0#1hadoop生态圈之日志采集框架Flume入门
Posted 择码记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0#1hadoop生态圈之日志采集框架Flume入门相关的知识,希望对你有一定的参考价值。
【1、简介】
flume 内部是一个个 agent,
agent 内部是 source,sink,channel。
source 用于跟数据源对接,
sink 用于将数据下沉到下一个 agent 或者外部存储系统,
channel 是 agent 内部数据传输通道,用于将数据从 source 到 sink。
图1 单个 agent 采集数据
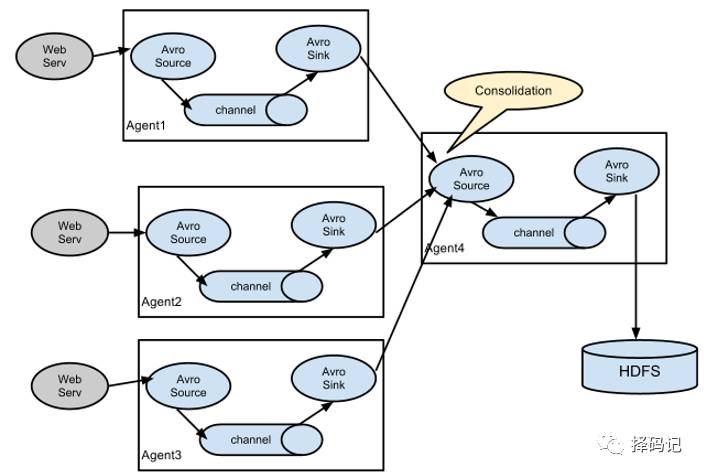
图2 多级 agent 之间串联
【2、安装部署】
1、下载 apache-flume-1.6.0-bin.tar.gz
http://flume.apache.org/download.html
2、解压
tar -zxvf apache-flume-1.6.0-bin.tar.gz -C [指定路径]
3、进入 flume/conf,修改 flume-env.sh,配置 JAVA_HOME
4、配置采集方案,描述在配置文件中,文件名可自定义
5、指定采集方案配置文件,启动 flume agent
【3、一个简单例子:从网络端口接收数据,下沉到 logger】
1、在 flume 下的 conf 目录新建一个配置文件
vi netcat-logger.conf
# 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
# 类型, 从网络端口接收数据,在本机启动,所以localhost
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式
# 下沉的时候是一批一批的,下沉的时候是一个个event
# Channel参数解释
# capacity:默认该通道中最大的可以存储的event数量
#trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、启动 flume-agent
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.conf 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
3、测试
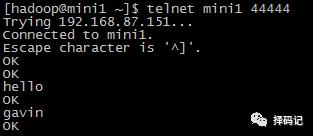

退出 telnet:ctrl + ]
telnet> quit
【4、从文件夹中采集数据】
1、配置文件
vi spool-logger.conf
#定义三大组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source组件
# 监听目录,spoolDir指定目录, fileHeader要不要给文件夹前坠名
# type=spoolDir采集目录源,目录里有就采
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/flumespool
a1.sources.r1.fileHeader = true
# 配置sink组件
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、启动
bin/flume-ng agent -c ./conf -f ./conf/spool-logger.conf -n a1 -Dflume.root.logger=INFO,console
3、测试
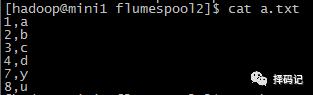
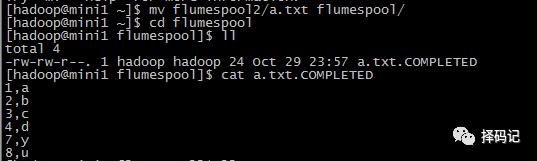
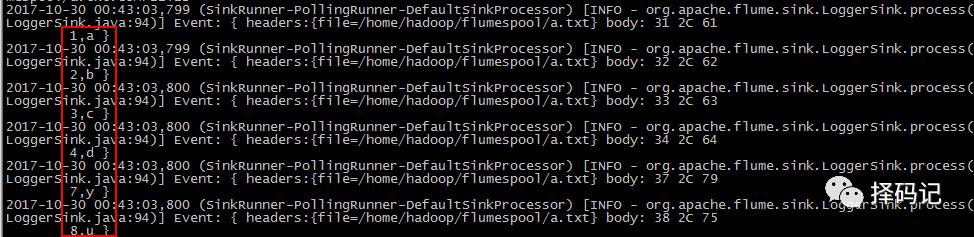
【5、日志文件不断追加内容,用 tail 命令获取数据,下沉到 hdfs】
[hadoop@mini1 conf]$ vi tail-hdfs.conf
#定义三大组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /bi/flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
#以下三行设置了每隔10分钟滚动一次
a1.sinks.k1.hdfs.round = true
#定义三大组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /bi/flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
#以下三行设置了每隔10分钟滚动一次 hdfs 的目录
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
#文件滚动周期(秒)
#每隔 3 秒滚动文件
a1.sinks.k1.hdfs.rollInterval = 3
#文件滚动的大小限制(bytes)
#每 500 字节滚动文件
a1.sinks.k1.hdfs.rollSize = 500
#写入多少个event数据后滚动文件(事件个数)
#每 20 个 events 滚动文件
a1.sinks.k1.hdfs.rollCount = 20
#在刷新到 hdfs 前允许写到文件的 events 个数
#每 5 个 events 更新到 hdfs 一次
a1.sinks.k1.hdfs.batchSize= 5
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

[hadoop@mini1 log]$ cat makelog.sh
#!bin/bash
#每隔一定时间往 test.log 文件追加数据
i=1
while true
do
echo "gavin$i" >> /home/hadoop/log/test.log
i=$(($i+1))
sleep 0.5
done
用命令
tail -F log/test.log
查看追加的效果。
执行 flume agent 命令
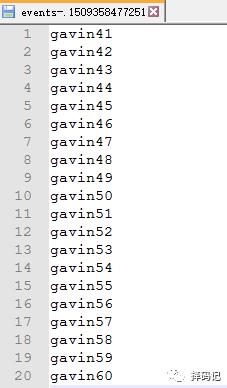
bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1
结果

【6、多个 agent 连接】
从tail命令获取数据发送到avro端口
另一个节点可配置一个avro源来中继数据,
发送到外部存储(
本例直接在命令行打出来方便看到效果,
如果要存储到外部存储,诸如 hdfs,可以参考上例。)
[hadoop@mini1 conf]$ cat tail-avro.conf
#定义三大组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# 配置sink组件
##sink端的avro是一个数据发送者
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = mini2
a1.sinks.k1.port = 4141
a1.sinks.k1.batch = 2
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
从 avro 端口接收数据,下沉到 logger
[hadoop@mini2 conf]$ cat avro-logger.conf
#定义三大组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
# 绑定本机所有 ip
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# 配置sink组件
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在 mini2 上,执行命令
bin/flume-ng agent -c conf -f conf/avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
接收 avro 数据。
在mini1上,执行命令
bin/flume-ng agent -c conf -f conf/tail-avro.conf -n a1
不断接收日志的新数据,以 avro 数据下沉到下一个组件。
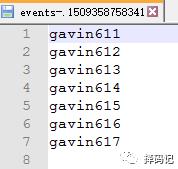
[hadoop@mini1 log]$ sh makelog.sh
结果
并且发现它是分批出现的,一批为 100 个 event。
查看刚才的配置,发现是
a1.channels.c1.transactionCapacity = 100
起了作用。
#trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
关于 flume 入门就到此为止。
更多资料,请参考官方文档:
http://flume.apache.org/FlumeUserGuide.html
以上是关于0#1hadoop生态圈之日志采集框架Flume入门的主要内容,如果未能解决你的问题,请参考以下文章