搜索引擎蜘蛛Spider的分类
Posted 孔生SEO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎蜘蛛Spider的分类相关的知识,希望对你有一定的参考价值。
Spider的分类
按照现在网络上所有 Spider的作用及表现出来的特征,可以将其分为3类:批量型 Spider增量型 Spider和垂直型 Spider。
1、批量型 Spider
一般具有明显的抓取范围和目标,设置抓取时间的限制、抓取数据量的限制或抓取固定范围内页面的限制等,当 Spider的作业达到预先设置的目标就会停止。普通站长和SEO人员使用的采集工具或程序,所派出的 Spider大都属于批量型 Spider,一般只抓取固定网站的固定内容,或者设置对某一资源的固定目标数据量,当抓取的数据或者时间达到设置限制后就会自动停止,这种 Spider就是很典型的批量型 Spider。
2、增量型 Spider
增量型 Spider也可以称之为通用爬虫。一般可以称为搜索引擎的网站或程序,使用的都是增量型 Spider,,但是站内搜索引擎除外,自有站内搜索引擎一般是不需要 Spider的。增量型 Spider和批量型 Spider不同,没有固定目标、范围和时间限制,一般会无休止地抓取下去,直到把全网的数据抓完为止。增量型 Spider不仅仅抓取尽可能全的页面,还要对已经抓取到的页面进行相应的再次抓取和更新。因为整个互联网是在不断变化的,单个网页上的内容可能会随着时间的变化不断更新,甚至在一定时间之后该页面会被删除,优秀的增量型 Spider需要及时发现这种变化,并反映给搜索引擎后续的处理系统,对该网页进行重新处理。当前百度、 Google网页搜索等全文搜索引擎的 Spider,一般都是增量型 Spider。
3、垂直型 Spider
垂直型 Spider也可以称之为聚焦爬虫,只对特定主题、特定内容或特定行业的网页进行抓取,一般都会聚焦在某一个限制范围内进行增量型的抓取。此类型的 Spider不像增量型Spider一样追求大面广的覆盖面,而是在增量型 Spider上增加一个抓取网页的限制,根据需求抓取含有目标内容的网页,不符合要求的网页会直接被放弃抓取。对于网页级别纯文本内容方面的识别,现在的搜索引 Spider还不能百分之百地进行准确分类,并且垂直型 Spider也不能像增量型 Spider那样进行全互联网爬取,因为那样太浪费资源。所以现在的垂直搜索引擎如果有附属的增量型 Spider,那么就会利用增量型 Spider以站点为单位进行内容容分类,然后再派出垂直型用人工添加抓取站点的方式来引导垂直型 Spider作业业。当然在同一个站点内也会存在不同的内容,此日时垂直型 Spider也需要进行内容判断析,但是工作量相对来说已经缩减优化了很多。现在淘网、优酷下的搜库、百度和 Google等大型搜索引擎下的垂直搜索使用的都是垂直型 Spider虽然现在使用比较广泛的垂直型 Spider对对网页的识别度已经很高,但是总会有些不足,这也使得垂直类搜索引擎上的SEO有了很大进步空间。
本书主要讨论网页搜索的的SEO,所以讨论的内容以增量型 Spider为主,也会简单涉及垂直型 Spider方面的内容,其实垂直型 Spider完全可以看作是做了抓取限制的增量型 Spider。
Spider的抓取策略
在大型搜索引擎 Spider的抓取过程中会有很多策略,有时也可能是多种策略综合使用。里简单介绍一下比较简单的Spdr抓取策略,以辅助大家对 Spider工作流程的理解。 Spider序一般会建立已抓取URL列表和待抓取URL列表(实际中是由哈希表来记录URL的两个状进行逐一对比,如果发现该链接已经抓取过过,就会直接去弃,如果发现该链接还未抓取把该链接放到待抓取URL队列列的末尾等待抓取。
Spider的眼中的互联网网页可以分为以下四类,如图所示:
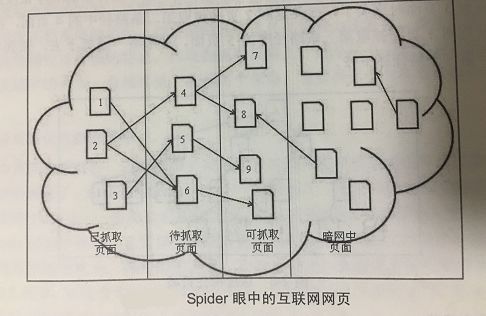
(1)已经抓取过的页面,即 Spider已经抓取过的页面。
(2)待抓取页面,也就是这些页面的URL已经被 Spider加入到了待抓取URL队列中,只
是还没有进行抓取。
(3)可抓取页面, Spider根据互联网上的链接关系最终是可以找到这些页面的,也就是说当下可能还不知道这些页面的存在,但是随着增量型 Spider的抓取,最终会发现这些页面的存在。
(4)暗网中的页面,这些网页和表层网络上的网页是脱钩的,可能这些页面中有链接指向能获得的网页,就属于暗网中的网页。据估计暗网网页要比非暗网网页大几个数量级。
全文搜索引擎的 Spider一直致力于抓取全网的数据,现在 Spider对于非暗网网页已经具备大量高效的抓取策略。对于暗网的抓取,各个搜索引擎都在努力研究自己不同的暗网Spider抓的形式提交给百度,百度会直接进行抓取和优先排名显示。这里主要讨论 Spider针对非暗网中网页的抓取策略。
当 Spider从一个入口网页开始抓取时,会获得这个页面上所有的导出链接,当 Spider随机抓取其中的一个链接时,同样又会收集到很多新的链接。此时 Spider面临一个抓取方式的选择:
(1)先沿着一条链接一层一层地抓取下去,直到这个链接抓到尽头,再返回来按照同样的规则抓取其他链接,也就是深度优先抓取策略。
(2)还是先把入口页面中的链接抓取一遍,把新发现的URL依次进行入库排列,然后对这些新发现的页面进行遍历抓取,再把最新发现的URL进行入库排列等待抓取,依次抓取下去,也就是广度优先抓取策略。
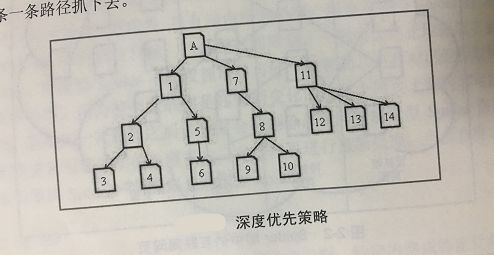
①深度优先策略
深度优先策略即一条道走到黑,当沿着一个路径走到无路可走时,再返回来走另一条路。如图所示所示为深度优先抓取策略的示意图,假设A页面为 Spider的入口, Spider在A页面上发现了1、7、111三个页面的链接,然后 Spider会按照图中数字所标示的顺序依次进行抓取。当第一条路径抓到3页面时到头了,就会返回2页面抓取第二条路径中的4页面,在4页面也抓到头了,就会返回1页面抓取第三条路径中的5页面,并顺着一路抓下去,抓到头后会按照之的规则沿一条一条路径抓下去。
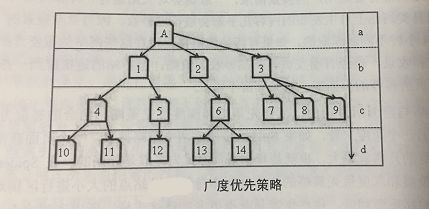
②广度优先策略
广度优先策略即Spider在一个页面上发现多个链接时,并不是一条道走到黑,顺着一个链接接继续抓下去,而是先把这些页面抓一遍,然后再抓从这些页面中提取下来的链接。如图所示为广度优先抓取策略的的示意图,假设A页面为 Spider的入口,Spider在A页面上发现了1不会继续抓1页页面中的其他链接,而是抓2页面。当b级页面抓取完成时,才会抓取从b级页面中提取到c级页面中的4、5、6、7、8、9六个页面,等c级页面抓取完成后,再抓取从c级页面中提取到的d级新页面,依次持续抓取下去。
理论上 Spider不论采用深度优先策略还是广度优先策略,只要时间足够,都可以把整个互联网上的网页抓取一遍。但是搜索引本身的资源也是有限的,快速抓取全互联网有价值的页用两种策略相结合的方式来进行抓取。一般 Spider可以在域名级别的页面使用广度优先抓取策先抓取策略,也就是说网站的权重越高,抓取量也会越大,刚上线的网站可能只会被抓一个首页。这也是很多新网站在一定时间内,在搜索引擎中只首页被索引的原因之一。
上面讨论的两个策略是站在 Spider只是单纯想抓取全互联网数据的基础上,所需要选择的所以在尽力抓取全网的同时,还要考虑对重要页面的优先抓取。这个“重要页面”的定义应该比较多或时效传播性比较强的特点。体现到抓取策略上,就是这个页面的导入链接很多,或者是权重高的大站中的网页。总结来说,就是两个策略:重要网页优先抓取策略和大站链接优先抓取策略。
(1)重要页面优先抓取策略
般认为页面的重要性,除了受寄主站点本身的质量和权重影响以外,就看导入链接的多少和导入链接的质量了。 Spider抓取层面上的“重要页面”一般由导入的链接来决定。在前面所讨论的抓取策略中, Spider一般都会把新发现的未抓取过的URL依次放到待抓取URL队列的尾端,等待 Spider按顺序抓取。在重要页面优先抓取的策略中就不是这样的了,这个待抓取URL队列的顺序是在不断变化的。排序的依据是:页面获得的已抓取页面链接的多少和链接权重的高低。如图所示,按照普通的抓取策略, Spider的抓取顺序应该是1、2、3、4、5、6、7使用重要页面优先策略后,待抓取页面的排序将变成6、4、5......。
(2)大站优先策略
大站优先策略,这个思路很简单。被搜索引引擎认定为“大站”的的网站,一定有着稳定的服务器、良好的网站结构、优秀的用户体验、及时的资讯内容、权威威的相关资料、丰富的内容类型和庞大的网页数量等特征,当然也会相应地拥有大量高质量的外链。也就是在一定程度上可以认定这些网站的内容就可以满足相当比例网民的搜素请求,搜索引擎为了在有限的资源内尽最大的努力满足大部分普通用户的搜索需求,一般就会对大站进行“特殊照顾”。因此大家可以看到新浪、网易类网站上自主发布的内容几乎都会被百度秒收,因为百度搜索的 Spider在这些网站上是7×24小时不间断抓取的。如果有新站的链接出现在这些网站的重要页面上,也会相应地被快速抓取和收录。曾经有朋友试验新站秒收的策略:把新站的链接推到一些大站的首页,或挂到大站首页所推荐的页面中,效果非常不错。
这两个策略与前面所讨论的广度优先策略和深度优先策略相结合的抓取方式是有共同点的。比如,从另一个角度来看,如果 Spider按照前两个策略抓取,一个页面获得的导入链接越多,被提前抓到的几率就越大,也就是和重要页面优先抓取是趋同的;在 Spider资源有限的情况下广度优先策略和深度优先策略的结合分配本身就会以站点的大小进行区别对待,大网站的页面有着先天的高重要程度,往往也容易获得更多的链接支持。所以宏观来看,这几个策略在抓取表现上有相近之处,在实际的抓取过程中相辅相成。
相对于整个互联网的网页来说, Spider的资源再充足也是有限的,所以优秀的 Spider程序应该首先保证对重要网页的抓取,然后オ是尽力抓取尽可能全的互联网网页信息。由此也可以看出依靠外部链接来引导 Spider和提升网站权重,以及依靠内容长期运营网站权重的重要性。
以上是关于搜索引擎蜘蛛Spider的分类的主要内容,如果未能解决你的问题,请参考以下文章
SEO优化蜘蛛spider的抓取方式-专业SEO技术教程(11)