爬虫技术初探——宏观分析小工具系列一(中泰宏观 梁中华 苏仪)
Posted 梁中华宏观研究
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫技术初探——宏观分析小工具系列一(中泰宏观 梁中华 苏仪)相关的知识,希望对你有一定的参考价值。
当前宏观研究中面临的一大问题是数据的限制,可以用于分析的质量较高的数据越来越少,而宏观经济内部结构变化又较大,传统的一些数据还出现了失灵的情况。在这种情况下,将一些新的计算机工具应用到宏观分析中,可以在一定程度上弥补数据不足的缺陷。
我们团队的苏仪同学,在数据挖掘、数据库搭建、高性能计算及海量数据分析方面具有专长,接下来会为大家介绍一些技术小工具,欢迎沟通交流,有技术相关需求,也欢迎联系我们。
爬虫的合理广泛应用
爬虫的应用需合法、合理、规范化,大部分抓取的数据只适合用于参考。
近来关于爬虫的新闻有许多,但使用爬虫的主要目的其实是为了更加有靶向性地快速、高效且持续地在网页上收录及筛选信息,尤其是数据。在网站上获取的信息,虽然不如行业协会统计的全面,但会对一些细节问题反映的更加直观。
通过在研究中利用爬虫技术获取更新更细的信息,有助于我们更好地做出判断。
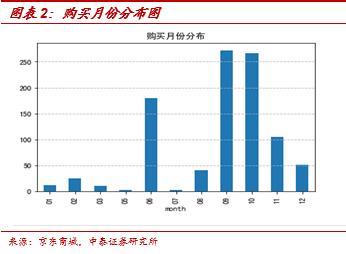
譬如,在研究茅台销量的时候,从电商平台上抓取一些公布出来的评论信息,也可以对产品做一个侧写。在7月份的时候我们在某电商平台上抓取了500ml 53度飞天茅台的用户评论量。在评论区我们可以看到购买者的用户等级、客户端、购买月份及发布的评论。在已有样本中,我们发现购买者使用的客户端中,安卓系统占了57.5%,iPhone占了36%。从购买月份来看,这款茅台在9月份销量最高,其次是10月份,在6月份的时候销量也很突出。
但在获取数据时,我们会发现由于网页设置及货品上下架的原因,获得的单一商品的数据在长周期的观察方面会存在断点。并且网站会自动过滤掉一些客户的评论,爬取下来的数据并不完全。这样的数据有一个特性,就是要持续跟踪,积累的数据样本越多,产出的结果越具有借鉴意义。才能看清楚数据背后的意义。我们更倾向于用已有数据计算细分项占比来看趋势,而非精确地定量计算。并且,我们也只是将趋势作为一种参考,并不产生商用价值,还是以官方公布数据为主要数据来源。
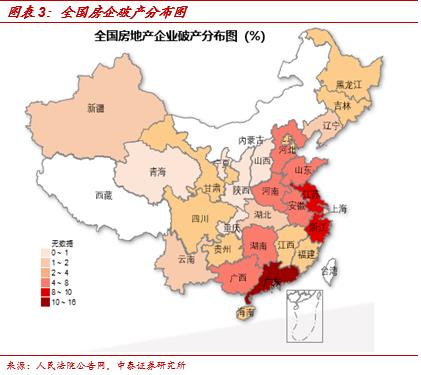
再比如,考虑到房地产行业在经济中的重要性,我们对人民法院公告网上公布的破产企业文书进行了爬取,筛选出了其中的房地产企业破产文书并进行了统计。根据我们的数据统计,2019年至今我国破产房企已经达到378家,其中广东省破产房企数量最多,高达60家,占比15.87%。浙江、江苏也是房地产企业破产重灾区。
但是网站公示的数据量有限,所以我们就需要对该数据做长期持续跟踪处理。通过月度数据对比,可以直观看到各省份破产企业的增加量,并做进一步深度研究。
此外,我们也可以跟踪一些房产交易网站,统计最新的房产交易、价格变动状况,能够更加真实、快捷的了解市场走势变化。
利用爬虫抓取网页表格数据
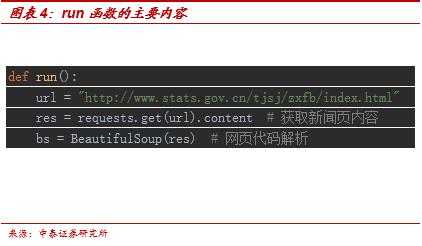
作为入门,我们先来介绍下如何利用爬虫抓取公开网站表格中的数据。在爬取过程中会用到两个主要函数,分别是get_csv函数和run函数。以统计局公布的CPI数据的爬取举例,整个框架中,我们更倾向于首先读取整个新闻页,筛选出其中的新闻标题和URL,再进一步筛选出我们需要的标题并获取URL,然后访问URL并获取具体内容。在解析网页的时候可以使用F12来获取相关信息。
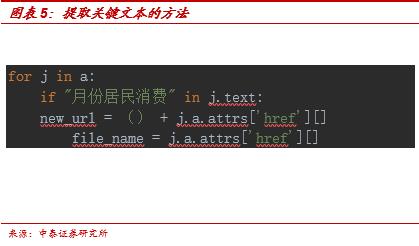
首先可以先定义run函数,并定义url变量。通过res变量来获取新闻页的所有内容。然后根据标签内容输入关键词,进行内容检索。在本例中,我们可通过j.text来获取文字内容,并通过定义j.a.attrs变量来获得我们所需要的信息。在此过程中我们用的解码工具是BeautifulSoup。
BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码,因此并不需要考虑编码方式。国家统计局官网上并没有一个指定的编码,因此在抓取数据的过程中BeautifulSoup已经够用。当然,当我们遇到有指定编码的网站时,比如猫眼网,BeautifulSoup就无法自动识别,可以考虑使用Xpath和正则表达式。
另一个重要函数是get_csv。我们通过这个函数解析获取CSV字段格式。
在get_csv函数中,我们首先要打开csv文件,并将爬取到的内容写入文件。这里我们可以充分使用Python的简洁特征,定义格式为打开csv文件并调成“w”写入文件。
重要的是爬取数据导入Excel表格时,要调成一致格式。在导入Excel时, 可以先把内容print一下看格式。一般而言字符串之间会存在空格,可以使用strip去掉首位空格,用逗号代替字符串间空格间隔。
后续使用的相关问题
在爬取数据时,如果追求时效性,可以在服务器上设置爬取时间,这样在数据公布出来的时间段里,爬虫会反复访问网页以获取相关内容并进行高效爬取。
Pytorch宣布Python2即将于2020年1月之后停止更新维护。
Python2和Python3以上版本差异较大,建议安装Python3以上版本。
在最新推出的Python3.8中,新推出的赋值表达式“:
=”操作符使得编写代码更加高效快捷,变量不存在也可以直接在表达式中赋值,不必新定义一个变量然后才能使用。
此外,本专题介绍的是从单一网页中提取数据,在整个网站中搜索带有时间序列的同一字段的数据表,并形成Excel表格的方法,将在下一个专题中
提到
。
最后,需要声明的是,在明确提示该网页不允许爬取的情况下,尽量不要使用爬虫获取数据并用于商业用途。
在利用爬虫获取数据的过程中,一定要做到合法合规。
风险提示:
代码的顺利运行还需要有良好的环境。
爬虫过程中总会遇到各种各样的奇怪问题。
爬虫需谨慎,要合法合规合理使用。
这份报告中涉及到的Python版本为Python3.7。
《
证券期货投资者适当性管理办法》于2017年7月1日起正式实施,通过微信订阅号制作的本资料仅面向中泰证券客户中的专业投资者,完整的投资观点应以中泰证券研究所发布的研究报告为准。若您非中泰证券客户中的专业投资者,为保证服务质量、控制投资风险,请勿订阅、接受或使用本订阅号中的任何信息。
因本订阅号难以设置访问权限,若给您造成不便,烦请谅解!中泰证券不会因为关注、收到或阅读本订阅号推送内容而视相关人员为中泰证券的客户。感谢您给与的理解与配合,市场
有风险,投资需谨慎。
本订阅号为中泰证券宏观团队设立的。本订阅号不是中泰证券宏观团队研究报告的发布平台,所载的资料均摘自中泰证券研究所已经发布的研究报告或对已经发布报告的后续解读。若因报告的摘编而产生的歧义,应以报告发布当日的完整内容为准。请注意,本资料仅代表报告发布当日的判断,相关的研究观点可根据中泰证券后续发布的研究报告在不发出通知的情形下作出更改,本订阅号不承担更新推送信息或另行通知义务,后续更新信息请以中泰证券正式发布的研究报告为准。
本订阅号所载的资料、工具、意见、信息及推测仅提供给客户作参考之用,不构成任何投资、法律、会计或税务的最终操作建议,中泰证券及相关研究团队不就本订阅号推送的内容对最终操作建议做出任何担保。任何订阅人不应凭借本订阅号推送信息进行具体操作,订阅人应自主作出投资决策并自行承担所有投资风险。在任何情况下,中泰证券及相关研究团队不对任何人因使用本订阅号推送信息所引起的任何损失承担任何责任。市场有风险,投资需谨慎。
中泰证券及相关内容提供方保留对本订阅号所载内容的一切法律权利,未经书面授权,任何人或机构不得以任何方式修改、转载或者复制本订阅号推送信息。若征得本公司同意进行引用、转发的,需在允许的范围内使用,并注明出处为“中泰证券研究所”,且不得对内容进行任何有悖原意的引用、删节和修改。
以上是关于爬虫技术初探——宏观分析小工具系列一(中泰宏观 梁中华 苏仪)的主要内容,如果未能解决你的问题,请参考以下文章