学员在学习Flume过程中碰到的问题,你遇见过么?
Posted ITSTAR全球VIP教学服务中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学员在学习Flume过程中碰到的问题,你遇见过么?相关的知识,希望对你有一定的参考价值。
老师整理了全部解析过程,供大家参考学习!坑已经已经提示出来了,每天学习一点,终能学会改bug(坑),让自己学会如何修改bug!
Flume案例简介:
Agent-1用来监控hive的日志,配置多Channel、Sink。第一个sink的数据落地到Agent-2的source然后通过sink将数据落地到本地;第二个sink的数据落地到Agent-3的source然后通过sink将数据落地到hdfs分布式文件系统。
环境需求:
Centos7+JDK1.8+Hadoop2.7.3+Flume1.7.0
实现:
创建flume-1.conf,用于监控hive.log文件的变动,同时产生两个channel和两个sink分别落地数据到flume-2和flume-3:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
\# 将数据流复制给多个channel
a1.sources.r1.selector.type = replicating
\# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
\# Describe the sink-1 注意:hostname写自己的机器的域名或者ip
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop104
a1.sinks.k1.port = 4141
\# Describe the sink-2
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop104
a1.sinks.k2.port = 4142
\# Describe the channe-l
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
\# Describe the channe-2
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
\# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
创建flume-2.conf,用于接收flume-1的event,同时产生1个channel和1个sink,将数据落地到本地目录:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
\# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop104
a2.sources.r1.port = 4141
\# Describe the sink
a2.sinks.k1.type = file_roll
a2.sinks.k1.sink.directory = /opt/flume3
\# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
\# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
警告:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
创建flume-3.conf,用于接收flume-1的event,同时产生1个channel和1个sink,将数据落地到hdfs:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
\# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop104
a3.sources.r1.port = 4142
\# Describe the sink
a3.sinks.k1.type = hdfs
a3.sinks.k1.hdfs.path = hdfs://hadoop104:9000/flume2/%Y%m%d/%H
\#上传文件的前缀
a3.sinks.k1.hdfs.filePrefix = flume2-
\#是否按照时间滚动文件夹
a3.sinks.k1.hdfs.round = true
\#多少时间单位创建一个新的目录
a3.sinks.k1.hdfs.roundValue = 1
\#重新定义时间单位
a3.sinks.k1.hdfs.roundUnit = hour
\#是否使用本地时间戳
a3.sinks.k1.hdfs.useLocalTimeStamp = true
\#积攒多少个Event才flush到HDFS一次
a3.sinks.k1.hdfs.batchSize = 100
\#设置文件类型,可支持压缩
a3.sinks.k1.hdfs.fileType = DataStream
\#多久生成一个新的文件
a3.sinks.k1.hdfs.rollInterval = 600
\#设置每个文件的滚动大小大概是128M
a3.sinks.k1.hdfs.rollSize = 134217700
\#文件的滚动与Event数量无关
a3.sinks.k1.hdfs.rollCount = 0
\#最小副本数
a3.sinks.k1.hdfs.minBlockReplicas = 1
\# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
\# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
启动:分别启动Flume-1、Flume-2、Flume-3
bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/flume-1.conf
bin/flume-ng agent --conf conf/ --name a2 --conf-file conf/flume-2.conf
bin/flume-ng agent --conf conf/ --name a3 --conf-file conf/flume-3.conf
同学们在学习过程中遇到的问题: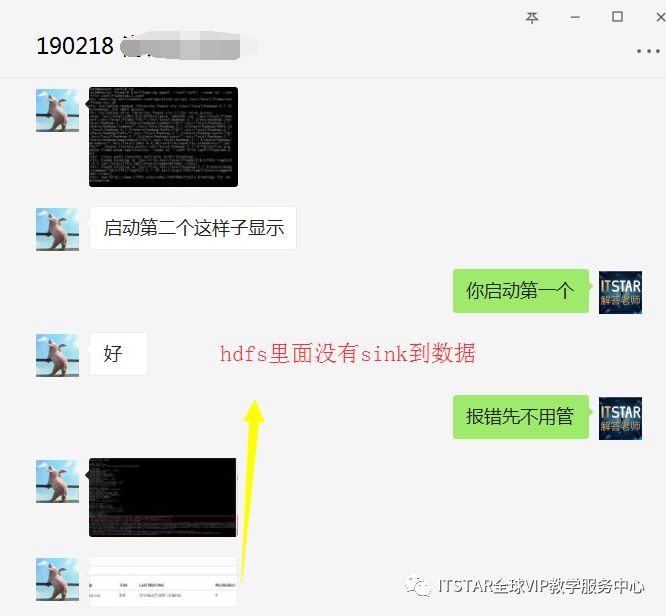
问题图片:
如上图片是VIP学员在学习过程中启动了Flume,并且Flume在悬停运行状态,没有报错。但是在监控的过程成中检查hdfs系统里面是没有收集到数据。如下图:
出现这个错误的原因是在配置的过程中忽略了配置Flume的环境变量。
vi ~/.bash_profile 配置环境变量
export FLUME_HOME=/usr/local/flume
export PATH=$FLUME_HOME/bin:$PATH
然后重新启动Fume,就可以监控到数据并且落地到hdfs和本地的目录里。
二、
在搭建的过程中一定要记住配置文件里面的“文件目录”、“Linux的域名”、“启动命令--conf-file 后面必须是自己的配置文件路径”。
vip解答服务的流程:
报名vip学习之后,通过售后老师加上解答微信或者QQ。
学习过程中遇到问题,在解答微信或者解答QQ进行文字、语音、图片等形式发来你的问题。
解答时间:每天的中午1:30到晚上的11:00,其余时间有问题的同学留言,看到会直接回复的。
解答方式:文字、语音、图片、远程操作你的电脑等方式。
——付出不亚于任何人的努力——
以上是关于学员在学习Flume过程中碰到的问题,你遇见过么?的主要内容,如果未能解决你的问题,请参考以下文章