重磅:Flume1-7结合kafka讲解
Posted 浪尖聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重磅:Flume1-7结合kafka讲解相关的知识,希望对你有一定的参考价值。
本文主要是将flume监控目录,文件,kafka Source,kafka sink,hdfs sink这几种生产中我们常用的flume+kafka+hadoop场景,希望帮助大家快速入生产。
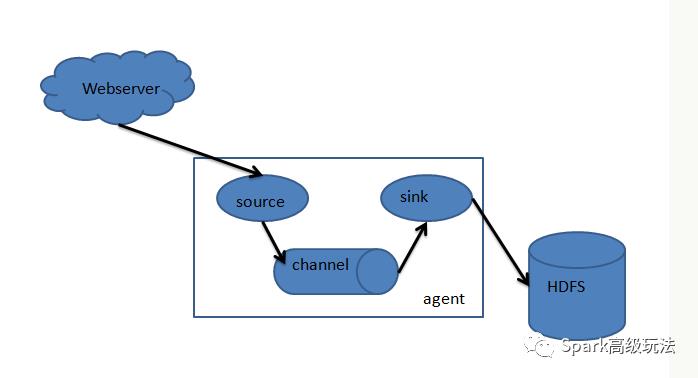
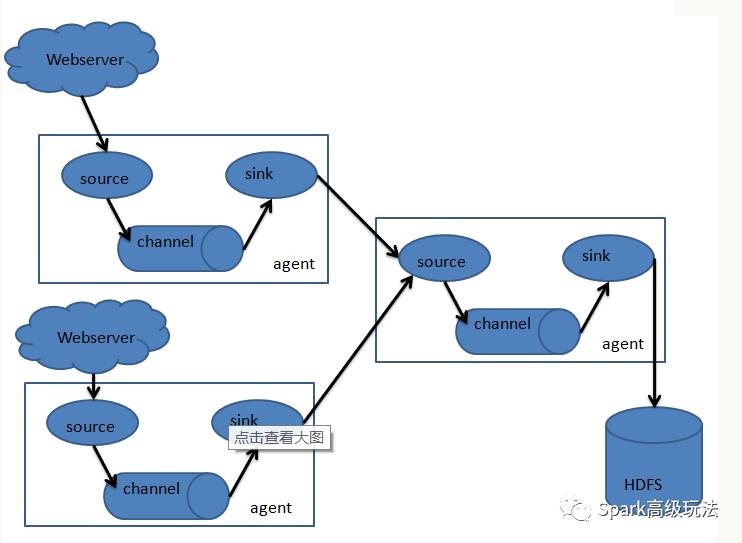
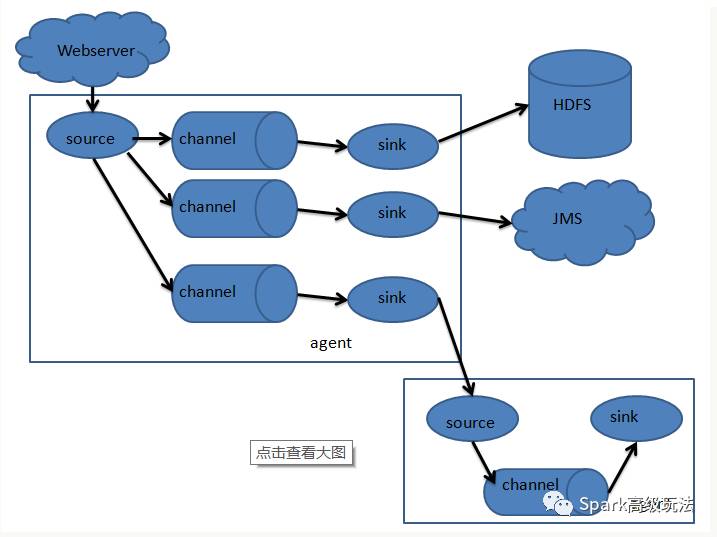
flume只有一个角色agent,agent里都有三部分构成:source、channel和sink。就相当于source接收数据,通过channel传输数据,sink把数据写到下一端。这就完了,就这么简单。其中source有很多种可以选择,channel有很多种可以选择,sink也同样有多种可以选择,并且都支持自定义。同时,agent还支持选择器,就是一个source支持多个channel和多个sink,这样就完成了数据的分发。
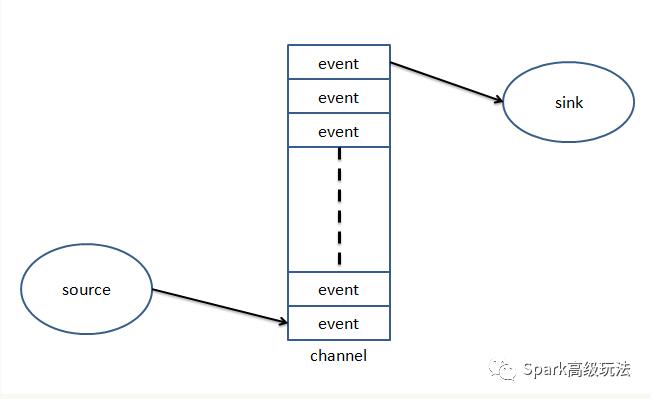
Event是flume数据传输的基本单元
flume以时间的形式将数据从源头传输到目的地
Event由可选的header和载有数据的一个byte array构成:
1,载有数据对flume是不透明的
2,header是容纳了key-value字符串对的无序集合,key在集合内是唯一的。
flume常见的组合方式:
一 Exec Source
Exec源在启动时运行一个给定的Unix命令,并期望该过程持续在标准输出上生成数据(除非将属性logStdErr设置为true,否则stderr将被简单地丢弃)。如果该过程因任何原因而退出,则该来源也退出并且不会产生进一步的数据。这意味着像cat [named pipe]或tail -F [file]这样的配置将产生所需的结果,而日期可能不会 - 前两个命令产生数据流,而后者产生单个事件并退出。
属性名称 |
默认值 |
描述 |
channels |
||
type |
- |
必须是: exec |
command |
- |
要执行的命令 |
shell |
- |
用于运行命令的shell调用。 例如 / bin / sh -c。 仅用于依赖诸如通配符,后退,管道等外壳功能的命令 |
restartThrottle |
10000 |
尝试重新启动之前的等待时间(以毫秒为单位) |
restart |
false |
停掉执行的cmd是否应该重新启动 |
logStdErr |
false |
是否应记录命令的stderr |
batchSize |
20 |
一次读取和发送到Channel的最大行数 |
batchTimeout |
3000 |
在数据被推向下游之前,如果未达到缓冲区大小,则等待的时间(以毫秒为单位) |
selector.type |
replicating |
replicating or multiplexing |
selector.* |
Depends on the selector.type value |
|
interceptors |
- |
Space-separated list of interceptors |
警告:
ExecSource和其它异步源的问题是,源不能保证,如果消息没有写入Channel,客户端知道。这种情况下数据就丢失了,例如,tail -F [file]。 虽然这是可能的,但存在明显的问题。如果channel填满,Flume无法发送event,会发生什么情况?flume无法向应用程序表名由于某种原因他需要保留日志或者事件没有被发送。 如果没有意义,只需要知道这一点:使用单向异步接口(如ExecSource)时,应用程序永远不能保证已收到数据!要获得更高的可靠性保证,请考虑Spooling Directory Source或通过SDK直接与Flume集成。
agent名称为a1的示例:
a1.sources = r1a1.channels = c1a1.sources.r1.type = execa1.sources.r1.command = tail -F /var/log/securea1.sources.r1.channels = c1
“shell”配置用于通过命令shell(例如Bash或Powershell)调用“command”。'command'作为参数传递给'shell'来执行。这允许“command”使用shell中的功能,例如通配符,back tick,管道,循环,条件等。
在没有'shell'配置的情况下,'command'将被直接调用。 'shell'的常见值:'/ bin / sh -c','/ bin / ksh -c','cmd / c','powershell -Command'等
示例:
a1.sources.tailsource-1.type = execa1.sources.tailsource-1.shell = /bin/bash -ca1.sources.tailsource-1.command = for i in /path/*.txt; do cat $i; done
二 Spooling Directory Source
这种source允许你通过往指定目录里防止文件的方式写入数据。这个Source会监控指定的目录是否有新文件产生,然后立即解析新文件里的事件。事件解析逻辑是可以插拔的。如果新文件的数据被读完,就被重命名为完成或者可删除。
不同于exec Source,该source是可靠的并且不会丢失数据,即使flume被重启或者杀死。为了交换这种可靠性,只有不可变的,唯一命名的文件可以放入监控目录。Flume试图检测这些问题条件,如果违反,将会失败:
1, 如果放入到监控目录的文件还在被写入,flume将在其日志文件中输出错误并停止。
2, 如果稍后重新使用了文件名,flume将在其日志里输出错误并停止处理。
为了避免上面的情况,给logs文件名加一个唯一的标识(如时间错)会很有用。
尽管数据源是有可靠性保证的,但是如果发生某些下游故障,仍然有事件出现重复。
属性名称 |
默认值 |
描述 |
channels |
- |
|
type |
– |
必须是spooldir |
spoolDir |
- |
监控的目录 |
fileSuffix |
.COMPLETED |
追加到完全读取文件的后缀名 |
deletePolicy |
never |
何时删除完成的文件:never or immediate |
fileHeader |
false |
是否添加header来存储绝对路径文件名 |
fileHeaderKey |
file |
将绝对路径文件名附加到事件header时使用的header key。 |
basenameHeader |
false |
将文件的基本名称附加到事件头时使用的key。 |
includePattern |
^.*$ |
正则表达式指定要包含哪些文件。它可以与ignorePattern一起使用。如果文件匹配ignorePattern和includePattern正则表达式,则该文件将被忽略。 |
ignorePattern |
^$ |
正则表达式指定要忽略的文件(跳过)。 它可以和includePattern一起使用。 如果文件匹配ignorePattern和includePattern正则表达式,则该文件将被忽略。 |
trackerDir |
.flumespool |
存储于文件处理相关的元数据的目录。如果此路径不是绝对路径,则将其解释为相对于spoolDir。 |
consumeOrder |
oldest |
以何种顺序读取监控目录中的历史文件:oldest, youngest and random. 在oldest和youngest的情况下,将使用文件的最后修改时间来比较文件。在平局的情况下,最小字典顺序的文件将被首先使用。随机的情况下,任何文件将被随机挑选。当使用oldest的和youngest的时候,整个目录将被扫描以选择oldest/youngest的文件,如果文件数量很多,这个过程可能会很慢。而使用随机可能导致旧文件消费很迟,如果新的文件保持进入监控目录。 |
pollDelay |
500 |
查询新文件时使用的延迟(以毫秒为单位)。 |
recursiveDirectorySearch |
false |
是否监控子目录,去读取新增文件 |
maxBackoff |
4000 |
如果channel已满,连续尝试写入channel的最长时间(以毫秒为单位)。每次channel抛出ChannelException时,源将以低回退开始并以指数形式增加,直到由此参数指定的值。 |
batchSize |
100 |
批量传送到Channel的数量 |
inputCharset |
UTF-8 |
输入文件的编码格式 |
decodeErrorPolicy |
FAIL |
当我们在输入文件中看到一个不可解码的字符时该怎么办。 FAIL:抛出异常,无法解析文件。 REPLACE:用“替换字符”字符替换不可解析的字符,通常是Unicode U + FFFD。 IGNORE:删除不可解析的字符序列。 |
deserializer |
LINE |
指定用于将文件解析为事件的反序列化器。 默认将每行解析为一个事件。 指定的类必须实现EventDeserializer.Builder |
deserializer.* |
每个事件反序列化器都不一样。 |
|
bufferMaxLines |
– |
(已过时)此选项现在被忽略。 |
bufferMaxLineLength |
5000 |
(废弃)提交缓冲区中一行的最大长度。 改用deserializer.maxLineLength。 |
selector.type |
replicating |
replicating or multiplexing |
selector.* |
Depends on the selector.type value |
|
interceptors |
– |
Space-separated list of interceptors |
interceptors.* |
例子:
a1.channels = ch-1a1.sources = src-1a1.sources.src-1.type = spooldira1.sources.src-1.channels = ch-1a1.sources.src-1.spoolDir = /var/log/apache/flumeSpoola1.sources.src-1.fileHeader = true
三 kafka sink
flume sink可以将数据发布到kafka一个topic。其中一个目标是将Flume与Kafka集成,以便进行基于拉式的处理系统可以处理来自各种Flume源的数据。Flume当前版本支持kafka0.9系列。Flume1.7已经不支持老版本(0.8.x)kafka。
属性名字 |
默认值 |
描述 |
channels |
||
type |
- |
必须为: org.apache.flume.sink.kafka.KafkaSin |
kafka.bootstrap.servers |
- |
Kafka的Broker,逗号隔开的hostname:port |
kafka.topic |
Defaultflume-topic |
接受数据的kafka,topic |
flumeBatchSize |
100 |
一批中处理多少条消息 更大的批次可以提高吞吐量,同时增加延迟。 |
kafka.producer.acks |
1 |
在考虑成功写入之前,有多少副本必须确认一条消息。 可用值为0(不等待确认),1(仅等待leader),-1(等待所有副本)将其设置为 -1以避免在某些leader失败的情况下数据丢失。 |
useFlumeEventFormat |
false |
默认情况下,事件直接从事件body作为字节消息内容放到Kafka主题上。设置为true来存储events为Flume Avro二进制格式。 与相同属性的KafkaSource或者有parseAsFlumeEvent 属性的KafkaChannel一起使用,将保留任何Flume头。 |
defaultPartitionId |
- |
如果不被partitionIdHeader覆盖,配置该整形值会使得当前channel的所有消息发送到该值指定的kafka分区。默认情况,如果该值没有设置,事件将由kafka分配生成分区-包括如果指定key(或者由kafka.partitioner.class指定的分区器) |
partitionIdHeader |
- |
设置后,sink将从事件header中获取使用此属性值命名的字段的值,并将消息发送到主题的指定分区。 如果该值表示一个无效分区,则会抛出EventDeliveryException异常。 如果标题值存在,则此设置将覆盖defaultPartitionId。 |
kafka.producer.security.protocol |
PLAINTEXT |
如果使用某种安全机制写入Kafka,则设置为SASL_PLAINTEXT,SASL_SSL或SSL。 见下文 有关安全设置的更多信息。 |
more producer security props |
如果使用SASL_PLAINTEXT,SASL_SSL或SSL,请参阅Kafka安全性以获取生产者所需的其他属性。 |
|
Other Kafka Producer Properties |
- |
支持任何kafka支持的Producer属性,使用时需要加上kafka.producer.前缀, kafka.producer.linger.ms |
注意:
Kafka Sink使用FlumeEventheader中的topic和key属性将事件发送到Kafka。 如果header中存在topic,则会将该事件发送到该特定topic,覆盖为sink配置的topic。 如果header中存在key,则Kafka将使用该key对topic分区之间的数据进行分区。 具有相同key的事件将被发送到相同的分区。 如果key为空,事件将被发送到随机分区。
Kafka汇也提供了key.serializer(org.apache.kafka.common.serialization.StringSerializer)和
value.serializer(org.apache.kafka.common.serialization.ByteArraySerializer)。 不建议修改这些参数。
下面给出一个Kafka sink的配置示例。 以前缀kafka.producer开始的属性Kafka生产者。 创建Kafka生产者时传递的属性不限于本例中给出的属性。 也可以在这里包含您的自定义属性,并通过作为方法参数传入的Flume Context对象在预处理器中访问它们。它们通过作为方法参数传入的Flume Context对象在预处理器内部。
实例一:监控文件,写入kafka
kafkasink配置## define agenta1.sources = r1a1.channels = c1a1.sinks = k1## define sourcesa1.sources.r1.channels = c1a1.sources.r1.type = execa1.sources.r1.command = tail -f /opt/logs.txta1.sources.r1.shell = /bin/bash -c## define channelsa1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100##sinksa1.sinks.k1.channel = c1a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSinka1.sinks.k1.kafka.topic = mytopica1.sinks.k1.kafka.bootstrap.servers = localhost:9092a1.sinks.k1.kafka.flumeBatchSize = 20a1.sinks.k1.kafka.producer.acks = 1a1.sinks.k1.kafka.producer.linger.ms = 1a1.sinks.ki.kafka.producer.compression.type = snappy启动kafkazkServer.sh startnohup /opt/modules/kafka_2.11-0.11.0.1/bin/kafka-server-start.sh /opt/modules/kafka_2.11-0.11.0.1/config/server.properties >/dev/null 2>&1 &flume启动bin/flume-ng agent --conf conf --name a1 --conf-file conf/kafkasink.properties -Dflume.root.logger=INFO,console消费者启动1,从上次偏移启动bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic2,从头消费bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic --from-beginning
四 kafka Source
Kafka Source是一个Apache Kafka 消费者,它从Kafka主题中读取消息。 如果您有多个Kafka source运行,您可以使用相同的消费者组配置它们,以便于每个kafka Source实例消费单独的一组partition数据。
属性名称 |
默认值 |
描述 |
channels |
||
kafka.bootstrap.servers |
- |
Kafka Broker列表 |
kafka.consumer.group.id |
flume |
消费者组的唯一标识,多个Source设置相同的id,表示它们同属于相同的消费者组。 |
kafka.topics |
- |
逗号分隔的topic列表 |
kafka.topics.regex |
- |
正则的方式定义订阅的topic。优先级高于kafka.topics,会覆盖kafka.topics假如同时配置的话。 |
batchSize |
1000 |
一个批次写入Channel的最大消息 |
batchDurationMillis |
1000 |
一个批次消息发送给Channel的最大延迟。Time和size任意一个达到界限都会立即发送消息。 |
backoffSleepIncrement |
1000 |
Kafka topic为空时触发的初始和增量等待时间。 等待周期将会减少对Kafka topic的pinging攻击。 一秒钟是在用例中的理想选择,但对于有拦截器的低延迟操作可能需要较低的值。 |
maxBackoffSleep |
5000 |
Kafka topic为空的时候,最大等待时间,5s是理想的选择。但是带有拦截器的低延迟操作可能需要更小的值。 |
useFlumeEventFormat |
false |
默认从kafka Topic取的消息是event body。设置为true将为以Flume Avro binary格式读取event。与相同属性的KafkaSource或者有parseAsFlumeEvent 属性的KafkaChannel一起使用,将保留任何Flume头。 |
migrateZookeeperOffsets |
true |
当找不到Kafka存储的偏移量时,在Zookeeper中查找偏移量并将它们提交给Kafka。 这应该是ture,以支持从旧版本的Flume无缝的Kafka客户端迁移。 一旦迁移,这可以设置为false,但通常不需要。 如果找不到Zookeeper偏移量,则Kafka配置kafka.consumer.auto.offset.reset定义如何处理偏移量。 |
kafka.consumer.security.protocol |
PLAINTEXT |
如果使用某种安全机制写入Kafka,则设置为SASL_PLAINTEXT,SASL_SSL或SSL。 见下文 有关安全设置的更多信息。 |
more consumer security props |
如果使用SASL_PLAINTEXT,SASL_SSL或SSL,请参阅Kafka安全性以获取消费者所需的其他属性。 |
|
Other Kafka Consumer Properties |
Kafka 消费者其它配置可以 以kafka.consumer.为前缀进行设置,例如:kafka.consumer.auto.offset.rese |
|
注意:
kafka Source覆盖了两个kafka参数: auto.commit.enable 被source默认配置未false。Kafka source确保的是至少一次消费语义。当kafka Source启动的时候,消息会被重复消费。Kafka source也提供默认值
为key.deserializer(org.apache.kafka.common.serialization.StringSerializer)和
value.deserializer(org.apache.kafka.common.serialization.ByteArraySerializer)。 不建议修改这些参数。
五 hdfs sink讲解
该sink会将数据写入hdfs,它目前支持创建文本和序列文件,这两种文件格式都支持压缩。可以根据所用时间,数据大小或事件数量定期滚动文件(关闭当前文件并创建一个新文件)。它还通过诸如时间戳或发生事件的机器时间等属性对数据进行存储分桶/分区。HDFS目录路径可能包含格式化转义序列,它们将被HDFSsink替换以生成存储事件的目录/文件名。使用此sink需要安装hadoop,以便Flume可以使用Hadoop jars与HDFS集群进行通信。请注意,需要支持sync()调用的Hadoop版本。
以下是支持的转义序列:
别号 |
描述 |
%{host} |
替换名为“host”的事件标题的值。 任意标题名称被支持。 |
%t |
Unix时间以毫秒为单位 |
%a |
本地的星期短名称(Mon, Tue, ...) |
%A |
本地的星期全名称(Monday, Tuesday, ...) |
%b |
本地月份短名称(Jan, Feb, ...) |
%B |
本地月份全名称(January, February, ...) |
%c |
本地日期和时间(Thu Mar 3 23:05:25 2005) |
%d |
月份中的日期(01,02,03..) |
%e |
月份中的日期,没有填充(1,2,3..) |
%D |
日期,类似: %m/%d/%y |
%H |
hour (00..23) |
%I |
hour (01..12) |
%j |
day of year (001..366) |
%k |
hour ( 0..23) |
%m |
month (01..12) |
%n |
month without padding (1..12) |
%M |
minute (00..59) |
%p |
locale’s equivalent of am or pm |
%s |
seconds since 1970-01-01 00:00:00 UTC |
%S |
second (00..59) |
%y |
last two digits of year (00..99) |
%Y |
year (2010) |
%z |
+hhmm numeric timezone (for example, -0400) |
%[localhost] |
替换agent正在运行的主机的主机名 |
%[IP] |
|
%[FQDN] |
替换运行代理程序的主机的规范主机名 |
正在使用的文件的名称将在最后包含“.tmp”。 文件关闭后,该扩展名将被删除。 这允许排除目录中的部分完整文件。
注意:对于所有与时间相关的转义序列,在事件的header中必须存在一个带有“timestamp”key的header(除非hdfs.useLocalTimeStamp被设置为true)。 一种自动添加的方法是使用TimestampInterceptor。
属性名称 |
默认值 |
描述 |
channel |
- |
- |
type |
- |
必须为: hdfs |
hdfs.path |
- |
HDFS directory path (eg hdfs://namenode/flume/webdata/) |
hdfs.filePrefix |
FlumeData |
名称作为由Flume在hdfs目录中创建的文件的前缀 |
hdfs.fileSuffix |
- |
追加到文件的后缀 |
hdfs.inUsePrefix |
- |
Flume正在写入的临时文件的前缀 |
hdfs.inUseSuffix |
.tmp |
Flume正在使用的临时文件的后缀 |
hdfs.rollInterval |
30 |
滚动当前文件之前等待的秒数(0 =不基于时间间隔滚动) |
hdfs.rollSize |
1024 |
触发滚动的文件大小(以字节为单位)(0:根据文件大小决不滚动) |
hdfs.rollCount |
10 |
滚动前写入文件的事件数量(0 =决不根据事件数量滚动) |
hdfs.idleTimeout |
0 |
超时之后,非活动文件关闭(0 =禁用空闲文件的自动关闭) |
hdfs.batchSize |
100 |
在刷新到HDFS之前写入文件的事件数量 |
hdfs.codeC |
- |
压缩格式. 其中之一均可 : gzip, bzip2, lzo, lzop, snappy |
hdfs.fileType |
SequenceFile |
文件格式:目前SequenceFile,DataStream或CompressedStream。(1)DataStream不会压缩输出文件,请不要设置codeC。(2)CompressedStream需要设置hdfs.codeC与一个可用的codeC。 |
hdfs.maxOpenFiles |
5000 |
只允许这个数目的打开的文件。 如果超过这个数字,则关闭最早的文件 |
hdfs.minBlockReplicas |
- |
指定每个HDFS块的最小数量的副本。 如果未指定,则它来自Classpath中的默认Hadoop配置。 |
hdfs.writeFormat |
- |
序列文件记录的格式。“Text”或“Writable”(默认)。 |
hdfs.callTimeout |
10000 |
HDFS操作允许的毫秒数,例如打开,写入,刷新,关闭。如果发生许多HDFS超时操作,则应该增加此数字。 |
hdfs.threadsPoolSize |
10 |
HDFS IO操作的每个HDFSsink的线程数(打开,写入等) |
hdfs.rollTimerPoolSize |
1 |
调度定时文件滚动的每个HDFSsink的线程数 |
hdfs.kerberosPrincipal |
- |
Kerberos user principal for accessing secure HDFS |
hdfs.kerberosKeytab |
- |
Kerberos keytab for accessing secure HDFS |
hdfs.round |
false |
时间戳向下舍入(如果为true,则影响除%t之外的所有基于时间的转义序列) |
hdfs.roundValue |
1 |
舍入到最高的倍数(在使用hdfs.roundUnit配置的单元中),小于当前时间。 |
hdfs.roundUnit |
second |
舍入值的单位 - 秒,分或小时。 |
hdfs.timeZone |
Local Time |
应用于解析目录路径的时区的名称,例如美洲/洛杉矶。 |
hdfs.useLocalTimeStamp |
false |
使用本地时间(而不是来自事件头的时间戳),同时替换转义序列。 |
hdfs.closeTries |
0 |
启动关闭尝试后,sink必须尝试重命名文件的次数。如果设置为1,则此sink不会重试失败的重命名(例如,由于NameNode或DataNode失败),并可能使文件保持打开状态,扩展名为.tmp。如果设置为0,sink将尝试重命名文件,直到文件最终重命名为止(对尝试次数没有限制)。如果关闭调用失败,文件仍可能保持打开状态,但数据将保持不变,在这种情况下,只有在重新启动Flume后,文件才会关闭。 |
hdfs.retryInterval |
180 |
连续尝试关闭文件之间的间隔(以秒为单位)。每次call都需要多次与namenode之间的RPC,所以该值设置过低会给namenode带来负担。如果0或者很小,则在第一次尝试失败时,sink将不会尝试关闭文件,并可能使文件保持打开状态或带有 “.tmp”扩展名。 |
serializer |
TEXT |
其他可能的选项包括avro_event或EventSerializer.Builder接口实现的完全限定类名。 |
实例二:Kafka Source 和 hdfs sink
kafka source配置## define agenta1.sources = s1a1.channels = c1a1.sinks = k1## define sourcesa1.sources.s1.type = org.apache.flume.source.kafka.KafkaSourcea1.sources.s1.channels = c1a1.sources.s1.batchSize = 5000a1.sources.s1.batchDurationMillis = 2000a1.sources.s1.kafka.bootstrap.servers = localhost:9092a1.sources.s1.kafka.topics = mytopica1.sources.s1.kafka.consumer.group.id = kafka2hdfs## define channelsa1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100##sinksa1.channels = c1a1.sinks = k1a1.sinks.k1.type = hdfsa1.sinks.k1.channel = c1a1.sinks.k1.hdfs.path = hdfs://Luffy.OnePiece.com:8020/flume/events/%y-%m-%d/%H%M/a1.sinks.k1.hdfs.filePrefix = flumeDataa1.sinks.k1.hdfs.fileSuffix = .logsinks.k1.hdfs.round = truea1.sinks.k1.hdfs.roundValue = 10a1.sinks.k1.hdfs.roundUnit = minutea1.sinks.k1.hdfs.useLocalTimeStamp = truea1.sinks.k1.hdfs.rollInterval = 600a1.sinks.k1.hdfs.rollSize = 268435456a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k1.hdfs.batchSize = 1000a1.sinks.k1.hdfs.fileType = DataStreama1.sinks.k1.hdfs.writeFormat = Texta1.sinks.k1.hdfs.idleTimeout = 60a1.sinks.k1.hdfs.threadsPoolSize= 1a1.sinks.k1.hdfs.callTimeout= 30000启动kafkazkServer.sh startnohup /opt/modules/kafka_2.11-0.11.0.1/bin/kafka-server-start.sh /opt/modules/kafka_2.11-0.11.0.1/config/server.properties >/dev/null 2>&1 &flume启动bin/flume-ng agent --conf conf --name a1 --conf-file conf/kafka2hdfs.properties -Dflume.root.logger=INFO,console生产者启动bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mytopic
注意事项:
1,写入hdfs需要进行如下操作,将core-site.xml和hdfs-site.xml复制到flume的conf目录下。
2,/etc/profile要配置好,hadoop信息,使得flume找到hadoop依赖信息。
export JAVA_HOME=/opt/modules/jdk1.8.0_121export HADOOP_HOME=/opt/modules/hadoop-2.7.4/export HADOOP_PREFIX=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOMEexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
推荐阅读:
1,
2,
3,
4,
更多文章,敬请期待
以上是关于重磅:Flume1-7结合kafka讲解的主要内容,如果未能解决你的问题,请参考以下文章