QQ好友说说爬虫技术详解
Posted 追梦程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了QQ好友说说爬虫技术详解相关的知识,希望对你有一定的参考价值。
自从上篇文章 推出后,好多小伙伴问小编怎么实现爬取QQ空间里的说说,今天小编就来详细的向大家介绍QQ好友说说爬虫技术。通过这篇文章的学习,希望可以给各位小伙伴带来帮助。
本文将从三个部分依次详解,分别是 预备知识简介、QQ好友说说爬虫框架、爬虫步骤详解。
一、预备知识简介
小编爬取QQ好友说说采用Python语言,所以各位小伙伴要有Python基础。另外在爬取中用到了Python的几个第三方库,分别是requests库、BeautifulSoup库,在数据存储和解析中用到了pymysql库、matplotlib库,所以各位对这些库要有所了解。
二、QQ好友说说爬虫框架
QQ好友说说爬虫的基本思想是使用已经在浏览器登录的cookie实现爬虫登录,利用准备好的好友QQ号下载全部好友说说html文件至本地文件系统,解析本地文件系统中的HTML文件提取说说信息存入MySql数据库,最后就是自己对MySql数据库中的说说信息进行分析了。爬虫框架图如下。
三、爬虫步骤详解
3.1 获取所有好友QQ号
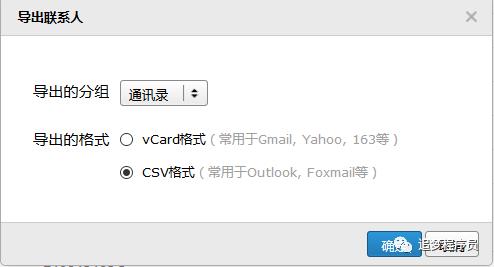
QQ邮箱有导出所有联系人的功能,故我们可以借助QQ邮箱获取所有好友QQ号。步骤如下:登录QQ邮箱-->点击右侧通讯录-->点击工具,选择导出联系人-->下载CSV格式文件。
3.2 获取在浏览器登录的cookie
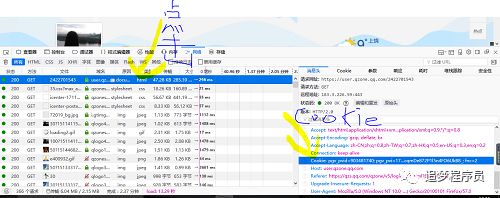
我们要利用已经在浏览器登录的cookie实现爬虫登录,所有必须得到浏览器cookie。步骤如下:打开浏览器 --> 进入 https://qzone.qq.com 网站 --> 按F12打开浏览器的开发工具,切换到Network(网络) --> 输入你的QQ号和密码登录进去 --> 点击第一行,复制请求头的cookie值至txt文件。
3.3 爬取全部好友说说
每一位好友说说页的url链接为 http://user.qzone.qq.com/好友QQ号 ,所有我们先要得到所有好友QQ号。读取csv文件,将所有好友QQ号存入qnumber_list数组。
 (注: /python/qqMoodCollect/QQmail.csv 为csv文件路径,这里要改为你的文件路径)
(注: /python/qqMoodCollect/QQmail.csv 为csv文件路径,这里要改为你的文件路径)
下面就是遍历 qnumber_list数组,依次下载说说HTML文件至本地文件系统。
(其中get_moods()方法为具体下载说说HTML文件方法,详情看GetHub上的代码)
3.4 解析说说HTML文件
下载的说说HTML文件中其实就是Json数据格式,我们可以利用Python内置的json库可以很方便的提取我们想要的信息,最后存入MySql数据库。具体解析过程详情请看 get_mooddetail.py 文件。
好了,以上就是本文的全部内容,各位小伙伴快动起手来吧。
(请多多关注)
以上是关于QQ好友说说爬虫技术详解的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(103):项目实战--抓取QQ空间说说的内容
Python爬虫编程思想(103):项目实战--抓取QQ空间说说的内容