反爬虫技术与“反”反爬虫技术
Posted 数据皮皮侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了反爬虫技术与“反”反爬虫技术相关的知识,希望对你有一定的参考价值。
反爬虫技术与“反”反爬虫技术
郭晓鹏
我们很熟悉爬虫,爬虫存在互联网的各个角落,爬虫有好处也有坏处,今天我们不讲如何进行爬取,我们来说一说和爬虫共同诞生的反爬虫技术。爬虫技术造成的大量IP访问网站侵占带宽资源、以及用户隐私和知识产权等危害,很多互联网企业都会花大力气进行“反爬虫”。相比于爬虫技术,反爬虫其实更复杂。在90年代开始有搜索引擎网站利用爬虫技术抓取网站时,一些搜索引擎从业者和网站站长通过邮件讨论定下了一项“君子协议”—— robots.txt。即网站有权规定网站中哪些内容可以被爬虫抓取,哪些内容不可以被爬虫抓取。这样既可以保护隐私和敏感信息,又可以被搜索引擎收录、增加流量。在远古时期,互联网还是一片乐土,大多数从业者都会默守这一协定,毕竟那时候信息和数据都没什么油水可捞。但很快互联网上开始充斥着商品信息、机票价格、个人隐私等等,在利益的诱惑下,自然有些人会开始违法爬虫协议了。当君子协议不再有效时,我们就采取技术的手段来反爬虫,今天我们主要说一说有那些技术方法来应对爬虫进行反爬。
01
通过请求头来控制访问
不管是浏览器还是爬虫程序,在访问目标源网站时都会带上一个头文件:User-Agent
反爬策略:我们的网站可以设定User-Agent白名单,属于正常的范围才能访问
缺点:爬虫程序很容易伪造头部进行请求,只能拦截一部分新手爬虫。
02
ip限制
反爬策略:让一个固定的ip在短时间,不能对接口进行频繁访问。
缺点:爬虫程序可以通过ip代理池切换ip进行访问,但对爬虫者来讲需要一定成本,对于反爬虫来讲通过这种免费或付费的ip代理可以绕过检测。
*代理ip池实现的简单思路*@return*/public static Sting getProxy(){String [] proxy={“http://118.245.23.2:80”,“http://118.145.23.2:8118”,“http://117.245.23.2:88”,“http://116.245.23.2:80”};return proxy [new Random().nextInt(proxy.length)];}
03
验证码验证
验证码是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于 计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。



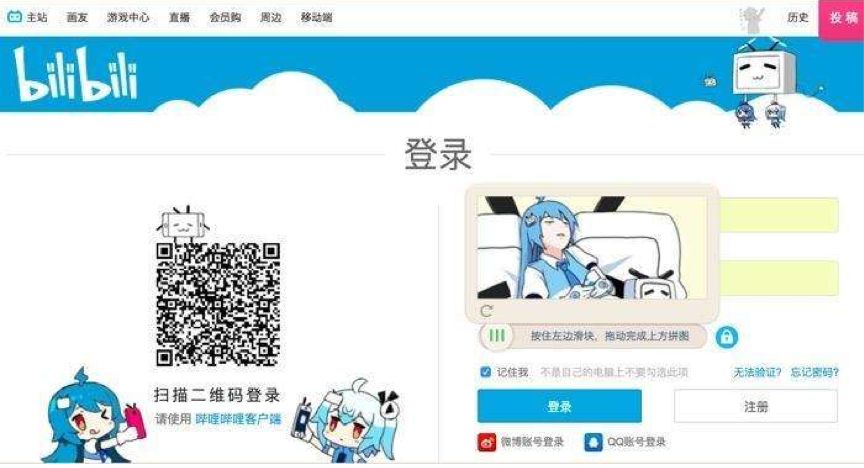
反爬措施:通过图片验证码防止爬虫程序进行爬取
缺点:影响正常的用户体验操作,验证码越复杂,网站体验感越差
04
session访问限制
反爬措施:后台统计登录用户的操作,比如短时间的点击事件,请求数据事件,与正常值比对,用于区分用户是否处理异常状态,如果是,则限制登录用户操作权限。
缺点:需要增加数据埋点功能,阈值设置不好,容易误杀。
05
数据加密
反爬措施:前端可以通过对查询参数、user-agent、验证码、cookie等前端数据进行加密生成一串加密指令,将加密指令作为参数,再进行服务器数据请求。该加密参数为空或者错误,服务器都不对请求进行响应;后端可以在服务器端同样有一段加密逻辑,生成一串编码,与请求的编码进行匹配,匹配通过则会返回数据。
缺点:加密算法写在JS里,爬虫程序经过一系列分析还是可以进行破解。
06
但是目前面对这些反爬虫技术,如果我们为了获取数据又必须用爬虫技术,那么面对这种情况应该如何解决?
首先我先介绍Google Chrome的开发者工具的打开方式,我下面的介绍都是在Google Chrome里进行,所以这个开发者工具的使用比较重要。
首先打开Google Chrome,对于Mac而言Cmd+Opt+I Windows而言Ctrl+Shift+I
以此我们可以打开开发者工具
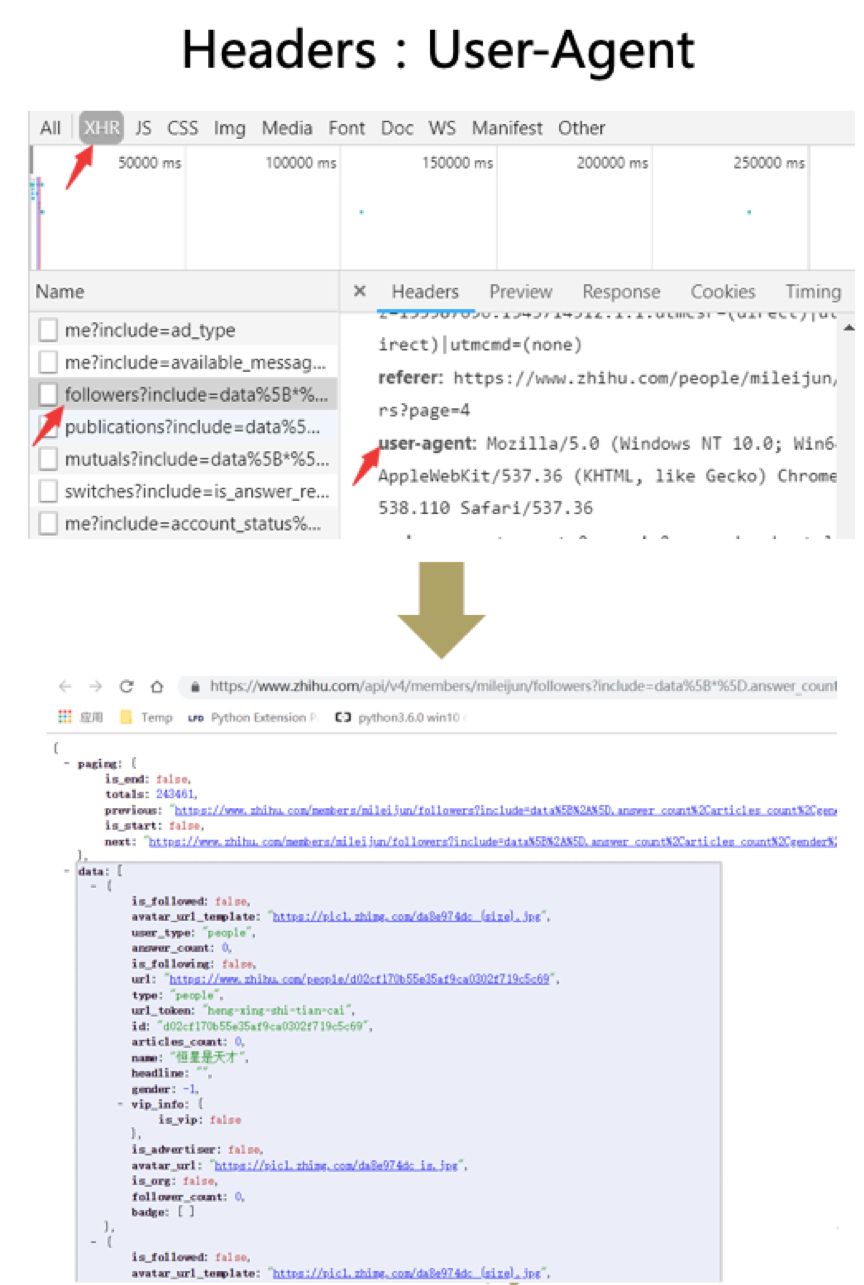
我们就以知乎为例进行解释
打开开发者工具之后,根据上图的步骤我们可以找到需要使用的网址。
然后在Atom里可以输入以下代码,从而形成一个python的文件。
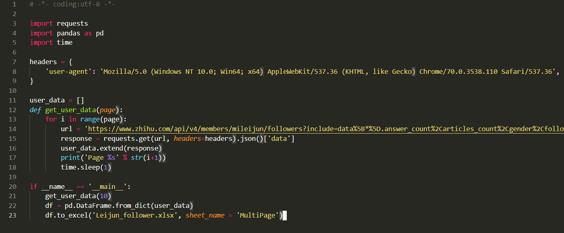
1. for循环及字符串控制(offset={}, .format(i*20))
2. 数据拼接 à x.extend(y)
3. time.sleep(z) à 模拟人的操作,避免高频抓取触发反爬机制
4. 定义函数 à 区分模块
从而可以将数据爬取出来。
通过本文的介绍相信大家已经对反爬虫技术以及“反反爬虫”技术有了一定的了解,下次再面对这样的情况时就可以这样进行处理。
欢迎关注数据皮皮侠!
编辑校对:郭通
以上是关于反爬虫技术与“反”反爬虫技术的主要内容,如果未能解决你的问题,请参考以下文章