从零学习安全测试,从XSS漏洞攻击和防御开始
Posted 黑白之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零学习安全测试,从XSS漏洞攻击和防御开始相关的知识,希望对你有一定的参考价值。
文章来源:腾讯WeTest
导读
本篇包含了XSS漏洞攻击及防御详细介绍,包括漏洞基础、XSS基础、编码基础、XSS Payload、XSS攻击防御。
第一部分:漏洞攻防基础知识
XSS属于漏洞攻防,我们要研究它就要了解这个领域的一些行话,这样才好沟通交流。同时我建立了一个简易的攻击模型用于XSS漏洞学习。
1. 漏洞术语
了解一些简单术语就好。
VUL
Vulnerability漏洞,指能对系统造成损坏或能借之攻击系统的Bug。
POC
Proof of Concept,漏洞证明;可以是可以证明漏洞存在的文字描述和截图,但更多的一般是证明漏洞存在的代码;一般不会破坏存在漏洞的系统。
EXP
exploit,漏洞利用;利用漏洞攻击系统的代码。
Payload
(有效攻击负载)是包含在你用于一次漏洞利用(exploit)中的攻击代码。
PWN
是一个黑客语法的俚语词 ,是指攻破设备或者系统。
0DAY漏洞和0DAY攻击
零日漏洞或零时差漏洞(Zero-dayexploit)通常是指还没有补丁的安全漏洞。
零日攻击或零时差攻击(Zero-dayattack)则是指利用这种漏洞进行的攻击。
零日漏洞不但是黑客的最爱,掌握多少零日漏洞也成为评价黑客技术水平的一个重要参数。
CVE漏洞编号
Common Vulnerabilities and Exposures,公共漏洞和暴露,为广泛认同的信息安全漏洞或者已经暴露出来的弱点给出一个公共的名称。
可以在https://cve.mitre.org/网站根据漏洞的CVE编号搜索该漏洞的介绍。也可以在中文社区http://www.scap.org.cn/上搜索关于漏洞的介绍
2. 漏洞攻击模型
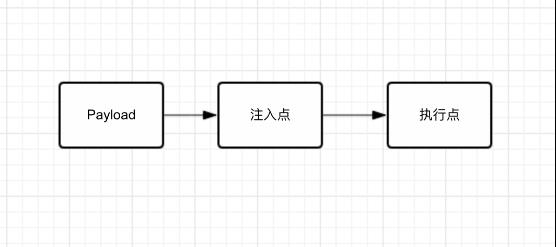
上图为一个简单的攻击模型。攻击就是将Payload通过注入点注入到执行点执行的过程。过程顺畅就表明这个漏洞被利用了。
第二部分:XSS基础知识
基础知识看完,现在我们可以开始接触了解XSS基础了。XSS基础不好就不用研究了,大家没用共同语言。
1. 什么是XSS?
XSS全称Cross-site scripting,跨站脚本攻击。攻击者通过网站注入点注入恶意客户端可执行解析的Payload,当被攻击者访问网站时Payload通过客户端执行点执行来达到某些目的,比如获取用户权限、恶意传播、钓鱼等行为。
2. XSS的分类
不了解分类其实很难学好XSS,大家对XSS分类有很多误解,而且很多文章上都解释错的,这里我给出一个相对好的XSS分类。
2.1 按照Payload来源划分
存储型XSS
Payload永久存在服务器上,所以也叫永久型XSS,当浏览器请求数据时,包含Payload的数据从服务器上传回并执行。
过程如图:
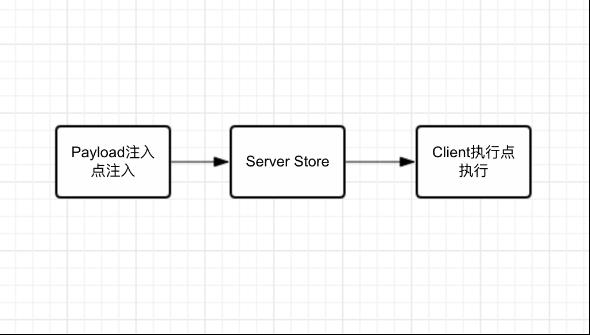
存储型XSS例子:
发表帖子内容包含Payload->存入数据库->被攻击者访问包含该帖子的页面Payload被执行
反射型XSS
又称非持久型XSS,第一种情况:Payload来源在客户端然后在客户端直接执行。第二种情况:客户端传给服务端的临时数据,直接回显到客户端执行。
过程如图:
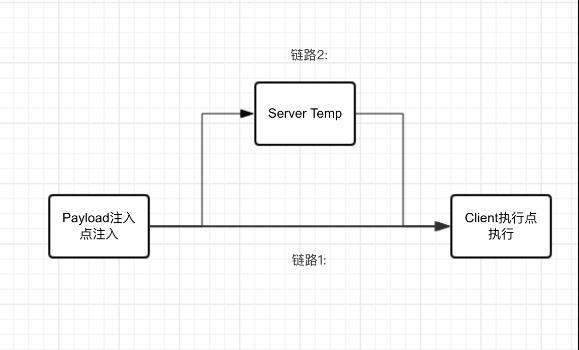
反射型XSS例子 :
1. 传播一个链接,这个链接参数中包含Payload->被攻击者访问这个链接Payload在客户端被执行。
2. 在客户端搜索框输入包含payload的内容->服务端回显一个页面提示搜索内容未找到,payload就被执行了。
2.2 按照Payload的位置划分
DOM-based XSS
由客户端javascript代码操作DOM或者BOM造成Payload执行的漏洞。由于主要是操作DOM造成的Payload执行,所以叫做DOM-based XSS,操作BOM同样也可以造成Payload执行,所以这个名词有些不准确,其实叫JavaScript-based XSS更好。
DOM-based的Payload不在html代码中所以给自动化漏洞检测带来了困难。
过程如图:

反射型DOM-based XSS的例子:
在客户端搜索框输入包含payload的内容->服务端回显一个页面提示搜索内容未找到,payload就被执行了。
存储型DOM-based XSS的例子:
从服务端接口中获取包含Payload的内容->JavaScript通过操作DOM、BOM造成Payload执行
HTML-based XSS
Payload包含在服务端返回的HTML中,在浏览器解析HTML的时候执行。这样的漏洞易于做自动化漏洞检测,因为Payload就在HTML里面。当然HTML-based XSS也有反射型和存储型的。
过程如图:
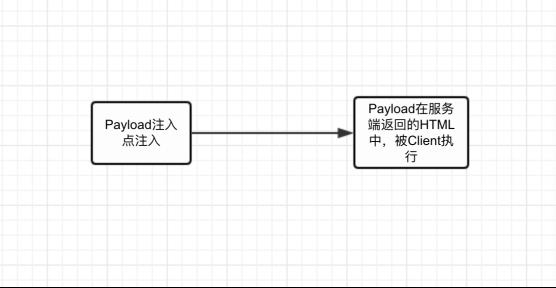
反射型HTML-based XSS的例子:
在客户端搜索框输入包含payload的内容->服务端回显一个页面提示搜索内容未找到,payload包含在HTML被执行。
存储型HTML-based XSS的例子:
发表帖子内容包含Payload->存入数据库->被攻击者访问包含该帖子的页面Payload在HTML页面中被执行
3. XSS的攻击目的及危害
很多写出不安全代码的人都是对漏洞的危害没有清晰的认识,下图是2017 OWASP 网络威胁Top10:

可以看到XSS在网络威胁中的地位举足轻重。
3.1 目的
1. cookie劫持
2. 篡改网页,进行钓鱼或者恶意传播
3. 网站重定向
4. 获取用户信息
3.2 危害
1. 传播类危害
2. 系统安全威胁
第三部分:XSS攻击的Payload
这部分我们分析下攻击模型中的Payload,了解Payload必须了解编码,学习好JS也必须要了解好编码。要想真正做好网络安全编码是最基本的。
1. 编码基础
编码部分是最重要的虽然枯燥但必须要会。后面很多变形的Payload都建立在你的编码基础。这里通16进制编码工具让你彻底学会编码。
1.1 编码工具
16进制查看器:方便查看文件16进制编码
MAC:HEx Friend
windows: HxD
编辑器Sublime:可以通过Sublime将文件保存不同编码类型
1.2 ASCII
定义:美国信息交换标准代码,是基于拉丁字母的一套计算机编码系统,主要用于显示现代英语和其他西欧语言。
编码方式:属于单子节编码。ASCII码一共规定了128个字符的编码,只占用了一个字节的后面7位,最前面的1位统一规定为0。0~31及127(共33个)是控制字符或通信专用字符。32~126(共95个)是字符(32是空格。
1.3 ISO-8859-1(Latin1)
定义:Latin1是ISO-8859-1的别名,ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在ISO-8859-1当中。
编码方式:ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
注意:ISO-8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用ISO-8859-1编码来表示。比如,虽然”中文”两个字不存在iso8859-1编码,以gb2312编码为例,应该是”d6d0 cec4”两个字符,使用iso8859-1编码的时候则将它拆开为4个字节来表示:”d6 d0 ce c4”(事实上,在进行存储的时候,也是以字节为单位处理的)。所以mysql中latin1可以表示任何编码的字符。
Latin1与ASCII编码的关系:完全兼容ASCII。
1.4 Unicode编码(UCS-2)
Code Point: 码点,简单理解就是字符的数字表示。一个字符集一般可以用一张或多张由多个行和多个列所构成的二维表来表示。二维表中行与列交叉的点称之为码点,每个码点分配一个唯一的编号,称之为码点值或码点编号。
BOM(Byte Order Mark):字节序,出现在文件头部,表示字节的顺序,第一个字节在前,就是”大端方式”(Big-Endian),第二个字节在前就是”小端方式”(Little-Endian)。
在Unicode字符集中有一个叫做”ZERO WIDTH NO-BREAK SPACE“的字符,它的码点是FEFF。而FFFE在Unicode中是不存在的字符,所以不应该出现在实际传输中。在传输字节流前,我们可以传字符”ZERO WIDTH NO-BREAK SPACE“表示大小端,因此字符”ZERO WIDTH NO-BREAK SPACE“又被称作BOM。
BOM还可以用来表示文本编码方式,Windows就是使用BOM来标记文本文件的编码方式的。Mac上文件有没有BOM都可以。
例如:\u00FF :00是第一个字节,FF是第二个字节。和码点表示方式一样属于大端方式。
Unicode编码字符集:旨在收集全球所有的字符,为每个字符分配唯一的字符编号即代码点(Code Point),用 U+紧跟着十六进制数表示。所有字符按照使用上的频繁度划分为 17 个平面(编号为 0-16),即基本的多语言平面和增补平面。基本的多语言平面又称平面 0,收集了使用最广泛的字符,代码点从 U+0000 到 U+FFFF,每个平面有 216=65536 个码点;
Unicode编码:Unicode 字符集中的字符可以有多种不同的编码方式,如 UTF-8、UTF-16、UTF-32、压缩转换等。我们通常所说的Unicode编码是UCS-2 将字符编号(同 Unicode 中的码点)直接映射为字符编码,亦即字符编号就是字符编码,中间没有经过特别的编码算法转换。是定长双字节编码:因为我们UCS-2只包括本的多语言平面(U+0000 到 U+FFFF)。
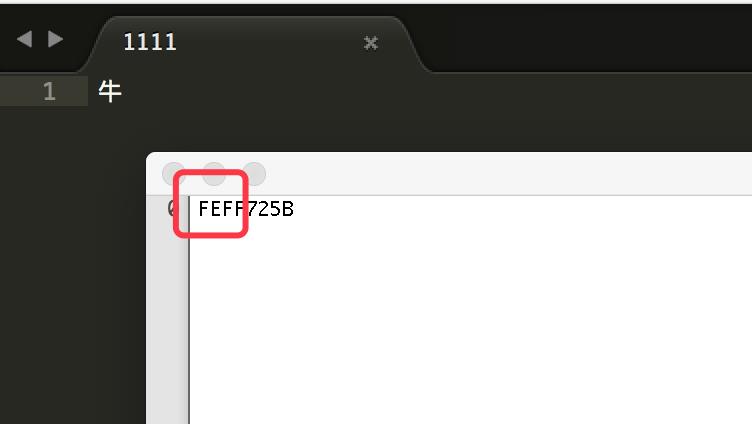
UCS-2的BOM:大端模式:FEFF。小端模式:FFFE。
文件保存成UTF-16 BE with BOM相当于UCS-2的大端模式,可以看到16进制开头为FEFF
Latin1与Unicode编码的关系:Latin1对应于Unicode的前256个码位。
1.5 UTF-16
定义及编码:UTF-16是Unicode的其中一个使用方式,在Unicode基本多文种平面定义的字符(无论是拉丁字母、汉字或其他文字或符号),一律使用2字节储存。而在辅助平面定义的字符,会以代理对(surrogate pair)的形式,以两个2字节的值来储存。是双字节编码。
UTF-16与UCS-2的关系:UTF-16可看成是UCS-2的父集。在没有辅助平面字符(surrogate code points)前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。现在若有软件声称自己支援UCS-2编码,那其实是暗指它不能支援在UTF-16中超过2bytes的字集。对于小于0x10000的UCS码,UTF-16编码就等于UCS码。
UTF-16的BOM:大端模式:FEFF。小端模式:FFFE。
1.6 UTF-8
定义及编码:UTF-8就是在互联网上使用最广的一种Unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码作为它的一部分,注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。从unicode到utf-8并不是直接的对应,而是要过一些算法和规则来转换。
Unicode符号范围 |
UTF-8编码方式(十六进制) |
0000 0000-0000 007F |
0xxxxxxx |
0000 0080-0000 07FF |
110xxxxx 10xxxxxx |
0000 0800-0000 FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
0001 0000-0010 FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
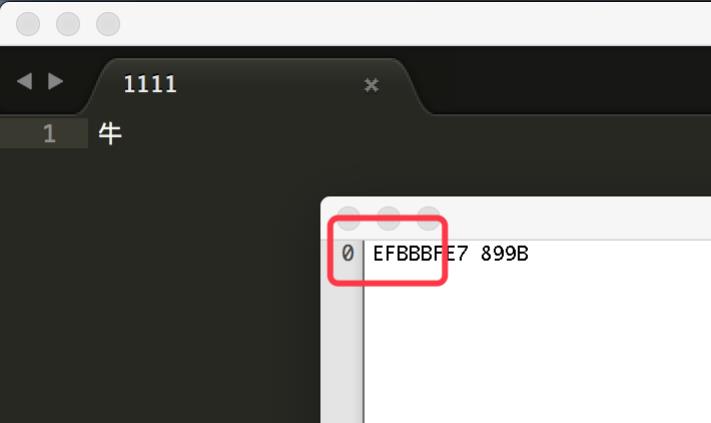
UTF8的BOM:EFBBBF。UTF-8不存在字符序列的问题,但是可以用用BOM表示这个文件是一个UTF-8文件。
文件保存成UTF-8 BE with BOM,可以看到16进制开头为EFBBBF
1.7 GBK/GB2312
定义及编码:GB2312是最早一版的汉字编码只包含6763汉字,GB2312只支持简体字而且不全,显然不够用。GBK编码,是对GB2312编码的扩展,完全兼容GB2312标准,支持简体字繁体字,包含全部中文字符。GBK编码采用单双字节编码方案,单字节和Latin1一致,双字节是汉字部分,其编码范围:8140-FEFE,剔除xx7F码位,共23940个码位。
GBK与Latin1的关系:GBK单字节编码区和Latin1编码一致。
GBK与Unicode的关系:GBK与Unicode字符集编码不同但是兼容的。如"汉"的Unicode值与GBK虽然是不一样的,假设Unicode为a040,GBK为b030,但是可以对应转化的。汉字的Unicode区:4E00-u9FA5。
GBK与UTF-8:GBK汉字采用双字节编码比在UTF-8中的三字节要小。但是UTF-8更通用。GBK与UTF-8转化:GBK—> Unicode —> UTF8
2. 前端中的编码
有了编码基础就可以来认识一下前端中的编码,这样你才能真正认识Payload。我这里的应该是总结最全的。
2.1 Base64
Base64可以用来将binary的字节序列数据编码成ASCII字符序列构成的文本。使用时,在传输编码方式中指定Base64。使用的字符包括大小写拉丁字母各26个、数字10个、加号+和斜杠/,共64个字符及等号=用来作为后缀用途。所以总共65个字符。
将3字节的数据,先后放入一个24位的缓冲区中,先来的字节占高位。数据不足3字节的话,于缓冲器中剩下的比特用0补足。每次取出6bit对原有数据用Base64字符作为编码后的输出。编码若原数据长度不是3的倍数时且剩下1个输入数据,则在编码结果后加2个=;若剩下2个输入数据,则在编码结果后加1个=。可以看出Base64编码数据大约是原来数据的3/4。
标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的/和+字符变为形如%XX的形式,而这些%号在存入数据库时还需要再进行转换,因为ANSI SQL中已将%号用作通配符。为解决此问题,可采用一种用于URL的改进Base64编码,它不在末尾填充=号,并将标准Base64中的+和/分别改成了-和_,这样就免去了在URL编解码和数据库存储时所要做的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
window.btoa/window.atob base64编码(binary to ascii)和解码仅支持Latin1字符集。
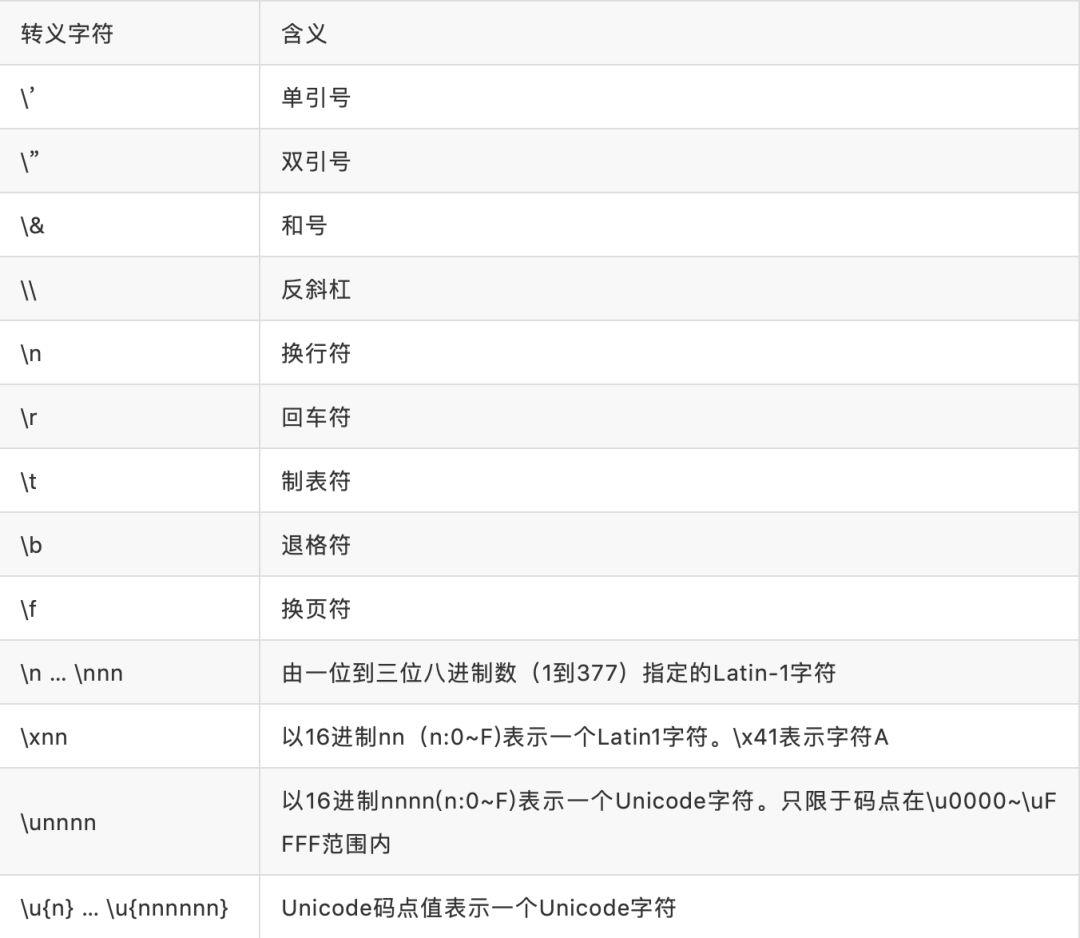
2.2 JS转义字符
js字符字符串中包含一些反斜杠开头的特殊转义字符,用来表示非打印符、其他用途的字符还可以转义表示unicode、Latin1字符。
特别注意:
1. 换行符\n在innerHTML使用只会展示一个空格并不会换行。
2. 通过\n、\u和\x可以代表任意unicode字符和Latin1字符。通过这个可以对js加密保证js安全和进行隐蔽攻击。
例子:
function toUnicode(theString) { //字符串转换为unicode编码字符串,切记这个字符串是复制用的,不是让你拿来直接执行的。
var unicodeString = '';
for (var i = 0; i < theString.length; i++) {
var theUnicode = theString.charCodeAt(i).toString(16).toUpperCase();
while (theUnicode.length < 4) {
theUnicode = '0' + theUnicode;
}
theUnicode = '\\u' + theUnicode;
unicodeString += theUnicode;
}
return unicodeString;
}
var xssStr = "alert('xss')";
var xssStrUnicode = toUnicode(xssStr);
//输出:"\u0061\u006C\u0065\u0072\u0074\u0028\u0027\u0078\u0073\u0073\u0027\u002"
eval("\u0061\u006C\u0065\u0072\u0074\u0028\u0027\u0078\u0073\u0073\u0027\u002"); //弹出xss弹窗
2.3 URL编码
RFC 1738做出规定”只有字母和数字[0-9a-zA-Z]、一些特殊符号”$-_.+!*’(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL”。所以当链接中包含中文或者其他不符合规定的字符的时候都需要经过编码的。然而由于浏览器厂商众多,对url进行编码的形式多种多样,如果不对编码进行统一处理,会对代码开发造成很大的影响,出现乱码现象。
URL编码规则:需要编码的字符转换为UTF-8编码,然后在每个字节前面加上%。
例如:
'牛'-->UTF-8编码E7899B-->URL编码是%E7%89%9BJS为我们提供了3个对字符串进行URL编码的方法:escape ,encodeURI,encodeURIComponent
escape:由于eccape已经被建议放弃所以大家就不要用了
encodeURI:encodeURI不编码的82个字符:!#$&’()*+,/:;=?@-._~0-9a-zA-Z,从中可以看不会对url中的保留字符进行编码,所以适合url整体编码
encodeURIComponent:这个对于我们来说是最有用的一个编码函数,encodeURIComponent不编码的字符有71个:!, ‘,(,),*,-,.,_,~,0-9,a-z,A-Z。
可以看出对url中的保留字进行的编码,所以当传递的参数中
包含这些url中的保留字(@,&,=),就可以通过这个方法编码后传输
这三个方法对应的解码方法: unescape、decodeURI、decodeURIComponent
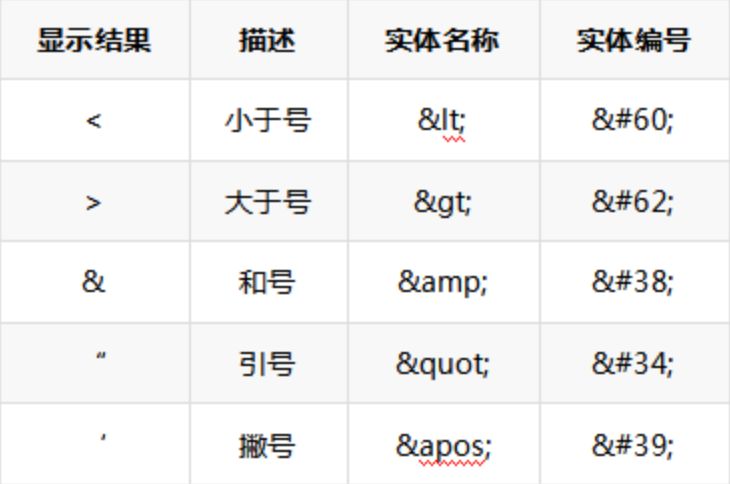
2.4 HTML字符实体
HTML中的预留字符必须被替换为字符实体。这样才能当成字符展示,否则会当成HTML解析。
字符实体编码规则:转义字符 = &#+ascii码; = &实体名称;
XSS字符串需要防御字符的实体转换表:
转化方法:
function encodeHTML (a) {
return String(a)
.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, """)
.replace(/'/g, "'");
};2.5 页面编码
页面编码设置:
<meta charset="UTF-8">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
脚本编码设置:
<script type="text/javascript" charset="UTF-8"></script>
注意:要想JS即可在UTF-8中正常使用又可以在GBK中正常使用,可以对JS中所有包含中文的字符串做字符转义。
例子:
alert("网络错误"); //弹出网络错误
alert("\u7f51\u7edc\u9519\u8bef"); //弹出网络错误3. Payload的分类
现在可以认识Payload的了,我不得不说这里对Payload的分类可以很好的让你认识Payload。也帮助你更好的对应到执行点。
3.1 原子Payload
最低层级的Payload。
javascript代码片段
可在eval、setTimeout、setInterval中直接执行,也可通过HTML等构成高阶Payload
javascript:javascript伪协议
结构:javascript:+js代码。可以在a标签的href属性被点击和window.location.href赋值的时候执行。
DATA URI协议
DATA URI结构:data:[][;base64], 。DATA URI数据在包含在iframe的src属性和object data属性中将会变成可执行的Payload.
字符串转义变种javascript代码片段
unicode或者Latin-1表示字符串。
eval("\u0061\u006C\u0065\u0072\u0074\u0028\u0027\u0078\u0073\u0073\u0027\u002"); //可执行的JS3.2 纯HTMLPayload
这种Payload特点不具有可执行的JS,但是存在传播风险,可以把别的站点注入到被攻击网站。
包含链接跳转的HTML片段
主要是传播危害
<a href="http://ha.ck">哈哈,我来钓鱼了</a>3.3 包含原子Payload的HTML片段Payload
script标签片段
script标签片段这种Payload可以引入外部JS或者可直接执行的script。这种Payload一般不能通过直接复制给innerHTML执行,不过在IE上可以。不过通过document.write是可以执行。
例子:
// Payload原始值:data:text/html,<script>alert('xss');</script>
var inputStr ="<script>alert('xss');<\/script>";
document.write(inputStr);包含事件处理的HTML片段
例如:包含img的onerror, svg的onload,input的onfocus等的HTML片段,都可以变成可执行的Payload。
var inputStr ="<img src=x onerror=alert('xss');>";
var inputStr ="<svg/onload=alert('xss')>";
var inputStr ="<input autofocus onfocus=alert('xss')>";
xssDom.innerHTML = inputStr;包含可执行JS属性的HTML片段
1. javascript伪协议
xssLink.setAttribute("href","javascript:alert('xss')")//点击可触发
var inputStr = "javascript:alert('xss')";
window.location.href = inputStr;2. DATA URI
例子:
// Payload原始值:data:text/html,<script>alert('xss');</script>
//var inputStr = '<iframe xss");</script>"></iframe>';
// var inputStr = '<object data="data:text/html;base64,ZGF0YTp0ZXh0L2h0bWwsPHNjcmlwdD5hbGVydCgneHNzJyk7PC9zY3JpcHQ+"></object>';
xssDom.innerHTML = inputStr; //弹出alert("xss")这里只是介绍了主要的Payload,还有很多不常见的Payload。
第四部分:XSS攻击模型分析
这部分我们根据漏洞攻击模型分析一下XSS的执行点和注入点。分析这两点其实就是找漏洞的过程。
1. XSS漏洞执行点
1. 页面直出Dom
2. 客户端跳转链接: location.href / location.replace() / location.assign()
3. 取值写入页面:innerHTML、document.write及各种变种。这里主要会写入携带可执行Payload的HTML片段。
4. 脚本动态执行:eval、setTimeout()、setInterval()
5. 不安全属性设置:setAttribute。不安全属性前面见过:a标签的href、iframe的src、object的data
6. HTML5 postMessage来自不安全域名的数据。
7. 有缺陷的第三方库。
2. XSS漏洞注入点
看看我们可以在哪些位置注入我们的Payload
1. 服务端返回数据
2. 用户输入的数据
3. 链接参数:window.location对象三个属性href、search、search
4. 客户端存储:cookie、localStorage、sessionStorage
5. 跨域调用:postMessage数据、Referer、window.name
上面内容基本包含了所有的执行点和注入点。对大家进行XSS漏洞攻防很有帮助。
第五部分 XSS攻击防御策略
1. 腾讯内部公共安全防御及应急响应
1. 接入公共的DOM XSS防御JS
2. 内部漏洞扫描系统扫描
3. 腾讯安全应急响应中心:安全工作者可以通过这个平台提交腾讯相关的漏洞,并根据漏洞评级获得奖励。
4. 重大故障应急响应制度。
2. 安全编码
2.1 执行点防御方法
执行点 |
防御 |
页面直出Dom |
服务端XSS过滤 |
客户端跳转链接 |
|
取值写入页面 |
客户端XSS过滤 |
脚本动态执行 |
确保执行Js字符串来源可信 |
不安全属性设置 |
内容XSS过滤,包含链接同客户端跳转链接 |
HTML5 postMessage |
origin限制来源 |
有缺陷的第三方库 |
不使用 |
2.2 其他安全防御手段
1. 对于Cookie使用httpOnly
2. 在HTTP Header中使用Content Security Policy
3. 代码审查
总结XSS检查表做代码自测和检视
4. 自动化检测XSS漏洞的工具
手工检测XSS漏洞是一件比较费时间的事情,我们能不能写一套自动检测XSS自动检测工具。竟然我知道了注入点、执行点、Payload自动化过程是完全有可能的。
XSS自动化检测的难点就在于DOM型XSS的检测。因为前端JS复杂性较高,包括静态代码分析、动态执行分析都不容易等。
第六部分 总结
上面内容文字比较多,看完还是很累的,总结起来就一句话:安全大于一切,不要心存侥幸,希望以上内容对您有帮助,不过以上内容仅代表个人理解,如有不对欢迎指正讨论。
你可能喜欢
以上是关于从零学习安全测试,从XSS漏洞攻击和防御开始的主要内容,如果未能解决你的问题,请参考以下文章