使用IDEA搭建Spark源码阅读环境
Posted 大数据与算法的学习历程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用IDEA搭建Spark源码阅读环境相关的知识,希望对你有一定的参考价值。
闲话一分钟
首先建议大家首先有一定的Spark基础,再来看源码。相信会学到更多的东西,尤其是整个app的运行过程,Spark的运行流程。
今天弄了一天,总算是弄好了。花费时间最多的就是在编译Spark。整个过程不是在排错就是在排错的路上。话不多说,直接说具体怎么搭建,同时也方便自己以后查阅。
准备工作:安装并下载一些必要的工具,本人使用的操作系统是Win10
1. Java1.8
2.Scala2.11.12
3.Maven3.5.3
4.git2.17.0
5.Spark2.2.1源码
6.Intellij IDEA 2017
Spark源码下载:
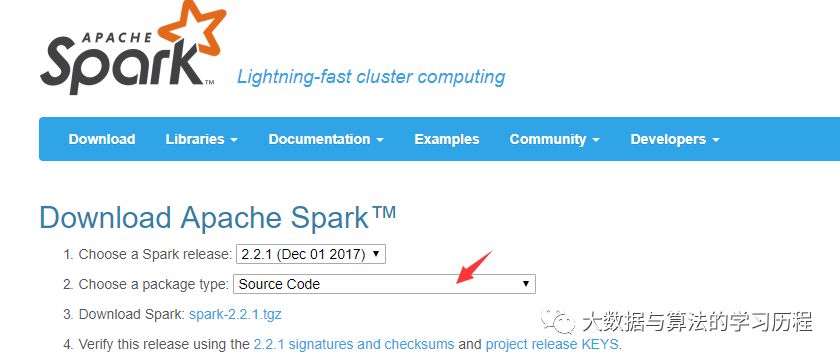
选择Source Code进行源码下载。
开始编译Spark
下载好源码之后,然后将其解压,使用cmd命令,进入到Spark的源码目录下进行mvn的编译。

在这里我们介绍下一个少走坑路的命令,我也是踩了很多坑才在StackOverflow上找到的。
使用命令:mvn -Dscala-2.11.12 -DskipTests clean package
进行Spark的编译,在这里指定自己下载安装好的Scala版本,主要是防止和spark里面的Scala版本不一致。
在编译过程中遇到的错误:
org.apache.maven.plugins:maven-antrun-plugin:1.8:run
这个错误antrun。主要原因是git没有安装,如果安装了git环境,就将git的bin目录添加到环境变量中Path下。
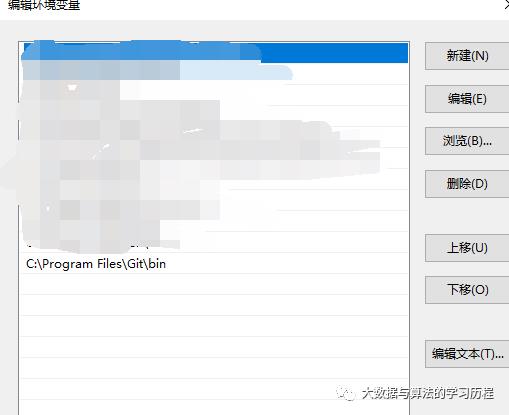
如果遇见其他的错误,比如说在编译过程中,SparkSQL编译失败了,说什么找不到之类的,忽略,然后重新执行该命令进行编译,可能有时候是因为网咯原因,导致一些jar包没有下载下来。重新运行就好了。我是这样解决的。
反复执行了好几次吧。然后终于编译成功了。
然后使用IDEA打开源代码编译后的目录。
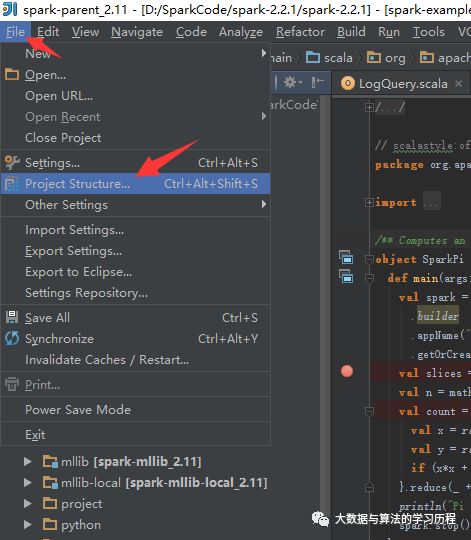
菜单栏--> File --> Open --> 选择根目录下的pom.xml。然后确定就行了,等待idea加载环境。
运行demo代码:
在这里我们运行Pi这个例子。
首先我们先将依赖工程依赖添加进去。
添加Scala依赖
然后能打开这样一个窗口。
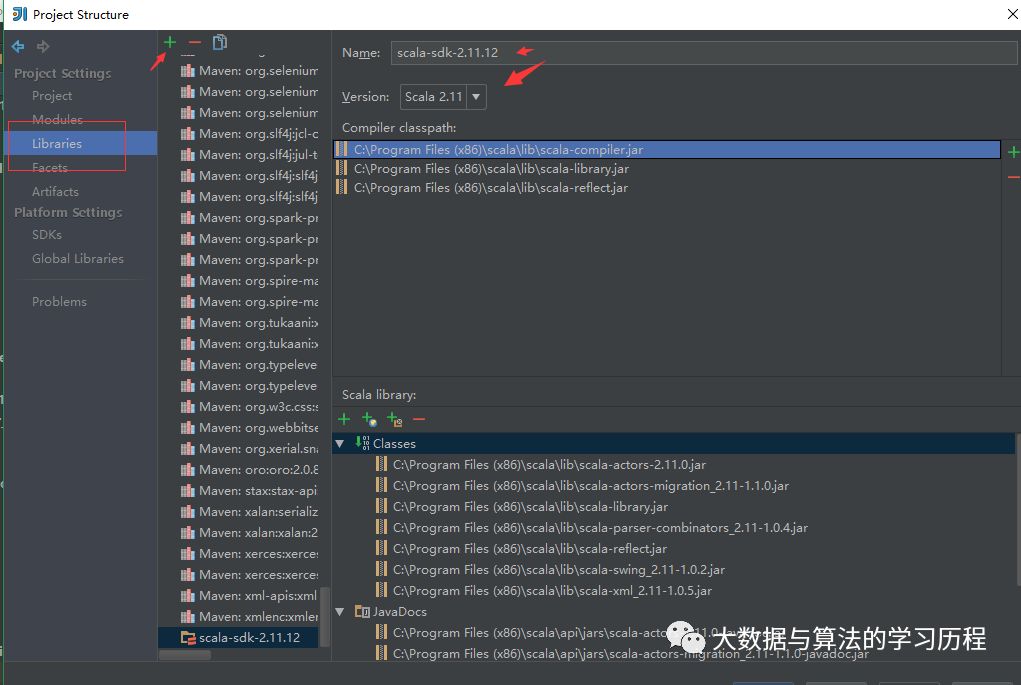
在这里可以添加Java依赖也可以添加Scala的依赖。
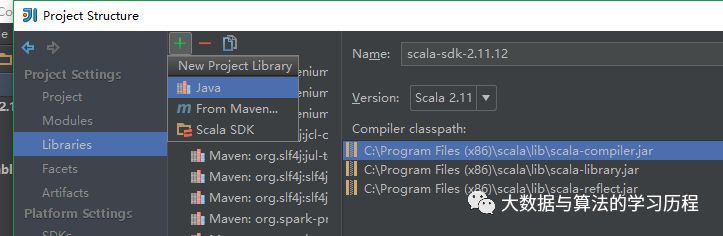
然后我们还需要添加scala的一些依赖Jar。
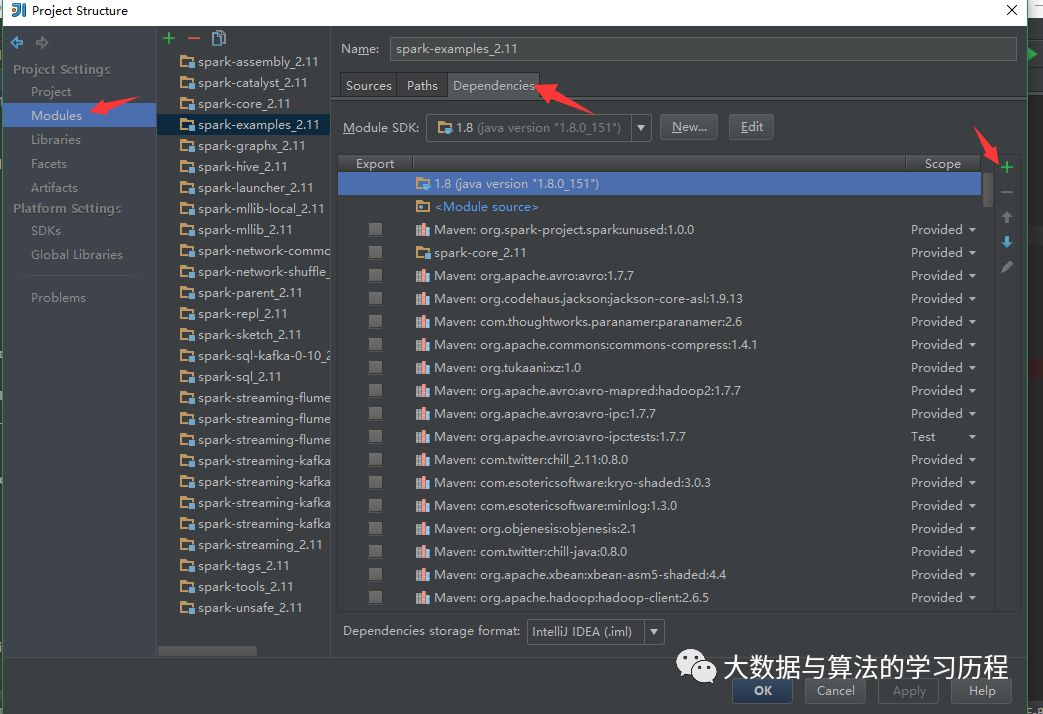
然后选择Spark根目录下的assembly/target/scala-2.11/jars/
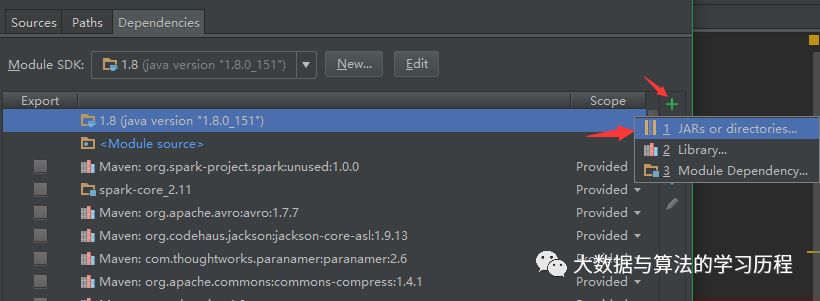
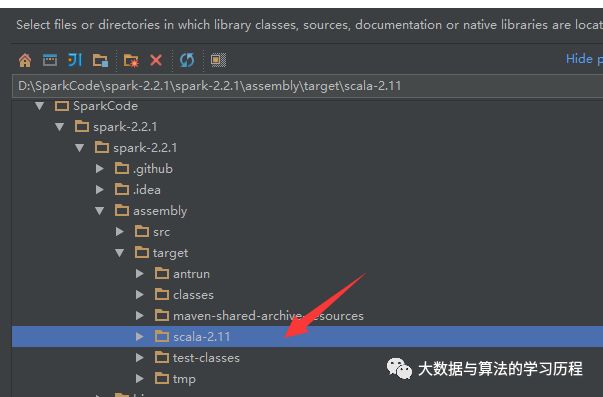
就ok拉。
做好这些之后,我们就开始运行Pi程序吧。
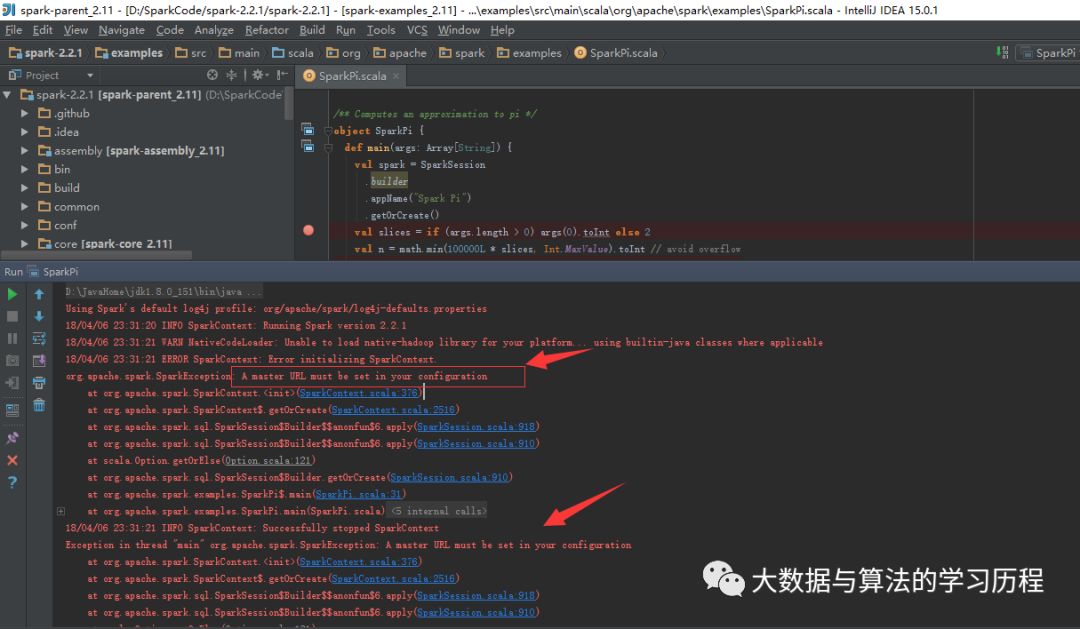
他说我们没有指定MasterURL,需要在config中配置。
RUN --> Edit Configurations
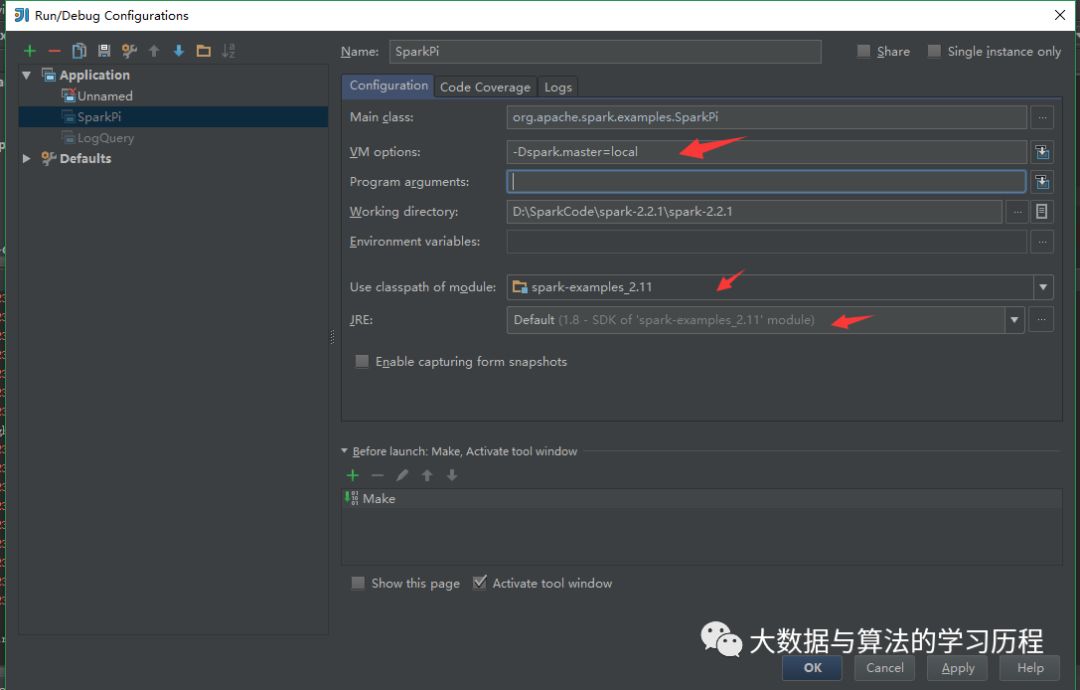
然后运行。
这样我们的PI就出来了。
我试过也是可以的哈。
然后就可以单步调试代码,阅读源码了。
以上是关于使用IDEA搭建Spark源码阅读环境的主要内容,如果未能解决你的问题,请参考以下文章