网络爬虫技术创建属于自己的有道词典
Posted 程序猿工作室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫技术创建属于自己的有道词典相关的知识,希望对你有一定的参考价值。
这里我们讲到爬虫相关的技术,用python语言来实现。python强大的库为我们提供了许多方便,其独特的语言特性深受广大猿友的喜爱。今天,为大家介绍如何利用python的网络爬虫技术来实现输入自己的有道词典。利用Google来检查一下有道官网的一些源代码,如下图:
首先打开有道的官网,单击鼠标右键,出现有检查的选项,我们点击检查,再点击network,在要翻译框中输入信息,右边network下会有变化。如下
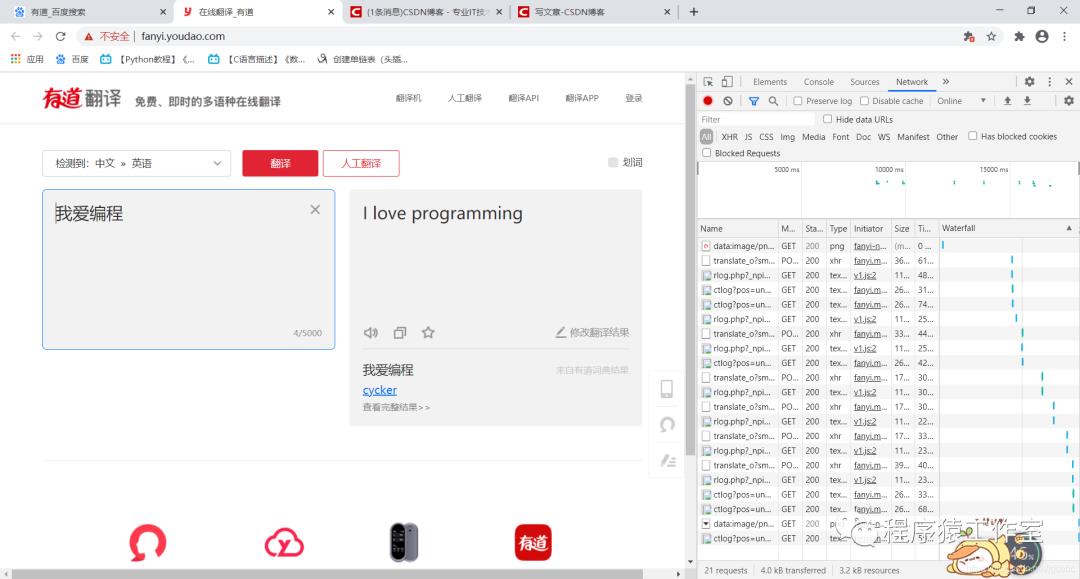
我们来查找相关的信息,与我们输入相关的代码块。我们点击下面的method下面的一些方法,其中有get,post,如果你没有找到method,在name同框下单击鼠标右键可以找到method的选项卡,点击即可。我们点击一个post方法前的名字,出现以下,如图:
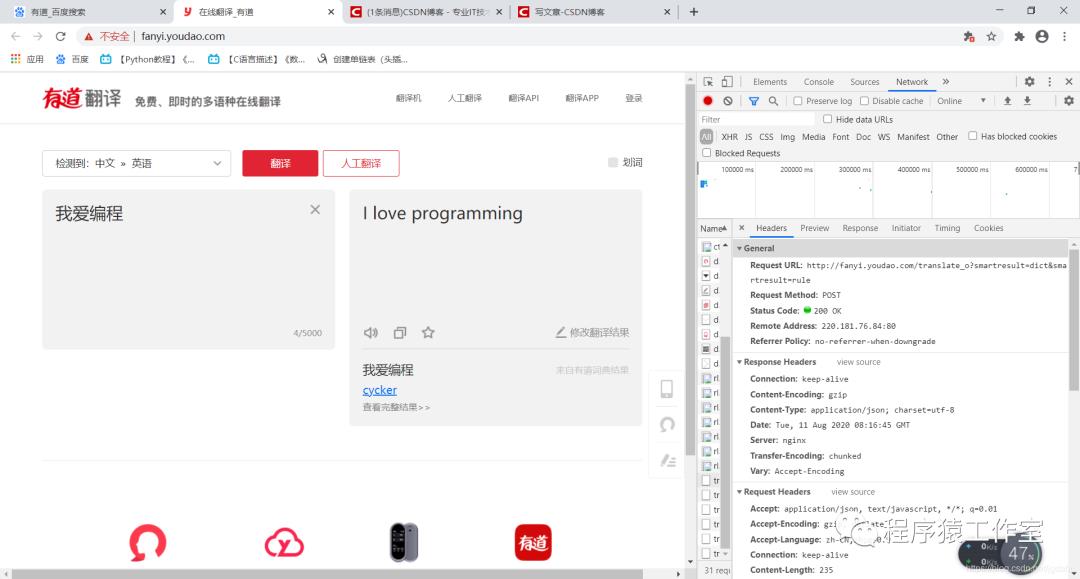
Request URL: http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
Request Method: POST
Status Code: 200 OK
Remote Address: 220.181.76.84:80
Referrer Policy: no-referrer-when-downgrade
那我们需要的是什么呢?
继续往下找,找fromdata:,下面是我们要找的内容,当然我们找的可能不一样,但你要找post中的fromdata,因为程序中需要
i: woaibian
from: AUTO
to: AUTO
smartresult: dict
client: fanyideskweb
salt: 15971347706367
sign: 6ad80e525096fac4d1d2d8276439147a
lts: 1597134770636
bv: 7b07590bbf1761eedb1ff6dbfac3c1f0
doctype: json
version: 2.1
keyfrom: fanyi.web
action: FY_BY_REALTlME
我们先看下代码:
"""
designer : 蒋光道
function : 爬取有道网站内容实现自己的字典
version : 1.0
date: 08/08/2020
"""
import urllib.request #导入urlib中的request模块
import urllib.parse #parse有解析的作用
import json #json是一种格式
text = input("请输入要翻译的内容 :")
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"#注意,这个url前面如果有0_或者是_0相关的,可以去掉,这似乎与反爬虫机制有关,我自己试过。
head={}#这里来模拟浏览器
head["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/84.0.4147.105 Safari/537.36"
data = {}#data是一个字典形式,这正是我们需要提取的
data["i"]= text
data["from"]= "AUTO"
data["to"]="AUTO"
data["smartresult"]= "dict"
data["client"]= "fanyideskweb"
data["salt"]= "15968687717172"
data["sign"]= "ffbf6f4c0c2001ae735f6fb95de58a04"
data["lts"]= "1596868771717"
data["bv"]= "7b07590bbf1761eedb1ff6dbfac3c1f0"
data["doctype"]= "json"
data["version"]= "2.1"
data["keyfrom"]="fanyi.web"
data["action"]= "FY_BY_CLICKBUTTION"
data = urllib.parse.urlencode(data).encode("utf-8")#data在这里转换一下
rep = urllib.request.Request(url,data,head) #此处传入data,请求方式变为post,这里是访问
reponse = urllib.request.urlopen(rep)
html = reponse.read().decode("utf-8")#设定编码
target = json.loads(html)
html_ = target["translateResult"]
html__ = html_[0][0]
print("翻译结果",html__["tgt"])
我的程序测试如下:
还想说的是,python本身也有翻译的库,但其自然有他的局限,这里我也给出代码:
"""
designer : 蒋光道
function : 翻译模块的使用
version : 1.0
date : 04/08/2020
"""
import os
from translate import Translator
Translator = Translator(from_lang="chinese",to_lang="english")
message__ = input("请输入要翻译的信息")
translation = Translator.translate(message__)
print(translation)
看到没有想到简单,但其实这个翻译较慢,我的测试如下:
欢迎大家留言指点,祝大家学好编程!
以上是关于网络爬虫技术创建属于自己的有道词典的主要内容,如果未能解决你的问题,请参考以下文章