浏览器Lexer与XSS-HTML编码
Posted anquanw6
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器Lexer与XSS-HTML编码相关的知识,希望对你有一定的参考价值。
0×00 简介
0×01 解码过程总述
0×02 浏览器中的词法分析
0×03 html编码与HTML解析
0×04 常见误区
0×05 浏览器有趣的容错行为
0×06 结语
0×00 简介
编码问题一直是一个痛点,在wooyun有一篇XSS编码的文章,讲到一些痛点,既然准备再次完成一篇对XSS中的编码讲解,同时也对得起这个文章的名字,本文就比较系统的讲一下浏览器Lexer中HTML编码处理的问题与XSS的html编码原理剖析。
0×01 解码过程总述
在开始XSS之前,我们如果不清楚编码解码的过程,将会对XSS造成非常大的困难,不懂得编码而乱插一气,如果你是自动化工具还好但是如果你是手动XSS,那么你可就遭殃了,运气好做出来,运气不好就怎么样也解决不了编码问题了。
了解编码过程首先从浏览器解析来讲吧
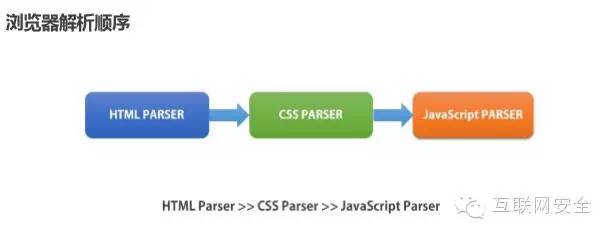
对浏览器解析HTML有过了解的同学,肯定是清楚浏览的的这些工具原理,一般来讲浏览器通过Lexer-Parser来解析生成Dom树然后再对CSS元素进行渲染,最后执行javascript(浏览器脚本),但是为什么要讲这一部分呢?原因就是这和解码的顺序是有关系的!
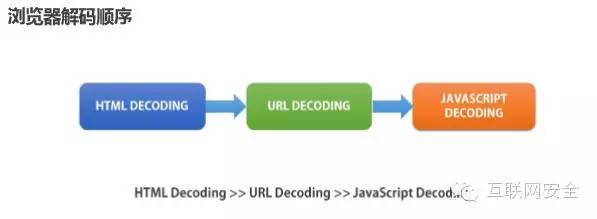
举一个简单的例子吧:在HTML(非XHTML)环境下如果你的xss输出点在<script>标签内,你采用了HTML实体编码的形式,怎么可能触发XSS漏洞呢?如果你不懂这个问题,也许你会做很多无用功。
0×02 浏览器中的词法分析
熟悉编译原理的读者可以自由选择快速略过第一第二段或者短暂复习一下。
关于一个计算机工作人员是否需要学习编译原理这个话题,我相信大家各持己见。但是我相信如果你是要做一个优秀的程序员或者是IT工作者,编译原理不一定要精通,但是至少应该有所了解,限于篇幅的原因,我并不打算在这里讲太多的编译原理的只是简单提及一下让大家知道编译原理到底是干什么的,在浏览器中是怎么被应用的。
Parser-Lexer Combination(解析器-词法分析器)
这个结构负责对html文档进行解析,解析的过程分为两个过程:词法分析和语法分析
本部分,主要讲词法分析部分
词法分析就是将输入的句子(语句,内容)分解为有顺序的单词和符号:具体例子就是如果输入1+2-3,那么经过词法分析,就应该按顺序得到五个token:分别是1(int),+(option),2(int),-(option),3(int)。然后得到的结果交给语法分析进行上下文无关语法判别。
如果有兴趣了解如何实现词法分析,可以参考编译原理及实践这本书。
那么在浏览器中,词法分析的特性还是值得注意的,例如,它会自动跳过HTML中的空格和换行或者制表符,这样也就是有些条件下仅仅是多个空格或者换行符制表符就能起到过waf,的原理了,(但是现在这种bypass方法已经很out了)。除此之外呢,在词法分析中,也许还会忽略注释部分,那么大家是不是又有一些想法了呢?那么,我们结合以前XSS的经验,笔者结合符号算法的简单叙述,大家可以理解检测一下自己的猜测是不是正确。
众所周知,我们的浏览器解析html时,是把
<img src = 1/>
这个标签解析成
<
img
src
=
1
/
>
这六个符号(token)的。
那么仅仅就是这么简单么?答案当然是否定的。
解析过程简单例子:
1. 在解析<这个符号以前,状态是Data State
2. 然后解析到<的时候,解析状态变为Tag open state,然后开始搜寻标签名,(在搜寻标签名的时候,我们要思考一个问题,<和标签名img并不是同一个token,他们显然是分别进行解析的,那么有没有可能忽略掉<和img之间的空格或者换行什么的?这个问题,我相信很好找到答案。)
3. 找到标签名,状态变为Tag name state,这个状态就表示已经识别了标签名,
4. 然后知道读取到最近的一个>时,结束tag name state的状态,重新进入Data State。
如果嵌套有标签的话重复上述解析步骤,关于</body>的部分,大同小异,只不过/符号会创建一个闭合标签的标识,来表示一个标签的闭合。
但是!我要说的是但是!这个解析过程是相当松散的。因为HTML的历史原因,导致HTML的模式千奇百怪,错误频繁出现,开发者程序员的水平参差不齐,HTML的不规范的特性。这个解析过程注定是相当复杂的。举个最简单的例子。
<img src=x onerror=alert(1)>
你觉得这个元素可以被识别么?能弹窗么?既然这么问,那么答案肯定是肯定的。
<img src=http://pic.com/pic.jpg>
如果http://pic.com/pic.jpg这个图片真实存在,那么,这个没有引号的标签可以被识别么?
除此之外,还有很多很多的神奇的trick值得去探索。
0×03 HTML编码与HTML解析
HTML实体编码的出现,解决了一个问题,例如<和>这两个符号在HTML文档中出现是非常不安全的,因为这标志着标签的开始和结束,为了安全使用这些保留字符。开发人员使用了一套叫实体编码的编码策略,这类编码以&开头,以分号;结尾。
但是结合0×02的知识我们可以猜测,以“;”为分割符,在实际的处理中,由于浏览器解析器高度的容错性,所有的可以成为分割符的符号放在结尾代替;当然有可能可以正确分隔,那么这也就是著名的一个trick:HTML实体编码最后的;可以省略,这就是原理所在。好,我们,接着讲HTML实体编码的一些有趣的东西。
在HTML编码,中大家都知道一个应该写为“&#数字”或者“&#x十六进制”,但是不为人知的可能就是后面的数字可以写成Unicode,曾经有点蛋疼的时候,笔者把所有的unicode字符用&#编码的形式打了出来,看了一下有没有什么有趣的符号。在《web之困》中,作者就举例了一个有趣的符号:
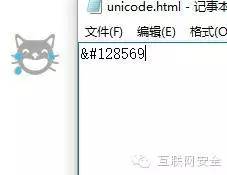
那么读者要问了,这个东西讲的有什么意思呢?那么接下来就要说一些很明确的,也是很多有误区的地方:HTML在哪里可以解析?整个HTML的文档下都可以解析么?
得明确地讲:HTML编码要在Data state(标签外部和标签的text段)和标签内的属性值的位置解析,但是直接注意的是在特殊模式(这个问题将在下一段中解释)下,即使是在Data state下,HTML编码也照样不会被解析。在0×02中,我们知道解析到HTML解析过程中,在遇到一对<和>的解析过程中,都是Tagname/open/close state,在这三个状态中,HTML编码也是不会被解码的,也就意味着解析到标签属性的值的时候自动切换进了Data State,这些都是符合我们正确认知的。
接下来我们来举例(以Firefox为例):
看到下面的标签,有读者就要问为什么没有反斜杠?很简单啊,浏览器识别一个标签我们在0×02部分讲到的,只需要<作为标签的开始,并且>作为标签的结束,所以不一定需要有</tagname>,在HTML解析条件下也可以识别标签
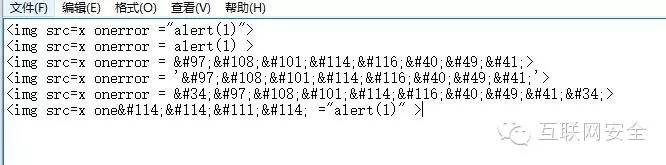
我们在记事本中输入这六个标签,读者可以来猜一下哪些可以弹窗,哪些不能?
很显然第一第二是完全可以的。
第三个没有明显写明边界,实际上这个和第二个的边界处理是一样的,默认了边界,(我们可以姑且认为=和>是独立的token,那么也就是说即使不用单引号或者双引号或者反引号照样可以起到边界的作用,事实上却是如此)
第四个人为加上了边界,所以当然是可以的,
第五个"就是引号,这里的引号在数据区,也就相当于onerror=”’ alert(1)’”
第六个,我们知道在非Data state段是不会HTML编码解码的,所以第六个破坏了属性的结构。
特殊模式:<style><script><textarea><xmp>这四个标签的text段按理说也是Data state但是没办法进行HTML编码的解析,原因就是他们处于特殊模式,在这个模式中,相当于是启动了别的解析器,也就是为了处理别的代码或者特定文本,关闭了HTML编码的解析。
接下来我们尝试一下HTML到底能不能在<script>中解析:
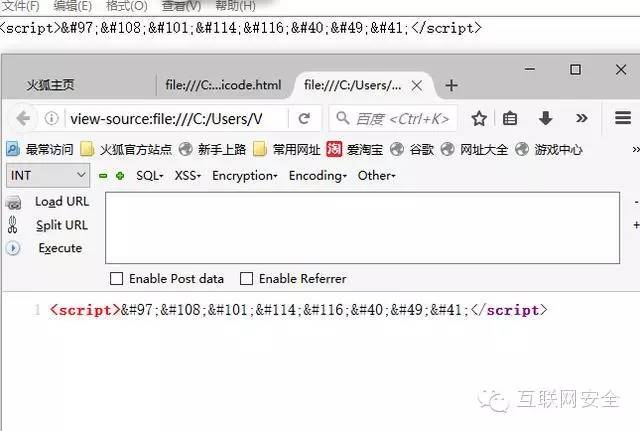
大家看到了,源码是这样的,显然是没有办法解析HTML编码的。
作为对比我们再看一下下面的情况
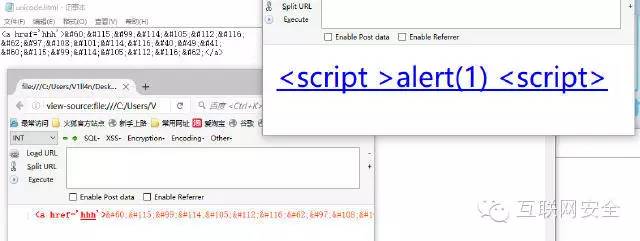
这样我们就发现了普通条件下的在标签的text段的确是发生了HTML编码的解析。
0×04 常见误区
我既然写在普通的Data State段,而且提示也提示出了<script>alert(1)<script>但是为什么不会弹框呢?可能有读者还是会有这个问题。
这里需要提醒大家的是:HTML编码(HTML实体编码)的出现,是为了防止保留符号与显示字符的冲突。
那么我们解析原因就很简单了:也就是说<script>alert(1)</script>这个字符串实际上只为了显示,而不执行,js代码的执行是放在HTML编码之后,而且必须位于可以执行的地方对么?大家想一下,如果放在<a>标签内,没人指示执行JS代码,而且显示<script>alert(1)</script>这个时候HTML解析器只是把它显示出来并不会执行(如果读者这里有点懵逼,那么请返回看0×01部分)。
然后为什么标签属性值的部分是可以执行的呢?很简单,因为onxxxx的函数都是时间处理函数,的确属于HTML标准的属性值,但是大家可以理解为这是JS特定函数或者特定功能的执行入口,那么在解析的时候,首先把HTML标签属性的值当作数据解析以后(解析HTML代码),然后交给JS引擎,然后执行。这样就可以得到JS的执行结果。
0×05 浏览器有趣的容错行为
我们接下来还是以一个标签为例。来总结一下浏览器是有多么强大的容错性。

对于这样一个标签,我们多多少少看起来还有点别扭。但是经过0×02的讲解,我相信大家脑子里应该是已经把它分解成了很多个token,而且,可以很轻易的分辨出这个tag是完全可以正常工作的。首先我们从开头一点一点来解释:
1. 在IE浏览器中,你可以在img中间加入NULL字符,而且还可以解析成功。
2. 在img和src还有src=s和title之间的两个边界,你完全可以用别的符号来替换边界
有图为证:

换成\t仍然可以解析成功,也就是并不是必须用空格或者\t的对吧。换成\n照样可以成功:
至于还有什么符号还可以,嗯哼,这就需要读者自己尝试了(什么难道你要自己一个一个试?)
1. 大家注意我在onerror和class参数之间没有空格或者其他分隔符,但是仍然可以执行成功,为什么?这个问题我在前面部分多次提到。
2. 属性的值的边界应该用什么来确定?单引号,双引号,反引号,还有呢?这里也是读者可以自己动手去尝试的。
0×06 结语
读者要明白,浏览器之间都是有差异的,尤其是IE和其他类型的浏览器,那么具体的差异的内容,大家可以fuzz一下,当然有一些资料推荐给大家使用的:《web application obfuscation》,《web之困》。本文简单谈一谈HTML编码这些问题就已经有了这么长的篇幅。如果有机会,笔者将在以后的文章中为大家讲解一下其他的编码部分(URL编码和JS编码)
以上是关于浏览器Lexer与XSS-HTML编码的主要内容,如果未能解决你的问题,请参考以下文章