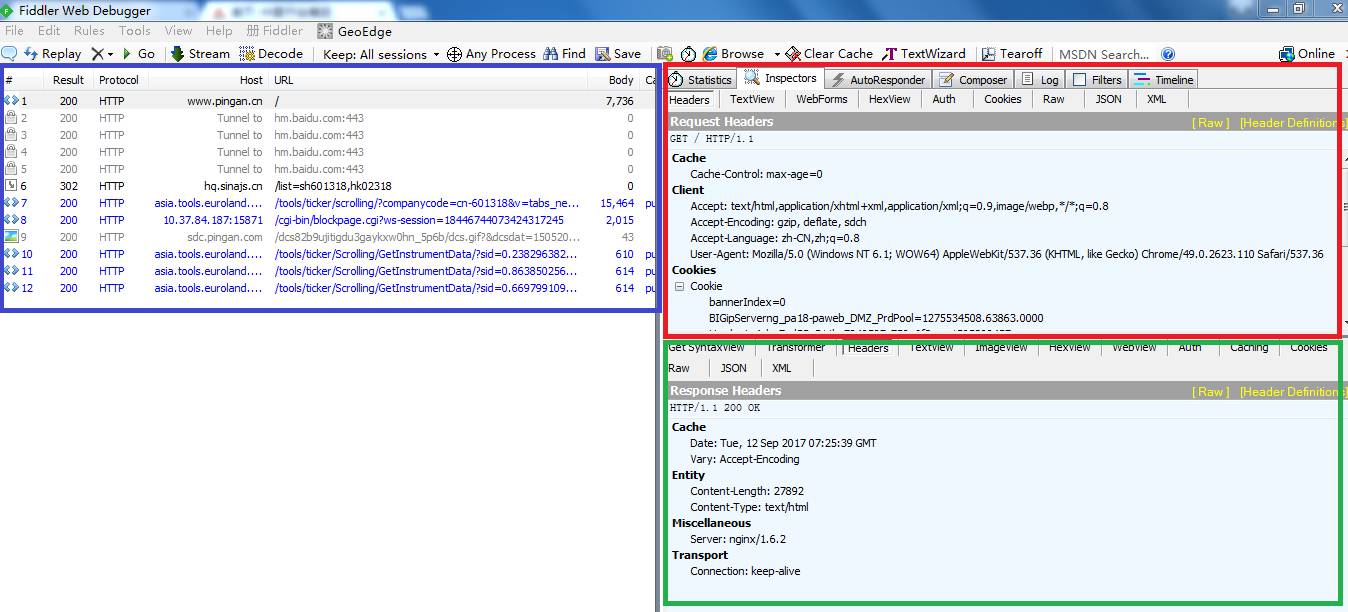
先启动Fiddler,然后通过浏览器访问任一网页,在Fiddler中便能看到本次通信的诸多细节。(偷窥技能get√)
如下图,蓝框部分是通信列表,每行记录代表一次请求与响应。选择其中一行后,在红框部分可以查看请求详情,绿框部分可以查看响应详情。
HTTP请求三要素之——请求方法
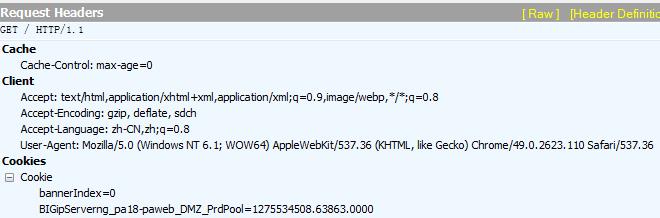
常见的请求方法有GET和POST。GET是向服务器索取信息,POST是向服务器提交信息(同时也可能伴随着信息索取)。如下图,Fiddler显示本次请求用的是GET方法。

HTTP请求三要素之——请求报头
报头主要包含一些自描述信息,如下图。接下来我们挑选请求报头中的一些关键项来作详解。
User-Agent:
该项信息描述了请求发送者(浏览器或爬虫程序)的身份。上图中,Chrome浏览器对自己身份的描述是“Mozilla/5.0 (Windows NT6.1) AppleWebKit/537.36(Khtml, like Gecko) Chrome/43.0.2357.134Safari/537.36”。
可见,Chrome浏览器向网页服务器暗示自己有四重身份,除了“Chrome”这层身份以外,它还自称有火狐和苹果的血统。
Chrome这样做的目的,是为了保证自己作为浏览器有更强的兼容性。一些网站会对请求报头中的User-Agent信息进行检查,如果不满足要求就会禁止访问。比如,由于历史原因,一些早期网站只接受User-Agent中带“Mozilla”字样的请求,Chrome如果不在自己的User-Agent中带上“Mozilla”字样就无法访问这些网站。
对于爬虫程序,该信息非常关键。如果没有特别指定,爬虫程序会很诚实的在User-Agent中表明自己的身份(直接告诉网页服务器“我是爬虫,来抓我呀”)。很多情况下,这种直白的请求会被拒绝访问。
为了避免被目标网站拒绝访问,爬虫程序需要学习Chrome的做法,伪造自己的身份。方法是,爬虫程序在发送请求时,把信息报头中的User-Agent设置为与Chrome浏览器一样。这样,网页服务器就会误以为请求来自浏览器而不是爬虫。(就像考试交卷时写别人名字)
具体如何实现,会在下期详解。
Accept-Encoding:
表示请求发送者希望接收到的编码或压缩格式。在上图中可以看到,Chrome发出的请求中该项信息是“gzip,deflate, sdch”,表示Chrome希望接收这三种格式的内容。
对于爬虫程序,建议在设置Accept-Encoding时不要带有gzip。原因是这样,gzip是一种压缩格式,浏览器在接收到该格式的信息后会自动进行解压,但爬虫程序并不会自动解压,最后导致出现乱码等问题。
Referer:
表示请求发送者是从哪个页面跳转过来的。来看个例子,我们从百度跳转到任一网站时,在Fiddler中查看该跳转请求,可以看到请求报头中带有Referer信息(如下图),且Referer的值是百度的URL(网址)。这是在告诉我们要去的那个网站:“我是从百度跳转过来的”。
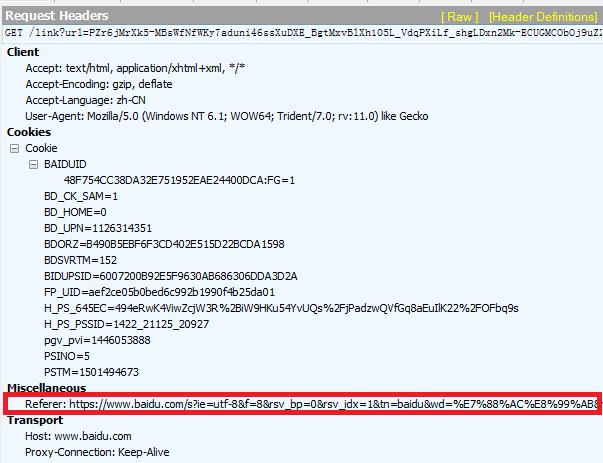
对于爬虫程序,该信息很重要,因为一些网站会通过检测该信息来防止盗链。因此,哪怕你的爬虫程序打算直接访问目标页面,有时候也需要伪造Referer信息,假装自己是从其他合法页面跳转过来的。(爬虫不易,全靠演技)
HTTP请求三要素之——请求正文
如果是GET方法,则正文一般为空。如果是POST方法,正文是需要提交到网页服务器的数据。
爬虫程序发出的正文内容需要模仿浏览器,否则网页服务器不会作出符合我们预期的响应。至于如何模仿,就是先用Fiddler“偷窥”,然后再“抄袭”。(同考试作弊流程)
HTTP响应三要素之——响应状态
下面列了几种常见状态,200表示访问成功,4开头的都是访问失败。其中404应该是大家最耳熟能详的:
200 OK
400 BadRequest
401 Unauthorized
403 Forbidden
404 NotFound
对于爬虫程序,不需要太关注这部分,只要在debug时能理解不同的响应状态即可。
HTTP响应三要素之——响应报头
类似于请求报头。对于爬虫程序而言,一般不需关注。
HTTP响应三要素之——响应正文
内容通常是目标页面的源代码。爬虫程序需要收集该源代码,并从中解析出关键信息。
***预备知识篇之网页源代码***
上文介绍了通信规则,那通信的主要内容是什么呢?没错,正是网页源代码。

什么是网页源代码
记录了页面上的文字、排版、样式、多媒体、超链接等等内容的代码。该源代码被浏览器解析后,再渲染成可视的内容(即我们看到的网页)呈现给用户。
如何查看源代码
请见下图,用的是Chrome浏览器。
选择“查看网页源代码”,可以查看源代码全文;
选择“检查”,可以查看各个页面元素对应的源代码片段。
源代码的三要素
源代码包括如下三种内容:
HTML:包含页面内容、框架、排版等信息。相当于骨架。
CSS:包含样式相关的信息。相当于皮肤。(理解成亡者农药里的“皮肤”也OK)
javascript:包含网页的动态行为。相当于肌肉。另外,它不是Java,并且跟Java没有半毛钱关系,不要搞混淆了。(大概就是雷锋和雷峰塔的关系)
来看一个具体的例子。如下图:
红框部分是HTML,即整个源代码,CSS和JavaScript是内嵌在其中的;
绿框部分是CSS,在这个例子中,它表示设置背景颜色为灰色;
蓝框部分是JavaScript,在这个例子中,它表示获取系统当前时间,并显示在页面上。
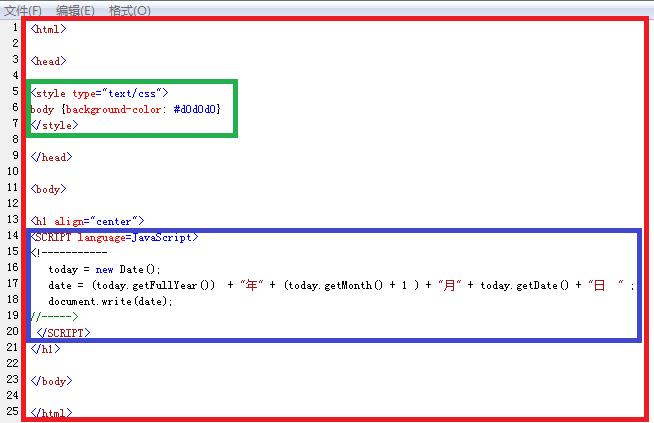
这段源代码被浏览器解释并渲染后,效果是这样的:

这跟爬虫有何关系?
爬虫程序首先需要模仿浏览器,与网页服务器进行互动,拿到网页源代码。之后,爬虫程序需要从大段大段的源代码中提取出我们想要的信息。
***预备知识篇之字符编码***
乱码,都遇到过吧。当字符信息被错误地解码时,就会出现乱码。下面我们来捋一捋Unicode,UTF-8,GB2312/GBK/ GB18030等耳熟但不能详的编码方式。
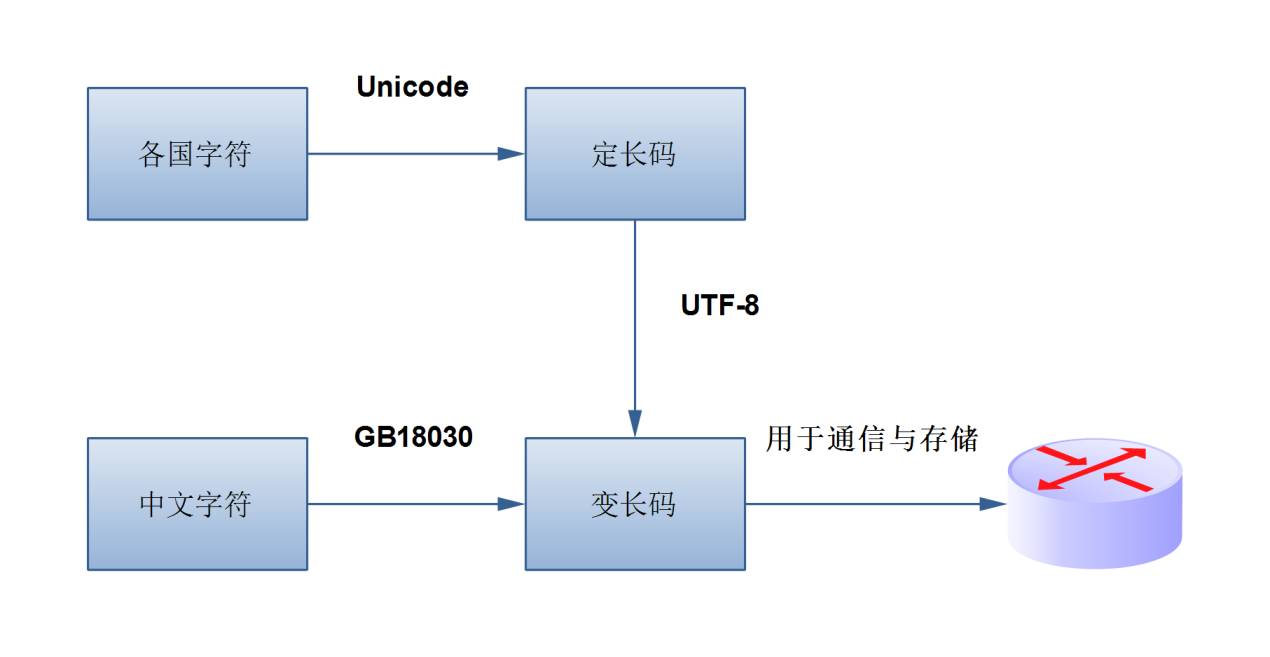
什么是Unicode?
Unicode是一套字符编码规则,由ISO(国际标准化组织)发布,在全球范围内都比较权威。它是一套映射关系(或曰函数),把“全球多个国家的字符”一对一地映射到“固定长度的数字”。Unicode一般不直接用于通信,而是会进行额外一层编码后再在互联网上传播。而UTF-8就是一种对Unicode的再编码。
什么是UTF-8?
UTF-8也是一套编码规则,它将“Unicode(定长数字)”一对一地映射到“变长的二进制码”。也就是说,UTF-8是嵌套在Unicode上的第二层编码。做这种再编码的目的是:
信息在互联网上传播必须要采用二进制形式;
由“定长”转换为“变长”,相当于一种压缩,可以起到节省空间和带宽的效果;
通过再编码,可以向下兼容ASCII(一种最原始的编码方式,仅对英文字符进行了编码,无法表示中文字符)。所谓“向下兼容”,通俗的说就是,任何一个英文字符在“Unicode嵌套UTF-8”和“ASCII”两套编码方式下得到的二进制码是一致的。
严格地说,Unicode和UTF-8一般需要组合使用,以便形成一个从“字符”到“二进制码”的映射。一些语境下,人们说起UTF-8的时候,可能是指Unicode加UTF-8的嵌套组合,而不单单是指UTF-8本身。
什么是GB2312/GBK/GB18030?
它们都是字符编码规则,是从“中文字符”到“变长的二进制码”的映射。不同之处是,Unicode和UTF-8是国际通用标准,而GB2312/GBK/GB18030等是我国自己定义的标准。另外,三者之间是包含关系,GBK是GB2312的扩展,GB18030是GBK的扩展。
为什么要搞这么多套编码,统一用一套不好吗?
用一套国际统一规则当然最好。但Unicode问世较晚,在此之前,如何在信息世界中表达中文,只能我们国家自己来规定。于是先出现了GB2312(/GBK/GB18030)。后来,Unicode出现了,但由于大量的历史信息都是GB2312(/GBK/GB18030)编码的,很难一下子全部切换到Unicode,于是就出现了现在这种两者共存的状态。
另有江湖传闻,说国家为了稳固我们在信息界的地位,想支持国产,不希望弃用GB系列。
这跟爬虫有何关系?
爬虫程序从网页服务器得到的响应内容是经过编码的,需要解码后才能还原出网页源代码。解码时需要选择正确的解码规则,通常来说,不是UTF-8就是GB18030。
如果要POST信息给服务器,需要先对信息进行编码(注意,不是解码),一般用UTF-8。
***预备知识篇之Cookie***
上网时经常被浏览器询问要不要保存Cookie,这种经历都有过吧?
什么是Cookie?
Cookie是网页服务器提供给客户端(浏览器),让客户端自行保存的一种身份证明信息。作用是:“当客户端过段时间再次来访时,出示Cookie,服务器就知道你是上次来过的某某某了”。
典型的应用场景是:“有些需要登录的网站,保存Cookie后,每次访问时只要出示Cookie就自动完成登录了”。
在浏览器向网页服务器发送请求时,Cookie会被包含在请求报头中发出。如下图。
这跟爬虫有何关系?
浏览器会自动处理Cookie,但爬虫程序不会。在构建爬虫应用时,Cookie相关的问题需要我们在程序中自行处理。好在,在Python中处理Cookie不难,具体实现方式会在下期详解。
***爬虫原理篇***
前文中,一些爬虫相关的问题已经陆陆续续被提及到了。总结一下,爬虫程序的工作流程是这样的:
模仿浏览器,向目标网站发送请求。一般来说,浏览器怎么发,我们就怎么发,模仿得越逼真越好。同时,我们还需要处理Cookie相关的问题,复杂一些的情况下可能需要模拟登录,甚至需要识别验证码(12306用过吧?)。
收集响应,并对响应内容进行解码,得到页面源代码。
从页面源代码中提取关键信息。提取手段有多种,比如专门用于解析HTML的BeautifulSoup,或者通用性更强的正则表达式等等。笔者习惯使用更通用的正则表达式。至于正则表达式的相关知识,内容较多,本文就不展开了,有兴趣的读者可自行了解。
以上~
到这里爬虫技术详解的上篇就结束了,小伙伴们一定会好奇这么强大的爬虫技术到底对于精算有什么神奇的应用呢?敬请期待下篇精彩的应用案例!
以上是关于精算下午茶爬虫技术详解的主要内容,如果未能解决你的问题,请参考以下文章