Eureka三级缓存
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Eureka三级缓存相关的知识,希望对你有一定的参考价值。
参考技术A Eureka Server存在三个变量:(registry、readWriteCacheMap、readOnlyCacheMap)保存服务注册信息,默认情况下定时任务每30s将readWriteCacheMap同步至readOnlyCacheMap,每60s清理超过90s未续约的节点,Eureka Client每30s从readOnlyCacheMap更新服务注册信息,而UI则从registry更新服务注册信息。三级缓存读取顺序:
默认读取只读map,如果只读map没有,则读取读写map,如果读写map也没有,就读取registry本地注册表缓存。
通过 eureka.server.response-cache-update-interval-ms 参数来设置,如果不设置,默认是30秒(每 30s 从二级缓存向三级缓存同步数据),如下图:
结论:在接受客户端注册的时候,服务端会将读写缓存的key清掉,30s后只读缓存从读写缓存拉取数据的时候,该服务列表获取到的是最新的数据。如果客户端下线,同样地,读写缓存也会被清除掉。所以极端情况,最长30s后,客户端才能获取到最新的服务列表。
参考连接:
https://www.cnblogs.com/shihaiming/p/11590748.html
Spring三级缓存
Spring三级缓存
循环依赖
循环依赖如下图所示:
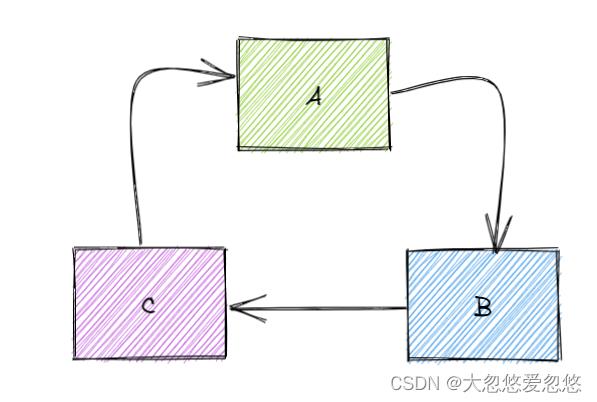
对应的spring代码形式如下:
@Component
public class A
@Autowired
private B b;
@Component
public class B
@Autowired
private C c;
@Component
public class C
@Autowired
private A a;
又或者:
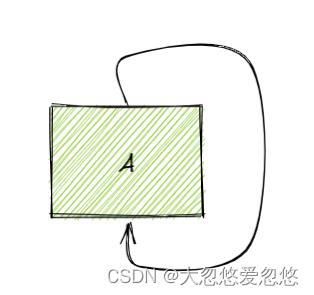
对应的spring代码形式如下:
@Component
public class A
@Autowired
private A a;
上面展示的循环依赖都是Spring可以解决的,但是对于构造器的循环依赖注入,Spring无法解决,会抛出异常:
@Component
public class A
private B b;
public A(B b)
this.b = b;
@Component
public class B
private A a;
public B(A a)
this.a = a;
对于Prototype类型的bean来说,如果存在循环引用也是会直接抛出异常结束
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
@Service
public class A
@Autowired
private B b;
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
@Service
public class B
@Autowired
private A a;
如何解决循环依赖
在正式研究Spring如何解决循环依赖之前,不如我们就假设spring目前没有提供三级缓存来解决循环依赖,那么目前spring的getBean流程图就如下所示:
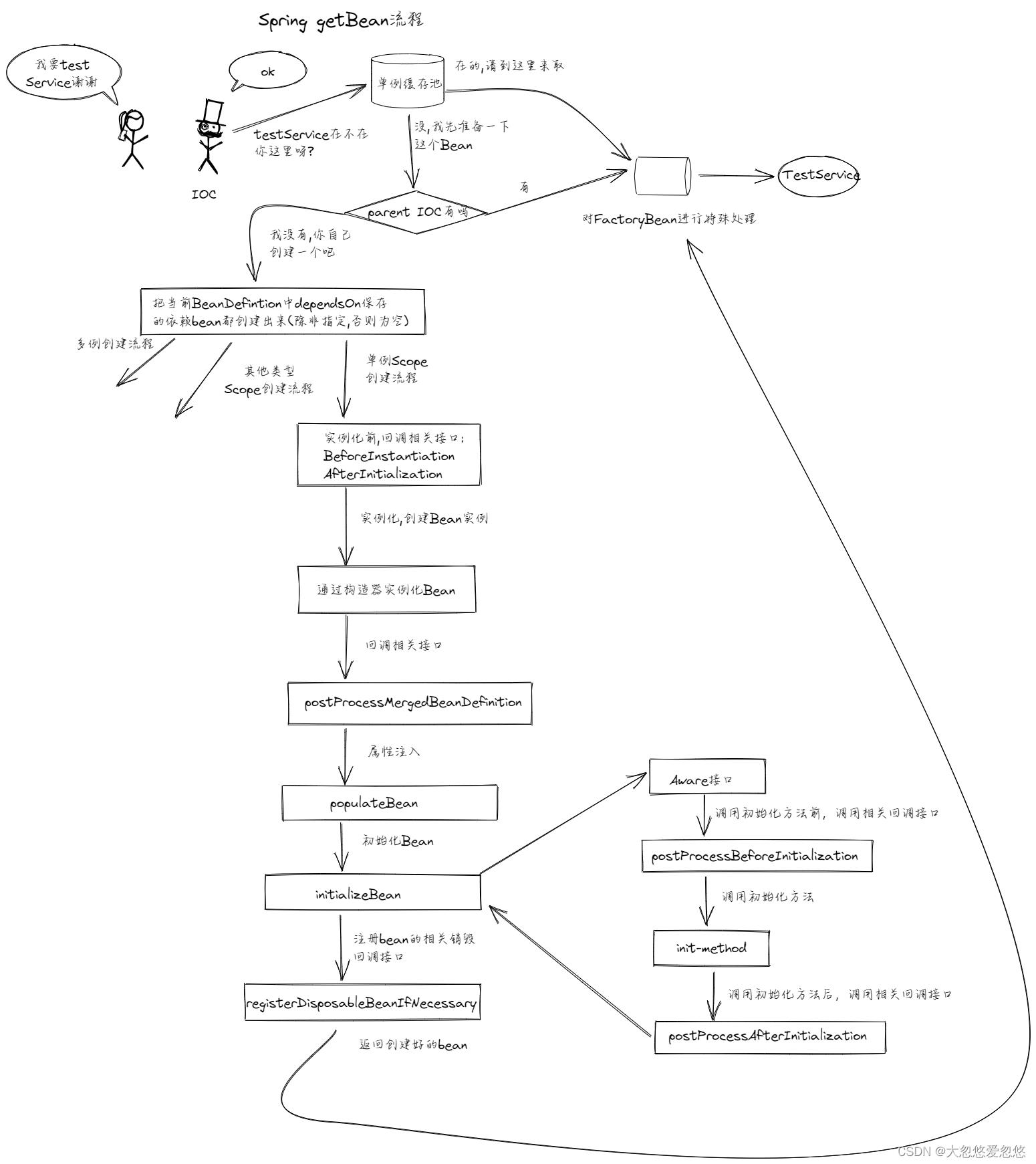
getBean总共就三个大的阶段:
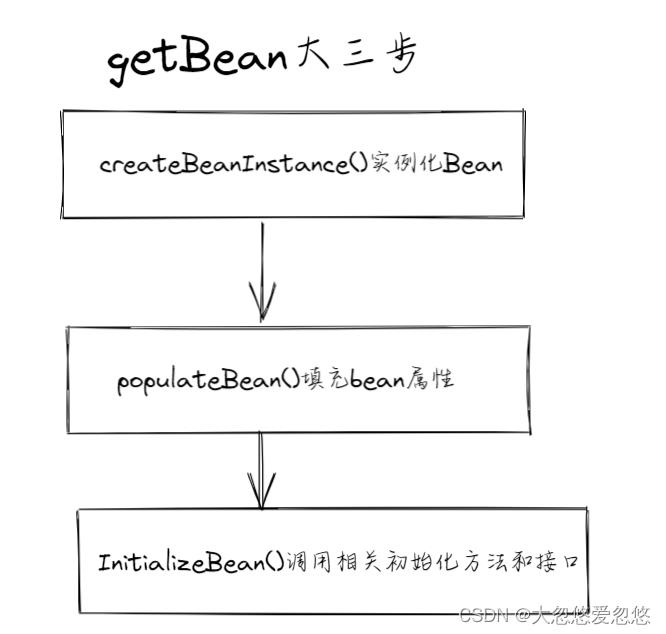
对于Spring而言,循环依赖会发生在第二步,即属性注入的过程,因此我们要想办法在属性注入前将当前Bean依赖的其他bean都进行创建。
在属性注入环节,如果发现当前bean依赖于其他bean,那么会去创建对应的bean.
不妨思考下面这个流程:
- A实例化完毕后,进行属性注入环节,发现其依赖于B,于是去创建B
- 进入B的getBean流程,B创建完后,进行属性赋值环节,又发现B又依赖于A,因此又尝试去创建A ---->死循环就出现在这里
大家可以思考一下,如何解决上面这个死循环.
- 当B调用getBean(A)的时候,因为此时A已经创建出来了,只是还没有赋值,那么是不是可以用一个集合记录当前已经实例化好的bean集合,并且将这个已经创建好的A实例放到这个提前暴露bean实例的缓存中。
- 这样当B调用getBean(A)的时候,该方法一开始还是去查单例缓存池,如果该缓存池没有就再去查询提前暴露bean实例缓存池,如果有了,那么直接返回即可。

这里提前暴露的意思就是将已经实例化bean但是还没有赋值的bean实例放到一个缓存池中,可以让其他bean在需要当前bean,但是当前bean还没初始化完的情况下,先引用这个暴露的bean
注意: 暴露出去的是这个bean对象的引用,因此该bean后续的属性注入的修改都是在同一块内存上完成的。
添加了提前暴露的缓存池后,循环引用的流程就变成了下面这样子:
- getBean(A),先去查一下单例缓存和提前暴露的缓存池有无此bean
- A第一次创建是没有的,那么我直接去实例化A,然后放入提前暴露的缓存池中
- 进入A的属性赋值阶段,发现依赖B,然后去getBean(B)
- getBean(B),先去查一下单例缓存和提前暴露的缓存池有无此bean
- B第一次创建是没有的,那么我直接去实例化B,然后放入提前暴露的缓存池中
- 进入B的属性赋值阶段,发现依赖A,然后去getBean(A)
- getBean(A),先去查一下单例缓存和提前暴露的缓存池有无此bean
- 发现提前暴露的缓存池中有A的引用,直接返回
- B进入初始化流程,然后创建完毕,返回
- A进入初始化流程,然后创建完毕,返回
还有一点大家可以看出来,因为必须在实例化后,当前bean对象才会被提前放入缓存池中,因此构造器造成的循环依赖无法解决
可以看到此时循环引用的问题就已经被解决了,但是我们给出的解决方案还存在诸多问题,但是思路是正确的,那么下面来看看Spring是如何完美解决bean的循环依赖的吧。
三级缓存解决循环依赖
我们上面只使用了二级缓存,即一个单例缓存池和一个提前暴露的单例缓存池,但是spring在此基础上多加了一个缓存池,并且具体的使用上也和我们上面讲的有点区别:
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry
...
// 从上至下 分表代表这“三级缓存”
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); //一级缓存
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); // 二级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); // 三级缓存
...
//用来记录正在创建的单例bean有哪些,当bean创建完毕后,会从该集合中移除
private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
//标记已经创建完毕的bean有哪些
private final Set<String> alreadyCreated = Collections.newSetFromMap(new ConcurrentHashMap<>(256));
三级缓存的作用分别如下:
- singletonObjects:用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用
- earlySingletonObjects:提前曝光的单例对象的cache,存放原始的 bean对象(尚未填充属性),用于解决循环依赖
- singletonFactories:单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖
下面跟随我的脚本一起来看看getBean过程中三级缓存是如何发挥作用并巧妙解决循环依赖问题的吧:
三级缓存解决流程
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException
String beanName = transformedBeanName(name);
Object beanInstance;
//查询三级缓存
Object sharedInstance = getSingleton(beanName);
//如果缓存中存在,就直接返回
if (sharedInstance != null && args == null)
...
//对FactoryBean的返回值做处理
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, null);
else
//如果当前beanName是Prototype并且正处于创建状态,那么这里直接抛出异常
//Prototype类型的bean不能被循环引用的体现
if (isPrototypeCurrentlyInCreation(beanName))
throw new BeanCurrentlyInCreationException(beanName);
//先去父IOC找找有无,有的话直接返回
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) ...
if (!typeCheckOnly)
//标记当前bean创建完毕
//加入alreadyCreated集合
markBeanAsCreated(beanName);
StartupStep beanCreation = this.applicationStartup.start("spring.beans.instantiate")
.tag("beanName", name);
try
...
//如果设置了beanDefintion的dependon属性,那么这里会进行处理
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null)
....
//下面进行bean的创建流程
if (mbd.isSingleton())
sharedInstance = getSingleton(beanName, () ->
try
//创建单例Bean
return createBean(beanName, mbd, args);
catch (BeansException ex)
//创建失败,销毁该单例bean
destroySingleton(beanName);
throw ex;
);
//对FactoryBean的返回值做处理
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
//其他类型的scope的bean的创建流程
....
return adaptBeanInstance(name, beanInstance, requiredType);
我们最关心的应该是三层缓存的查询方法,即getSingleton:
public Object getSingleton(String beanName)
//第二个参数表示是否允许循环依赖,这里允许
return getSingleton(beanName, true);
protected Object getSingleton(String beanName, boolean allowEarlyReference)
//先查询一级缓存--即单例缓存池,如果这里面有就直接返回
Object singletonObject = this.singletonObjects.get(beanName);
//如果没有,并且当前bean正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName))
//查询二级缓存,判断有无
singletonObject = this.earlySingletonObjects.get(beanName);
//如果二级缓存也没有,并且允许循环依赖
if (singletonObject == null && allowEarlyReference)
synchronized (this.singletonObjects)
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null)
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null)
//查询三级缓存--取出当前bean关联的单例工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
//如果存在的话
if (singletonFactory != null)
//从工厂中获取到这个单例对象
singletonObject = singletonFactory.getObject();
//加入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//并从三级缓存中移除这个单例工厂
this.singletonFactories.remove(beanName);
//找到就返回,否则返回null
return singletonObject;
我相信各位此时都有一个疑惑,为什么需要singletonFactories,而不是直接两级缓存完事了呢?
- 这个问题涉及到aop代理相关,这里先卖个关子,下面我会好好讲讲
先来看看getSingleton方法:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory)
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects)
//首先查看单例缓存池中是否已经存在了当前bean
//即当前bean是否已经创建完了
Object singletonObject = this.singletonObjects.get(beanName);
//如果一级缓存中没有
if (singletonObject == null)
//并且如果单例bean集合正处于销毁状态,那么抛出异常
if (this.singletonsCurrentlyInDestruction)
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
if (logger.isDebugEnabled())
logger.debug("Creating shared instance of singleton bean '" + beanName + "'");
//记录当前bean正处于创建状态--加入singletonsCurrentlyInCreation
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions)
this.suppressedExceptions = new LinkedHashSet<>();
try
//这里就是调用createBean方法来创建单例对象
singletonObject = singletonFactory.getObject();
newSingleton = true;
catch (IllegalStateException ex)
// Has the singleton object implicitly appeared in the meantime ->
// if yes, proceed with it since the exception indicates that state.
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null)
throw ex;
catch (BeanCreationException ex)
if (recordSuppressedExceptions)
for (Exception suppressedException : this.suppressedExceptions)
ex.addRelatedCause(suppressedException);
throw ex;
finally
if (recordSuppressedExceptions)
this.suppressedExceptions = null;
//当前单例对象创建完毕后
//清除其正处于创建状态的标记,即从singletonsCurrentlyInCreation集合中移除
afterSingletonCreation(beanName);
//如果是一个新的单例对象被创建
if (newSingleton)
//加入一级缓存中去--顺便清除二三级缓存中当前bean的信息
addSingleton(beanName, singletonObject);
//返回创建的单例对象
return singletonObject;
下面再来看看createBean方法:
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException
...
RootBeanDefinition mbdToUse = mbd;
...
try
//初始化前,先去调用bean的后置处理器两个初始化前后的回调接口
//如果在这里,返回的值不为空,那么会直接形成短路
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null)
return bean;
catch (Throwable ex)
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
try
//真正创建bean
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isTraceEnabled())
logger.trace("Finished creating instance of bean '" + beanName + "'");
return beanInstance;
....
看来还需要再追踪一层doCreateBean:
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException
...
if (instanceWrapper == null)
//实例化bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
//从BeanWrapper中取出真正被创建出来的bean实例
Object bean = instanceWrapper.getWrappedInstance();
...
//调用相关bean后置处理器的回调接口
synchronized (mbd.postProcessingLock)
if (!mbd.postProcessed)
try
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
....
//当前bean是否允许早期被暴露出去
//三个前提: 当前bean是单例的,允许循环依赖,当前bean处于正创建的状态
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
...
//加入单例工厂---就是加入三级缓存中
//这里getEarlyBeanReference是关键,这里会调用bean后置处理器的getEarlyBeanReference接口
//自动代理创建器在此处创建代理对象
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
//拿到暴露出去的bean实例
Object exposedObject = bean;
try
//属性赋值
populateBean(beanName, mbd, instanceWrapper);
//初始化bean
exposedObject = initializeBean(beanName, exposedObject, mbd);
catch (Throwable ex)
....
//当前bean是否允许早期暴露---满足上面三个条件
if (earlySingletonExposure)
//此时第二个参数为false,表示不允许提前暴露
//因此不会去查询三级缓存---只会去查询到二级缓存
//当前bean因为还处于创建状态,因此一级缓存是绝对没有的,二级缓存可能有,可能没有
Object earlySingletonReference = getSingleton(beanName, false);
//如果二级缓存有,说明产生了循环依赖
if (earlySingletonReference != null)
//如果经历过属性赋值和初始化过后的bean依然和之前的bean实例一致
//说明当前bean没有被代理过,否则就是两个对象了
if (exposedObject == bean)
exposedObject = earlySingletonReference;
//如果当前bean被代理了,那么默认是不支持循环引用发生的
//下面再判断被代理后的对象是否允许在存在循环引用的情况下再注入其他bean实例,默认为false
//并且当前bean确实存在对其他bean的依赖
//这里举个例子:
//例如A与B相互引用,此时A走到这里,说明引用的B已经从三级缓存中获取到了提早暴露出的A的引用,并放入了二级缓存
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName))
//A这里拿到的应该是B
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String depende以上是关于Eureka三级缓存的主要内容,如果未能解决你的问题,请参考以下文章