第六篇 爬虫技术之天天基金网 实战篇
Posted python编程军火库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第六篇 爬虫技术之天天基金网 实战篇相关的知识,希望对你有一定的参考价值。
hello,大家好,今天我们来用代码实现一下节前分析的那篇如何抓取基金排名的数据:
# -*- encoding: utf-8 -*-
# !/usr/bin/python
"""
@File : day_day_funding_scrapy.py
@Time : 2019/10/13 17:34
@Author : haishiniu
@Software: PyCharm
"""
import json
import requests
import logging
import random
from pyquery import PyQuery as pq
import sys
reload(sys)
sys.setdefaultencoding('utf8')
class FundScrapy(object):
"""
天天基金网
"""
def __init__(self):
"""
初始化信息
"""
self.session = requests.session()
self.timeout = 60
def get_main_info(self):
"""
获取首页的信息
:return:
"""
try:
main_url = 'http://fund.eastmoney.com/'
self.session.headers["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"
self.session.headers["Accept-Encoding"] = "gzip, deflate, br"
self.session.headers["Accept-Language"] = "zh-CN,zh;q=0.9"
self.session.headers["Connection"] = "keep-alive"
self.session.headers["Host"] = "fund.eastmoney.com"
self.session.headers["Upgrade-Insecure-Requests"] = "1"
self.session.headers["User-Agent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
main_response = self.session.get(main_url, verify=False, timeout=self.timeout).content
self.session.headers["Referer"] = 'http://fund.eastmoney.com/data/fundranking.html'
# 获取前10% 倒数5% order数据 -->总样本量:750
page_list = [1]
# page_list = [1]
order_list = []
hander_list = ['fund_code', 'fund_name', 'date', 'asset_value', 'asset_value', 'day_rate', 'wek_rate', 'one_m_rate',
'three_m_rate', 'six_m_rate', 'one_y_rate', 'two_y_rate', 'three_y_rate', 'this_y_rate', 'complate_day_rate']
for i in page_list:
v_value = random.random()
fund_ranking_url = "http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=zzf&st=desc&sd=2018-08-03&ed=2019-08-03&qdii=&tabSubtype=,,,,,&pi=%s&pn=50&dx=1&v=%s" %(i, v_value)
# print fund_ranking_url
fund_ranking_response = self.session.get(fund_ranking_url, verify=False, timeout=self.timeout)
fund_ranking_response.encode = 'utf8'
fund_ranking_response = fund_ranking_response.text
# print fund_ranking_response
# print fund_ranking_response.find('var rankData = {datas:[')
# print fund_ranking_response.find(']')
response_list_json = fund_ranking_response[fund_ranking_response.find('var rankData = {datas:['):fund_ranking_response.find(']')].replace("var rankData = {datas:[", "")
response_list_json = response_list_json
for i in response_list_json.split('"'):
if len(i.split(',')) < 10:
continue
order = i.split(',')
order_list.append(order)
for i in order_list:
print(i)
except Exception as ex:
logging.exception(str(ex))
if __name__ == "__main__":
CRZY_SCRAPY = FundScrapy().get_main_info()
具体的实现如上述代码,我们来对比一下获取的数据和网页展示的数据:
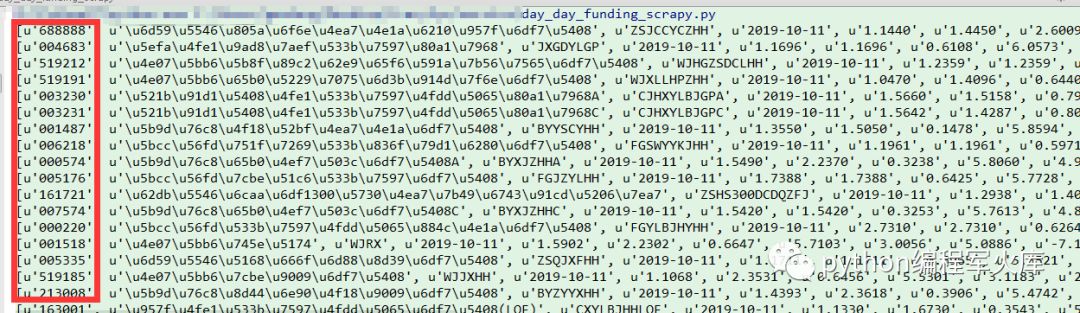
好了,本期我们主要是分享了如何实现获取数据从代码层面的实操。后期我们会在此基础上进行拓展,敬请期待!
当你发现自己的才华撑不起野心时,请安静的坐下来学习吧。
------还是牛
以上是关于第六篇 爬虫技术之天天基金网 实战篇的主要内容,如果未能解决你的问题,请参考以下文章