闲聊网络爬虫技术
Posted Data室工作
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了闲聊网络爬虫技术相关的知识,希望对你有一定的参考价值。
大家好,今天和大家一起聊聊网络爬虫技术。 为什么和大家聊聊这个技术话题呢?
为什么和大家聊聊这个技术话题呢?
自信息化技术兴起后,信息数据它就一直在巨增。这个时候啊,电商的网页信息数据伴随交易增加,人们就能看到多数商品的信息,比如买的皮鞋价值几何?短裤销量爆款咋滴?今年嗨的是啥流行款?动次打次的网页信息探索就这样产生了........

想想拿这些数据作为市场需求的预判,不是更有价值和意义吗?
是的,这样想没错!搜集行业的数据,不违反行业规则,提升自己的产品竞争力,还是搜集公开的网页数据,这难道不更好吗?
那么搜集网页信息数据要咋办呢?于是,网络爬虫技术产生了,即网页数据采集的方法成功的被很多人所喜爱,大数据时代的又一神兵利器,就这样来到了我们的身边,美好事情发生。大概这样美好的事情,总以为是在电视剧里,不经意的馅饼掉下来,这让我们不得不好奇网络爬虫技术是什么吧?看下图留言说说你的看法思路。
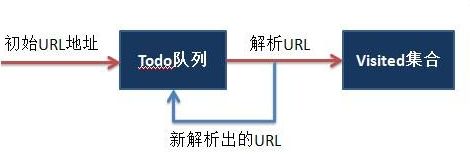
注:上述图片源自百度
上图的大致流程较为贴近网络爬虫。当时呢,我也很好奇,有一天,朋友问我爬虫技术是什么?她问我是大蟑螂吗?还是大蜘蛛啊?那时的我就瞬间360度的得意笑了。就想初次给同学显摆显摆,为了让他们记住,我还多此一举在PPT上展示宇宙级的最最好看的超美大蜘蛛,结果是无情的把美好的爬虫技术在他们心中PASS了,他们还是认为网络爬虫是大蜘蛛。其实呢,我也明白,给一些和计算机脱轨,远离数据的人讲网络爬虫,大家都会或多或少有这样的想法。不过,学到这门技术想来也是很棒的哦!
为了避免再次的尴尬,必须再次和大家郑重说明:网络爬虫并不是爬虫,非要和虫子挂钩,那我就这样比喻:像蚕虫一样慢慢的咀嚼网页,吐出丝丝飘然的信息节点,欣赏丝绸汇集的绫罗绸缎,辅以加工修饰,就成为最有意义的数据。
哈哈,网络爬虫是不是很棒呢?咱来看看下图的网页数据采集原理:
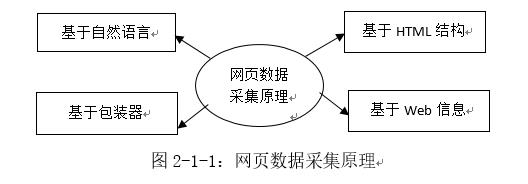
解释下如何?浅显的和大家聊聊是没啥问题的,允许质疑哦
我认为:网页数据采集原理,也涉及到网络爬虫技术的原理。
网络爬虫,离不开网络,就像鱼儿离不开水一样,没有网络,没有网页,我也会饥渴,无任何用武之地,岂不悲哉?它的存在就靠以下四点:
1.基于自然语言
自然语言是什么呢?说白了就是你能看懂的东西,文字、图片啥都可以。非要学术讲的话:通常是指一种自然地随文化演化的语言。如英语、汉语、日语为自然语言,而世界语也是人造语言,那么爬虫获取的信息你总看得懂吧?
2.基于包装器:
这个呢?包装器,可能接触程序的都懂,这里就是说爬虫包,爬虫设计的什么工具东东之类的,对,我想是这样!你认为呢?
3.基于html结构
网页?网页格式是什么,当然HTML吧!所以,爬虫总得依靠它存在吧!
4.基于Web信息:
这一点,最好明白,为什么呢,因为网络爬虫获取网页信息数据,它需要网上有信息数据啊,不然爬虫爬啥?吃饭没有饭,没多大意义,嘿嘿,你懂得!
说了这么多,网络爬虫最后能干啥啊?告诉你,悄悄滴,肯定是获取数据,不信?
看,看,看下面——
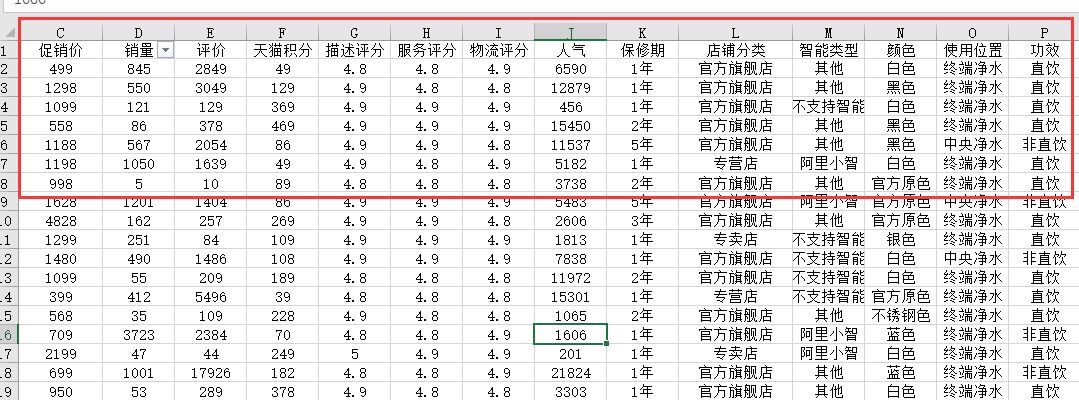
注:信息来源某电商网站,已对信息数据进行干扰项。
以上是采用网络爬虫技术获取的某网站数据,仅以展示,对数据真实不做任何说明。
好了今天的话题就是聊到这了,你有什么想说的吗?下方留言互动哦!
——我是谈天,我为团队代言
以上是关于闲聊网络爬虫技术的主要内容,如果未能解决你的问题,请参考以下文章