测试方法Flume+HDFS+Spark日志分析入门篇
Posted 非功能之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测试方法Flume+HDFS+Spark日志分析入门篇相关的知识,希望对你有一定的参考价值。
IT基础建设的监控离不开日志分析,当系统由于某些BUG挂掉时,通过命令查询错误日志排除,也因此日志分析是经常做的事情。假若系统记录的日志很多,仍采取这种方式,很明显效率不高,那么大数据下的日志分析技术应运而生,到底是怎样的流程呢,今天小编就来介绍Flume+HDFS+Spark架构下的日志分析。
Flume+HDFS+Spark架构
应用日志的处理流程是这样的:先由应用系统产生日志,由其日志框架定义进行处理,如log4j或logback,将日志打印到控制台或输出到指定的文件中,当我们需要对日志文件进行查看时,可以使用vim等工具。
Flume+HDFS+Spark架构的日志处理流程是这样的:将日志采集组件Flume作为Agent部署在Application Server上,用于收集本地日志文件,并将日志转存到HDFS数据平台中,然后由Spark实现日志分析。
由于用到HDFS数据平台,因此需要安装Hadoop,关于Flume、Hadoop、Spark等的原理和特性,及安装不再详细叙述,本文只简述如何使用Flume+HDFS+Spark构建一套日志采集系统并进行日志分析。注:本文的运行环境为windows 7。
Flume安装完毕后,需要修改相关配置文件,使之能够与完成日志采集。
将log4j日志输出到Flume的日志文件中,配置如下:
log4j.appender.flume= org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname= localhost
log4j.appender.flume.Port= 41414
log4j.appender.flume.UnsafeMode= true
二、将flume采集的日志输出到HDFS数据平台,需要修改flume.conf中的sink配置,如下:
agent1.sinks. type=hdfs
agent1.sinks. channel=channel1
agent1.sinks. hdfs.path=hdfs://localhost:9000/user/
agent1.sinks. hdfs.fileType=DataStream
agent1.sinks.hdfs.writeFormat=Text
agent1.sinks.hdfs.rollInterval=0
agent1.sinks.hdfs.rollSize=1024000
agent1.sinks.hdfs.rollCount=0
agent1.sinks.hdfs.idleTimeout=60
将sink的type设置为hdfs,然后指定输出路径,这里指定输入到HDFS的/user目录,将fileType配置为DataStream, writeFormat配置为Text,可直接打开生成的文件进行查看。roll开头的参数用来控制滚动日志输出,rollsize按文件大小滚动rollSize=1024000,即1M大小滚动生成一个新的文件接收新的EVENTS。idleTimeout设置为60秒,即60秒后如果文件没有被写入数据,则会关闭正在使用的.tmp文件,重命名去掉.tmp,一旦有新的events到达,则会新创建一个新的.tmp文件进行接收。
运行Application,即可在hdfs://localhost:9000/user目录下看到应用输出的日志信息。
Spark日志分析
Apache Spark是一个快速成长的开源集群计算系统,其生态系统构建在Spark内核引擎之上,使得Spark具备快速的内存计算能力,效率更高、运行速度更快。随着框架的日趋丰富,Spark具有越来越强大的功能和极好的易用性,使之能够进行高级数据分析,Spark生态系统如下:
Streaming具备实时流数据的处理能力,Spark SQL语言查询结构化数据,DataFrame将数据保存为行的集合,可快速查询、绘制和过滤数据,MLib是Spark的机器学习框架,GraphX是图计算框架,提供结构化数据的图计算能力。Spark支持Scala、Java、Python和R等四种语言的API编程。
Spark提供了交互式的shell命令行,目前支持Scala和Python两种,本文以Scala进行操作。
一、启动Spark shell
Scala 是一门现代的多范式编程语言,志在以简练、优雅及类型安全的方式来表达常用编程模式,它平滑地集成了面向对象和函数语言的特性,运行于Java平台(JVM,Java虚拟机),并兼容现有的Java 程序,是Spark 的主要编程语言,优点是开发效率更高,代码更精简,并且可以通过Spark Shell进行交互式实时查询,方便排查问题。
bin/spark-shell启动Sparkshell:
成功后,如下图所示,出现”scala>”提示符:
那么现在就可以开始日志分析了。
基础操作
Spark的主要抽象是分布式的元素集合(distributedcollection of items),称为RDD(ResilientDistributed Dataset,弹性分布式数据集),它可被分发到集群各个节点上,进行并行操作。RDD可以通过HDFS或任何支持Hadoop的文件系统创建,或者从其他RDD转化而来。
通过HDFS创建一个RDD,代码如下:
scala> val textFile =sc.textFile("hdfs://localhost:9000/user/file.txt");//val 是scala语法中声明常量的方式,sc是在进入sparkshell 时创建的sparkcontent即spark上下文,此编码是将hdfs节点上的文件读取到内存中;Sparkshell读取 HDFS 中的文件,通过 "hdfs://" 前缀指定。

注意:
1、如果使用本地文件系统路径,须保证所有的节点有相同的路径,或者使用共享路径。
2、textFile还支持加载目录,即加载目录下所有文件,支持压缩文件、通配符等,textFile(hdfs://localhost:9000/user/),textFile(hdfs://localhost:9000/user/file.gz),textFile(hdfs://localhost:9000/user/*.txt)。
3、textFile可以控制文件分区的数量,即Spark为每个文件块创建一个分区,分区大小默认值是128M。
RDD支持两种类型的操作,actions:在数据集上运行计算后返回值;transformations:转换,从现有数据集创建一个新的数据集。
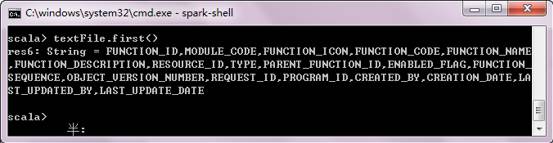
count()和first()属于actions,分别为统计行数和显示第一个Item。
scala> textFile.count()//统计文本文件的总行数

scala> textFile.first()//first读取文件的第一个Item,对于文本文件就是第一行内容
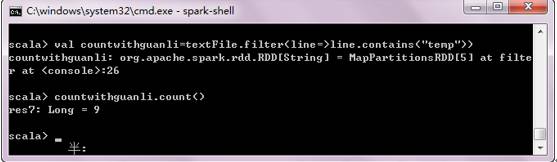
Filter属于transformation,通过filter筛选出包括temp关键字的RDD,然后进行计数。当得到一个经过过滤操作后的RDD,可对其进行action操作使相应的数据流向应用程序。
scala>valcountwithguanli=textFile.filter(line=>line.contains(“temp”))
scala>countwithguanli.count()
 当然也可以使用action和transformation链式操作的方式,使代码更为简洁:
当然也可以使用action和transformation链式操作的方式,使代码更为简洁:
textFile.filter(line=>line.contains("tmp")).count()//统计包含 tmp 的行数
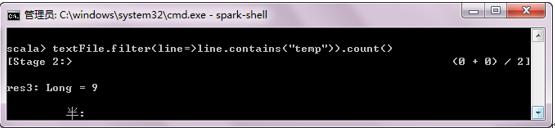
RDD 的 actions 和transformations 可以用在更复杂的计算中,例如通过map和reduce可以找到包含单词最多的行。首先使用map方法将每行映射成一个数,创建一个新的RDD,然后使用reduce方法找出包含单词量最多的行。map()、reduce() 中的参数是Scala的函数字面量(functionliterals,也称为闭包closures)。
textFile.map(line=> line.split(" ").size).reduce((a, b) => if (a > b) a elseb)//返回包含单词最多的行
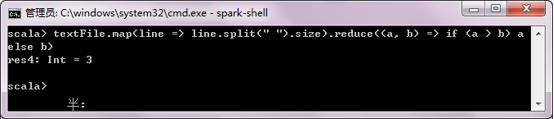
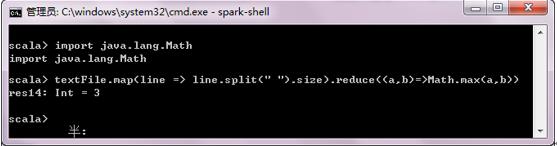
也可以引入其他Java包,如Math.max() 函数,使上述代码更容易理解,此时Math可以作为map和reduce的字面量参数。
scala>import java.lang.Math//引入java包
scala textFile.map(line => line.split(" ").size).reduce((a,b)=>Math.mad(a,b))//返回包含单词最多的行
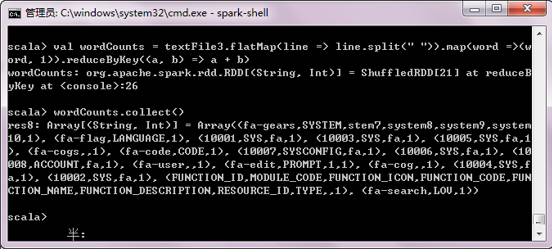
使用Hadoop MapReduce数据流模式,同样可以实现以上功能。
scala>valwordCounts = textFile.flatMap(line => line.split(" ")).map(word=> (word, 1)).reduceByKey((a, b) => a + b) // 实现单词统计
scala>wordCounts.collect()// 输出单词统计结果
从上面可以看出,输入内容是无序的,Spark支持排序,通过sortByKey方法实现。经过排序,输出数据发生了变化。
scala>wordCounts.sortByKey()//排序
scala>sort.collect()//显示文本内容
Spark 支持在集群范围内将数据集缓存至每一个节点的内存中,可避免数据传输,当数据需要重复访问时此特征优势非常明显。调用cache(),就可以将数据集进行缓存。
scala>countwihtguanli.cache()
小结
以上是小编搭建的大数据日志分析架构,以及使用Spart shell提供的scala交互式编程进行日志分析的入门操作。使用RDD,既可以进行数据转换,也可以进行action操作,这意味着transformation可以改变数据格式、进行数据查询或数据过滤操作,action则可以触发数据改变、抽取数据、收集数据进行计算。
若要分析应用日志,需了解具体的应用需求,根据需求获取或过滤数据集,得到想要的结果,掌握RDD的基本操作后,可以通过更多的实例来熟练Spark,更多内容请参考Spark官网文档。
以上是关于测试方法Flume+HDFS+Spark日志分析入门篇的主要内容,如果未能解决你的问题,请参考以下文章