使用爬虫技术揭秘盗版书城背后的秘密
Posted 信安灯塔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用爬虫技术揭秘盗版书城背后的秘密相关的知识,希望对你有一定的参考价值。

继上次python爬取视频,之后会陆续会有一些python小例子的文章分享给大家,以及一些爬虫的思路~~
本次分享的是通过爬虫去爬取小说,话不多说,开工!!!
我们本次以《斗破苍穹》这本小说为例,有没有看过这部小说的朋友啊~~~
经过《python爬取视频》这篇文章中,我们可以知道拿到一个网站要进行分析:
分析浏览器与服务器的请求与响应
分析网站的源代码
同样的我们去度娘搜索《斗破苍穹》
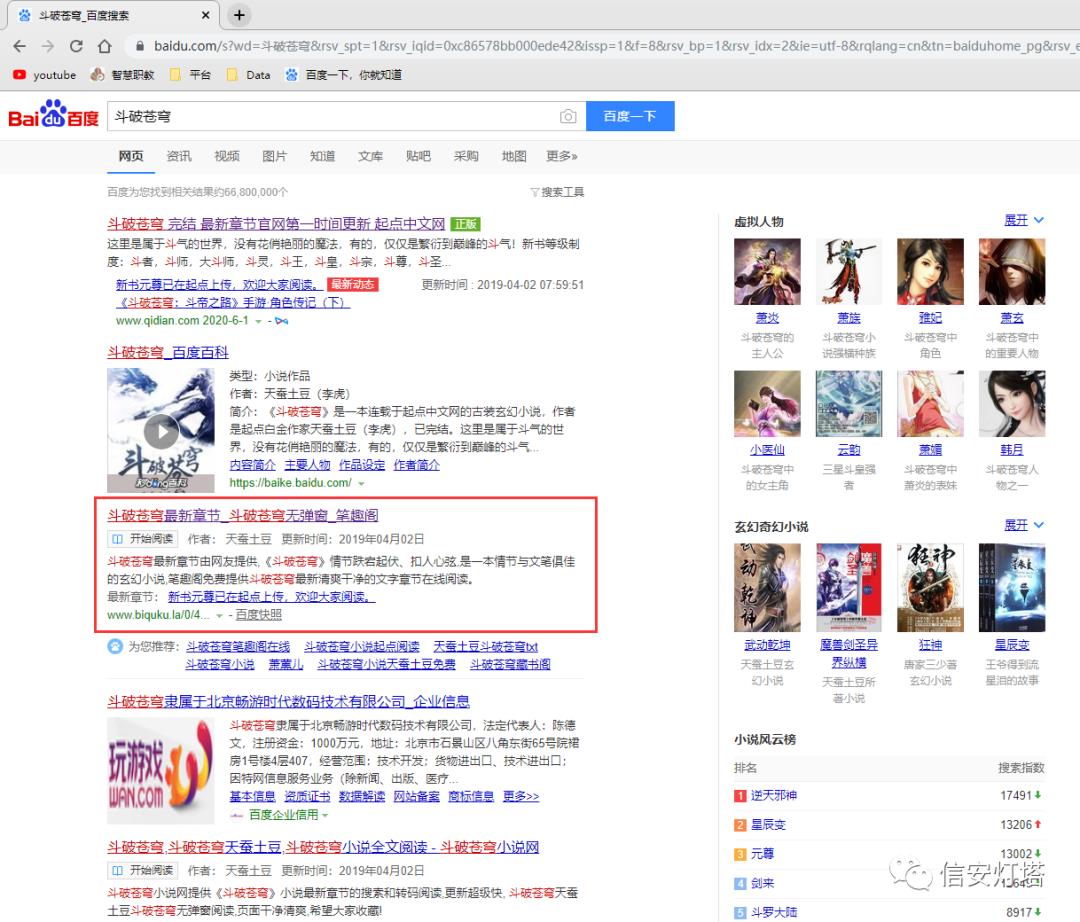
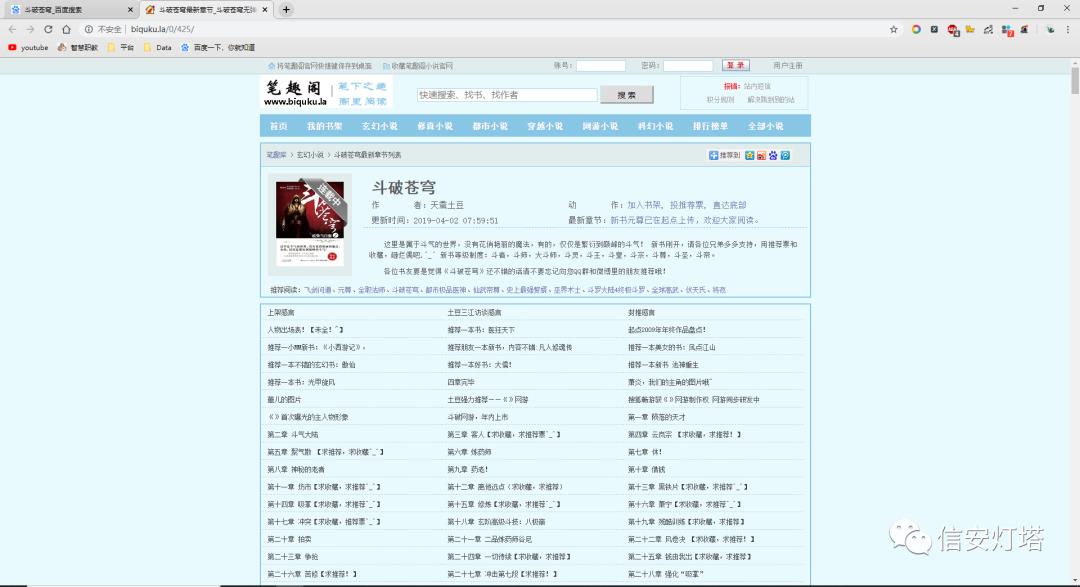
找到一个能看的网站点进去,网站如下:
http://www.biquku.la/0/425/
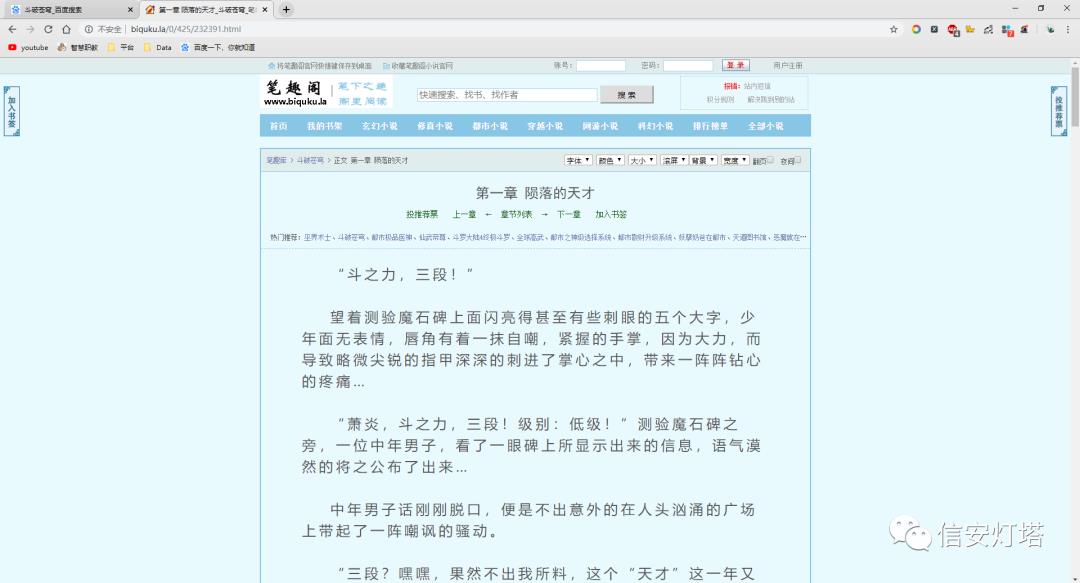
看到这个 "斗之力,三段!" ,有没有勾起你的一丝丝青春, 咳咳咳,跑题了~~~~
我们本次的目标就是将这本《斗破苍穹》这本书的完整内容爬取下来,冲冲冲
http://www.biquku.la/0/425/232391.html
我猜你心里可能会这样想:232391.html 这个232391这个数字会不会代表《斗破苍穹》这本书的编号呢?
答案是肯定的!!!
同样的,通过键盘上的F12,打开检查,也可以右键打开,如下
刷新一下网页
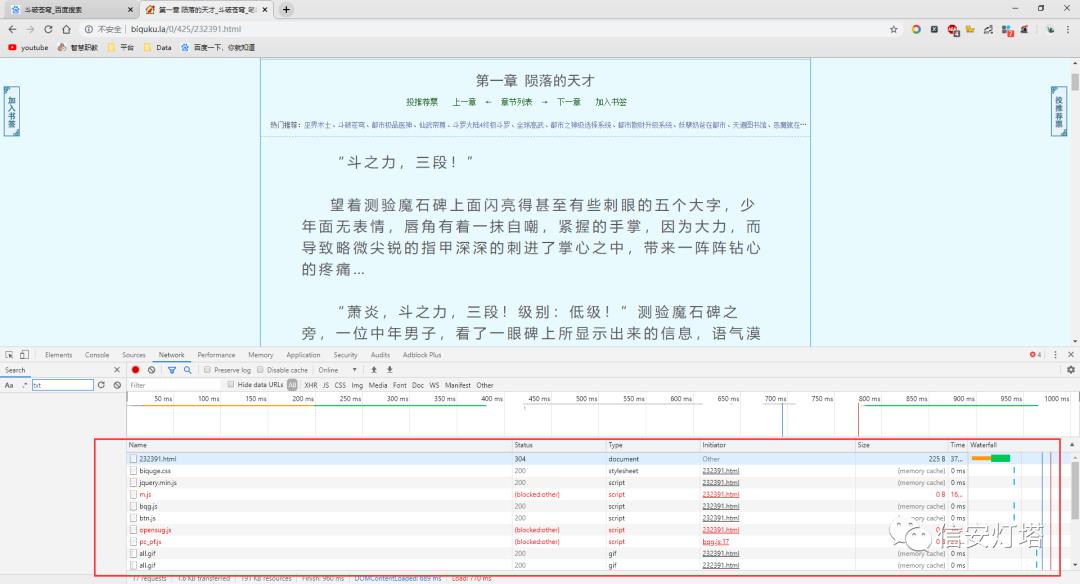
通过浏览器去访问小说的服务器,得到了这么多的文件,又到了找文件环节,上次是视频,根据老辣的经验知道,视频的常见的文件后缀名是MP4,那现在小说会是什么呢?
想啊想啊,文字会是撒? txt? World? emmmmmm.......词穷了
按照这个逻辑去找一下,还是ctrl+F快速查找:
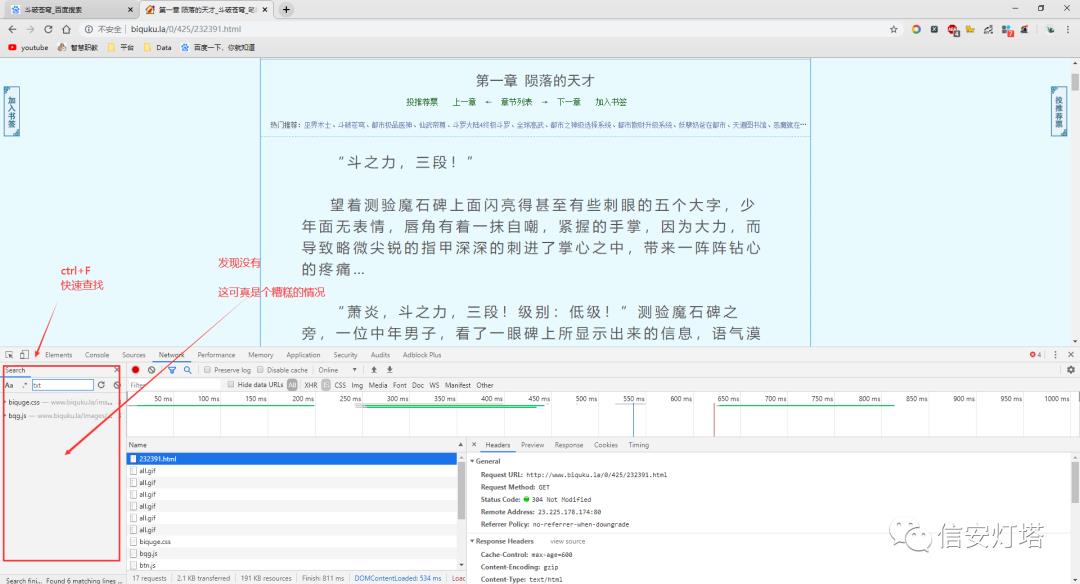
发现没有,那world有吗?不死心,再去试试
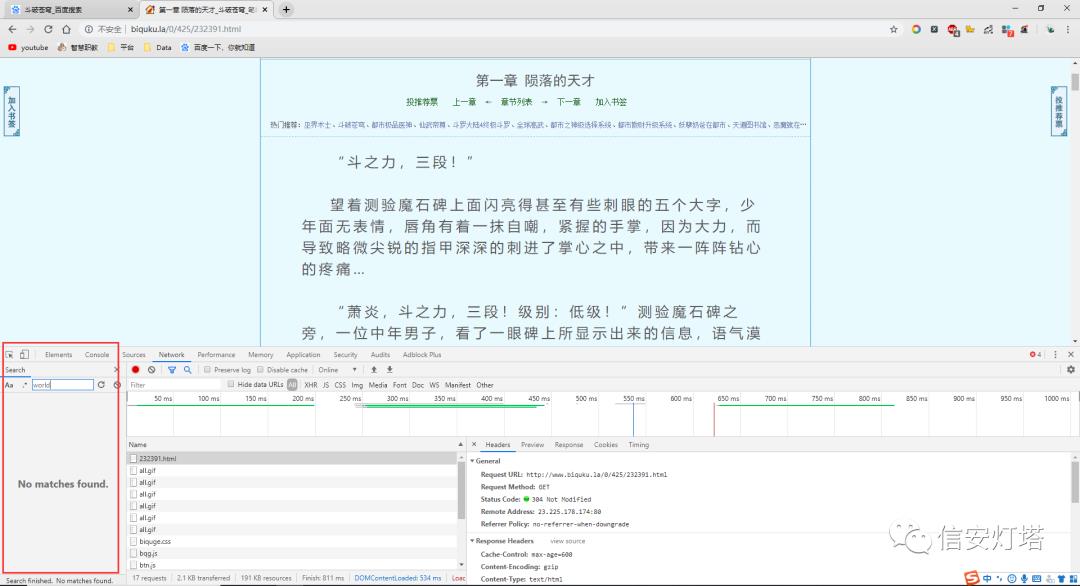
还是撒都没有,完了完了,还没有一丝头绪,只有最后的网页的源代码没有分析了
颤抖这双手,打开网页的源代码,心里这要是在没有点线索该咋搞捏?
通过F12再次打开控制台,如下
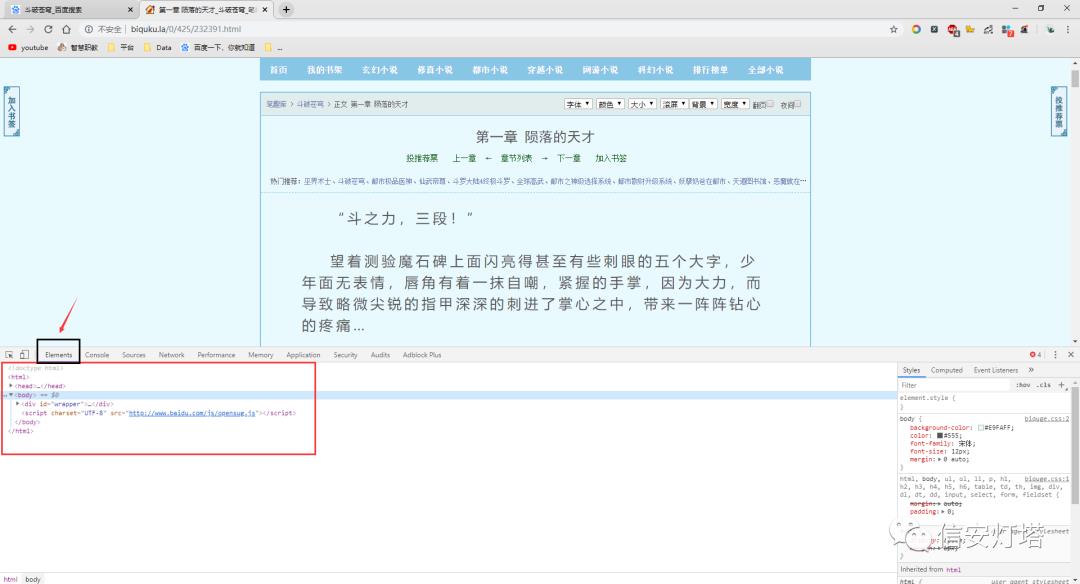
控制台中Elenments中的内容也是网页的源代码,也可以在网页上用右键点击查看网页源代码,也可以用快捷键ctrl+U打开网页源代码
我们这里用控制台来分析网页源代码,这是为什么呢?因为控制台给我们提供了一些很方便的工具使用~~~主要是图个方便~~~
我们来熟悉一下这个控制台
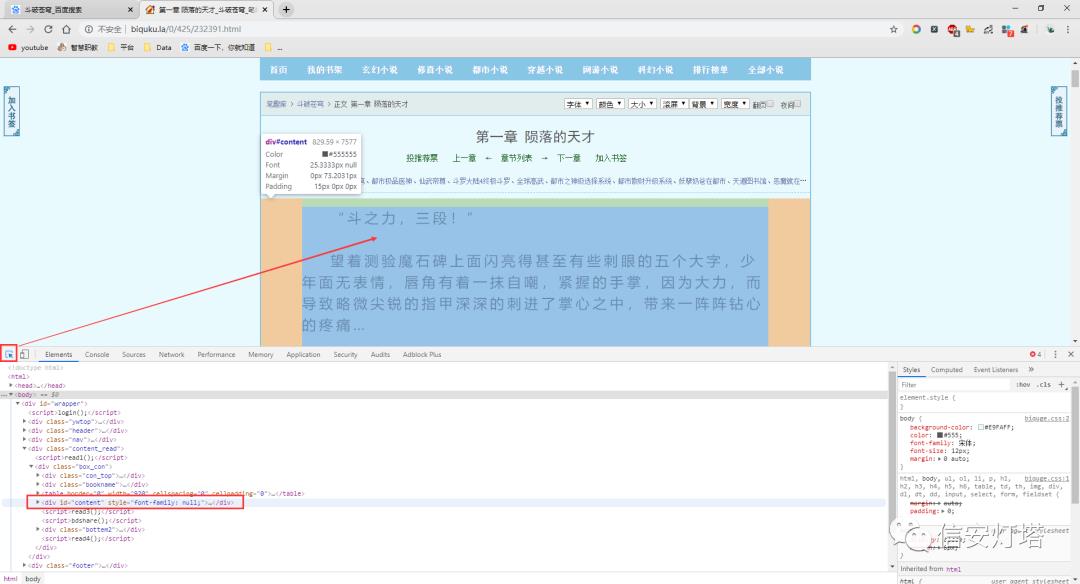
我们通过点击控制台上的鼠标小箭头,然后移动鼠标到上图箭头所指的位置,那么这个箭头是干嘛的呢?这个箭头是用来检索网页上的元素,比如我们现在其实是想要获取到小说的内容,我们就可以看看小说的内容在网页源代码里的位置在哪里
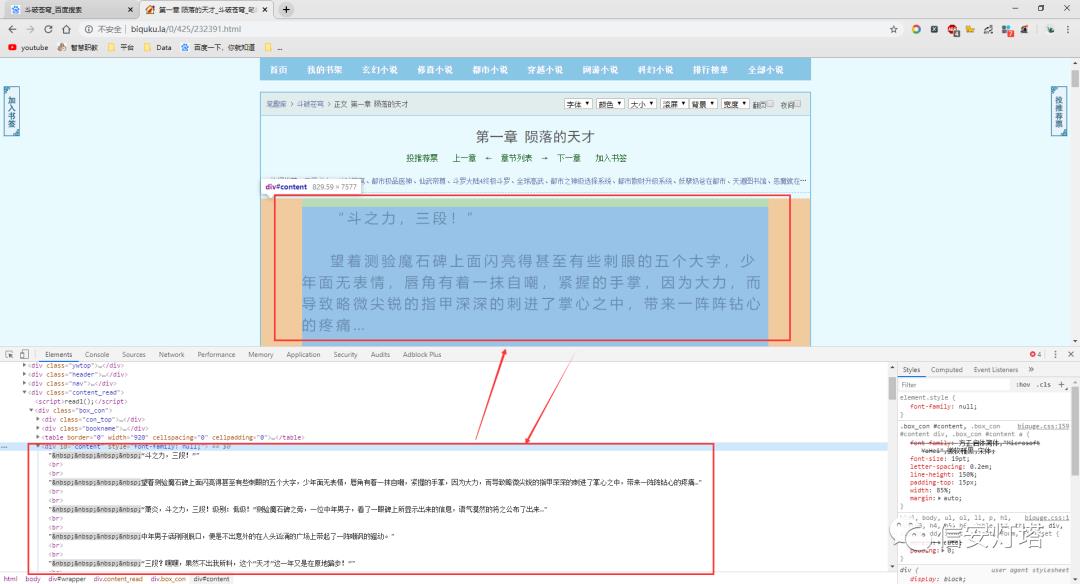
其实如果ctrl+U也可以直观的发现小说的内容在源代码的位置
找到内容之后接下来就是想如何把内容给抓取下来了!!!
import requestsimport parselfrom urllib import parse# 先爬取一章# 请求网址 获取网页数据 htmldef download_one_page(url):res = requests.get(url)# 乱码解决问题 万能解码res.encoding = res.apparent_encoding# 字符串 网页html# 解析方法 正则表达式 xpath css selectorsel = parsel.Selector(res.text)#每一个章节的名字# h1 = sel.css("h1::text")# title = h1.get()book_title_url = url.split(url.split("/")[-1])[0]pes = requests .get(book_title_url)pes.encoding = pes.apparent_encodingbook_title_sel = parsel.Selector(pes.text)h1 = book_title_sel.css("h1::text")title = h1.get()content = sel.css("#content::text")# text = ",".join(content.getall())# 列表合并为字符串lines = content.getall()text = ""for line in lines:text += line.strip() + "\n\n""""保存数据"""with open(title + ".txt", "a", encoding="utf-8") as f:f.write(text)def download_one_book(url):res = requests.get(url)res.encoding = res.apparent_encodingsel = parsel.Selector(res.text)#获取所有的请求网址url_s = sel.css("dd > a::attr(href)").getall()# for url in url_s[20:]:for url in url_s:# 把网址补全url = parse.urljoin(res.url, url)# download_one_page("http://www.biquku.la/0/425/"+url)print(url)download_one_page(url)# 下载一本小说的方法download_one_book("http://www.biquku.la/0/425/")
往期回顾
以上是关于使用爬虫技术揭秘盗版书城背后的秘密的主要内容,如果未能解决你的问题,请参考以下文章