爬虫技术之Selenium
Posted 后厂反应堆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫技术之Selenium相关的知识,希望对你有一定的参考价值。
本文作者
目录:
1.爬虫与反爬虫的爱恨情仇
2.新一代爬虫之Selenium+ChromeDriver
3.爬虫实战
一、爬虫与反爬虫的爱恨情仇
网络爬虫:(也被叫做网页蜘蛛、网络机器人)是一种能够“自动化浏览网络”的程序,它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息 。
1.1 反爬技术
反爬技术的兴起,主要的原因是以下两点:
行业竞争 —— 像BAT公司之间的竞争
恶意爬虫 —— 抢票软件、收集个人信息
大公司基于自己数据的保护,都建立了反搜索引擎抓取的规则,比如淘宝、京东的商品信息在百度搜索引擎是检索不到的,微信的数据搜索引擎也是不能抓取的等等,这种大公司之间的行业数据屏障,延伸出了爬虫技术。
另外一种就是恶意爬虫的出现,比如抢票软件的出现,刷单软件,还有更恶劣的是私自收集用户个人数据网上出售的,这些都是不合法的,目前国家的法律也出台了数据隐私保护的相关条纹,使用爬虫技术收集个人信息是违法的。
反爬技术也是有代价的:
人力和机器成本
误伤
反爬技术将普通用户识别为爬虫,从而限制其访问,如果误伤过高,反爬效果再好也不能使用(例如封ip,只会限制ip在某段时间内不能访问),一般拦截率越高,误伤率越高。
下面我们看一下爬虫的基本流程:
1.2 爬虫的基本流程

上面是一个简单爬虫的基本流程,知道了怎么爬,我们在介绍一个好用的工具Scrapy。
1.3 Scrapy框架
这是一个可以使用Python的快速实现屏幕抓取和web抓取的框架, 用于抓取web站点并从页面中提取结构化的数据。它的主要用途是数据挖掘、监测和自动化测试等 。Scrapy吸引人的地方在于它是一个框架, 任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类, 如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持,简直是为了普及人人会爬虫而设计的。
下面是Scrapy的经典架构图,也可以说成流程图。
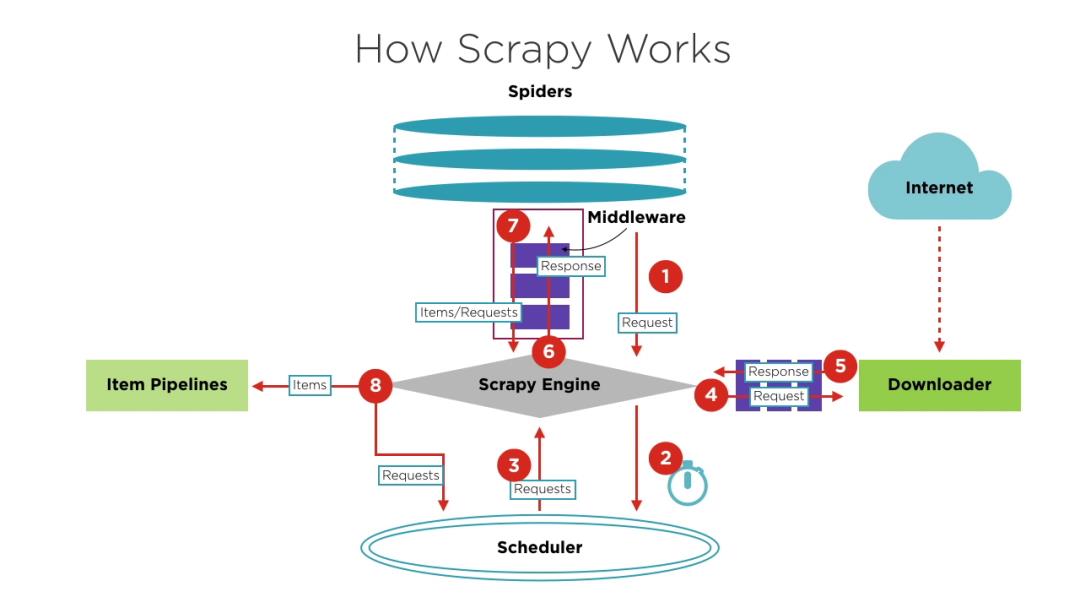
从框架图我们可以看到,Scrapy由这几部分组成:
Scrapy Engine:就是引擎,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等,他是信息的中转站。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
除了这些还有两个中间件:
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
使用 Scrapy 爬虫 一共只需要四步:
新建项目 :新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
有了Scrapy,我们就可以轻松的写爬虫了。
下面我们就讲一下,爬虫和反爬技术的演进。
1.4 爬虫和反爬技术的演进
第一层防线:Header
爬虫:发现感兴趣的网站,开始着手分析网络请求,用Scrapy写爬虫爬取网站数据 网站:后台监控发现请求中的User-Agent都是python,直接限制访问。
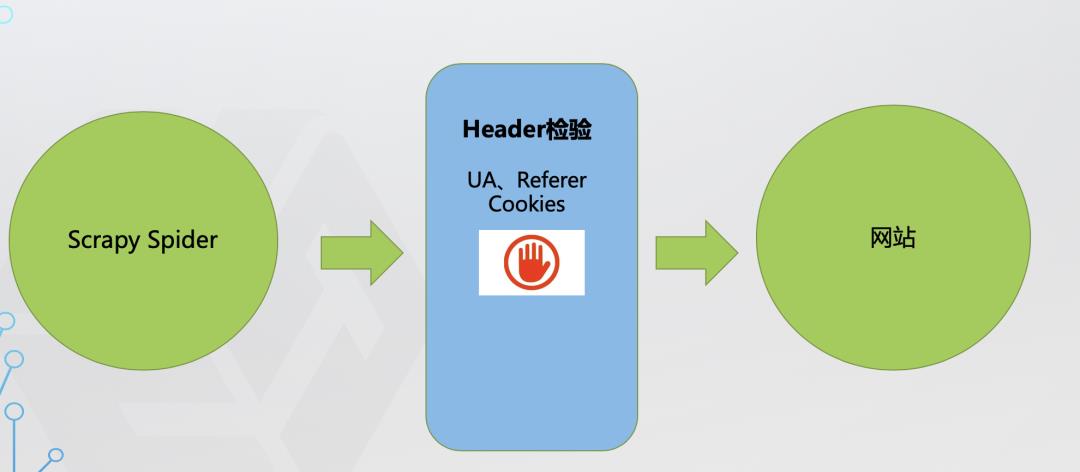
(1)Header检测
通过检测header中的重要参数,判断是不是正常请求。
header中通常包含UA及User-Agent,Referer,Cookies等。
User-Agent是检查用户所用客户端的种类和版本。
Referer是检查此请求由哪里来,通常可以做图片的盗链判断。在Scrapy中,如果某个页面url是通过之前爬取的页面提取到,Scrapy会自动把之前爬取的页面url作为Referfer。也可以通过上面的方式自己定义Referfer字段。
(2)Cookies
网站可能会检测Cookie中session_id的使用次数,如果超过限制,就触发反爬策略。所以可以在Scrapy中设置 COOK:IES_ENABLED = False 让请求不带Cookies。
也有网站强制开启Cookis,这时就要麻烦一点了。可以另写一个简单的爬虫,定时向目标网站发送不带Cookies的请求,提取响应中Set-cookie字段信息并保存。爬取网页时,把存储起来的Cookies带入Headers中。
这样我们就能突破第一层防线了。
第二层防线:频繁请求限制
爬虫:通过在请求头中传递User-Agent参数模拟浏览器请求 网站:后台监控发现同一ip在某时间段内请求过于频繁,直接限制访问。
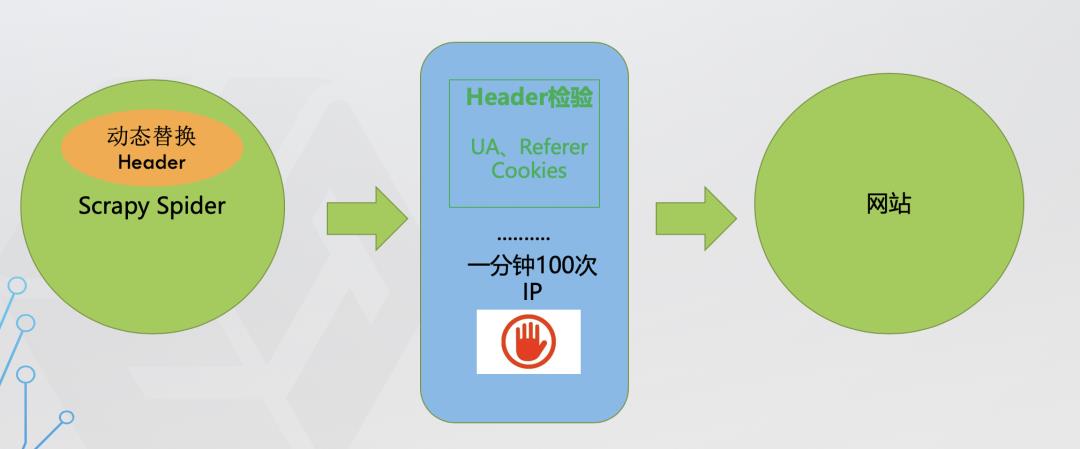
后台对访问进行统计, 如果单个 userAgent 访问超过阈值, 予以封锁。这种方法拦截爬虫效果非常明显,但是杀伤力过大,误伤普通用户概率非常高。所以要慎重使用。破解方法:收集大量浏览器的 userAgent 即可。
防护策略:网站对访问有频率限制,还设置验证码。增加验证码是一个既古老又相当有效果的方法。能够让很多爬虫望风而逃。而且现在的验证码的干扰线, 噪点都比较多,甚至还出现了人类肉眼都难以辨别的验证码(12306 购票网站)。
高级破解方法:python+tesseract 验证码识别库模拟训练,或使用类似 tor 匿名中间件(广度遍历IP)
第三层防线:账号验证
爬虫:在原来的基础上,再通过ip代理向网站发起请求
网站:后台监控发现ip发生变化,但某一时间段内的请求量过大,对服务器造成过大压力,网站中某些数据直接要求登录才能访问(例如:新浪微博)
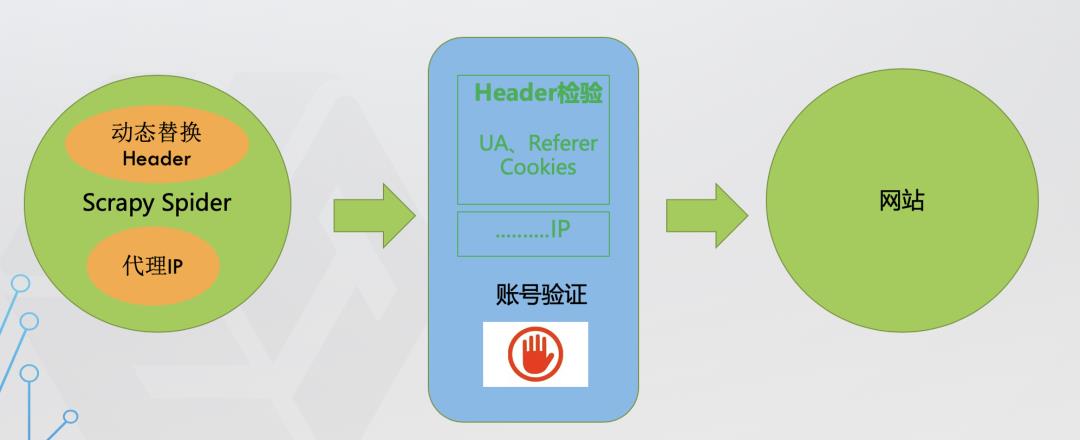
破解方法:注册账号,每次请求携带cookie或者token
防护策略:健全账号体系,用户只能访问好友信息,非好友信息不能访问,或只能访问部分信息
继续破解:注册多个账号,多个账号联合爬取,模拟人去请求,限制请求速度
到了这里其实已经很难在获取更多信息了。
第四层防护:对页面接口返回内容动态处理
增加动态网站,数据通过js动态加载,增加网络分析复杂度,或者发现大量请求时只请求html,而不请求image和css以及js,亦或者直接返回假数据给爬虫。网站页面是动态页面,采用 Ajax 异步加载数据方式来呈现数据。这种方法其实能够对爬虫造成了绝大的麻烦。首先用 Firebug 或者 HttpFox 对网络请求进行分析。如果能够找到 ajax 请求,也能分析出具体的参数和响应的具体含义。则直接模拟相应的http请求,即可从响应中得到对应的数据。这种情况,跟普通的请求没有什么区别 能够直接模拟ajax请求获取数据固然是极好的,但是有些网站把 ajax 请求的所有参数全部加密了,我们根本没办法构造自己所需要的数据的请求。
基于 javascript 的反爬虫手段,主要是在响应数据页面之前,先返回一段带有JavaScript 代码的页面,用于验证访问者有无 JavaScript 的执行环境,以确定使用的是不是浏览器。例如淘宝、快代理这样的网站。
这种反爬虫方法。通常情况下,这段JS代码执行后,会发送一个带参数key的请求,后台通过判断key的值来决定是响应真实的页面,还是响应伪造或错误的页面。因为key参数是动态生成的,每次都不一样,难以分析出其生成方法,使得无法构造对应的http请求。
但是道高一尺魔高一丈,我们还是有办法的。
破解方法:采用 selenium+phantomJS 框架的方式进行爬取。调用浏览器内核,并利用phantomJS 执行 js 来模拟人为操作以及触发页面中的js脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程,只是完完整整的把人浏览页面获取数据的过程模拟一遍。
这种方法一般的网站是无法防御的,因为我们构造了一个真实的浏览器环境,等页面的数据展示完成后,我们使用我们构造的浏览器内核把页面的数据拿出来,这是釜底抽薪的方法。
二、新一代爬虫之Selenium+ChromeDriver
特点:
模拟浏览器真实请求
通过selenium和phantomjs(无界面浏览器)
简单的原理图:
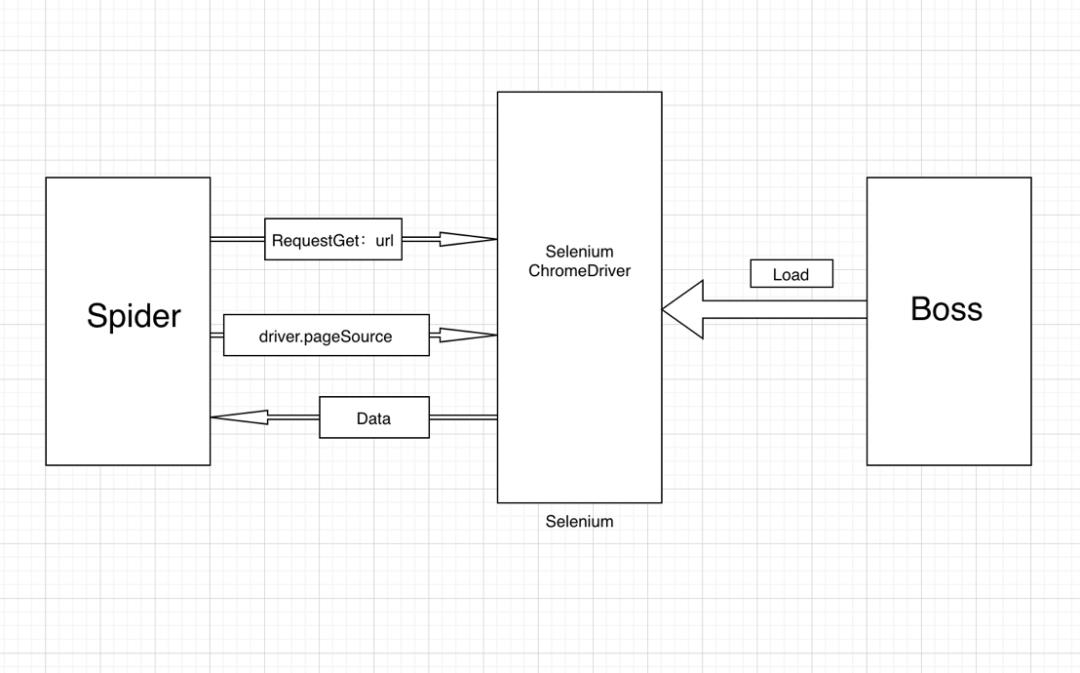
2.1 什么是Selenium
Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
2.2 功能
框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
使用简单,可使用Java,Python等多种语言编写用例脚本。
2.3 优势
Selenium 测试直接在浏览器中运行,模拟用户真实操作。
三、爬虫实战
我们拿拉钩网站作为例子,只是用来做技术研究,勿商用!!!
下面是我们的demo,这个是初始化方法:拿到chrome的driver:

这是核心方法,使用driver加载url:

现在我们的driver就已经加载拉钩的页面了,接下来就能开始解析数据了。
首先拿到页面的内容:

我们输出一下text:
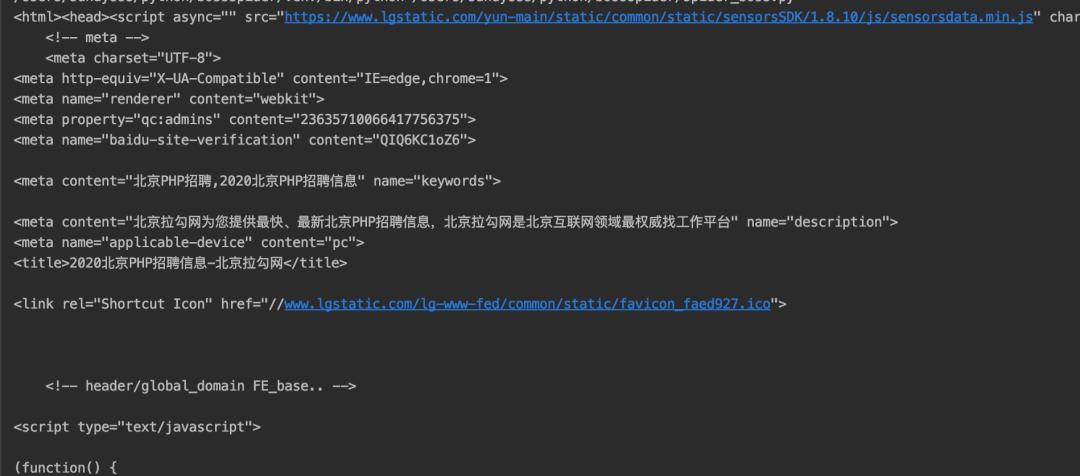
我们找一下我们需要的职位信息:
已经拿到了,剩下的就是解析页面元素信息了,页面解析我们就不介绍了。
好了,我们使用Selenium拿到了我们需要的页面信息,爬虫最重要的步骤就是这里。
最后强调一点:技术本无罪,但是肆意的使用,做恶意的事情就是主观的问题了,所以我们可以学习这种技术,但是不要用于非法目的。
现面向所有技术发烧友
征集优秀原创技术文章
后厂反应堆将为你提供展示平台
期待你的分享哦!
(可添加上图微信投稿)
以上是关于爬虫技术之Selenium的主要内容,如果未能解决你的问题,请参考以下文章