手摸手,带你用合理的姿势使用webpack4(下)
Posted 前端大全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手摸手,带你用合理的姿势使用webpack4(下)相关的知识,希望对你有一定的参考价值。
segmentfault.com/a/1190000015919928
推荐先阅读 webpack 入门教程之后再来阅读本文。
Webpack 4 和单页应用入门
本文为手摸手使用 webpack4(下),主要分为两部分:
怎么合理的运用浏览器缓存
怎么构建可靠的持久化缓存
默认分包策略
webpack 4 最大的改动就是废除了 CommonsChunkPlugin 引入了 optimization.splitChunks。
webpack 4 的Code Splitting 它最大的特点就是配置简单,如果你的 mode 是 production,那么 webpack 4 就会自动开启 Code Splitting。
以下内容都会以 vue-element-admin 为例子。 在线
bundle-report
如上图所示,在没配置任何东西的情况下,webpack 4 就智能的帮你做了代码分包。入口文件依赖的文件都被打包进了app.js,那些大于 30kb 的第三方包,如:echarts、xlsx、dropzone等都被单独打包成了一个个独立 bundle。
它内置的代码分割策略是这样的:
新的 chunk 是否被共享或者是来自 node_modules 的模块
新的 chunk 体积在压缩之前是否大于 30kb
按需加载 chunk 的并发请求数量小于等于 5 个
页面初始加载时的并发请求数量小于等于 3 个
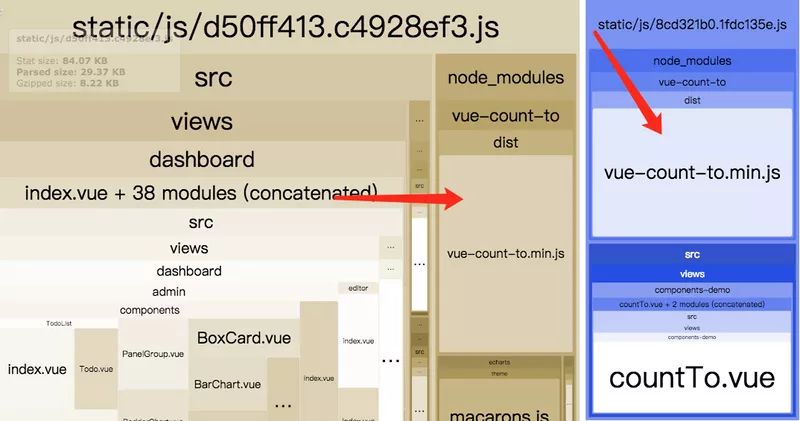
但有一些小的组件,如上图:vue-count-to 在未压缩的情况下只有 5kb,虽然它被两个页面共用了,但 webpack 4 默认的情况下还是会将它和那些懒加载的页面代码打包到一起,并不会单独将它拆成一个独立的 bundle。(虽然被共用了,但因为体积没有大于 30kb)
你可能会觉得 webpack 默认策略是不是有问题,我一个组件被多个页面,你每个页面都将这个组件打包进去了,岂不是会重复打包很多次这个组件?就拿vue-count-to来举例,你可以把共用两次以上的组件或者代码单独抽出来打包成一个 bundle,但你不要忘了vue-count-to未压缩的情况下就只有 5kb,gizp 压缩完可能只有 1.5kb 左右,你为了共用这 1.5kb 的代码,却要额外花费一次 http 请求的时间损耗,得不偿失。我个人认为 webpack 目前默认的打包规则是一个比较合理的策略了。
但有些场景下这些规则可能就显得不怎么合理了。比如我有一个管理后台,它大部分的页面都是表单和 Table,我使用了一个第三方 table 组件,几乎后台每个页面都需要它,但它的体积也就 15kb,不具备单独拆包的标准,它就这样被打包到每个页面的 bundle 中了,这就很浪费资源了。这种情况下建议把大部分页面能共用的组件单独抽出来,合并成一个component-vendor.js的包(后面会介绍)。
优化没有银弹,不同的业务,优化的侧重点是不同的。个人认为 webpack 4 默认拆包已经做得不错了,对于大部分简单的应用来说已经够用了。但作为一个通用打包工具,它是不可能满足所有的业务形态和场景的,所以接下来就需要我们自己稍微做一些优化了。
优化分包策略
就拿 vue-element-admin 来说,它是一个基于 Element-UI 的管理后台,所以它会用到如 echarts、xlsx、dropzone等各种第三方插件,同时又由于是管理后台,所以本身自己也会写很多共用组件,比如各种封装好的搜索查询组件,共用的业务模块等等,如果按照默认的拆包规则,结果就不怎么完美了。
如第一张图所示,由于element-ui在entry入口文件中被引入并且被大量页面共用,所以它默认会被打包到 app.js 之中。这样做是不合理的,因为app.js里还含有你的router 路由声明、store 全局状态、utils 公共函数,icons 图标等等这些全局共用的东西。
但除了element-ui,其它这些又是平时开发中经常会修改的东西,比如我新增了一个全局功能函数,utils文件就会发生改变,或者我修改一个路由的 path,router文件就变了,这些都会导致app.js的 hash 发生改变:app.1.js => app.2.js。但由于 element-ui和 vue/react等也被打包在其中,虽然你没改变它们,但它们的缓存也会随着app.xxx.js变化而失效了,这就非常不合理的。所以我们需要自己来优化一下缓存策略。
我们现在的策略是按照体积大小、共用率、更新频率重新划分我们的包,使其尽可能的利用浏览器缓存。
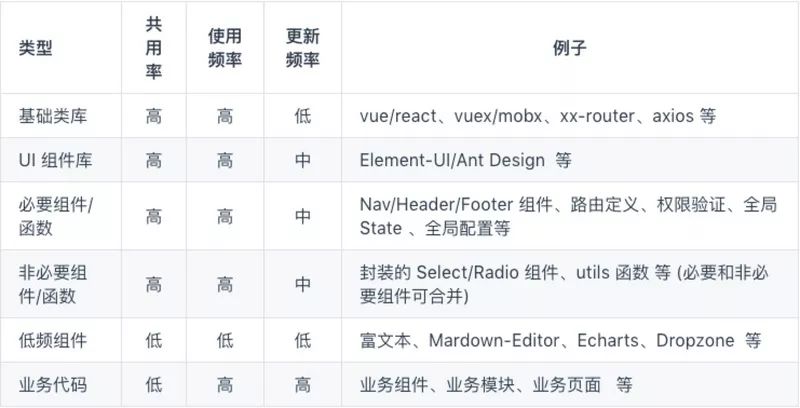
我们根据上表来重新划分我们的代码就变成了这样。
基础类库 chunk-libs
它是构成我们项目必不可少的一些基础类库,比如 vue+vue-router+vuex+axios 这种标准的全家桶,它们的升级频率都不高,但每个页面都需要它们。(一些全局被共用的,体积不大的第三方库也可以放在其中:比如 nprogress、js-cookie、clipboard 等)
UI 组件库
理论上 UI 组件库也可以放入 libs 中,但这里单独拿出来的原因是: 它实在是比较大,不管是 Element-UI还是Ant Design gizp 压缩完都可能要 200kb 左右,它可能比 libs 里面所有的库加起来还要大不少,而且 UI 组件库的更新频率也相对的比 libs 要更高一点。我们不时的会升级 UI 组件库来解决一些现有的 bugs 或使用它的一些新功能。所以建议将 UI 组件库也单独拆成一个包。
自定义组件/函数 chunk-commons
这里的 commons 主要分为 必要和非必要。
必要组件是指那些项目里必须加载它们才能正常运行的组件或者函数。比如你的路由表、全局 state、全局侧边栏/Header/Footer 等组件、自定义 Svg 图标等等。这些其实就是你在入口文件中依赖的东西,它们都会默认打包到app.js中。
非必要组件是指被大部分页面使用,但在入口文件 entry 中未被引入的模块。比如:一个管理后台,你封装了很多 select 或者 table 组件,由于它们的体积不会很大,它们都会被默认打包到到每一个懒加载页面的 chunk 中,这样会造成不少的浪费。你有十个页面引用了它,就会包重复打包十次。所以应该将那些被大量共用的组件单独打包成chunk-commons。
不过还是要结合具体情况来看。一般情况下,你也可以将那些非必要组件函数也在入口文件 entry 中引入,和必要组件函数一同打包到app.js之中也是没什么问题的。
低频组件
低频组件和上面的共用组件 chunk-commons 最大的区别是,它们只会在一些特定业务场景下使用,比如富文本编辑器、js-xlsx前端 excel 处理库等。一般这些库都是第三方的且大于 30kb,所以 webpack 4 会默认打包成一个独立的 bundle。也无需特别处理。小于 30kb 的情况下会被打包到具体使用它的页面 bundle 中。
业务代码
这部分就是我们平时经常写的业务代码。一般都是按照页面的划分来打包,比如在 vue 中,使用路由懒加载的方式加载页面 component: () => import('./Foo.vue') webpack 默认会将它打包成一个独立的 bundle。
完整配置代码:
splitChunks: {
chunks: "all",
cacheGroups: {
libs: {
name: "chunk-libs",
test: /[\/]node_modules[\/]/,
priority: 10,
chunks: "initial" // 只打包初始时依赖的第三方
},
elementUI: {
name: "chunk-elementUI", // 单独将 elementUI 拆包
priority: 20, // 权重要大于 libs 和 app 不然会被打包进 libs 或者 app
test: /[\/]node_modules[\/]element-ui[\/]/
},
commons: {
name: "chunk-comomns",
test: resolve("src/components"), // 可自定义拓展你的规则
minChunks: 2, // 最小共用次数
priority: 5,
reuseExistingChunk: true
}
}
};

上图就是最终拆包结果概要,你可以 点我点我点我,在线查看拆包结果。
这样就能尽可能的利用了浏览器缓存。当然这种优化还是需要因项目而异的。比如上图中的共用组件 chunk-commons,可能打包出来发现特别大,包含了很多组件,但又不是每一个页面或者大部分页面需要它。很可能出现这种状况:A 页面只需要 chunk-commons里面的 A 组件,
但却要下载整个chunk-commons.js,这时候就需要考虑一下,目前的拆包策略是否合理,是否还需要chunk-commons?还是将这些组件打包到各自的 bundle 中?还是调整一下 minChunks: 2( 最小共用次数)?或者修改一下它的拆包规则?
// 或者你可以把策略改为只提取那些你注册在全局的组件。
- test: resolve("src/components")
+ test: resolve("src/components/global_components") //你注册全局组件的目录
博弈
其实优化就是一个博弈的过程,是让 a bundle 大一点还是 b? 是让首次加载快一点还是让 cache 的利用率高一点? 但有一点要切记,拆包的时候不要过分的追求颗粒化,什么都单独的打成一个 bundle,不然你一个页面可能需要加载十几个.js文件,如果你还不是HTTP/2的情况下,请求的阻塞还是很明显的(受限于浏览器并发请求数)。所以还是那句话资源的加载策略并没什么完全的方案,都需要结合自己的项目找到最合适的拆包策略。
比如支持HTTP/2的情况下,你可以使用 webpack4.15.0 新增的 maxSize,它能将你的chunk在minSize的范围内更加合理的拆分,这样可以更好地利用HTTP/2来进行长缓存(在HTTP/2的情况下,缓存策略就和之前又不太一样了)。
Long term caching
持久化缓存其实是一个老生常谈的问题,前端发展到现在,缓存方案已经很成熟了。简单原理:
针对 html 文件:不开启缓存,把 html 放到自己的服务器上,关闭服务器的缓存
针对静态的 js,css,图片等文件:开启 cdn 和缓存,将静态资源上传到 cdn 服务商,我们可以对资源开启长期缓存,因为每个资源的路径都是独一无二的,所以不会导致资源被覆盖,保证线上用户访问的稳定性。
每次发布更新的时候,先将静态资源(js, css, img) 传到 cdn 服务上,然后再上传 html 文件,这样既保证了老用户能否正常访问,又能让新用户看到新的页面。
相关文章 大公司里怎样开发和部署前端代码?(https://www.zhihu.com/question/20790576/answer/32602154)
所以我们现在要做的就是要让 webpack 给静态资源生产一个可靠的 hash,让它能自动在合适的时候更新资源的 hash,
并且保证 hash 值的唯一性,即为每个打包后的资源生成一个独一无二的 hash 值,只要打包内容不一样,那么 hash 值就不一样。
其实 webpack 4 在持久化缓存这一块已经做得非常的不错了,但还是有一些欠缺,下面我们将要从这几个方面讨论这个问题。
RuntimeChunk(manifest)
Module vs Chunk
HashedModuleIdsPlugin
NamedChunksPlugin
RuntimeChunk(manifest)
webpack 4 提供了 runtimeChunk 能让我们方便的提取 manifest,以前我们需要这样配置
new webpack.optimize.CommonsChunkPlugin({
name: "manifest",
minChunks: Infinity
});
现在只要一行配置就可以了
{
runtimeChunk: true;
}
它的作用是将包含chunks 映射关系的 list单独从 app.js里提取出来,因为每一个 chunk 的 id 基本都是基于内容 hash 出来的,所以你每次改动都会影响它,如果不将它提取出来的话,等于app.js每次都会改变。缓存就失效了。
单独抽离 runtimeChunk 之后,每次打包都会生成一个runtimeChunk.xxx.js。(默认叫这名字,可自行修改)

优化
其实我们发现打包生成的 runtime.js非常的小,gzip 之后一般只有几 kb,但这个文件又经常会改变,我们每次都需要重新请求它,它的 http 耗时远大于它的执行时间了,所以建议不要将它单独拆包,而是将它内联到我们的 index.html 之中(index.html 本来每次打包都会变)。
这里我选用了 script-ext-html-webpack-plugin,主要是因为它还支持preload和 prefetch,正好需要就不想再多引用一个插件了,你完全可以使用 inline-manifest-webpack-plugin或者 assets-webpack-plugin等来实现相同的效果。
const ScriptExtHtmlWebpackPlugin = require("script-ext-html-webpack-plugin");
// 注意一定要在HtmlWebpackPlugin之后引用
// inline 的name 和你 runtimeChunk 的 name保持一致
new ScriptExtHtmlWebpackPlugin({
//`runtime` must same as runtimeChunk name. default is `runtime`
inline: /runtime..*.js$/
});
Module vs Chunk
我们经常看到xxxModuleIdsPlugin、xxxChunksPlugin,所以在 webpack 中 module和 chunk到底是一个怎么样的关系呢?
chunk: 是指代码中引用的文件(如:js、css、图片等)会根据配置合并为一个或多个包,我们称一个包为 chunk。
module: 是指将代码按照功能拆分,分解成离散功能块。拆分后的代码块就叫做 module。可以简单的理解为一个 export/import 就是一个 module。
每个 chunk 包可含多个 module。 比如:
//9.xxxxxxxxx.js
//chunk id为 9 ,包含了Vc2m和JFUb两个module
(window.webpackJsonp = window.webpackJsonp || []).push([
[9],
{
Vc2m: function(e, t, l) {},
JFUb: function(e, t, l) {}
}
]);
一个module还能跨chunk引用另一个module,比如我想在app.js里面需要引用 chunkId为13的模块2700可以这样引用:
return n.e(13).then(n.bind(null, "27OO"));
HashedModuleIdsPlugin
了解了 module和chunk之后,我们来研究一下 moduleId。
首先要确定你的 filename 配置的是chunkhash(它与 hash 的区别可以看上篇文章)。
output: {
path: path.join(__dirname, 'dist'),
filename: '[name].[chunkhash].js',
}
我们在入口文件中随便引入一个新文件test.js
//main.js
import "./test";
//test.js
console.log("apple");
我们运行npm run build,发现了一件奇怪的事情,我只是多引入了一个文件,但发现有十几个文件发生了变化。这是为什么呢?
我们随便挑一个文件 diff 一下,发现两个文件只有 module id 的不同。

这是因为:
webpack 内部维护了一个自增的 id,每个 module 都有一个 id。所以当增加或者删除 module 的时候,id 就会变化,导致其它文件虽然没有变化,但由于 id 被强占,只能自增或者自减,导致整个 id 的顺序都错乱了。
虽然我们使用 [chunkhash] 作为输出名,但仍然是不够的。
因为 chunk 内部的每个 module 都有一个 id,webpack 默认使用递增的数字作为 moduleId。
如果引入了一个新文件或删掉一个文件,都可能会导致其它文件的 moduleId 发生改变,
那这样缓存失效了。如:
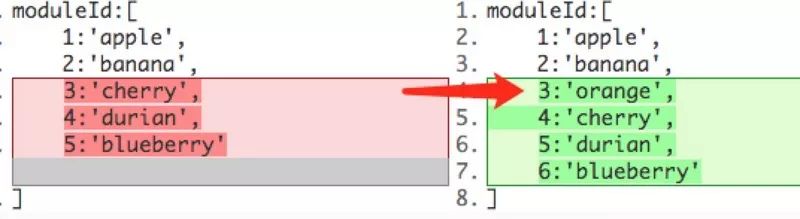
本来是一个按序的 moduleId list,这时候我插入一个orange模块,插在第三个位置,这样就会导致它之后的所以 module id 都依次加了 1。
这到了原因,解决方案就很简单了。我们就不要使用一个自增的 id 就好了,这里我们使用HashedModuleIdsPlugin。
或者使用optimization.moduleIds v4.16.0 新发布,文档还没有。查看 源码发现它有natural、named、hashed、size、total-size。这里我们设置为optimization.moduleIds='hash'等于HashedModuleIdsPlugin。源码了也写了webpack5会优化这部分代码。
它的原理是使用文件路径的作为 id,并将它 hash 之后作为 moduleId。

使用了 HashedModuleIdsPlugin`,我们再对比一下发现 module id 不再是简单的 id 了,而是一个四位 hash 过得字符串(不一定都是四位的,如果重复的情况下会增加位数,保证唯一性 源码)。
这样就固定住了 module id 了。
NamedModulesPlugin 和 HashedModuleIdsPlugin 原理是相同的,将文件路径作为 id,只不过没有把路径 hash 而已,适用于开发环境方便调试。不建议在生产环境配置,因为这样不仅会增加文件的大小(路径一般偶读比较长),更重要的是为暴露你的文件路径。
NamedChunkPlugin
我们在固定了 module id 之后同理也需要固定一下 chunk id,不然我们增加 chunk 或者减少 chunk 的时候会和 module id 一样,都可能会导致 chunk 的顺序发生错乱,从而让 chunk 的缓存都失效。
作者也意识到了这个问题,提供了一个叫NamedChunkPlugin的插件,但在使用路由懒加载的情况下,你会发现NamedChunkPlugin并没什么用。
供了一个线上demo,可以自行测一下。这里提就直接贴一下结果:

产生的原因前面也讲了,使用自增 id 的情况下是不能保证你新添加或删除 chunk 的位置的,一旦它改变了,这个顺序就错乱了,就需要重排,就会导致它之后的所有 id 都发生改变了。
接着我们 查看源码 还发现它只对有 name 的 chunk 才奏效!所以我们那些异步懒加载的页面都是无效的。这启不是坑爹!我们迭代业务肯定会不断的添加删除页面,这岂不是每新增一个页面都会让之前的缓存都失效?那我们之前还费这么大力优化什么拆包呢?
其实这是一个古老的问题了 相关 issue: Vendor chunkhash changes when app code changes 早在 2015 年就有人提了这个问题,这个问题也一直讨论至今,’网友们’也提供了各种奇淫巧技,不过大部分随着 webpack 的迭代已经不适用或者是修复了。
这里我就结合一下 timse(webpack 第二多贡献)写的持久缓存的文章(在 medium 上需要翻墙)
总结一下目前能解决这个问题的三种方案。
目前解决方案有三种
records
webpackChunkName
自定义 nameResolver
webpack records
很多人可能连这个配置项都没有注意过,不过早在 2015 年就已经被设计出来让你更好的利用 cache。官方文档
要使用它配置也很简单:
recordsPath: path.join(__dirname, "records.json");
对,只要这一行代码就能开启这个选项,并打包的时候会自动生成一个 JSON 文件。它含有 webpack 的 records 记录 – 即「用于存储跨多次构建(across multiple builds)的模块标识符」的数据片段。可以使用此文件来跟踪在每次构建之间的模块变化。
大白话就是:等于每次构建都是基于上次构建的基础上进行的。它会先读取你上次的 chunk 和 module id 的信息之后再进行打包。所以这时候你再添加或者删除 chunk,并不会导致之前所说的乱序了。
简单看一下构建出来的 JSON 长啥样。
{
"modules": {
"byIdentifier": {
"demo/vendor.js": 0,
"demo/vendor-two.js": 1,
"demo/index.js": 2,
....
},
"usedIds": {
"0": 0,
"1": 1,
"2": 2,
...
}
},
"chunks": {
"byName": {
"vendor-two": 0,
"vendor": 1,
"entry": 2,
"runtime": 3
},
"byBlocks": {},
"usedIds": [
0,
1,
2
}
}
我们和之前一样,在路由里面添加一个懒加载的页面,打包对比后发现 id 并不会像之前那样按照遍历到的顺序插入了,而是基于之前的 id 依次累加了。一般新增页面都会在末尾填写一个新 id,删除 chunk 的话,会将原来代表 chunk 的 id,保留,但不会再使用。
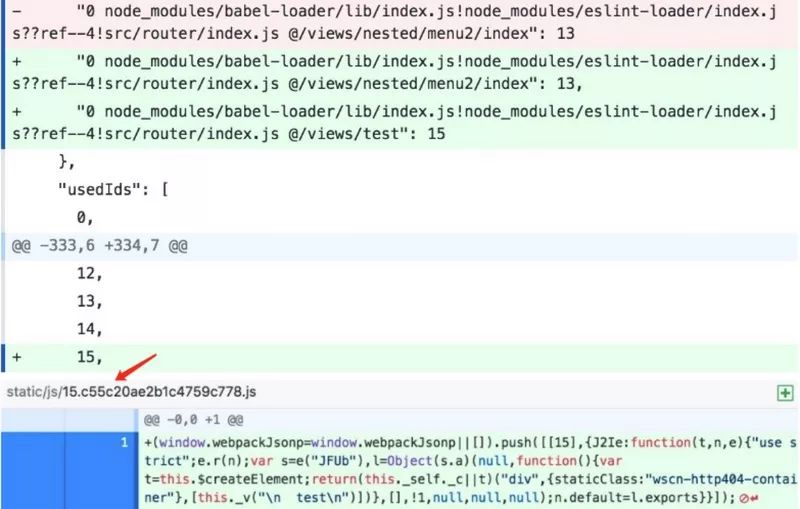
但这个方案不被大家知晓主要原因就是维护这个records.json比较麻烦。如果你是在本地打包运行webpack的话,你只要将records.json当做普通文件上传到github、gitlab或其它版本控制仓库。
但现在一般公司都会将打包放在 CI里面,用docker打包,这时候这份records.json存在哪里就是一个问题了。它不仅需要每次打包之前先读取你这份 json,打包完之后它还需要再更新这份 json,并且还要找地方存贮,为了下次构建再使用。你可以存在 git 中或者找一个服务器存,但存在什么地其它方都感觉怪怪的。
如果你使用 Circle CI可以使用它的store_artifacts,相关教程。
本人在使用了之后还是放弃了这个方案,使用成本略高。前端打包应该更加的纯粹,不需要依赖太多其它的东西。
webpackChunkName
在 webpack2.4.0 版本之后可以自定义异步 chunk 的名字了,例如:
import(/* webpackChunkName: "my-chunk-name" */ "module");
我们在结合 vue 的懒加载可以这样写。
{
path: '/test',
component: () => import(/* webpackChunkName: "test" */ '@/views/test')
},
打包之后就生成了名为 test的 chunk 文件。

chunk 有了 name 之后就可以解决NamedChunksPlugin没有 name 的情况下的 bug 了。查看打包后的代码我们发现 chunkId 就不再是一个简单的自增 id 了。
不过这种写法还是有弊端的,首先你需要手动编写每一个 chunk 的 name,同时还需要保证它的唯一性,当页面一多,维护起来还是很麻烦的。这就违背了程序员的原则:能偷懒就偷懒。
所以有什么办法可以自动生成一个 name 给 chunk 么 ?查看 webpack 源码我们发现了NamedChunksPlugin其实可以自定义 nameResolver 的。
自定义 nameResolver
NamedChunksPlugin支持自己写 nameResolver 的规则的。但目前大部分相关的文章里的自定义函数是不适合 webpack4 ,而且在结合 vue 的情况下还会报错。
社区旧方案:
new webpack.NamedChunksPlugin(chunk => {
if (chunk.name) {
return chunk.name;
}
return chunk.modules.map(m => path.relative(m.context, m.request)).join("_");
});
适配 webpack4 和 vue 的新实现方案:
new webpack.NamedChunksPlugin(chunk => {
if (chunk.name) {
return chunk.name;
}
return Array.from(chunk.modulesIterable, m => m.id).join("_");
});
当然这个方案还是有一些弊端的因为 id 会可能很长,如果一个 chunk 依赖了很多个 module 的话,id 可能有几十位,所以我们还需要缩短一下它的长度。我们首先将拼接起来的 id hash 以下,而且要保证 hash 的结果位数也能太长,浪费字节,但太短又容易发生碰撞,所以最后我们我们选择 4 位长度,并且手动用 Set 做一下碰撞校验,发生碰撞的情况下位数加 1,直到碰撞为止。详细代码如下:
const seen = new Set();
const nameLength = 4;
new webpack.NamedChunksPlugin(chunk => {
if (chunk.name) {
return chunk.name;
}
const modules = Array.from(chunk.modulesIterable);
if (modules.length > 1) {
const hash = require("hash-sum");
const joinedHash = hash(modules.map(m => m.id).join("_"));
let len = nameLength;
while (seen.has(joinedHash.substr(0, len))) len++;
seen.add(joinedHash.substr(0, len));
return `chunk-${joinedHash.substr(0, len)}`;
} else {
return modules[0].id;
}
});
我给 vue-cli 官方也提了一个相关issue尤雨溪最后也采纳了这个方案。
所以如果你现在下载最新 vue-cli@3上面啰嗦了半天的东西,其实都已经默认配置好了(但作者本人为了找到这个 hack 方法整整花了两天时间 o(╥﹏╥)o)。
目前测试了一段时间没发现有什么问题。不过有一点不是很理解,不知道 webpack 出于什么样的原因,官方一直没有修复这个问题?可能是在等 webpack5 的时候放大招吧。
总结
拆包策略:
基础类库 chunk-libs
UI 组件库 chunk-elementUI
自定义共用组件/函数 chunk-commons
低频组件 chunk-eachrts/chunk-xlsx等
业务代码 lazy-loading xxxx.js
持久化缓存:
使用 runtimeChunk 提取 manifest,使用 script-ext-html-webpack-plugin等插件内联到index.html减少请求
使用 HashedModuleIdsPlugin 固定 moduleId
使用 NamedChunkPlugin结合自定义 nameResolver 来固定 chunkId
上述说的问题大部分在 webpack 官方文档都没明确指出,唯一可以参考的就是这份 cache 文档,在刚更新 webpack4 的时候,我以为官方已经将 id 不能固定的问题解决了,但现实是残酷的,结果并不理想。不过作者也在很多的 issue 中说他正在着手优化 long term caching。
We plan to add another way to assign module/chunk ids for long term caching, but this is not ready to be told yet.
在 webpack 的 issue 和源码中也经常见到 Long term caching will be improved in webpack@5和TODO webpack 5 xxxx这样的代码注释。这让我对webpack 5很期待。真心希望webpack 5能真正的解决前面几个问题,并且让它更加的out-of-the-box,更加的简单和智能,就像webpack 4的optimization.splitChunks,你基本不用做什么,它就能很好的帮你拆分好bundle包,同时又给你非常的自由发挥空间。
展望
Whats next? 官方在这篇文章中展望了一下 webpack5 和讲述了一下未来的计划–持续改进用户体验、提升构建速度和性能,降低使用门槛,完善Persistent Caching等等。同时 webpack 也已经支持 Prefetching/Preloading modules,我相信之后也会有更多的网站会使用这一属性。
同时 webpack 的团队已经承诺会通过投票的方式来决定一些功能。比如不久前发起的投票。
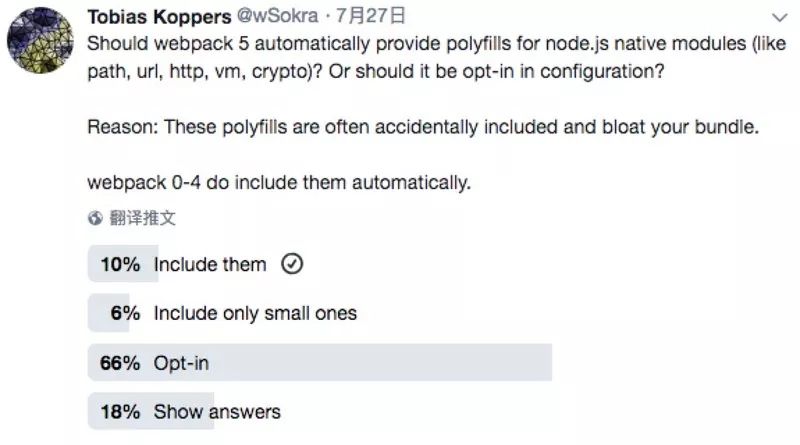
大家可以关注 Tobias Koppers 的 twitter 进行投票。
最后还是期待一下 webpack5 和它之后的发展吧。如果没有 webpack,也就不会有今天的前端。
其实如一开始就讲的,vue 有vue-cli、react 有creat-react-app,现在新建项目基本都是基于脚手架的,很少有人从零开始写 webpack 配置文件的,而且一般开发中,一般程序员也不需要经常去修改 webpack 的配置。webpack 官方本身也在不断完善默认配置项,相信 webpack 的配置门槛也会越来低多。
愿世间再无 webpack 配置工程师。

【关于投稿】
如果大家有原创好文投稿,请直接给公号发送留言。
① 留言格式:
【投稿】+《 文章标题》+ 文章链接
② 示例:
【投稿】《不要自称是程序员,我十多年的 IT 职场总结》:http://blog.jobbole.com/94148/
③ 最后请附上您的个人简介哈~
觉得本文对你有帮助?请分享给更多人
关注「前端大全」,提升前端技能
以上是关于手摸手,带你用合理的姿势使用webpack4(下)的主要内容,如果未能解决你的问题,请参考以下文章