PPTthe road to webpack 5
Posted 前端早读课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PPTthe road to webpack 5相关的知识,希望对你有一定的参考价值。
2019年8月17日在深圳科兴科学园国际会议中心举办腾讯LIVE开发者大会(TLC大前端信息流)上,由Maintainer webpack@TheLarkInn带来的一场《the road to webpack 5》的分享。
为了方便阅读对PPT的字体做了一定的优化。另说想说一句,英文真的很酷。











持久缓存(Persistent Caching)
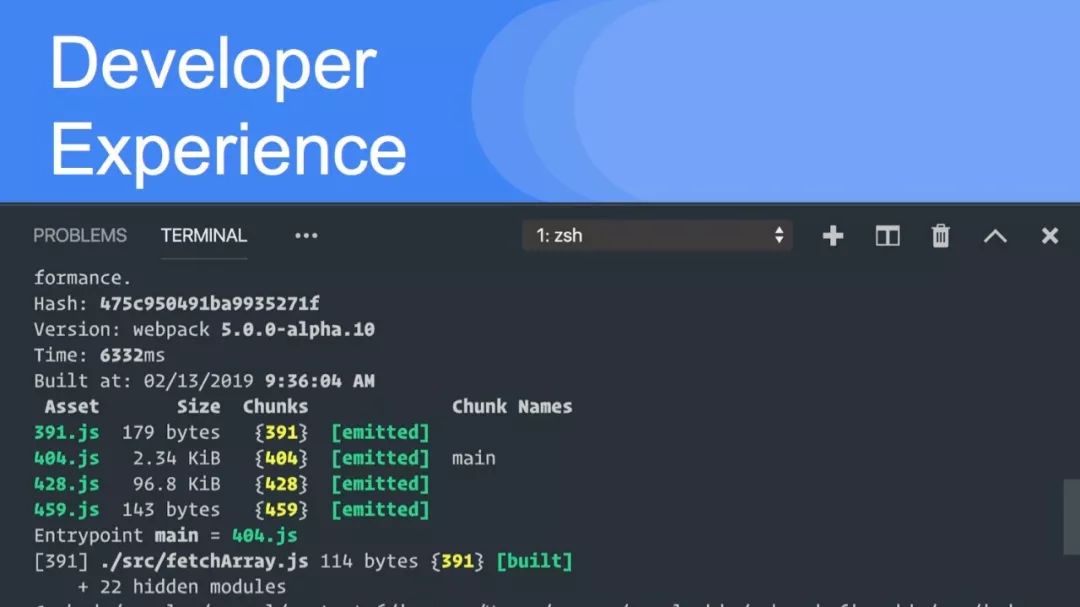
先简单地概述一下webpack的工作原理:webpack读取入口文件(entry),然后递归查找所依赖的模块(module),构建成一个“依赖图”,然后根据配置中的加载器(loader)和打包策略来对模块进行编译。
但是如果中间有文件发生变化了,上面所述的整个递归遍历流程会重新再进行一次。
大致流程如下:


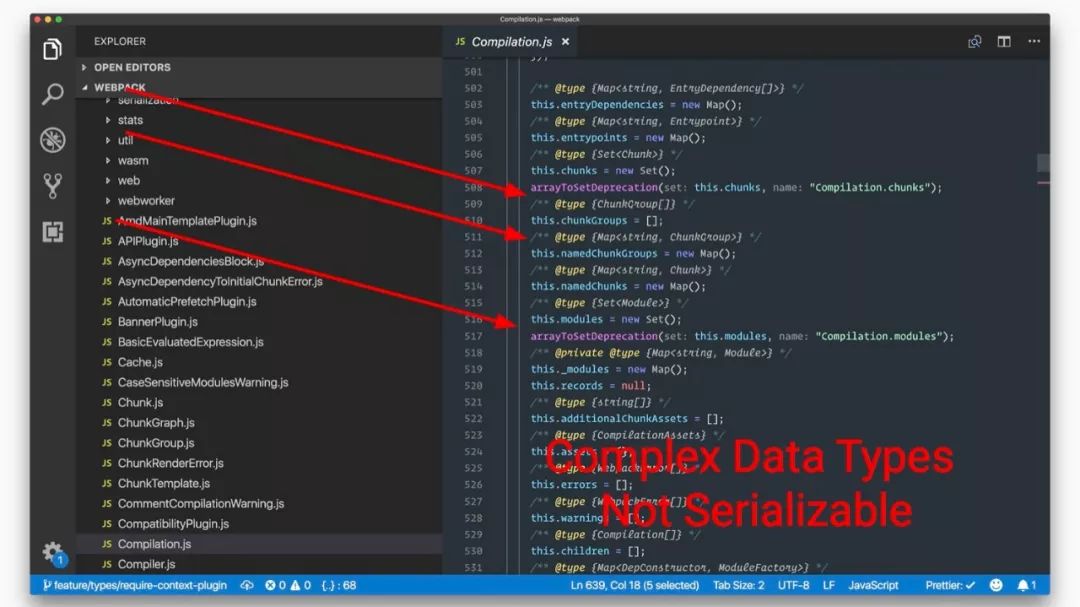


webpack 5利用持久缓存优化了整个流程,当检测到某个文件变化时,依照“依赖图”,只对修改过的文件进行编译,从而大幅提高了编译速度。
经过测试,16000模块的单页应用,速度可以提高98%




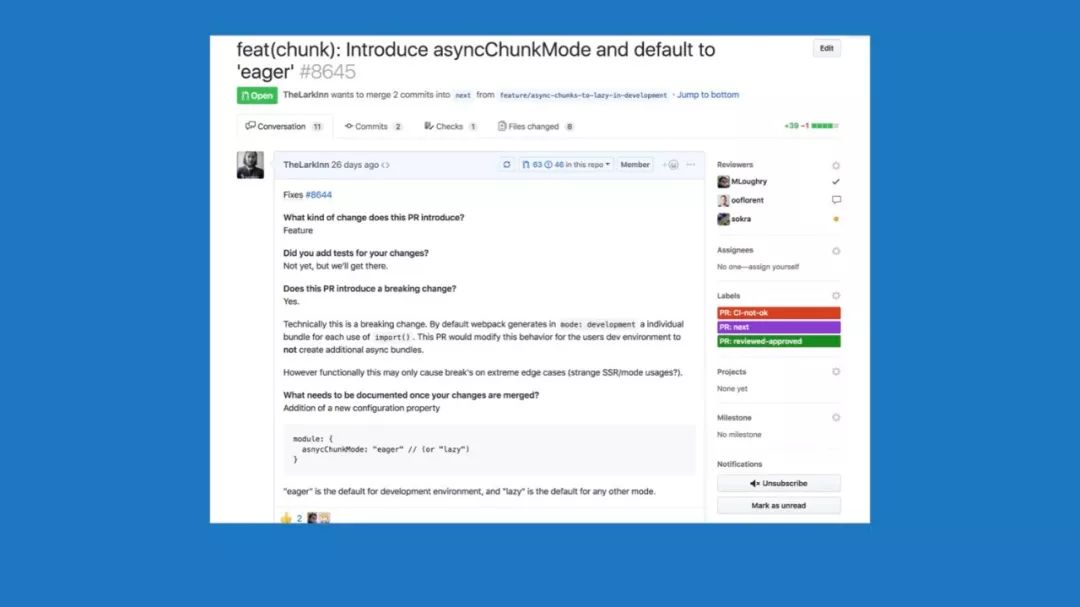
引入了更多新东西
webpack 5 要求node的最低版本为 Node 8。不再是之前的Node 6。
另外,webpack 5还引入了webAssembly、Hashing、多线程、还有workers。



命名IDs
默认情况下,在开发模式下启用了一个新命名的块id算法,该算法提供块(和文件名)供人阅读的引用。模块ID由其相对于上下文的路径决定。一个块ID是由块的内容决定的,所以你不再需要使用:
import(/* webpackChunkName: "name" */ "module")上面的行可以用于调试,但是如果您想要控制生产环境的文件名,那么这也是有意义的。在生产中使用chunkIds:“named”是有可能的,只是要确保不要意外地暴露有关模块名称的敏感信息。
optimization: { chunkIds: 'named' }从v4迁移时,您可能会发现不喜欢在开发模式中更改文件名。记住这一点,您可以传递下面的行,以便从配置文件中使用旧的数值模式。
chunkIds: “natural”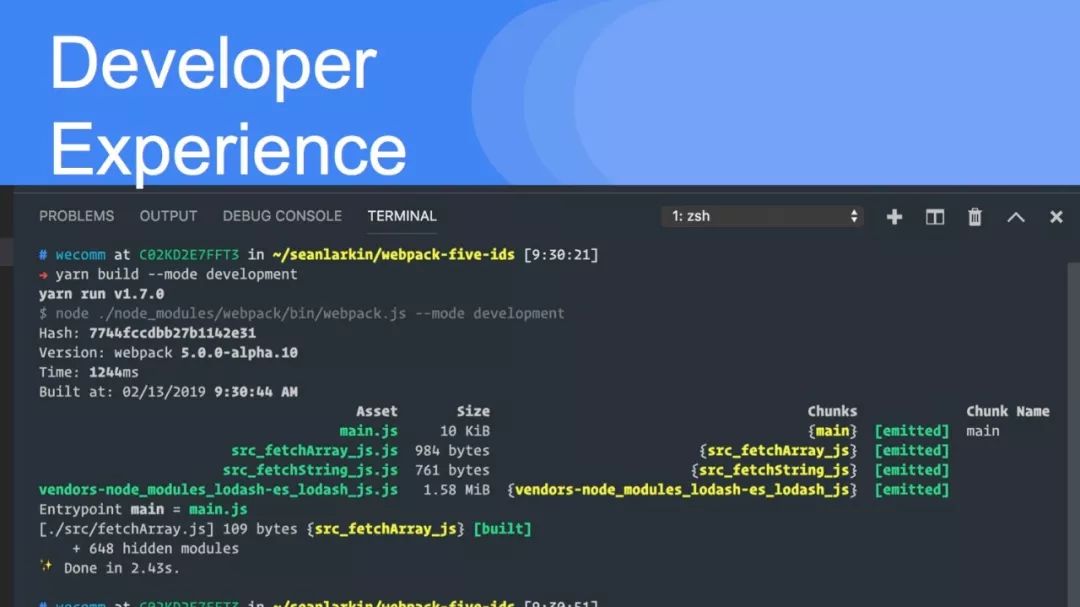
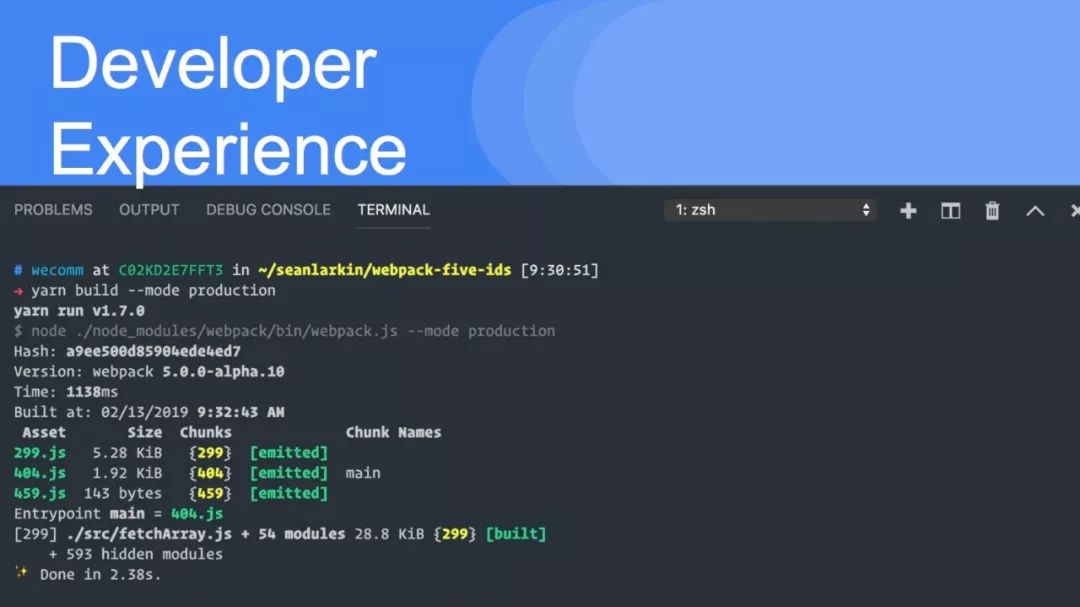
为了增强long-term caching,增加了新的算法,并在生产模式下使用以下配置开启:
chunkIds: "deterministic”,
moduleIds: “deterministic"这些算法以确定性的方式为模块和数据块分配非常短(3或4个字符)的数字 id。这是捆绑包大小和长期缓存之间的权衡。从 v4迁移时,最好使用 chunkIds 和 moduleIds 的默认值。你也可以从配置文件中选择旧的默认设置:
chunkIds: "size”,
moduleIds: “size"这些行将生成较小的 bundle,但由于缓存的原因,它们更经常地失效。

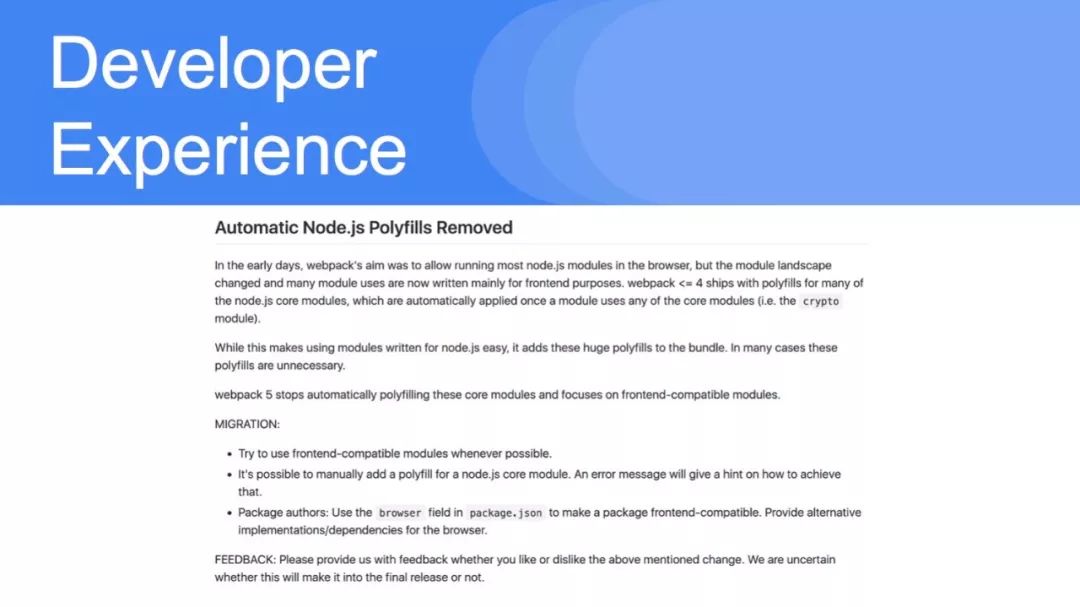
NodeJS的polyfill脚本被移除
在过去,Webpack的目标是允许在浏览器中运行大多数Node.js模块,但是模块环境发生了变化,现在许多模块的使用都是专门为前端目的编写的。版本<= 4随polyfills一起提供给大多数Node.js核心模块,这些模块一旦使用任何核心模块,就会自动应用。
这反过来又将这些大型填充添加到最终的包中,但通常是不必要的。v5中的尝试是自动停止填充这些核心模块,并将重点放在前端兼容的模块上。
在迁移到v5时,最好尽可能使用前端兼容的模块,并在可能的情况下手动为核心模块添加一个polyfill(错误消息可以帮助指导您)。对于核心团队来说,反馈是值得赞赏/鼓励的,因为这个变更可能会进入最终的v5版本,也可能不会。





着急想看视频的话可以在油管上先看看:https://www.youtube.com/watch?v=J_sDa58UUQo
参考:https://blog.logrocket.com/new-features-in-webpack-5-2559755adf5e/
为你推荐
以上是关于PPTthe road to webpack 5的主要内容,如果未能解决你的问题,请参考以下文章
pytorch 笔记: 复现论文 Stochastic Weight Completion for Road Networks using Graph Convolutional Networks(代