初识java爬虫技术
Posted 小二与小七
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识java爬虫技术相关的知识,希望对你有一定的参考价值。
1 话不多说先来体验一把
环境:
java 9
inteliJ idea 2019.3.4
maven 3.5.2
创建maven工程,添加依赖坐标。
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.xiaoqi</groupId><artifactId>crawler_demo</artifactId><version>1.0.0-SNAPSHOT</version><dependencies><!--httpclient--><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.6</version></dependency><!--日志--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version></dependency><!--test--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency></dependencies></project>
如下代码,试试爬取学校网站讯息。
package com.xioqi.crawler;import org.apache.http.HttpEntity;import org.apache.http.client.methods.CloseableHttpResponse;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.HttpClients;import org.apache.http.util.EntityUtils;import java.io.IOException;public class CrawlerDemo {/**** @param url 请求地址* @return 响应的数据*/public static String getResponseMessage(String url){//根据请求类型创建请求对象,传入请求地址HttpGet httpGet = new HttpGet(url);//声明一个response对象用存放响应的数据CloseableHttpResponse response = null;try {//创建httpClient客户端发起请求并获得响应response = HttpClients.createDefault().execute(httpGet);//获取响应的状态码int statusCode = response.getStatusLine().getStatusCode();System.out.println(statusCode);//一条华丽的分割线System.out.println("======================================");//解析响应数据并返回HttpEntity entity = response.getEntity();return EntityUtils.toString(entity, "utf8");} catch (IOException e) {e.printStackTrace();}finally {//释放资源if (response != null){try {response.close();} catch (IOException e) {e.printStackTrace();}}}return "请求失败";}}
然后写个测试类测试一下,idea快捷键(Shift +Ctrl +t),如下图选择Create New Test...
然后填写以下信息即可快速生成一个测试方法。
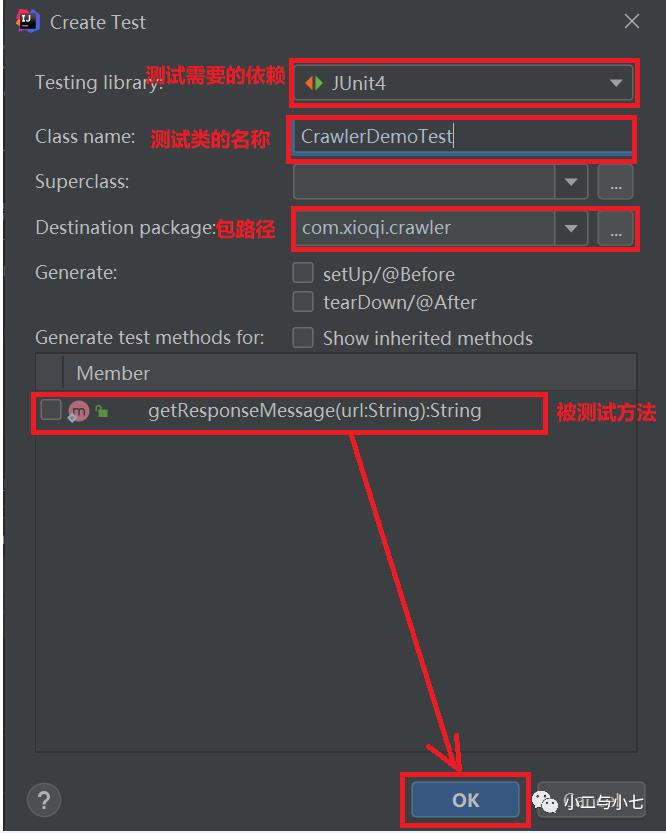
具体如下:
package com.xiaoqi.crawlerTest;import com.xioqi.crawler.CrawlerDemo;import org.junit.Test;public class CrawlerDemoTest {@Testpublic void test01(){String responseMessage = CrawlerDemo.getResponseMessage(""+"http://www.xaut.edu.cn");System.out.println(responseMessage);}}

当然还有这个,这说明什么,我们学校的还是有不错的反爬虫策略(这个呢就不研究了),嗯嗯~,
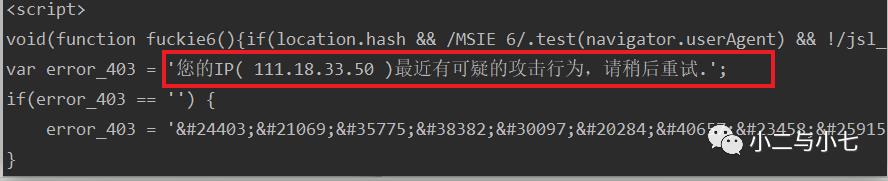
那就换个网址比如这个(http://www.xbiquge.la/),一个小说网站,反正也是盗版再继续被盗也没关系吧~~~~~
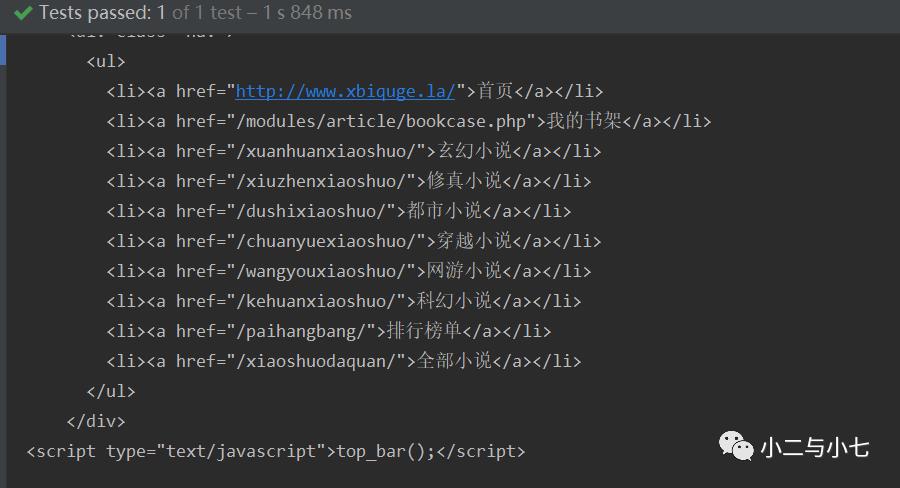
如下图这次就拿到很多讯息了。。。。。
小说的分类
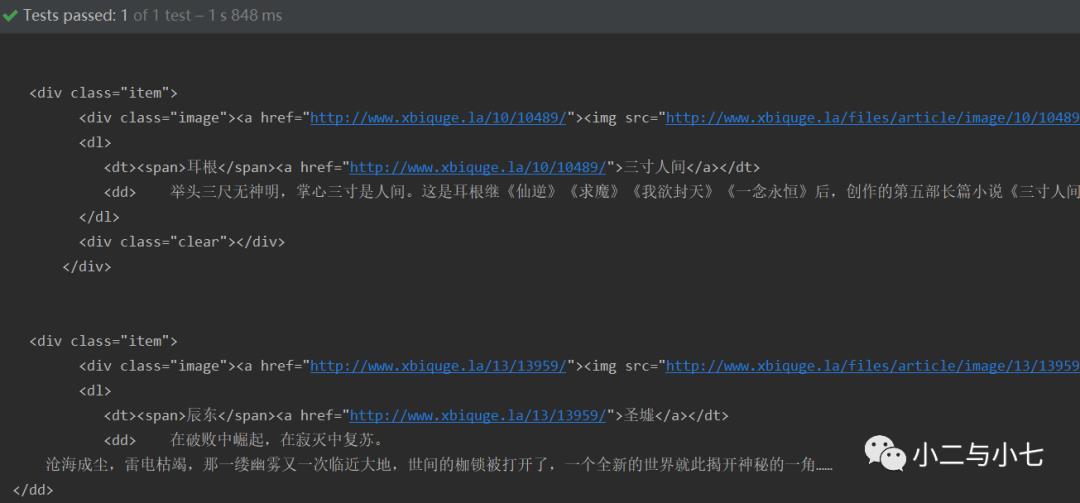
还有这个小说简介。。。
2 网络爬虫简介(复制自百度百科)
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
比如上面的代码,我们获取到的只是一些html的数据,所以还需要进一步的对这些数据进行处理,后面慢慢介绍。
3 其他的请求方式及带参请求
前面是那个例子使用的是get请求的方式,下面使用带有参数的post请求。
public static String postResponseMessage(String url){//声明一个response对象用存放响应的数据CloseableHttpResponse response = null;//根据请求类型创建请求对象,传入请求地址HttpPost httpPost = new HttpPost(url);//声明一个用来封装表单参数的List集合,List<NameValuePair> params = new CopyOnWriteArrayList<>();//访问地址:https://movie.douban.com/subject/33442331/?tag=%E7%83%AD%E9%97%A8&from=gaia_video//BasicNameValuePair是NameValuePair的一个实现类params.add(new BasicNameValuePair("tag","%E7%83%AD%E9%97%A8"));params.add(new BasicNameValuePair("from","gaia_video"));try {//创建一个FormEntity对象,传入表单参数UrlEncodedFormEntity entity = new UrlEncodedFormEntity(params,"utf8");httpPost.setEntity(entity);//创建httpClient客户端发起请求并获得响应response = HttpClients.createDefault().execute(httpPost);//获取响应的状态码int statusCode = response.getStatusLine().getStatusCode();System.out.println(statusCode);//一条华丽的分割线System.out.println("======================================");//解析响应数据并返回HttpEntity httpEntity = response.getEntity();return EntityUtils.toString(httpEntity, "utf8");} catch (Exception e) {e.printStackTrace();} finally {//释放资源if (response != null){try {response.close();} catch (IOException e) {e.printStackTrace();}}return "请求失败";}
测试
@Testpublic void test02(){String responseMessage = CrawlerDemo.postResponseMessage("https://movie.douban.com/subject/33442331/");System.out.println(responseMessage);}
4 请求设置及连接池
如下使用连接池发起post请求。。。
//创建连接池管理对象private static PoolingHttpClientConnectionManager hcm = new PoolingHttpClientConnectionManager();private static String getDoPost(String url) {//从连接池中获取对象CloseableHttpClient client = HttpClients.custom().setConnectionManager(hcm).build();//发送post请求HttpPost httpPost = new HttpPost(url);CloseableHttpResponse response = null;try {response = client.execute(httpPost);return EntityUtils.toString(response.getEntity(), "utf8");} catch (IOException e) {e.printStackTrace();}finally {if (response != null){try {response.close();} catch (IOException e) {e.printStackTrace();}}}return "";}
连接池参数设置
//设置最大连接数hcm.setMaxTotal(50);//设置单台主机的最大连接数hcm.setDefaultMaxPerRoute(5);
请求参数设置
//创建连接池管理对象private static PoolingHttpClientConnectionManager hcm = new PoolingHttpClientConnectionManager();private static String getDoPost(String url) {//设置最大连接数hcm.setMaxTotal(100);//设置单台主机的最大连接数hcm.setDefaultMaxPerRoute(10);//从连接池中获取对象CloseableHttpClient client = HttpClients.custom().setConnectionManager(hcm).build();//配置请求信息RequestConfig config = RequestConfig.custom().setConnectTimeout(2000) //创建连接的最长时间2000毫秒.setConnectionRequestTimeout(1000) //连接请求的最长时间.setSocketTimeout(3000) //数据传输的最长时间.build();//发送post请求HttpPost httpPost = new HttpPost(url);//将配置讯息设置到请求中httpPost.setConfig(config);CloseableHttpResponse response = null;try {response = client.execute(httpPost);return EntityUtils.toString(response.getEntity(), "utf8");} catch (IOException e) {e.printStackTrace();}finally {if (response != null){try {response.close();} catch (IOException e) {e.printStackTrace();}}}return "";}
5 Html解析器--jsoup
前文有提到获取到的响应数据是一个Html文件,我们还需要把所需的数据解析出来,jsoup是一个非常优秀html解析器,现在有很多流行的解析器都是再它的基础上开发出来的。
再pom文件中添加以下坐标
<!--jsoup--><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><!--IO工具--><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency><!--String工具--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.9</version></dependency>
5.1 url解析
获取(https://www.xs4.cc/changshengjie/)这个网站上长生界小说的所有章节讯息。如下图,它所有的章节信息都存储在这个<dd/>标签中,就直接使用标签选择器获取里面的内容。
/*** 解析Url*/public static void urlTest(String url){try {/*** 根据url获取dom对象* 参数一:请求地址* 参数二:超时时间 超时时间尽量长一点*/Document dom = Jsoup.parse(new URL(url), 20000);//使用标签选择器获取对应标签的内容String text = dom.getElementsByTag("dd").text();System.out.println(text);} catch (IOException e) {e.printStackTrace();}}
控制台输出结果,当然也可以把这些数据存在文件中。
睡觉了,那天有空再继续。。。。。
以上是关于初识java爬虫技术的主要内容,如果未能解决你的问题,请参考以下文章