最简单易学的网页爬虫技术,Power BI三步抓取考拉海购商品数据! Posted 2021-04-30 PowerBI学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最简单易学的网页爬虫技术,Power BI三步抓取考拉海购商品数据!相关的知识,希望对你有一定的参考价值。
Power BI可以获取各种数据源,比如常用的Excel、CSV、文本、PDF以及各种关系和非关系型数据库等。我们经常在Web网站上查看各行各业的网页,我们能否用Power BI抓取来自网页端的数据呢?答案是肯定的!
Power BI支持通过Web数据源的方式获取网页数据,同时借助PowerQuery的自定义函数,我们还可以实现多页面数据抓取。今天以抓取考拉海购的商品数据为例,分享一下PowerBI网页爬虫的操作方法。
第一步:分析网页结构,找到真实URL
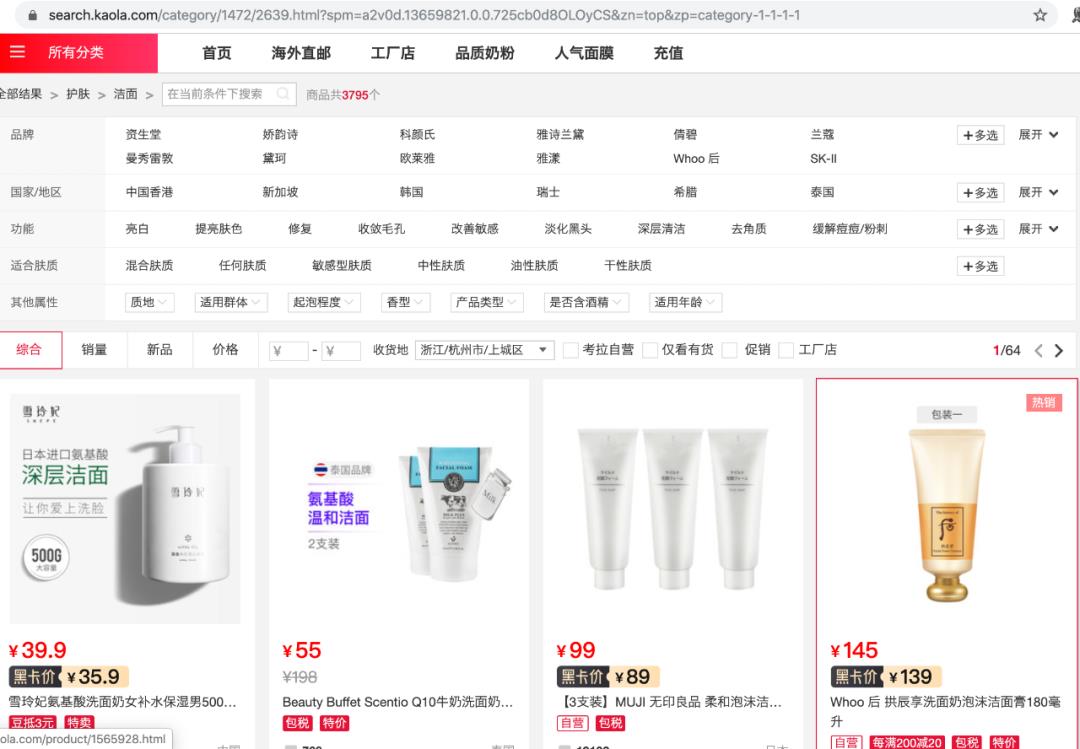
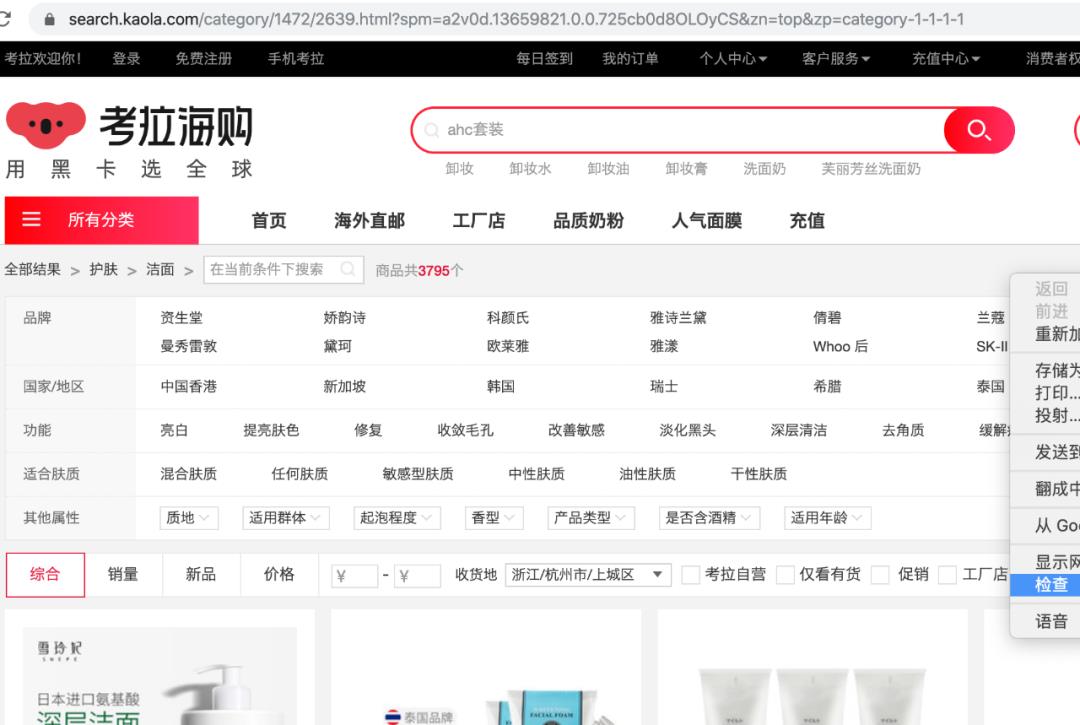
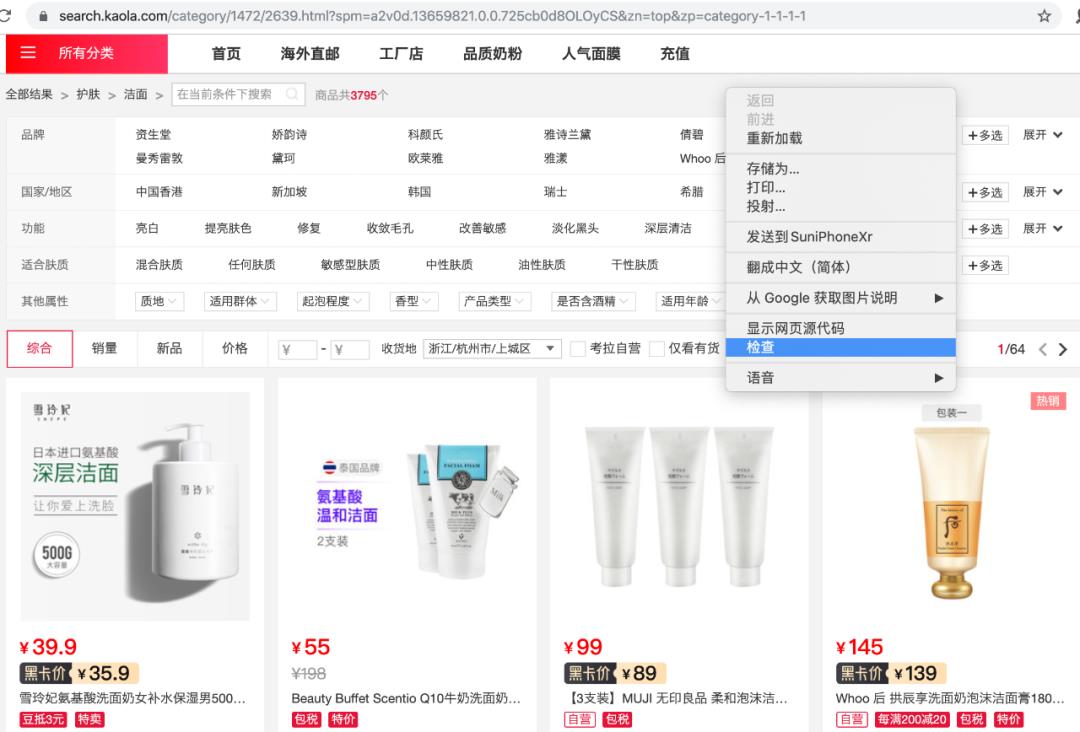
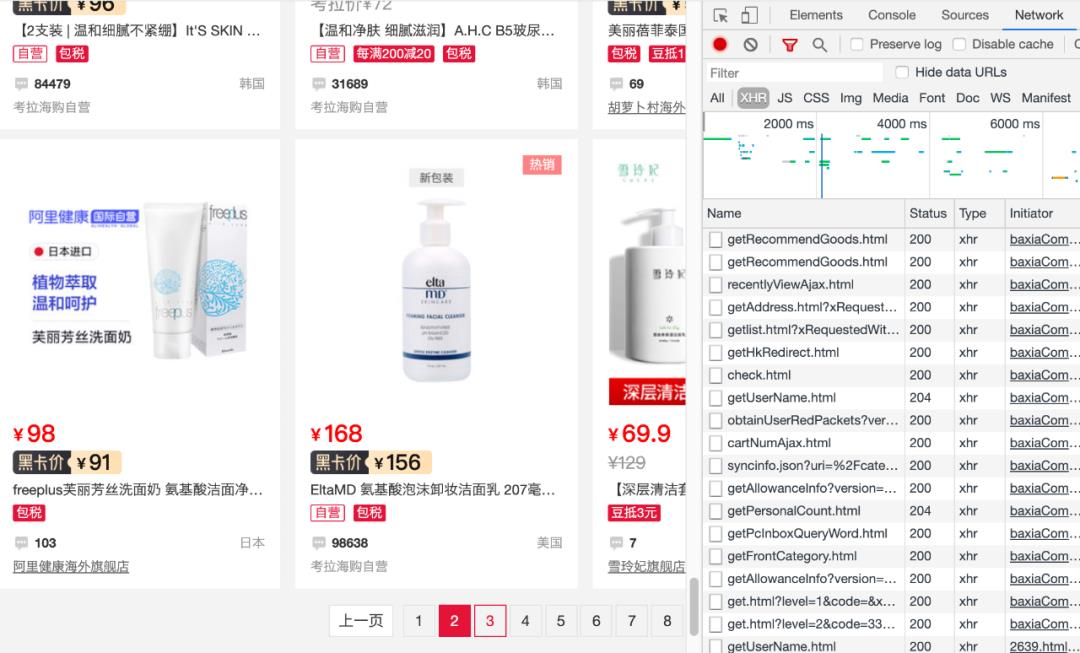
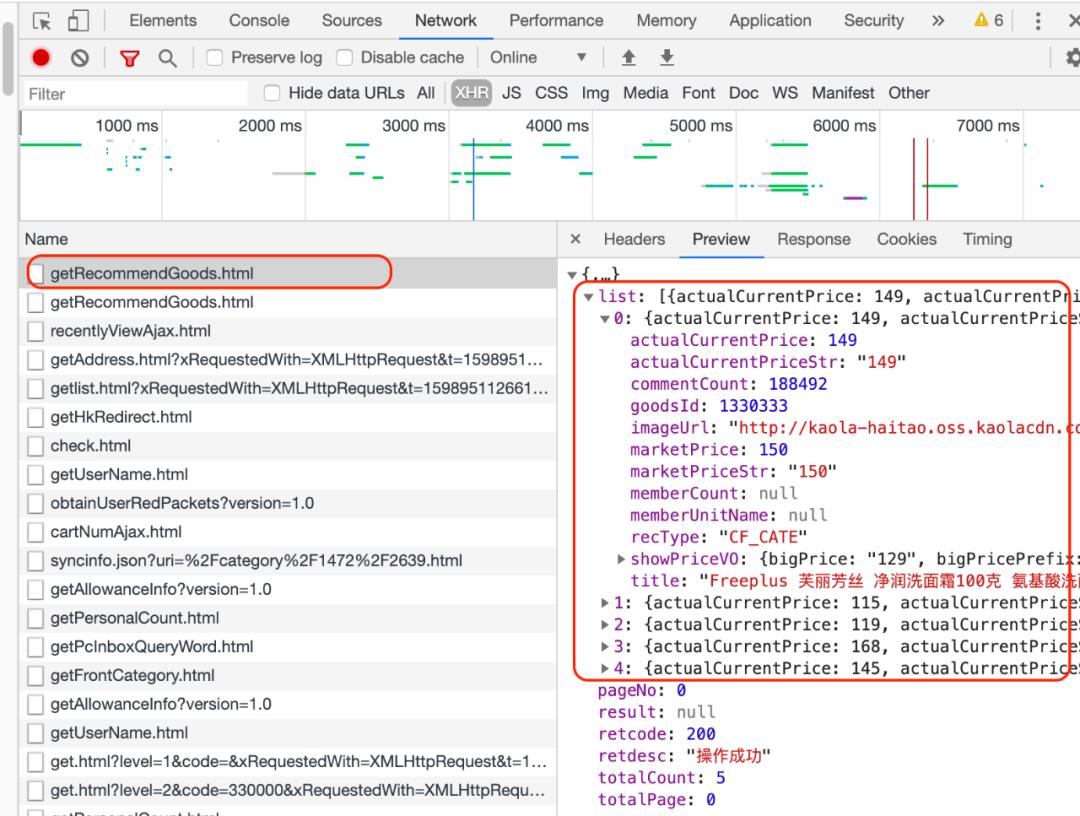
打开考拉网站,浏览至想要抓取的商品页面,单击鼠标右键进入检查页(推荐使用谷歌浏览器),选择Network-XHR。滚动商品页到底后点击页码,连续翻页至第3页,右侧检查出现name数据列表。
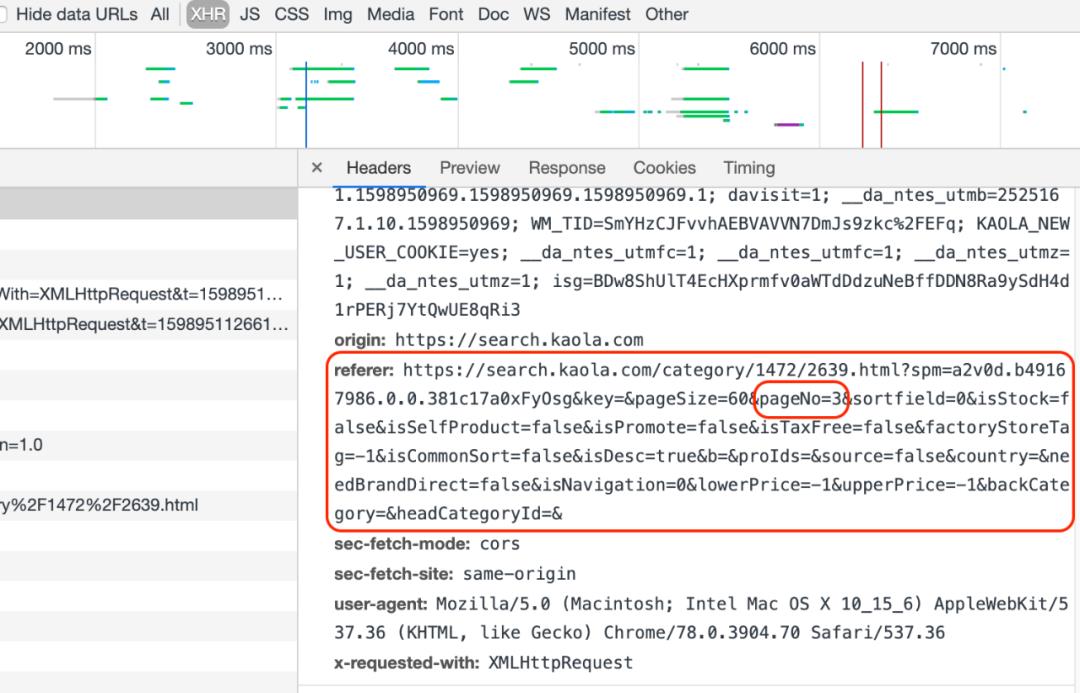
单击name列表里的链接(这里可以看到含goods的链接),查看链接的Preview是否有商品list,确认之后回到Headers,找到网页的真实URL并复制,一般真实URL带有page或pageNO等字段。
第二步:打开PowerBI,构建爬虫函数
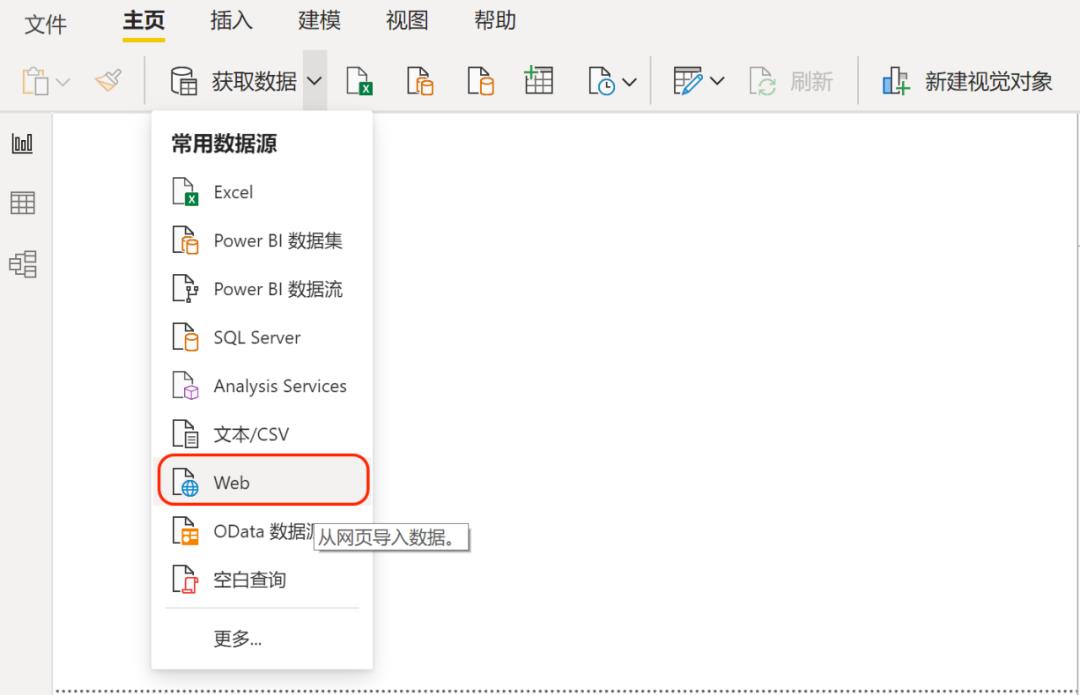
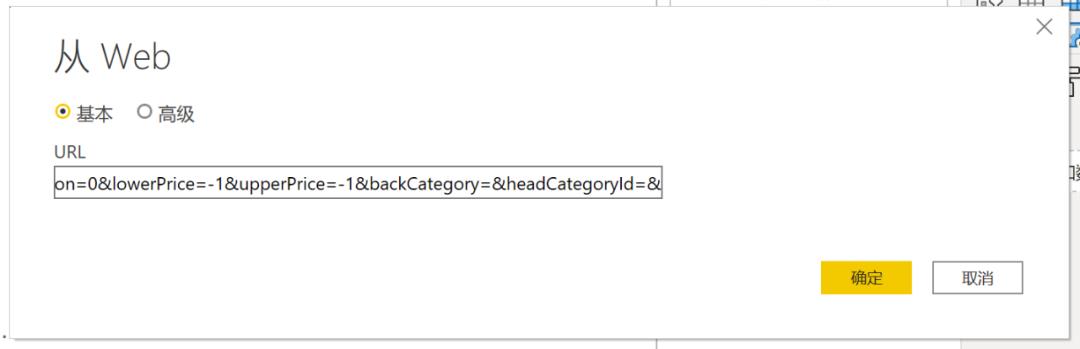
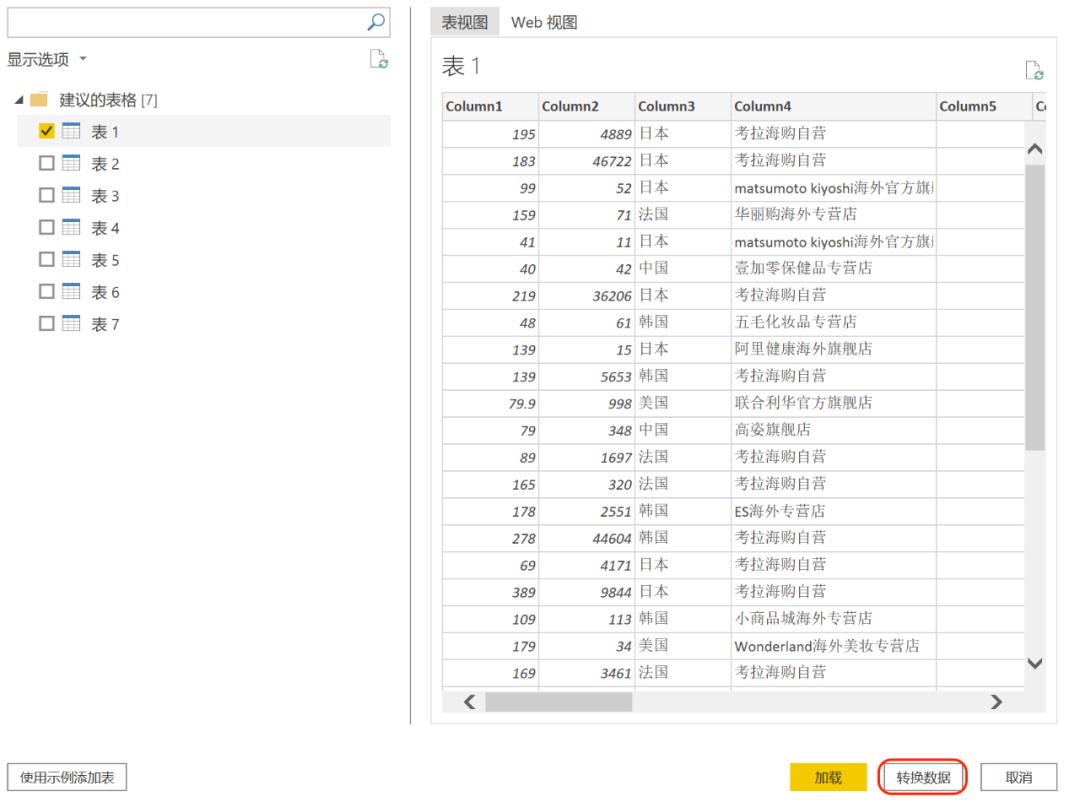
单击【获取数据】->【web】,复制粘贴URL,确认后点击“连接”。连接成功后获得自动检测到的数据表,预览之后选择需要的数据表,点击“转换数据”后进入到PowerQuery中。
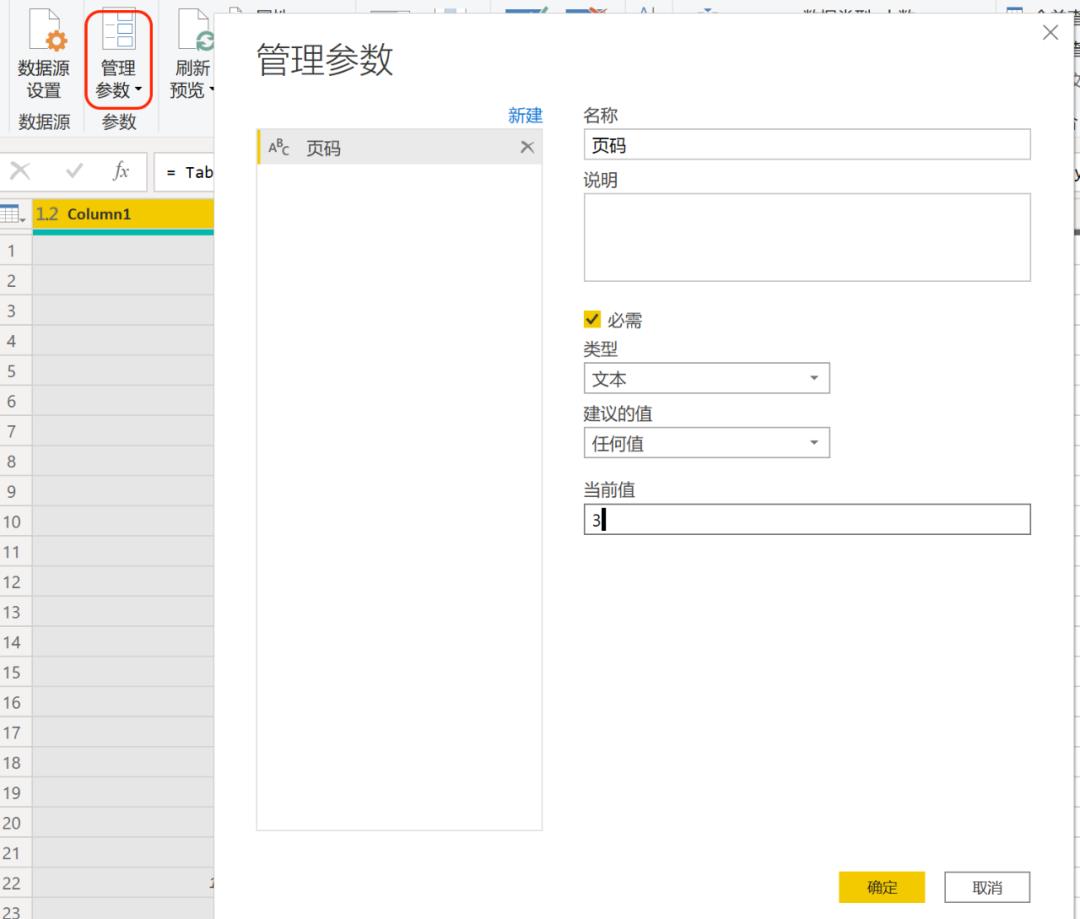
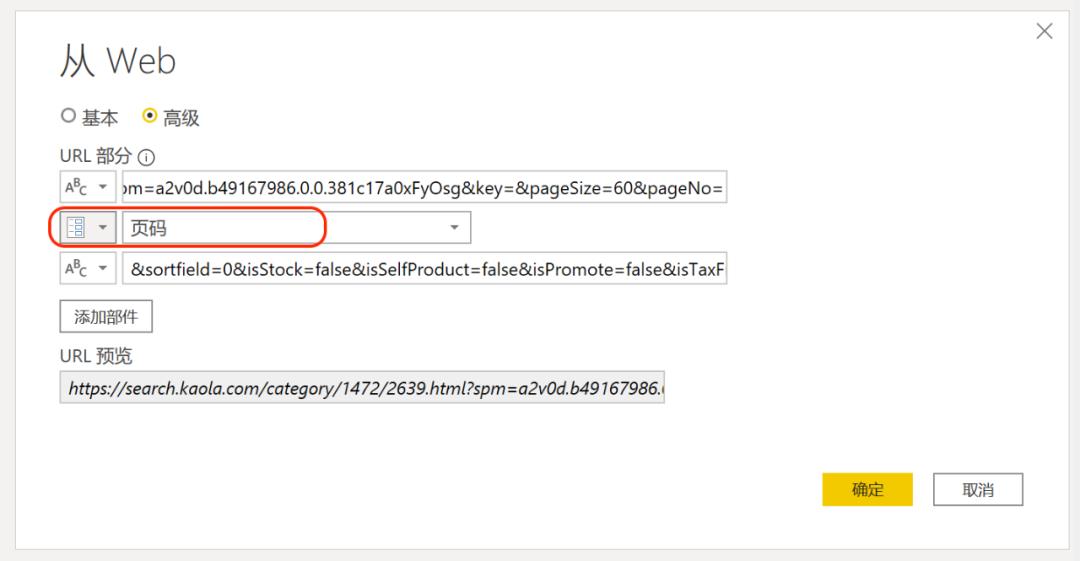
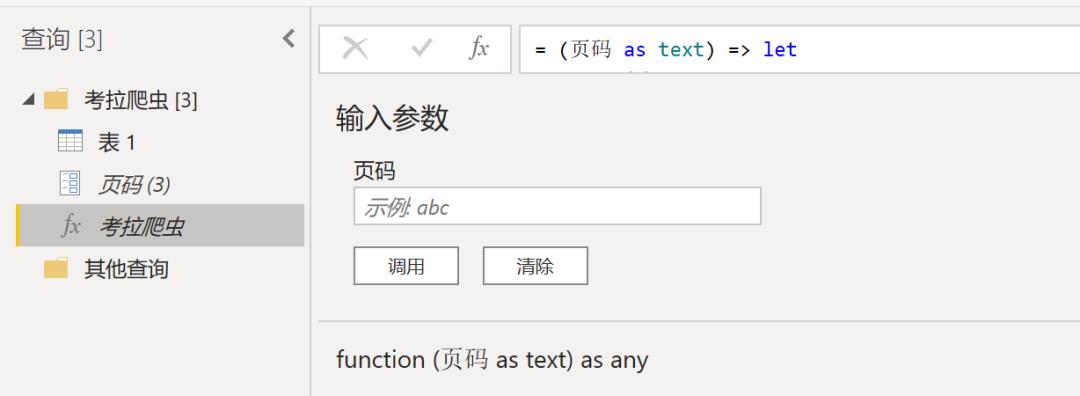
单击【主页】-【参数管理】,创建一个新的参数并命名为【页码】,设置格式为文本,当前值为3。完成后双击步骤【源】,将web获取模式修改为高级,将URL按页码前后分开,页码3替换为参数页码。
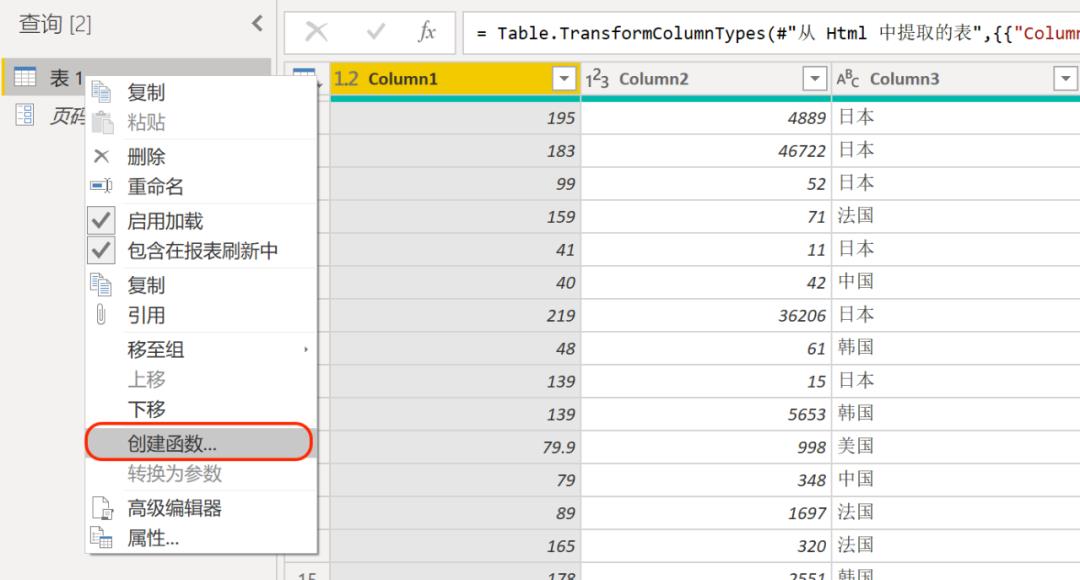
上述步骤完成之后,在查询表处单击鼠标右键选择【创建函数】,到这里商品的爬虫函数就创建完成了。
第三步:创建页码表,应用爬虫函数
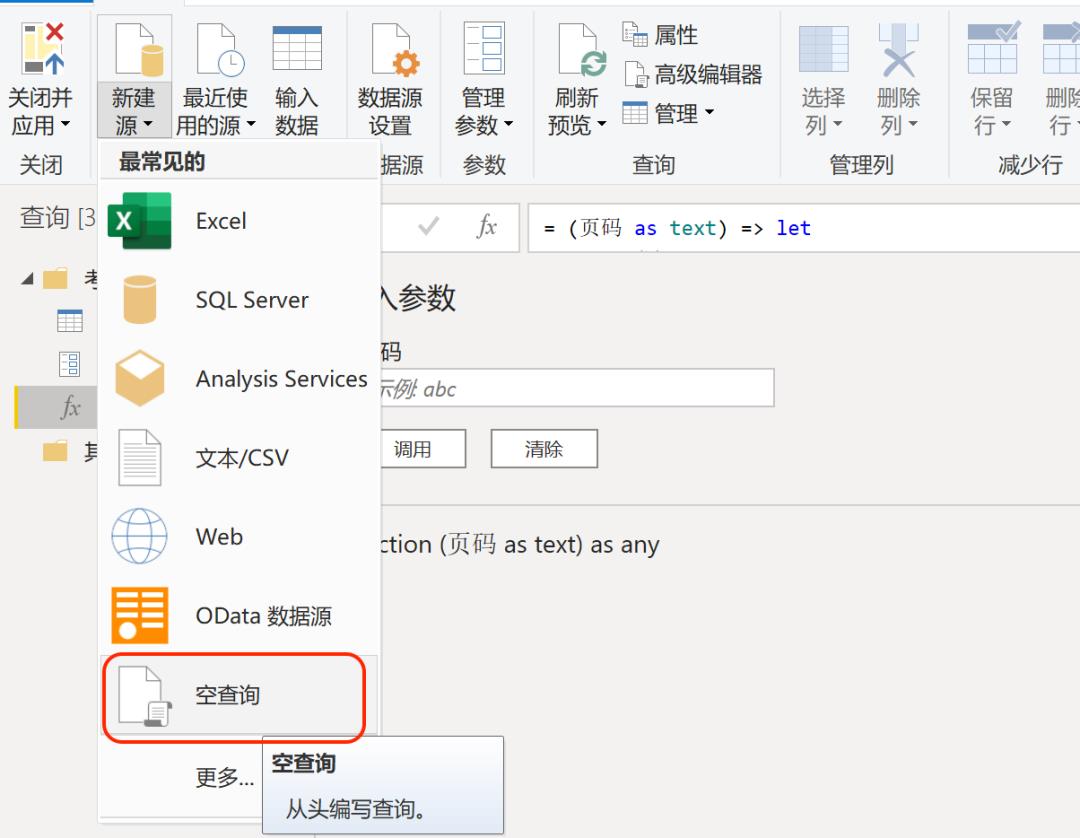
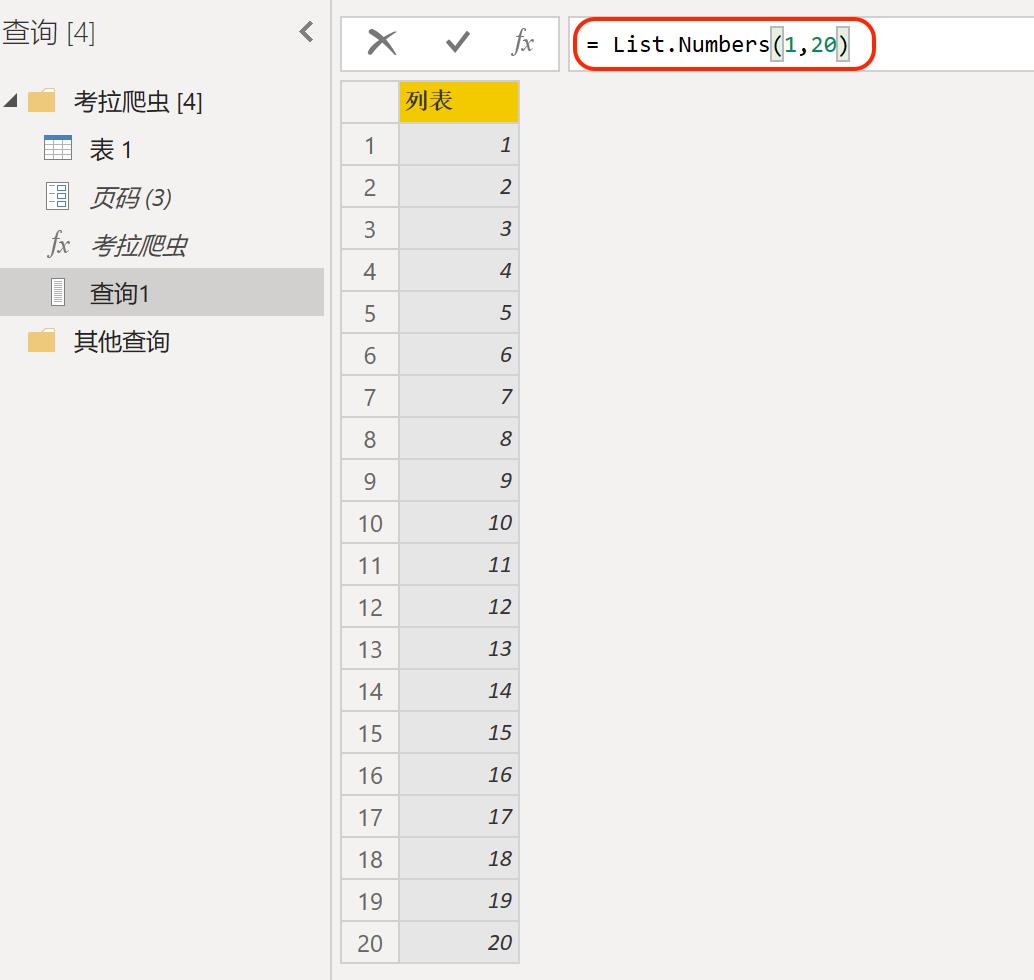
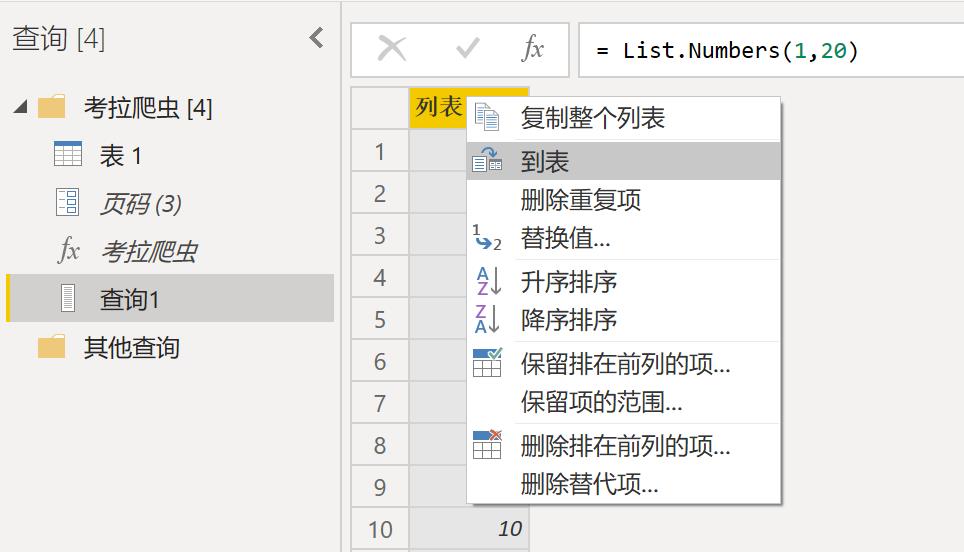
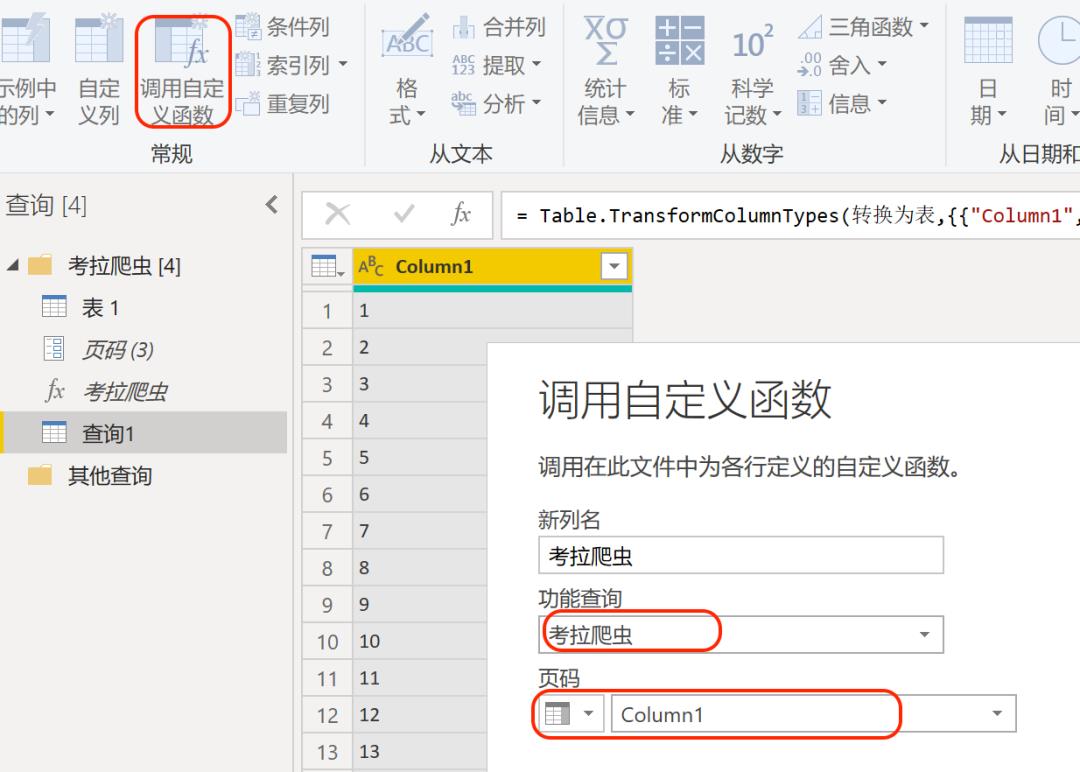
点击【主页】-【新建源】,创建空查询,输入公式=List.Numbers(1-20),创建页码表。页码表不能直接被使用,我们选中页码表单击鼠标右键选择【到表】,并将页码格式设置为文本。
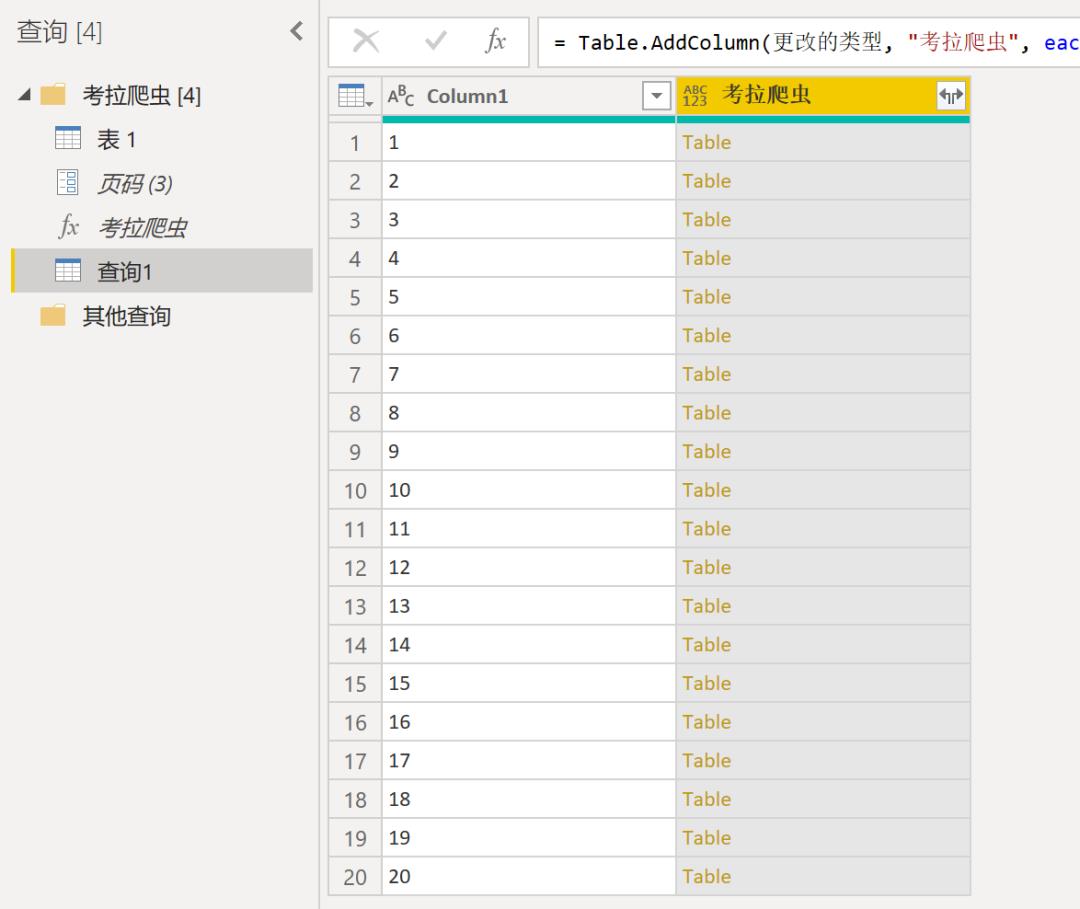
选中页码表,点击【添加列】-【调用自定义函数】,将页码参数设置为页码表的第一列,之后单击确定,爬虫随即开始运行。稍等片刻之后,页码表右侧会生成一个新table列,即代表数据爬取完成。
最后单击table列的下三角,展开table中的列,确认之后20页商品数据就抓取完成了。获取数据之后,我们可以根据自己的需求进行数据清洗及分析等工作。
好啦,以上就是Power BI抓取多页面数据的操作方法和步骤,PowerBI抓取数据还有很多其他不同情况和方法,后面我们会继续展开分享。
如需本次爬取案例的源文件,可以至公众号回复暗号【考拉爬虫】下载。
更多文章/视频:
以上是关于最简单易学的网页爬虫技术,Power BI三步抓取考拉海购商品数据!的主要内容,如果未能解决你的问题,请参考以下文章
power bi如何抓取连续的分秒
如何利用python爬取网页内容
从使用 Power BI 的网站抓取数据 - 从网站上的 Power BI 检索数据
如何用爬虫爬取网页上的数据
用爬虫抓取网页得到的源代码和浏览器中看到的不一样运用了啥技术?
网络爬虫技术的攻与防