专知荟萃24视频描述生成(Video Captioning)知识资料全集(入门/进阶/论文/综述/代码/专家,附查看)
Posted 专知
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了专知荟萃24视频描述生成(Video Captioning)知识资料全集(入门/进阶/论文/综述/代码/专家,附查看)相关的知识,希望对你有一定的参考价值。
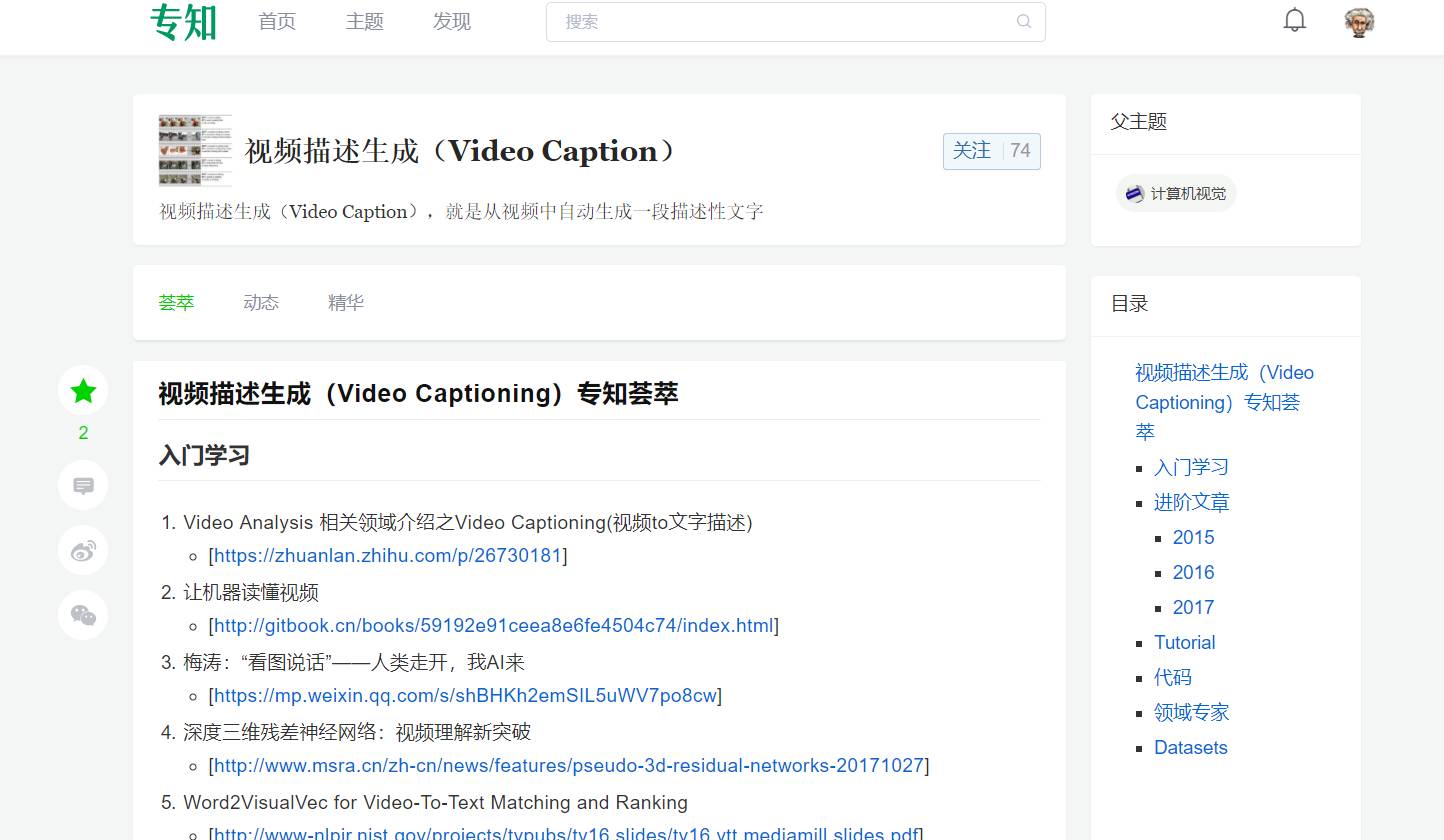
视频描述生成(Video Captioning)专知荟萃
入门学习
进阶文章
2015
2016
2017
Tutorial
代码
领域专家
Datasets
Video Analysis 相关领域介绍之Video Captioning(视频to文字描述)
[https://zhuanlan.zhihu.com/p/26730181]
让机器读懂视频
[http://gitbook.cn/books/59192e91ceea8e6fe4504c74/index.html]
梅涛:“看图说话”——人类走开,我AI来
[]
深度三维残差神经网络:视频理解新突破
[http://www.msra.cn/zh-cn/news/features/pseudo-3d-residual-networks-20171027]
Word2VisualVec for Video-To-Text Matching and Ranking
[http://www-nlpir.nist.gov/projects/tvpubs/tv16.slides/tv16.vtt.mediamill.slides.pdf]
Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrell, Long-term Recurrent Convolutional Networks for Visual Recognition and Description, CVPR, 2015.
- [http://arxiv.org/pdf/1411.4389.pdf]Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko, Translating Videos to Natural Language Using Deep Recurrent Neural Networks, arXiv:1412.4729.
UT / UML / Berkeley [http://arxiv.org/pdf/1412.4729]
Yingwei Pan, Tao Mei, Ting Yao, Houqiang Li, Yong Rui, Joint Modeling Embedding and Translation to Bridge Video and Language, arXiv:1505.01861.
Microsoft [http://arxiv.org/pdf/1505.01861]
Subhashini Venugopalan, Marcus Rohrbach, Jeff Donahue, Raymond Mooney, Trevor Darrell, Kate Saenko, Sequence to Sequence--Video to Text, arXiv:1505.00487.
UT / Berkeley / UML [http://arxiv.org/pdf/1505.00487]
Li Yao, Atousa Torabi, Kyunghyun Cho, Nicolas Ballas, Christopher Pal, Hugo Larochelle, Aaron Courville, Describing Videos by Exploiting Temporal Structure, arXiv:1502.08029
Univ. Montreal / Univ. Sherbrooke [http://arxiv.org/pdf/1502.08029.pdf]]
Anna Rohrbach, Marcus Rohrbach, Bernt Schiele, The Long-Short Story of Movie Description, arXiv:1506.01698
MPI / Berkeley [http://arxiv.org/pdf/1506.01698.pdf]]
Yukun Zhu, Ryan Kiros, Richard Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, Sanja Fidler, Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books, arXiv:1506.06724
Univ. Toronto / MIT [[http://arxiv.org/pdf/1506.06724.pdf]]
Kyunghyun Cho, Aaron Courville, Yoshua Bengio, Describing Multimedia Content using Attention-based Encoder-Decoder Networks, arXiv:1507.01053
Univ. Montreal [http://arxiv.org/pdf/1507.01053.pdf]
Multimodal Video Description
[https://dl.acm.org/citation.cfm?id=2984066]
Describing Videos using Multi-modal Fusion
[https://dl.acm.org/citation.cfm?id=2984065]
Andrew Shin , Katsunori Ohnishi , Tatsuya Harada Beyond caption to narrative: Video captioning with multiple sentences
[http://ieeexplore.ieee.org/abstract/document/7532983/]
Jianfeng Dong, Xirong Li, Cees G. M. Snoek Word2VisualVec: Image and Video to Sentence Matching by Visual Feature Prediction
[https://pdfs.semanticscholar.org/de22/8875bc33e9db85123469ef80fc0071a92386.pdf]
Dotan Kaufman, Gil Levi, Tal Hassner, Lior Wolf, Temporal Tessellation for Video Annotation and Summarization, arXiv:1612.06950.
TAU / USC [[https://arxiv.org/pdf/1612.06950.pdf]]
Chiori Hori, Takaaki Hori, Teng-Yok Lee, Kazuhiro Sumi, John R. Hershey, Tim K. Marks Attention-Based Multimodal Fusion for Video Description
[https://arxiv.org/abs/1701.03126]
Weakly Supervised Dense Video Captioning(CVPR2017)
Multi-Task Video Captioning with Video and Entailment Generation(ACL2017)
Multimodal Memory Modelling for Video Captioning, Junbo Wang, Wei Wang, Yan Huang, Liang Wang, Tieniu Tan
[https://arxiv.org/abs/1611.05592]
Xiaodan Liang, Zhiting Hu, Hao Zhang, Chuang Gan, Eric P. Xing Recurrent Topic-Transition GAN for Visual Paragraph Generation
[https://arxiv.org/abs/1703.07022]
MAM-RNN: Multi-level Attention Model Based RNN for Video Captioning Xuelong Li1 , Bin Zhao2 , Xiaoqiang Lu1
[https://www.ijcai.org/proceedings/2017/0307.pdf]
“Bridging Video and Language with Deep Learning,” Invited tutorial at ECCV-ACM Multimedia, Amsterdam, The Netherlands, Oct. 2016.
[https://www.microsoft.com/en-us/research/publication/tutorial-bridging-video-language-deep-learning/]
ICIP-2017-Tutorial-Video-and-Language-Pub
[https://www.microsoft.com/en-us/research/wp-content/uploads/2017/09/ICIP-2017-Tutorial-Video-and-Language-Pub.pdf]
neuralvideo
[https://github.com/olivernina/neuralvideo]
Translating Videos to Natural Language Using Deep Recurrent Neural Networks
[ https://www.cs.utexas.edu/~vsub/naacl15_project.html#code\]
Describing Videos by Exploiting Temporal Structure
[https://github.com/yaoli/arctic-capgen-vid]
SA-tensorflow: Soft attention mechanism for video caption generation
[https://github.com/tsenghungchen/SA-tensorflow]
Sequence to Sequence -- Video to Text
[https://github.com/jazzsaxmafia/video_to_sequence\]
梅涛 微软亚洲研究院资深研究员梅涛博士,微软亚洲研究院资深研究员,国际模式识别学会会士,美国计算机协会杰出科学家,中国科技大学和中山大学兼职教授博导。主要研究兴趣为多媒体分析、计算机视觉和机器学习。 - [https://www.microsoft.com/en-us/research/people/tmei/]
Xirong Li 李锡荣 中国人民大学数据工程与知识工程教育部重点实验室副教授、博士生导师。
[http://lixirong.net/]
Jiebo Luo IEEE/SPIE Fellow、长江讲座美国罗彻斯特大学教授
[http://www.cs.rochester.edu/u/jluo/]
Subhashini Venugopalan
[https://www.cs.utexas.edu/~vsub/\]
[https://www.microsoft.com/en-us/research/publication/msr-vtt-large-video-description-dataset-bridging-video-language-supplementary-material/]
[http://ms-multimedia-challenge.com/]
[http://www.cs.utexas.edu/users/ml/clamp/videoDescription/]
视频描述生成(Video Captioning)专知荟萃
入门学习
进阶文章
2015
2016
2017
Tutorial
代码
领域专家
Datasets
特别提示-专知视频描述生成主题:
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录,顶端搜索“视频描述生成” 主题,获得专知荟萃全集知识等资料,直接PC端访问体验更佳!如下图所示~
请扫描专知小助手,加入专知人工智能群交流~

-END-
专 · 知
人工智能领域主题知识资料查看获取:
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
点击“阅读原文”,使用专知!
以上是关于专知荟萃24视频描述生成(Video Captioning)知识资料全集(入门/进阶/论文/综述/代码/专家,附查看)的主要内容,如果未能解决你的问题,请参考以下文章
Video Diffusion Models:基于扩散模型的视频生成
文本生成视频Make-A-Video,根据一句话就能一键生成视频 Meta新AI模型
文本生成视频Make-A-Video,根据一句话就能一键生成视频 Meta新AI模型