大数据运维之某银行大数据采集工具Flume性能优化案例
Posted 中亦安图
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据运维之某银行大数据采集工具Flume性能优化案例相关的知识,希望对你有一定的参考价值。
且看中亦科技
如何帮助客户玩转运维大数据
案例概述
某银行运维大数据项目在采集交易系统日志时采用flume1.6的版本,因为日志文件按照时间点不断产生新文件名的文件,该版本现有的source类型无法满足日志采集需求,项目组定制开发新增了一个source类型。使用新source后,基本的采集需求得到了满足,但处理的并发数超过1000进程就会崩溃,并且随着监控文件夹下的日志文件数增多,flume agent会频繁挂起。2017年2月上旬,中亦大数据产品团队顾问应邀赴现场支持,查看分析source代码后发现整个逻辑实现欠妥且耦合度过高,很难在原代码基础上修改。结合代码基本情况和采集需求,大数据产品团队工程师决定采用1.7版本,1.7版本的TaildirSource可以满足上述场景,我们在新版本上定制化开发。通过一系列场景测试分析,客户最终采纳了大数据产品团队工程师的解决方案。同时在测试过程中,我们发现新的问题,如:删除的文件依然占用内存,打开文件数过多后进程会偶尔出现卡死的情况,针对这两个问题,大数据产品团队工程师经过分析和测试得出结论,并给出了相应的解决方案。最终,完全达到了客户当前的场景需求,已经在生产上平稳运行快一年。

问题描述
某城商行核心交易主机每天产生日志文件数在3000-3500,日志文件每半分钟切换一次,监控目录下总文件数在80000-90000。该行大数据项目组在采集交易系统日志时采用flume1.6,因该版本现有的source类型无法满足日志采集需求,项目组自行编写新增了一个source类型。使用新source后,基本的采集需求得到了满足,但自定义source处理并发数不能超过1000,且监控目录下文件数过多时flume agent会挂起。flume采集过程中,删除监控目录下超过保存周期的文件,发现缓存中仍保留着这些文件的信息,对cpu资源和内存空间造成了极大的浪费。另外,随着process过程中打开文件数增多,超过某个上限后系统进程就会卡死,需重启flume agent。
分析解决问题
1
1、中亦工程师分析了该问题,并且根据现有的开源版本和功能,提出来了在1.7版本使用新的功能模块来达到客户要求的建议,中亦工程师进行了严格的测试:
配置测试结果
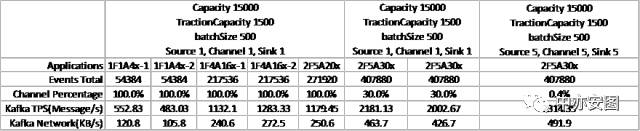
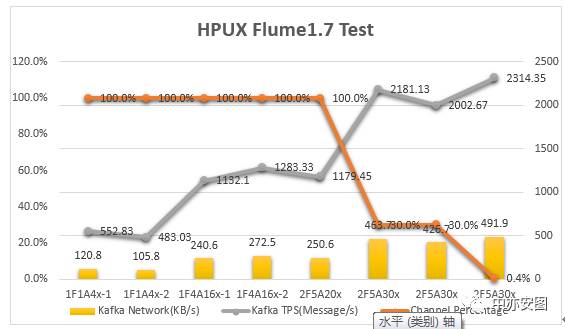
配置说明
测试环境:Flume 1.7 运行于HPUX(XX.XXX.XX.XXX)
Source:TailDirSource
Channel:MemoryChannel
Sink:KafkaSink
Kafka(XX.XXX.X.XX)为测试环境服务器
[测试配置一]:
Channel – 1个
Capacity:15000,
TransactionCapacity: 1500
Source – 1个
batchSize: 500
Sink – 1个
batchSize: 500
[测试配置二]:
Channel – 1个
Capacity:150000,
TransactionCapacity: 15000
Source – 1个
batchSize: 5000
Sink – 1个
batchSize: 5000
[测试配置三]:
Channel – 5个
Capacity:150000,
TransactionCapacity: 15000
Source – 5个
batchSize: 5000
Sink – 5个
batchSize: 5000
[场景一]:1F1A4x
在1个Folder下,1路应用,轮转4次日志
[场景二]:1F4A16x
在1个Folder下,4路应用,每一路轮转4次,共16次日志
[场景三]:2F5A20x
场景一和场景二同时启动
总共2个Folder,5路应用,共20次日志
[场景四]:2F5A30x
场景一和场景二同时启动,分别增加日志轮转次数两次
总共2个Folder,5路应用,共30次日志
结果说明
最终,客户采纳了中亦大数据产品团队顾问的建议,使用1.7版本的flume,并在上做定制化开发。
在完成1.7版本的升级后,采用定制化TaildirSource删除文件仍然占用内存,经分析是因为更新缓存列表时只往列表中添加了新增的文件而未将不存在的文件从列表中移除,通过在updateTailFiles时添加从缓存列表中移除已删除文件的逻辑后,删除文件占用内存的问题最终得以解决;
同时,针对打开文件数过多flume进程出现卡死的情况,中亦科技技术专家分析认为是由于TaildirSource源码对于打开文件的上限没有作限制,一旦达到某个上限,cpu和内存吃紧,从而造成进程卡死。解决办法和前一个问题一样,只要定义一个文件打开的上限,当打开文件数达到上限时强制close tf,并且updateTailFiles 时将其从缓存列表中移除即可。通过相关操作,这个问题也得到了圆满解决。
2
2、对于删除文件占用内存的问题,中亦大数据产品团队工程师在updateTailFiles时添加从缓存列表中移除已删除文件的逻辑后,删除文件占用内存的问题最终得以解决。
3
3、针对process过程中打开文件数过多造成flume进程卡死的问题,中亦大数据产品团队工程师在tail文件时增加打开文件数是否达到上限的判断逻辑,若达到上限,强制close按时间排序的前n个文件并在重新updateTailFiles时将其从文件列表中移除。
问题总结
问题一:process过程中打开文件数达到某个上限后,flume进程会出现卡死的现象,这个问题如何解决?
process遍历匹配文件列表并实例化TailFile时文件被近乎同时地打开并等待处理,如果文件切换较快,缓存列表中还会不断加入新文件,加上处理某些文件可能会耗时过长,这也就意味着等待处理的文件会越来越多,处于累积的状态。Linux下的I/O操作默认是阻塞I/O,即open和socket创建的I/O都是阻塞I/O。当读写操作没有完成时,函数就不会返回,进程会一直阻塞在那里,而flume本身对打开文件超过上限的情况没作任何处理,因此打开文件数达到某个上限后,flume进程会出现卡死的现象。据此,在tail过程中当文件打开数达到某一上限时我们可以尝试强制关闭按时间排序的前n个文件并在重新updateTailFiles时将其从文件列表中移除。
问题二:监控目录下文件删除后仍然占用内存空间的问题如何解决?
文件删除后仍然占用内存,说明虽然文件已经删除,但缓存列表中依然保留着已删除文件信息,且文件处于打开状态,因此在文件删除后遍历文件夹updateTailFiles获取匹配文件缓存列表时关闭已删除的文件并将其从缓存列表中移除。

中亦科技
更多大数据运维的实战案例,且听我们下回分解。
北京中亦安图科技股份有限公司
长按识别左侧二维码,关注“中亦科技”,了解更多内容!
以上是关于大数据运维之某银行大数据采集工具Flume性能优化案例的主要内容,如果未能解决你的问题,请参考以下文章