前端XSS相关整理
Posted 前端儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端XSS相关整理相关的知识,希望对你有一定的参考价值。
前端安全方面,主要需要关注 XSS(跨站脚本攻击 Cross-site scripting) 和 CSRF(跨站请求伪造 Cross-site request forgery)
当然了,也不是说要忽略其他安全问题:后端范畴、DNS劫持、HTTP劫持、加密解密、钓鱼等
CSRF主要是借用已登录用户之手发起“正常”的请求,防范措施主要就是对需要设置为Post的请求,判断Referer以及token的一致性,本文不展开
相对来说,XSS的内容就非常庞大了,下面就来整理一下一些XSS的知识点。比较匆忙,可能有点乱哈~
一、XSS
恶意攻击者向页面中注入可执行的JS代码来实现XSS的攻击。
如常见的
Payload:<script>alert(1)</script>
<div>[输出]</div>
<div><script>alert(1)</script></div>这个 Payload 可以从编辑区域而来
<input type="text" value="[输入]" />当然,输入和输出的位置还可以出现在其他地方,根据输入输位置的不同,可以形成不同类型的XSS,相应的防范措施也不同。
1.1 XSS的分类
一般来说,可以将XSS分为三类:反射型XSS、存储型XSS、DOM-base 型XSS
1.1.1 反射型XSS
大多通过URL进行传播,发请求时,XSS代码出现在URL中,提交给服务端。服务端未进行处理或处理不当,返回的内容中也带上了这段XSS代码,最后浏览器执行XSS代码
比如在 php的smarty模板中直接获取url的参数值
Payload: <script>alert(1)</script>
http://local.abc.com/main/?r=abc/index¶m=<script>alert(1)</script>
<div><{$smarty.get.param}></div>X-XSS-Protection
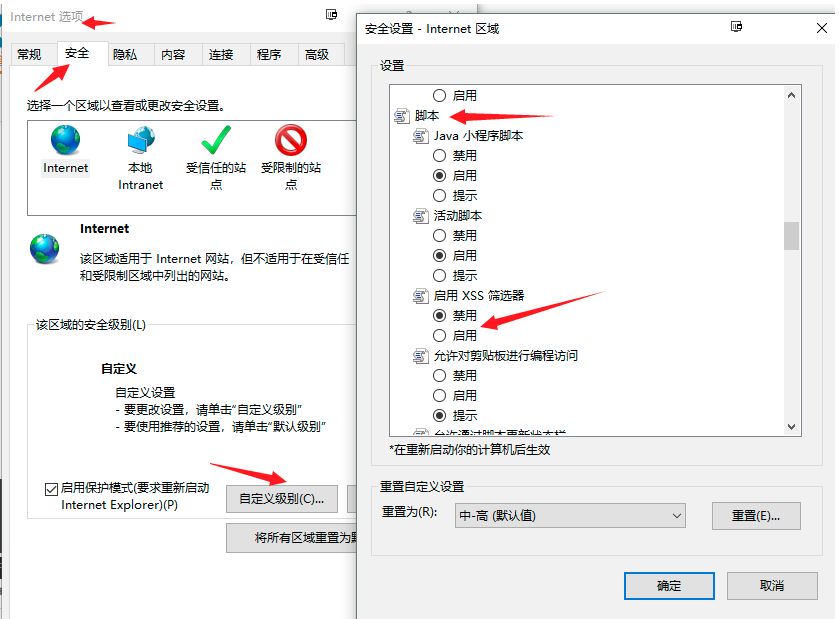
新版Chrome和Safari中,已自动屏蔽了这种XSS,形如
这个屏蔽是由 XSS Auditor操作的,它由HTTP返回头部进行控制,有四个可选值
X-XSS-Protection : 0 关闭浏览器的XSS防护机制
X-XSS-Protection : 1 删除检测到的恶意代码(如果不指定,IE将默认使用这个)
X-XSS-Protection : 1; mode=block 如果检测到恶意代码,将不渲染页面 (如果不指定,Chrome将默认使用这个)
X-XSS-Protection : 1; report=<reporting-uri> 删除检测到的恶意代码,并通过report-uri发出一个警告。前三个在IE和Chrome中有效,最后一个只在Chrome中有效
可以手动在设置请求头看看变化
header('X-XSS-Protection: 1; mode=block');建议配置为后两个的结合,禁止页面渲染并进行上报
header('X-XSS-Protection: 1; mode=block; report=www.xss.report');不建议仅仅配置为1,因为它删除恶意代码的功能有时比较鸡肋,可能会弄巧成拙。
另外,这个配置只能充当辅助作用,不能完全依赖,其也可能会产生一些问题
不过在Firefox中并未屏蔽
在IE中的XSS Filter也默认也开启了屏蔽,也可手动关闭试试,或者通过HTTP头部进行控制

1.1.2 存储型XSS
提交的XSS代码会存储在服务器端,服务端未进行处理或处理不当,每个人访问相应页面的时候,将会执行XSS代码
如本文开始的第一个例子
1.1.3 DOM-base 型XSS
这个类型和反射型的有点类似,区别是它不需要服务端参与
比如在JS中直接获取URL中的值
Payload: alert('xss')
http://local.abc.com/main/?r=abc/index#alert('xss')
<script>
var hash = eval(location.hash.slice(1));
</script>另外,有些攻击方式的类型是单一的,有些是混合的。防范攻击,不应仅根据类型来防范,而应根据输入输出的不同来应对。
在反射型和DOM-base型中,一般会通过设置一些有诱导性质的链接,用户点击链接后则触发链接中的XSS
Content Security Policy(CSP)内容安全策略
为了防范XSS,CSP出现了。
CSP 的实质就是白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,提供了这种白名单之后,实现和执行则由浏览器完成
通过一系列的自定义配置,可以在很大程度上防止恶意脚本的攻击,建议进行配置。
不过策略比较新,在各浏览器也有一些兼容性的问题。另外,似乎还是可以通过绕过的,这里就不展开了
Cookie 配置
大多使用cookie来实现对用户的认证。如果攻击者拿到了这个认证cookie,就可以登录了用户的账号了
XSS的主要目的是为了得到cookie,当然也不仅是为了获取cookie
cookie安全注意点
Httponly:防止cookie被xss偷
https:防止cookie在网络中被偷
Secure:阻止cookie在非https下传输,很多全站https时会漏掉
Path :区分cookie的标识,安全上作用不大,和浏览器同源冲突
通过设置 cookie的几个属性,可以在一定程度上保障网站的安全
不过并没有十全十美的东西,虽然攻击门槛提高了,但HttpOnly在某些特定情况下还是能绕过的,道高一尺魔高一点一尺呀
1.2 执行JS代码
XSS的目的一般是盗取cookie,一般需要通过JS 的 document.cookie来获取这个值。
所以要先思考的是:在什么地方可以执行JS相关的代码
然后要思考的是:攻击者能不能在这些地方构造出能够执行的脚本
1.2.1 <script>标签中
<script>alert(1);</script>1.2.2 html中的某些事件
<img src="1" onerror="alert(1)" >
<input type="text" onfocus="alert(1)">
<span onmouseover="alert(1)"></span>1.2.3 javascript: 伪协议
<a href="javascript:alert(1)">test</a>
<iframe src="javascript:alert(1)"></iframe>
location.href = 'javascript:alert(1)'对于事件的执行触发,是有机会防御的,围观 这篇文章
1.2.4 base64编码的 data: 伪协议
Payload: <script>alert('XSS')</script> ,它的base64编码为PHNjcmlwdD5hbGVydCgnWFNTJyk8L3NjcmlwdD4K
<a href="data:text/html;base64,PHNjcmlwdD5hbGVydCgnWFNTJyk8L3NjcmlwdD4K">test</a>1.2.5 css中的expression表达式
仅在IE8以下才支持expression,可以忽略这个了
<span style="color:1;zoom:expression(alert(1));"></span>1.2.6 css中的src
很多文章都说到这个payload,然鹅并没有生效,不知真假
根据一些讨论,在css中是很难实现xss的
.abc {
background: url(...)
}1.2.7 使用 eval、new Function、setTimeout 执行字符串时
setTimeout('alert(1)');
eval('alert(2)');
var f = new Function('alert(3)');
f();1.3 编码与解码
防范XSS,比较通用的做法是:提交保存前对特殊字符进行过滤转义,进行HTML实体的编码
var escape = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
"'": ''',
'`': '`'
};事实上,仅仅这样做还是不够的
那为什么要进行HTML实体的编码呢?
这涉及到浏览器的解析过程。
浏览器在解析HTML文档期间,根据文档中的内容,会经过 HTML解析、JS解析和URL解析几个过程
首先浏览器接收到一个HTML文档时,会触发HTML解析器对HTML文档进行词法解析,这完成HTML解码工作并创建DOM树。
如果HTML文档中存在JS的上下文环境,JavaScript解析器会介入对内联脚本进行解析,完成JS的解码工作。
如果浏览器遇到需要URL的上下文环境,URL解析器也会介入完成URL的解码工作。
URL解析器的解码顺序会根据URL所在位置不同,可能在JavaScript解析器之前或之后解析
1.3.1 HTML实体编码
浏览器会对一些字符进行特殊识别处理,比如将 < > 识别为标签的开始结束。
要想在HTML页面中呈现出特殊字符,就需要用到对应的字符实体。比如在HTML解析过程中,如果要求输出值为 < > ,那么输入值应该为其对应的实体 < >
字符实体以&开头 + 预先定义的实体名称,以分号结束,如“<”的实体名称为<
或以&开头 + #符号 以及字符的十进制数字,如”<”的实体编号为<
或以&开头 + #x符号 以及字符的十六进制数字,如”<”的实体编号为<
字符都是有实体编号的但有些字符没有实体名称。
普通编码与实体编码的在线转换
1.3.2 Javascript编码
Unicode 是字符集,而 utf-8,utf-16,utf-32 是编码规则
最常用的如“\uXXXX”这种写法为Unicode转义序列,表示一个字符,其中xxxx表示一个16进制数字
如”<” Unicode编码为“\u003c”,不区分大小写
普通编码与Unicode转义序列的在线转换
Unicode字符集大全
1.3.3 URL编码
%加字符的ASCII编码对于的2位16进制数字,如”/”对应的URL编码为%2f
转换可以使用 JS 自带的 encodeURIComponent 和 decodeURLComponent 方法来对特殊字符进行转义,也可以对照ASCII表为每个字符进行转换
1.3.4 编码解码分析
<span class="a<b">abc</span>
等价于
<span class="a<b">abc</span>上述代码中
编码顺序:HTML编码
解码顺序:HTML解码
<a href="//www.baidu.com?a=1&b=2">abc</a>
等价于
<a href="//www.baidu.com?a=1%26b=2">abc</a>
等价于
<a href="//www.baidu.com?a=1%26b=2">abc</a>上述代码中
编码顺序:URL编码 -> HTML编码
解码顺序:HTML解码 -> URL解码
<a href="#" onclick="alert(1)">abc</a>
等价于
<a href="#" onclick="\u0061\u006c\u0065\u0072\u0074(1)">abc</a>
等价于
<a href="#" onclick="\u0061\u006c\u0065\u0072\u0074(1)">abc</a>上述代码中
编码顺序:Javascript编码 -> HTML编码
解码顺序:HTML解码 -> Javascript解码
需要注意的是,在JS的解码中,相关的标识符才能被正确解析(如这里的 alert 标识符),
像圆括号、双引号、单引号等等这些控制字符,在进行JavaScript解析的时候仅会被解码为对应的字符串文本(比如这里并未对 (1) 进行编码,如果对括号及括号里面内容做JS编码,将无法执行alert函数 )
<a href="javascript:alert(1<2)">abc</a>
等价于
<a href="javascript:\u0061\u006c\u0065\u0072\u0074(1<2)">abc</a>
等价于(使用JS的方法进行的URL编码)
<a href="javascript:alert(1%3C2)">abc</a>
等价于(使用转换成对应ASCII编码对应2位16进制数字的URL编码)
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34%28%31%3C%32%29">abc</a>
等价于
<a href="javascript:alert(1%3C2)">abc</a>上述代码中
编码顺序:Javascript编码 -> URL编码 -> HTML编码
解码顺序:HTML解码 -> URL解码 -> Javascript解码
这里还需要注意的是,在URL的编码中,不能对协议类型(这里的 javascript: )进行编码,否则URL解析器会认为它无类型,导致无法正确识别
应用这个解析顺序,看以下这个例子
输入源 abc为URL中的值,如果后端仅进行了HTML的编码,还是有问题的
Payload-0: http://local.abc.com/main/?r=abc/index&abc=');alert('11
<span onclick="test('<{$abc}>')">test</span>
<span onclick="test('');alert('11')">test</span>解码顺序先是进行HTML解码,此时会将 '解析成 ' 号,接着进行Javascript的解码,识别到 ' 即可闭合test函数,调用成功
所以,这种情况下,后端需要先进行Javascript编码再进行HTML的编码
当然,还有其他顺序的混合。也需要考虑编码工作能不能正确地进行过滤
<a href="javascript:window.open('[输入源]')">解码顺序:
HTML解码 -> URL解码 -> Javascript解码 -> URL解码
引申出去,还有一些字符集的知识点,脑壳疼,就不在这整理了
1.4 常见XSS攻击方式
XSS的攻击脚本多种多样,在使用了模板(前端模板和后端模板)之后,需要格外注意数据的输入输出
下面列举几个常见的
1.4.1 PHP使用Yii框架中的Smarty模板
有时候会使用 $smarty.get.abc 获取URL中的参数,未经转义
Payload-1: http://local.abc.com/main/?r=abc/index&abc=<script>alert(1)</script>
<span><{$smarty.get.abc}></span>
<span><script>alert(1)</script></span>
Payload-2: http://local.abc.com/main/?r=abc/index&abc="><script>alert(1)</script>
<a href="/main/?param=<{$smarty.get.abc}>">abc</a>
<a href="/main/?param="><script>alert(1)</script>">abc</a>
Payload-3: http://local.abc.com/main/?r=abc/index&abc=" onmouseover=alert(1)
<a href="/main/?param=<{$smarty.get.abc}>">abc</a>
<a href="/main/?param=" onmouseover="alert(1)" ">abc</a>
Payload-4: http://local.abc.com/main/?r=abc/index&urlTo=javascript:alert(1)
<a href="<{$smarty.get.urlTo}>">urlTo</a>
<a href="javascript:alert(1)">urlTo</a>
Payload-5: http://local.abc.com/main/?r=abc/index&urlTo=data:text/html;base64,PHNjcmlwdD5hbGVydCgxKTwvc2NyaXB0Pgo=
<a href="<{$smarty.get.urlTo}>">urlTo</a>
<!-- 对 <script>alert(1)</script> 进行 base64编码 为 PHNjcmlwdD5hbGVydCgxKTwvc2NyaXB0Pgo= -->
<a href="data:text/html;base64,PHNjcmlwdD5hbGVydCgxKTwvc2NyaXB0Pgo=">urlTo</a>
Payload-6: http://local.abc.com/main/?r=abc/index&abc=</script><script>alert(1)//
<script>
var abc = '<{$smarty.get.abc}>';
</script>
<script>
// 第一个 script标签被闭合,虽然会报错,但不会影响第二个script标签,注意需要闭合后面的引号或注释,防止报错
var abc = '</script><script>alert(1)//';
</script>
Payload-7: http://local.abc.com/main/?r=abc/index&abc=alert(1)
<script>
if (<{$smarty.get.abc}> == 'abc') {
console.log(1);
}
</script>
<script>
// 此处因为没有用引号,所以可以直接执行 alert(1)
if (alert(1) == 'abc') {
console.log(1);
}
</script>
Payload-8: http://local.abc.com/main/?r=abc/index&abc='){}if(alert(1)){//
<script>
if ('<{$smarty.get.abc}>' == 'abc') {
console.log(1);
}
</script>
<script>
// 用了引号之后,闭合难度增加,不过还是可以闭合起来的
if (''){}if(alert(1)){//' == 'abc') {
console.log(1);
}
</script>
Payload-9: http://local.abc.com/main/?r=abc/index&abc=');alert('1
Payload-10: http://local.abc.com/main/?r=abc/index&abc=%26%2339%3B);alert(%26%2339%3B1 对参数进行了HTML的实体编码
<span onclick="test('<{$smarty.get.abc}>')">test</span>
<span onclick="test('');alert('1')">test</span>
Payload-11: http://local.abc.com/main/?r=abc/index&abc=" onfocus="alert(1)" autofocus="autofocus"
<input type="text" id="input" value="<{$smarty.get.abc}>">
<input id="input" value="" onfocus="alert(1)" autofocus="autofocus" "="" type="text">在线 base64编码解码
解决方式为:
不使用 $smarty.get 相关获取参数,改用后端过滤数据后再返回参数;
Yii框架中相应位置配置:'escape_html' => true
在页面标签内嵌的脚本中直接使用后端返回的数据并不安全,后端可能过滤不完善(见Payload-7和Payload-0)避免直接使用
可以改用将数据存储在属性中,再通过脚本获取属性的方式
1.4.2 JS操作DOM的时候是否会有XSS隐患?
使用 jQuery的append相关方法时(比如 html方法)可能会
// 执行
$($0).html('<script>alert(1);</script>');
// 执行
$($0).html('\u003cscript\u003ealert(1);\u003c/script\u003e');
// 执行
$($0).append('<script>alert(1);</script>');
// 不执行
$0.innerHTML = '<script>alert(1);</script>';原因是在jQuery中使用了eval方法执行相应的脚本,需要注意的是,Unicode编码的字符在运算中会被解析出来

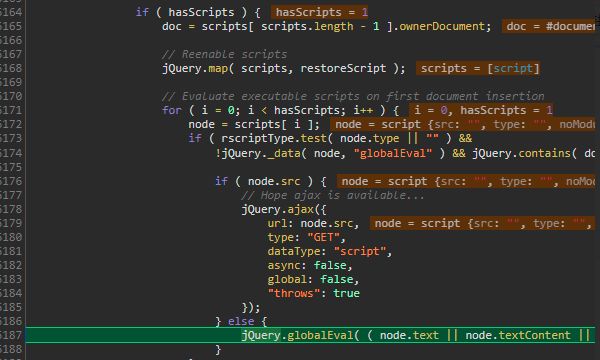
所以,要注意的是
使用jQuery设置DOM内容时,记得先对内容进行转义
对于设置输入框的值,是安全的
<input type="text" id="input">
<textarea value="12" id="textarea"></textarea>
<script>
// 不执行
document.getElementById('input').value = '"><script>alert(1);<\/script>';
document.getElementById('textarea').value = '"><script>alert(1);<\/script>';
// 不执行
$('#input').val('" onmouseover="alert(1)"');
$('#textarea').val('" onmouseover="alert(1)"');
</script>对于设置属性的值,是安全的
<input type="text" id="input">
<textarea value="12" id="textarea"></textarea>
<script>
// 不执行
document.getElementById('input').setAttribute('abc', '"><script>alert(1);<\/script>');
document.getElementById('textarea').setAttribute('abc', '"><script>alert(1);<\/script>');
// 不执行
$('#input').attr('abc', '" onmouseover="alert(1)"');
$('#textarea').attr('abc', '" onmouseover="alert(1)"');
</script>
1.4.3 前端Handlebars模板中的安全问题
后端有Smarty模板,前端也可以有Handlebars模板,使用模板有利于开发维护代码。不过和后端一样,使用模板也要考虑到XSS的问题
Handlebars模板中可选择是否开启转义
<!-- 转义,如果name的值已经被后端转义为实体符> 那么Handlebars将会转换成 &gt; 在浏览器中将会显示 > -->
<!-- 所以此时需要先将 > 转回 > 再传入Handlebars模板,才能看到正确的 > 符号 -->
<span>{{name}}</span>
<!-- 不转义 -->
<span>{{{name}}}</span>所以要注意的第一点是:
如果使用了转义占位符,就需要先进行还原;如果不使用转义,就不要还原,否则将造成XSS
另外,Handlebars模板可以自定义helper,helper有两种使用方式,直接返回数据或返回子层
<!-- 模板 [A] -->
<script type="text/template" id="test-tpl">
<span abc="{{#abc attrData}}{{/abc}}">111{{#abc data}}{{/abc}}</span>
<span>
<input type="text" value="{{#abc attrData}}{{/abc}}">
</span>
</script>
<!-- 模板 [B] -->
<!-- <script type="text/template" id="test-tpl">
<span abc="{{#abc attrData}}{{attrData}}{{/abc}}">111{{#abc data}}{{data}}{{/abc}}</span>
<span>
<input type="text" value="{{#abc attrData}}{{attrData}}{{/abc}}">
</span>
</script> -->
<!-- 容器 -->
<span id="test"></span>
<script src="........./handlebars/handlebars-v4.0.5.js"></script>
<script type="text/javascript">
// 自定义helper
Handlebars.registerHelper('abc', function (text, options) {
// 对输入数据进行过滤 [1]
// text = Handlebars.Utils.escapeExpression(text)
// helper直接返回数据 [2]
return text;
// helper返回子层 [3]
// return options.fn(this);
});
// Handlebars获取数据
function getHtml(html, data) {
let source = Handlebars.compile(html);
let content = source(data);
return content;
}
var data = '<script>alert(1);<\/script>';
var attrData = '" onmouseover="alert(2)"';
// 渲染
$('#test').html(getHtml($('#test-tpl').html(), {
data: data,
attrData: attrData
}));
</script>进入页面后,将会执行 alert(1) ,然后鼠标滑过span或input元素,将会执行 alert(2)
这是因为Handlebars在处理helper时,如果是返回数据,将不进行转义过滤
解决方案为:
如果使用了自定义的helper直接返回数据,先转义一遍,即取消注释[1] 处 代码
或者不直接返回数据,即注释模板[A],[1] 和[2]处,取消注释模板[B],[3]处 代码
另外,前端模板会频繁和JS进行交互,在前端直接使用JS获取URL参数并放到模板中时,要格外注意防止产生DOM-base型XSS,如下面这段代码
Payload: http://local.abc.com/main/?r=abc/index¶m=%22%20onmouseover=%22alert(2)%22
function getUrlParam(name) {
let value = window.location.search.match(new RegExp('[?&]' + name + '=([^&]*)(&?)', 'i'));
return value ? decodeURIComponent(value[1]) : '';
}
var attrData = getUrlParam('param');1.4.4 React JSX模板中的 dangerouslySetInnerHTML
<span dangerouslySetInnerHTML={{__html: '<script>alert(1);</script>'}}></div>
这段代码会执行么
事实上,并不会。与模板不同,它使用的是 innerHTML来更新DOM元素的内容,所以不会执行恶意代码
不过,这个内容不会显示在页面中,如果这时正常的一段内容,就应该转义之后再放入 __html的值中
1.4.5 在React的服务端渲染中,也要注意安全问题
服务端渲染需要一个初始的state,并与客户端做对应
可能会长这样子
<!-- 客户端 -->
<div id="content">
<|- appHtml |>
</div>
<script id="preload-state">
var PRELOAD_STATE = <|- preloadState |>
</script>
// 服务端
res.render('xxx.html', {
appHtml: appHtml,
preloadState: JSON.stringify(preloadState).replace(/</g, '\\u003c')
});类似模板,服务端将数据传给客户端时,在模板组装数据的时候要防止构造出闭合 <script>标签的情景
这里可以将 < 替换成对应的Unicode字符串,在JS中获取该字符串时,可以直接识别为 <
1.4.6 百度编辑器的编辑源码,可能会有安全问题
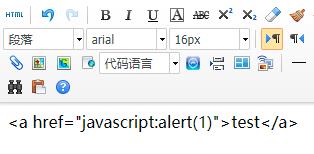
在编辑器内直接输入这串内容,不会执行。点击查看源码,可以看到已经经过转义
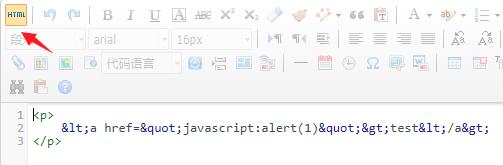
我们可以直接在这里修改源码
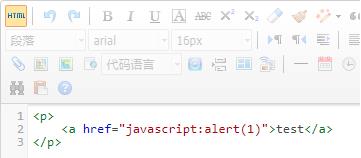
再切换回去,一个XSS漏洞就产生了,如果稍加不注意就会被利用。
所以,在前端范畴必须将此入口去除,后端也应加强一些特殊字符的转义
1.4.7 谨防 javascript: 伪协议
链接中带有 javascript: 伪协议可执行对应的脚本,常见于 a 的 href 标签和 iframe的 src 中
<a href="javascript:alert(1)">test</a>
<!-- 冒号: 的HTML实体符 -->
<a href="javascript:alert(1)">test</a>
<iframe src="javascript:alert(1)"></iframe>输入源多为一个完整的URL路径,输出地方多为模板与JS的操作
<a href="<{$urlTo}>">test</a>
<a href="{{{urlTo}}}">test</a>
location.href = getUrlParam('urlTo');普通的HTML实体符并不能过滤这个伪协议
需要知道的是,javascript: 能够正常工作的前提为:开始URL解析时没有经过编码
解决方案:
1. 前端后端都要先对 '"><& 这些特殊字符进行过滤转义,特别是在与模板共用时,它们很有可能会闭合以产生攻击,或者利用浏览器解码的顺序来绕过不严格的过滤
2.严格要求输入的URL以 https:// 或 http:// 协议开头
3.严格限制白名单协议虽然可取,但有时会造成限制过头的问题。还可以单独限制伪协议,直接对 javascript: 进行过滤
过滤时需要兼容多层级的嵌套: javajavajavascript:script:script:alert(1)
同时显示的时候,将多余的冒号 : 转义成URL编码,注意避免把正常的协议头也转义了,要兼容正常的URL
转义冒号要使用 encodeURIComponent , encodeURI转义不了,另外escape也不建议使用,关于三者的区别
function replaceJavascriptScheme(str) {
if (!str) {
return '';
}
return str.replace(/:/g, encodeURIComponent(':'));
}
Handlebars.registerHelper('generateURL', function (url) {
url = Handlebars.Utils.escapeExpression(url);
if (!url) {
return '';
}
var schemes = ['//', 'http://', 'https://'];
var schemeMatch = false;
schemes.forEach(function(scheme) {
if (url.slice(0, scheme.length) === scheme) {
url = scheme + replaceJavascriptScheme(url.slice(scheme.length));
schemeMatch = true;
return false;
}
});
return schemeMatch ? url : '//' + replaceJavascriptScheme(url);;
});1.4.8 注意符号的闭合 '">< 和其他特殊符号
闭合标签,闭合属性是很常见的一种攻击方式,要重点关注哪里可能被恶意代码闭合。
本文使用了模板Smarty,在使用模板的时候,一般都将模板变量放在了引号中,需要带符号来闭合来实现攻击
<span abc="<{$abc}>"></span>
" onclick=alert(1)在设置了特殊符号转义的情况下,这种攻击方式将失效
然鹅当输出的数据不在引号当中时,防范难度将加大。因为分离属性可以使用很多符号,黑名单过滤可能列举不全
abc/index?abc=1 onclick=alert(1)
<span id="test1" abc=<{$abc}>>test</span>所以,尽量用引号包裹起变量
另外,也要避免在 <script>标签中直接使用模板中的变量,可以改用将模板变量缓存在HTML属性中,JS再进行取值
防止该 <script>标签被恶意代码闭合,然后执行恶意代码,例子可见上文的 Payload-6
还要注意JS的语法,在某些时候,特殊符号 反斜杠\ 没有过滤的话,也有安全问题
<script>
var aaaa = '?a=<{$a}>' + '&b=<{$b}>';
</script>
?r=abc/index&a=\&b==alert(1);function b(){}//
<script>
// 构造处可执行的代码,如果空格也被转义了,还可以用注释占位 function/**/b(){}
var aaaa = '?a=\' + '&b==alert(1);function b(){}//';
</script>假设只对 ' " > < & 进行了转义,可以试试从URL拿数据,这里需要利用到JS代码中关键的 & 符号与 \ 转义符
\ 将第一个分号转义为字符串
& 与运算将前后分离
b的参数加上 = 号构造处bool运算
为了防止b未定义,在后面用函数提升特性来定义
最后注释符防止报错
为了攻击也是蛮拼的....所以最好还是要对JS操作的字符用反斜杠进行转义一下,比如 \ -> \\
1.4.9 图片 exif 信息含有恶意代码
另一种XSS攻击的方式是在图片的exif信息中注入脚本,在读取图片信息时要注意过滤
在早期的很多插件中都没有进行处理,如之前爆出的 Chrome Exif Viewer 插件问题,可能还有相关插件没有这些意识,平时也要注意
另外,站点自身在读取文件信息时也要注意,攻击者在上传文件前,可能会对文件的信息进行修改,过滤不当很可能就造成严重的存储型漏洞
以上是关于前端XSS相关整理的主要内容,如果未能解决你的问题,请参考以下文章