爬虫技术,你可以成为互联网上的spiderman
Posted 达内首都教学部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫技术,你可以成为互联网上的spiderman相关的知识,希望对你有一定的参考价值。


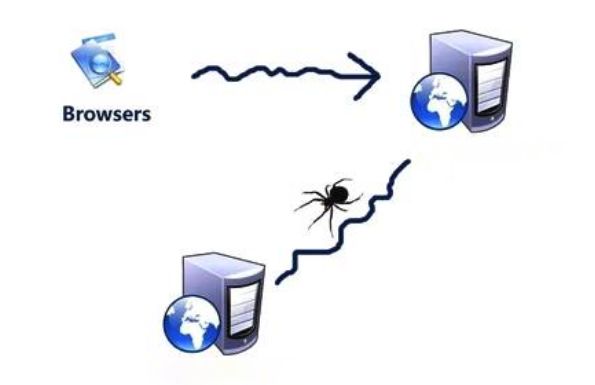
1. 爬虫现在已经不陌生了,说白了就是像浏览器一样获取网络上的信息,只不过我们的浏览器是没有界面的,这样会更加快捷方便。

2. 爬虫比浏览器强大的地方在于很快速的解析多个任意网页甚至网页内容。而我们的浏览器只能一次访问一个网页。
3. 爬虫可以搜索出特定信息内容,比如图片 视频 商品价格等等。



目前不同的编程语言都有各自的爬虫技术,比如python的urllib原生解析网页。其实java也有很多爬虫技术。
Java爬虫有以下几种技术
最简单的一种爬虫技术
Nutch属于分布式爬虫,爬虫使用分布式,主要是解决两个问题:1)海量URL管理;2)网速。如果要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎,否则尽量不要选择Nutch作为爬虫。用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。

WebCollector使用了Nutch的爬取逻辑(分层广度遍历),Crawler4j的的用户接口(覆盖visit方法,定义用户操作),以及一套自己的插件机制,设计了一套爬虫内核。
Heritrix 是个“Archival Crawler”——来获取完整的、精确的、站点内容的深度复制。包括获取图像以及其他非文本内容。抓取并存储相关的内容。对内容来者不拒,不对页面进行内容上的修改。重新爬行对相同的URL不针对先前的进行替换。爬虫主要通过Web用户界面启动、监控和调整,允许弹性的定义要获取的url

crawler4j是Java实现的开源网络爬虫。提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫
WebMagic项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。


1、确定一个(多个)种子网页
2、进行数据的内容提取
3、将网页中的关联网页连接提取出来
4、将尚未爬取的关联网页内容放到一个队列中
5、从队列中取出一个待爬取的页面,判断之前是否爬过。
6、把没有爬过的进行爬取,并进行之前的重复操作。
7、直到队列中没有新的内容,爬虫执行结束。


一般来说,表示从种子页到当前页的打开连接数,一般建议不要超过5层。
表示爬取时的优先级。建议使用广度优先,按深度的层级来顺序爬取。
往期回顾:
以上是关于爬虫技术,你可以成为互联网上的spiderman的主要内容,如果未能解决你的问题,请参考以下文章