Flume系统介绍及安装配置
Posted 大数据与数据科学家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume系统介绍及安装配置相关的知识,希望对你有一定的参考价值。
一、系统介绍
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制,比如文本、HDFS、Hbase等)的能力。
1. 系统功能
数据采集:
Flume最早是Cloudera提供的日志收集系统,目前是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
数据处理:
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
2. 工作方式
Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据现在由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
3. FLUME架构
Flume的逻辑结构如下图所示。
Flume采用了分层架构:分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。Flume使用两个组件:Master和Node,Node根据在Master shell或web中动态配置,决定其是作为Agent还是Collector。
(1) agent
agent的作用是将数据源的数据发送给collector。Flume自带了很多直接可用的数据源(source),如:
text(“filename”):将文件filename作为数据源,按行发送;
tail(“filename”):探测filename新产生的数据,按行发送出去;
fsyslogTcp(5140):监听TCP的5140端口,并且接收到的数据发送出去;
tailDir("dirname"[, fileregex=".*"[, startFromEnd=false[, recurseDepth=0]]]):监听目录中的文件末尾,使用正则去选定需要监听的文件(不包含目录),recurseDepth为递归监听其下子目录的深度;
console[("format")] :直接将将数据显示在consolr上;
text(“txtfile”):将数据写到文件txtfile中;
dfs(“dfsfile”):将数据写到HDFS上的dfsfile文件中;
syslogTcp(“host”,port):将数据通过TCP传递给host节点;
agentSink[("machine"[,port])]:等价于agentE2ESink,如果省略,machine参数,默认使用flume.collector.event.host与flume.collector.event.port作为默认collector;
agentDFOSink[("machine" [,port])]:本地热备agent,agent发现collector节点故障后,不断检查collector的存活状态以便重新发送event,在此间产生的数据将缓存到本地磁盘中;
agentBESink[("machine"[,port])]:不负责的agent,如果collector故障,将不做任何处理,它发送的数据也将被直接丢弃;
agentE2EChain:指定多个collector提高可用性。 当向主collector发送event失效后,转向第二个collector发送,当所有的collector失败后,它会非常执着的再来一遍。
(2) collector
collector的作用是将多个agent的数据汇总后,加载到storage中。它的source和sink与agent类似。数据源(source),如:
collectorSource[(port)]:Collector source,监听端口汇聚数据;
autoCollectorSource:通过master协调物理节点自动汇聚数据;
logicalSource:逻辑source,由master分配端口并监听rpcSink。
sink,如:
collectorSink( "fsdir","fsfileprefix",rollmillis):collectorSink,数据通过collector汇聚之后发送到hdfs, fsdir 是hdfs目录,fsfileprefix为文件前缀码;
customdfs("hdfspath"[, "format"]):自定义格式dfs。
(3) storage
storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase,分布式存储等。
(4) Master
Master是管理协调agent和collector的配置等信息,是flume集群的控制器。
在Flume中,最重要的抽象是data flow(数据流),data flow描述了数据从产生,传输、处理并最终写入目标的一条路径。
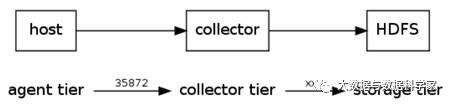
对于agent数据流配置就是从哪得到数据,把数据发送到哪个collector。对于collector是接收agent发过来的数据,把数据发送到指定的目标机器上。
二、系统安装
1. 下载安装包
官网下载:
apache-flume-1.5.0-bin.tar.gz
apache-flume-1.5.0-src.tar.gz
2. 分别解压
解压apache-flume-1.5.0-bin.tar.gz,解压到usr文件夹下面

解压apache-flume-1.5.0-src.tar.gz,解压到usr文件夹下面

src里面文件内容,覆盖解压后bin文件里面的内容

重命名

3. 配置环境变量

4. 建立配置文件
这里面的配置文件还是比较特别的,不同于以往我们安装的软件,我们这里可以自己建立配置文件。
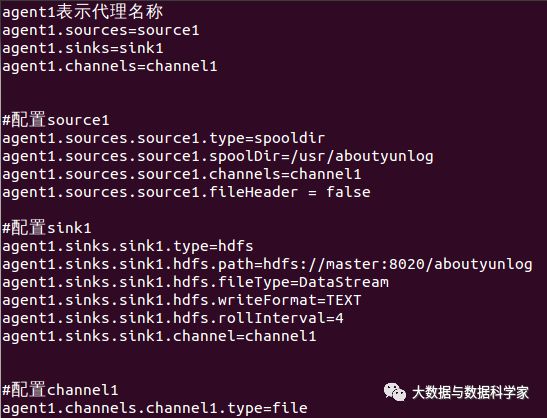
首先我们建立一个 example文件,然后把下面内容,粘帖到里面就可以了,注意不要有乱码,有乱码的话,可以直接创建一个文件,然后上传。方法也有很多,能解决就好。
agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/aboutyunlog
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:8020/aboutyunlog
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=4
agent1.sinks.sink1.channel=channel1
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/aboutyun_tmp123
agent1.channels.channel1.dataDirs=/usr/aboutyun_tmp
5. 启动flume
运行命令:
flume-ng agent -n agent1 -c conf -f usr/flume/conf/example -Dflume.root.logger=DEBUG,console
我们启动flume之后会看到下面信息,并且信息不停的重复。这个其实是在空文件的时候,监控的信息输出。
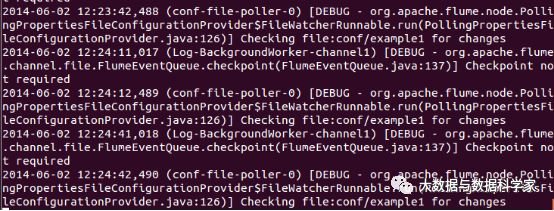
注意:这个不要关闭,我们另外开启一个shell,在监控文件夹中放入要上传的文件。
比如我们在监控文件夹下,创建一个test1文件,内容如下:

这时候flume监控shell,会有相应的变化。
上传成功之后,我们去hdfs上,查看上传文件:

这样我们就做到了flume上传到hadoop2.2。
三、应用的设计与实现
1.应用介绍
Avro可以发送一个给定的文件给Flume,Avro 源使用AVRO RPC机制。
2.应用实现与源代码
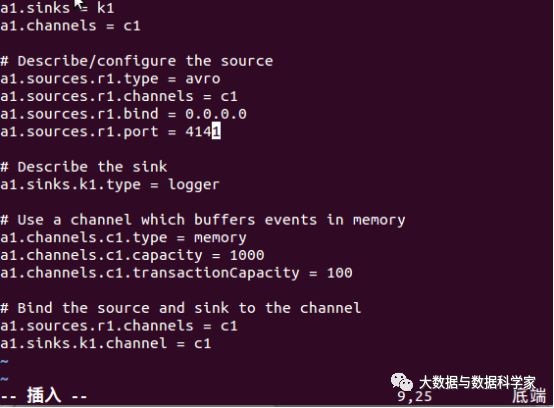
创建agent配置文件:

并输入以下内容:
四、实验设计与分析
1.实验过程
(1).启动flume agent a1

(2).创建指定文件

(3).使用avro-client发送文件

2.实验结果
可以观察到,m1的控制台,可以看到以下信息,注意最后一行,是”hello world”。
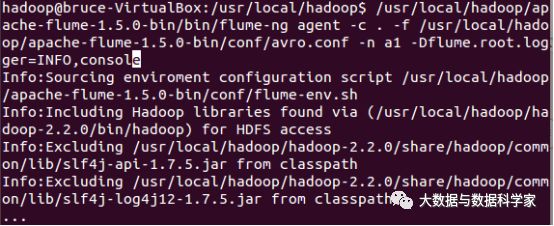
3.实验结论
可以得到Flume Avro能够在两台机器间实现数据传输的结论。
主编:王宏志
特邀副主编: 朱劼
副主编: 丁小欧
责任编辑: 齐志鑫,宋扬
编辑: 陶颖安
长按下图并点击 “识别图中二维码”,即可关注大数据与数据科学家微信公共号
以上是关于Flume系统介绍及安装配置的主要内容,如果未能解决你的问题,请参考以下文章