如何应对反爬虫技术?
Posted 深度学习工程师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何应对反爬虫技术?相关的知识,希望对你有一定的参考价值。
如何应对反爬虫技术?
是新朋友吗?记得先点蓝字关注我哦~
介绍了如何使用scrapy框架对豆瓣电影评论进行爬取。由于爬虫获取数据过于频繁,服务器会检测出你是一只爬虫,进而把你的ip被封禁一段时间。这里简单讨论一下如何应对网站的反爬虫技术。
01
通常的应对方法
1. 首先,不能自己告诉服务器你是一只爬虫。例如使用requests库,当不设置请求头的user-agent时,requests发送请求时会自己向服务器坦白,例如:
r.request.headers['user-agent']'python-requests/2.23.0'
2. 使用代理ip。当一个ip段时间内频繁请求服务器时,服务端会有相应的策略判断是不是恶意的爬虫所为。因此,可以考虑使用代理ip的方式,应对反爬虫技术。在scrapy中有三种方式使用代理ip。
1). 使用环境变量设置代理ip;
2). 在发起请求时通过meta参数传递代理设置;
3). 自定义中间件;
其中方式1),所有的请求都使用同一个代理,当爬虫运行一段时间之后还是有被封禁的风险。方式2)和3),可以给每个请求更灵活的分配代理ip,但前提是有可靠的代理ip池,这样就可以自定义代理ip的使用策略了。免费的代理ip通常不稳定或者根本不可用。
3. 修改cookie。cookie是客户端发送请求后从服务端得到数据,下次请求时会带上cookie,服务端就可以进行某些验证了。对于豆瓣电影评论爬取,为了应对反爬虫,每次请求时都将cookie进行随机替换,尽量让服务端认为是不同的用户发起的请求,实践证明,这种方式起到了一定的效果。
4. 控制爬取的速度。以一个服务器可接受的频率发起请求,代价是获得数据的时间变长了。
02
代码实践
这里实践一下通过改变 cookie的方式迷惑服务器。当用浏览器访问豆瓣电影时,可以找到相应的cookie,如下图所示:
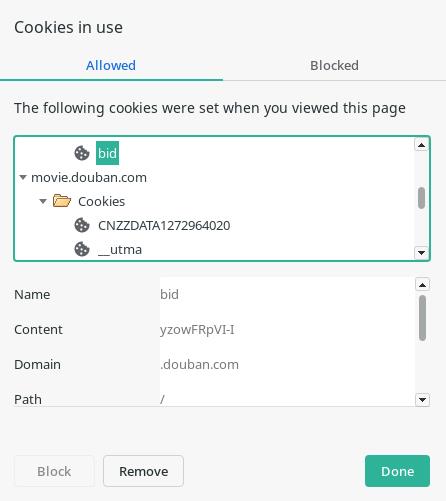
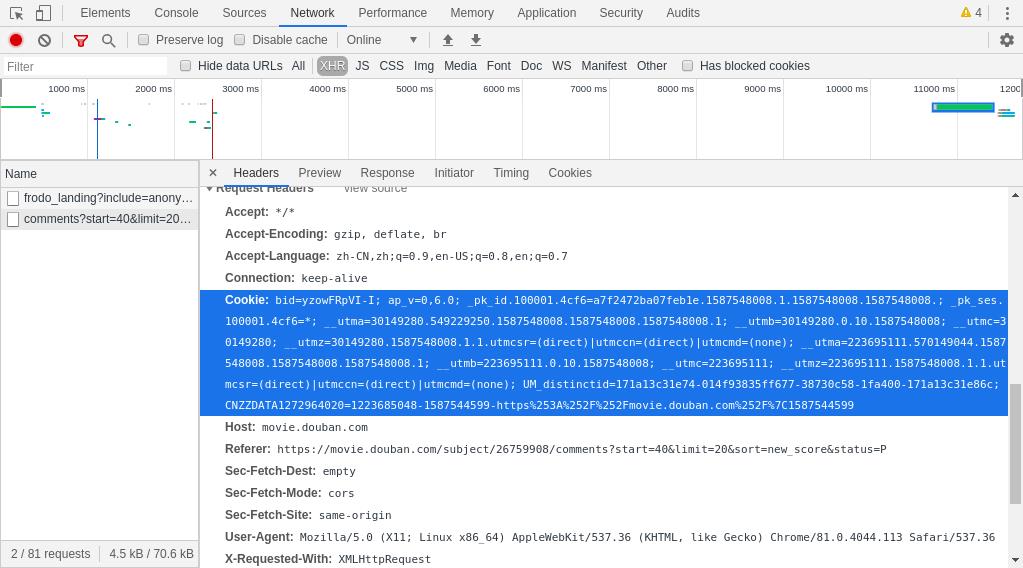
可以看到浏览器里豆瓣的域名下有很多个cookie,在第二次请求时浏览器将cookie发送给了服务器,如下图所示,是请求评论页面时的cookie,其中包含一个name为bid的cookie,爬虫每次发起请求时会修改这个cookie的值。
爬虫开始工作时首先会发起一个请求并记录cookie:
def __init__(self, movie_page_limit=10, comment_page_limit=20):super().__init__(MovieCommentsSpider.name)MovieCommentsSpider.start_urls[0] += '&page_limit=' + str(movie_page_limit)self.comment_page_limit = int(comment_page_limit)# get cookier = requests.head(MovieCommentsSpider.start_urls[0], headers=MovieCommentsSpider.headers)self.cookie = dict(r.cookies.items())
每次发起新的请求前会随机的选取cookie字符串中的一个子串,并将其替换成自己的逆序,得到新的cookie,然后再请求页面:
# update cookiestart = random.randint(0, len(self.cookie['bid']))old = self.cookie['bid'][start:]self.cookie['bid'].replace(old, old[::-1], 1)yield scrapy.Request(url + "&start=" + str(page * 20), headers=MovieCommentsSpider.headers,meta={'level': 1}, callback=self.parse, cookies=self.cookie)
其余部分的代码参考。按照这种简单的方式安全地爬取了6万余条影评数据:
03
待办事项
1. 处理验证码,登录,Js
2. 可靠的代理Ip

欢迎扫码关注
点“在看”给我一朵小黄花
以上是关于如何应对反爬虫技术?的主要内容,如果未能解决你的问题,请参考以下文章