Flume-NG技术原理
Posted Hadoop大数据之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume-NG技术原理相关的知识,希望对你有一定的参考价值。
Flume源自Cloudera公司,原名Flume-OG(original generation),用于日志收集。现已加入到Apache下,改名为Flume-NG(next generation)。Flume是一个分布式、可靠、高可用的服务,它能够将不同数据源的海量日志数据进行高效收集、汇聚、移动,最后存储到一个中心化数据存储系统中,它是一个轻量级的工具,简单、灵活、容易部署,适应各种方式日志收集并支持failover和负载均衡。官方网站:http://flume.apache.org
一、Flume核心组件
| 术语 | 说明 |
| Event | 一个数据单元,由消息头(Header)和消息体(body)组成 |
| Agent | 独立的flume进程,包含Source、Channel、Sink |
| Source | 数据源收集组件 |
| Channel | 数据管道,接收来自Source组件传递的Event |
| Sink | Channel管道数据Event,往下个agent传递 |
| Interceptor | 拦截器 |
1)Agent结构
agent是Flume的核心,包含三个核心组件,分别是Source、Channel、Sink,通过这些组件将Event从一个地方流向下一个地方,如:
单个agent结构
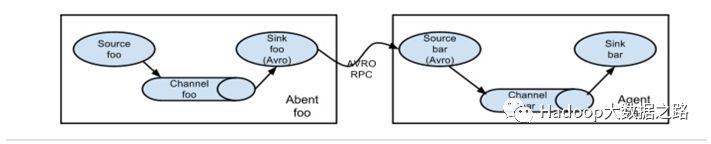
数据由一个agent往下一个agent传递
多个agent收集数据往一个agent传递
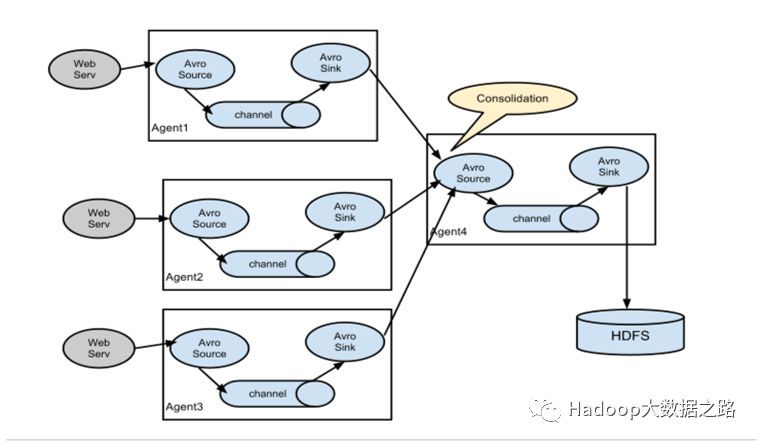
agent的一个Source往多个Sink并将数据存储到不同的存储器上
生产应用部署
2)Source
Source是数据收集端,负责捕捉数据并将数据封装到事件(Event)里,最后将数据推送到Channel中,flume提供了很多内置的Source:
| Source类型 | 说明 |
| Exec Source | 执行shell命令方式,如tail -F |
| Spool DirectorySource | 监控目录新文件数据 |
| Thrift Source | 支持Thrift协议 |
| Svslog Source | 读取svslog数据,支持UDP和TCP两种协议 |
| Avro Source | 支持AVRO协议 |
| HTTP Source | 基于HTTP POST或GET数据源 |
| Netcat Source | 监控流经端口的 |
| JMS Source | 从jms系统中读取数据 |
| ...... | ...... |
3)Channel
Channel是连接Source和Sink的组件,可以当做一个缓冲区或数据队列,它将数据存储在内存或磁盘上,直到Sink处理完该事件,比较常用的Channel,MemoryChannel和FileChannel:
| Channel类型 | 说明 |
| Memory Channel | 将Event数据存储在内存 |
| File Channel | 将Event数据存储在磁盘中 |
| JDBC Channel | 将数据持久到数据库中 |
| Kafka Channel | 将数据往Kafka存储 |
| Spillable Memory Channel | 将数据持久化到内存和磁盘,当内存队列满了后将数据持久化到磁盘 |
| Custome Channel | 自定义channel |
4)Sink
Sink从Channel中取出事件,将数据发送到别处,可以存储到本地文件、hdfs、kafka、hbase等,也可以是其它Agent的Source。
| HDFS Sink | 数据写入hdfs |
| HBase Sink | 数据写入hbase数据库 |
| Avro Sink | 将数据转换为Avro Event,发送到配置的RPC端口上 |
| Thrift Sink | 将数据转换为Thrift Event,发送到配置的RPC端口上 |
| Logger Sink | 将数据写入到日志文件中 |
| ElasticSearch Sink | 将数据发送到搜索服务器集群 |
| Custom Sink | 自定义Sink |
| ...... | ...... |
5)拦截器
Flume提供了拦截器,当Source指定一个拦截器后,拦截器会得到Event数据,可以在拦截器中过滤提取数据,一个Source可以指定多个拦截器成为拦截器chain。
| 拦截器类型 | 说明 |
| TimestampInterceptor | 时间戳拦截器 |
| HostInterceptor | 主机名拦截器 |
| StaticInterceptor | 静态拦截器 |
| RegexFilteringInterceptor | 正则过滤拦截器 |
| RegexExtractorInterceptor | 正则提取拦截器 |
| UUIDInterceptor | UUID拦截器 |
| MorphlineInterceptor | ... |
| CustomInterceptor | 自定义拦截器 |
二、负载均衡与故障转移
Sink groups允许组织多个sink到一个实体上,Sink processors能够提供在组内所有sink之间实现负载均衡的能力,而且在失败的情况下能够进行故障转移从一个sink到另外一个sink。
| Property Name | Default | Description |
| sinks | - | Space-separated list of sinks that are participating in the group |
| processor.type | default | The component type name, needs to default、failover or load balance |
1)负载均衡(load balance)
Load balancing sink processor提供了多个sink负载均衡的能力,它维护了一个active sinks列表,该列表中的负载均衡是分布式的。默认实现了round_robin(轮询调度)或者random(随机)的选择机制,默认配置是:round_robin(轮询调度),也可以通过继承AbstractSinkSelector类来实现自定义的选择机制。当被调用时,选择器根据配置文件的选择机制挑选下一个sink,并且调用该sink,如果所选的sink传递Event失败,则通过选择机制挑选下一个可用的sink,以此类推。
| Property Name | Default | Description |
| processor.sinks | - | Space-separated list of sinks that are participating in the group |
| processor.type | default | The component type name, needs to be load_balance |
| processor.selector | round_robin(轮询调度) | Selection mechanism. Must be either round_robin, random or FQCN of custom class that inherits from AbstractSinkSelector |
processor.selector.maxTimeOut |
30000 | Used by backoff selectors to limit exponential backoff (in milliseconds) |
2)故障转移
Failover Sink Processor维护了一个sink的优先级列表,具有故障转移的功能。配置参数如下:
| Property Name | Default | Description |
| sinks | - | Space-separated list of sinks that are participating in the group |
| processor.type | default | The component type name, needs to be failover |
| processor.priority.<sinkName> | - | Priority value. <sinkName> must be one of the sink instances associated with the current sink group A higher priority value Sink gets activated earlier. A larger absolute value indicates higher priority |
| processor.maxpenalty | 30000 | The maximum backoff period for the failed Sink (in millis) |
以上是关于Flume-NG技术原理的主要内容,如果未能解决你的问题,请参考以下文章