DBA眼中的基线与容量(上)
Posted DFC基石
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DBA眼中的基线与容量(上)相关的知识,希望对你有一定的参考价值。
DBA眼中的基线与容量(上)
基线与容量是DBA运维系统工作中所必须面临的问题。比如老白前阵子刚买了一个SURFACE PRO4,开机后要求升级系统,点了’YES’接受升级请求后,SURFACE就不断的在更新,微软的系统升级大家都经历过,没有百分比,也没有在干嘛的提示,10分钟,20分钟,30分钟过去了,界面还是这样。当时我就有点犯傻,到底这种情况是否正常呢?问了一个用过SURFACE的朋友,他说有时候升级确实需要半小时甚至更多。于是我就放心了。这其实就是一种基线。如果你不了解第一次开机的升级需要多长时间这个基线,那么性急的朋友可能要强制关机重启了,那你的SURFACE变砖的机会就很高了。
前面通过一个例子简单介绍了基线大致是什么东西,实际上今天老白要介绍的基线和传统的基线在本质上是一样的,不过在对基线这两个字的理解上会有较大的不同。等会我们再来揭晓老白眼中的基线到底是何方神圣。
谈基线之前我们先来看看DBA晋级的几个特征,下图是老白自己定义的DBA的几个能力阶段。最初级的DBA刚刚进入这个行业,没有技术和业务积累,因此他们往往是根据现象分析问题;第二级别的DBA除了根据现象分析问题外,还可以根据一些运行指标来分析问题,比如DB CACHE命中率,TOP 5 事件等;如果你不仅仅根据指标来分析问题,还可以根据基线来分析问题了,那么恭喜你,你晋级为第三等级,也就是较为高级的DBA了;而能够成为真正高手的DBA,除了能够通过基线来分析问题外,还了解各种IT组件和业务的容量,他们不仅能通过系统历史数据来分析指标是否正常,还可以根据自己积累的一些通用性的指标体系来判断指标是否正常,这对于分析一个全新的,自己没有任何指标特性积累的系统来说,是十分有用的。

刚刚入门的DBA处理为你的时候往往是根据问题的表面现象,问题所表现出来的最为表层的东西去分析问题,比如从日志中发现一条信息,前台的一个告警等等。下面这张图就勾画出了一个刚刚入门的DBA的处理问题的路径。
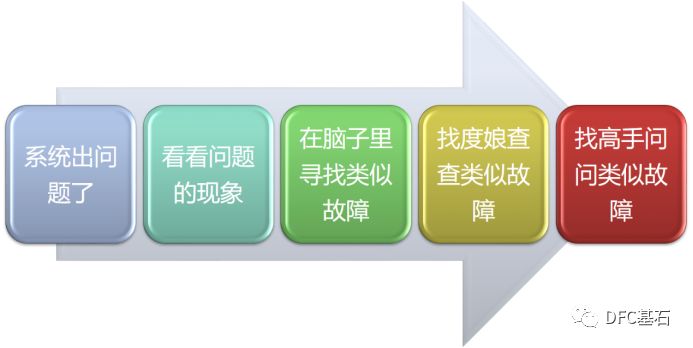
随着DBA自身能力的提升,他学会了采集操作系统和数据库的一些运行指标信息,学会了简单的阅读AWR报告,于是再遇到问题,分析问题的思路也随之有了很大的提升。如果发现某个数据库比较慢了,会先从AWR报告上去查找系统可能存在什么问题,比如某些命中率指标是否偏低,某些争用是否有点严重,某些等待事件是否比较异常等等。然后再到百度或者MOS上去查找某些指标异常,可能是什么引起的。
由于有第一手的数据,并且学会了分析指标,学会了看AWR里的LOAD PROFILE和TOP EVENTS等,DBA处理问题的成功率也有了较大的提升。这个阶段的DBA基本上能够独立分析较为复杂的系统问题了,老白也把这类DBA定位为中级DBA。下面的一张图勾画了中级DBA处理问题的路径:
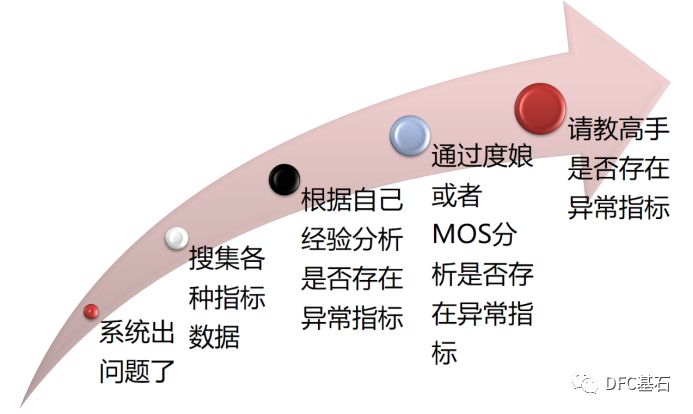
在这个阶段,DBA已经能够根据需要处理和分析的问题的不同特征使用相关的工具去采集各种数据,并且根据自己的经验分析这些指标是否存在异常现象,有些人会通过百度或者MOS网站去查找资料,辅助分析采集的指标是否存在异常,如果暂时无法在网上找到适当的资料,他们也可以很准确的和后台的高手进行交流,描述现场的情况,并在高手的指导下解决问题。
有时候我们还无法简单的从某些指标发现问题,因为每个系统的指标都会有所不同。经常有朋友问我,我的系统的DB CACHE命中率只有95%,正常不正常,我的系统单块读响应时间6毫秒,正常吗?说实在的我比较难以回答他的问题,因为在不同的系统中,这些指标差异相当大。这些指标只有和横向对比,才比较容易搞清楚。比如某个指标正常不正常,最简单的方法是把系统正常时的这个指标拿出来,和当前的指标比较一下。Oracle有个awrddrpt就可以实现把两个时间段的AWR指标放在一个报告里进行比对。我们可以通过同一个指标的直接比较得到我们所需要的答案。
这种分析方法,老白就称之为基线分析,而真正掌握了基线分析的DBA,就一只脚迈进了高手的行列了。处于这个阶段的DBA可以准确的在出现问题的系统中采集关键的指标信息,并且通过系统正常时间段的基线数据与之比较,从而快速定位系统可能存在的问题。
而更高层次的DBA不仅仅能够通过基线比对分析来发现系统可能存在的问题,他还能够通过系统容量指标和系统级的基线数据来判断一个以前不太熟悉或者从未接触过的没有历史基线数据的系统是否正常。这个阶段的DBA不仅仅会考虑系统的基线数据,他们还会考虑系统的总体负载能力,考虑数据库标准操作产生的资源消耗情况,考虑不同硬件之间的容量差异,考虑信息系统长期发展的可持续问题。
基线和容量很容易混淆,我们还是先通过一个例子来区分基线和容量。如果我们在维护一套自己熟悉的系统,那么我们很容易通过基线对比来判断,但是如果遇到一套系统是我们以前不熟悉的,不仅仅系统不熟悉,连系统所跑的业务不熟悉。这个时候如果要我们来分析问题,那么我们总不能和客户说让我先熟悉一阵子再来分析吧。
如果是10多年前,那么很多系统出现问题往往伴随的是系统瓶颈,比如老白的《DBA优化日记》里所说的沈阳和海尔的案例,都是不同程度出现了系统资源瓶颈导致的问题。那种系统在AWR报告或者OS采集的数据中,很容易就能发现一些异常的指标。而现在的绝大多数系统并没有出现资源瓶颈,所以很多指标在表现上并没有出现极端的现象,作为一个资深的DBA,虽然不清楚这个系统以往的历史指标是怎么样的,但是根据其历史经验以及他对某个it组件的容量,可以较为准确的判断哪些指标可能存在不合理的现象。这些判断取决于DBA能够掌握某些IT组件的总体负载能力,比如一台IBM P750小型机,在CPU满配的情况下,大体上每秒能处理多少OLTP并发交易。
DBA如果能够掌握一些容量数据,就可以通过容量模型的管理来考虑信息系统长期可持续发展的问题,从而使运维水平提高一个层次。所以老白认为,掌握容量是DBA进阶为系统架构师路上的必进之路。
在正式介绍基线之前,我们还需要通过一个例子来加深认识。比如近期老白遇到了一个系统性能问题,这是一台4路PC SERVER,32核的,上面跑了一个ORACLE 11G的数据库,从8月2日一早开始,某个系统就出现了问题,CPU使用率基本上处于100%,而平时的时候,这套系统的CPU最高使用率不超过40%。8月3日起,系统又恢复正常。这一天到底出了什么问题,导致了CPU资源突然增长这么多呢?我们先来看看系统的总体情况:
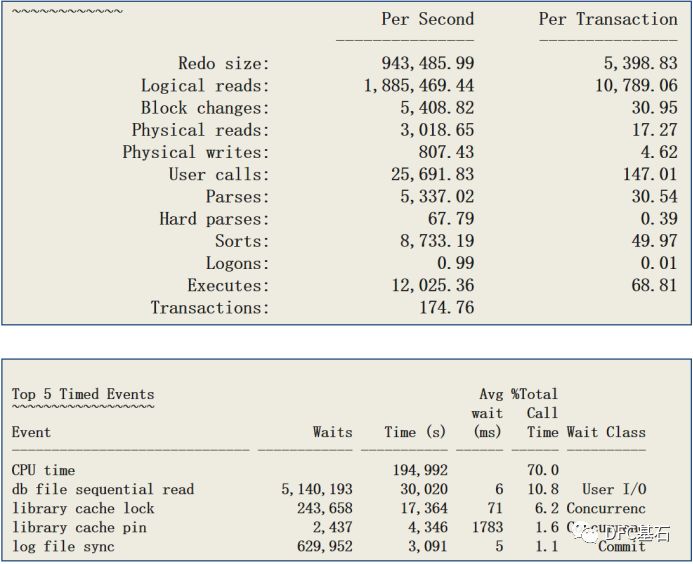
从AWR报告的LOAD PROFILE和TOP 5 EVENTS来看,可能出问题的点很多,包括:
l 应用出了问题?因为逻辑读很高,有188万多
l 共享池争用?因为TOP 5 EVENTS里有library cache lock/library cache pin的等待
l 某个SQL出现问题?因为逻辑读很高,有188万多
l 存储系统出现问题?因为db file sequential read的平均等待时间为6毫秒,Log file sync等待也有5毫秒
l 服务器出现问题?服务器负载过高也可能出现类似的情况
l ……
到底问题出在哪里呢?不同层级的DBA会有不同的怀疑方向。在往下看之前,大家可以考虑下,等会我们来揭晓答案,同时大家也可以自己心里测算下,按照老白的四级划分,你目前处于哪个层级。当然这个层级划分不一定合理。
当然了,能从中看出问题的DBA起码也不是刚入门的菜鸟,至少是能够看指标的DBA。根据指标分析的DBA,往往会把关注点放到了TOP 5 EVENTS里面几个和library cache相关的指标上,这两个指标占了系统等待事件的8%左右。根据这个指标,十分有理由怀疑是不是系统的共享池出问题了。如果你的答案也是Library cache pin/lock,那么你可能是一个初中级的DBA。
而基于基线分析的DBA可能会把LIBRARY CACHE放到第二位,因为这两个等待加在一起才8%的占比,不至于把系统从40%不到的CPU负载加大一倍多。而经常观察本系统的一些核心指标的DBA很快会发现Logical reads的指标比平时高很多,并且他也明白逻辑读多了,CPU资源消耗肯定高。从逻辑读比较高这一点,很容易想到系统中可能存在高开销的SQL,找一找是不是有哪条SQL的执行计划发生了变化,或者系统中是否存在一些以前不存在的大开销的SQL,可能是定位问题的关键。
如果你有幸进入了顶级DBA的行列,那么你可能不仅仅会关注到逻辑读过大的问题,对于一台4路32核的老PC SERVER来说,他可能很快就可以看出每秒12025次的执行也是比较高的。因此对于具有容量分析能力的DBA来说,他关注的疑点可能会增加一个,为什么有那么多的执行数量。当然,对于具有容量分析能力的DBA,可以在不清楚这个系统以前负载指标的情况下,第一时间定位到逻辑读超过180万/秒,执行超过12000,对于一台4路32核的较老的4路PC SERVER来说,是比较高的。当然最后通过这两个疑点,两类DBA会有两个略微相似的分析路径。基于基线分析的DBA很可能重点先放在逻辑读较高的SQL上,看看是不是有哪些SQL的执行计划出现了变化。而具有容量分析能力的DBA会先把焦点放到执行数量较多的SQL上,看看哪些SQL的执行频率提高了,或者说出现了什么执行数量较高的SQL。
这三类DBA可能最终都会找出问题的原因,只是他们的分析路径有所不同而已。当然首先关注执行数量的DBA可能会更早的定位到问题。这个问题的最终结果会让大家都有些意外。是一些开销不大的但是执行频率很高的SQL把存储撑爆了,高峰期RAC两个节点的总的IOPS达到了10万以上,导致该存储的IO响应时间大幅下降。虽然我们在AWR报告上看到这个存储的db file sequential read的时间是6毫秒,不算差,但是这是一台CACHE很大的高端存储,这个系统正常时候,这个指标是2毫秒。
到这里,大家应该了解到自己处于DBA的那个层级了吧,不过没关系,自己在心里可以盘算,是应该找老板加薪还是默默的把它烂在心里。下面我们来总结一下,如果某一天业务部门说某个系统很慢,而你发现系统资源没有瓶颈,数据库也没有什么指标明显异常,那么你该怎么进一步分析呢?这其实是现在的DBA所面临的常见问题。在老白经常跑现场的时代,问题简单的多,系统出现性能问题无外乎负载太高或者SQL太烂。而现在的DBA面临的挑战要严峻的多,一个各种指标异常不明显的系统,是较难分析的。这回我们从最佳实践往下看,看看高大上的解决方案一直到IT民工怎么应对这一问题的。
如果系统层面没有发现什么明显的瓶颈,那么至少有一半的可能性是和业务模块本身有关的。因此最好你手头有业务运行的基线,通过这些基线来查找存在异常的业务模块,然后从这些业务模块入手,通过应用性能监控工具下钻到这个模块调用的类,直到SQL。这种分析方式可以很直观的发现系统可能存在的问题。不过缺点是,你首先必须部署了应用性能分析工具。这些价格昂贵的工具往往是你无法获得的。
退而求其次的处理路径是,如果不幸的是你没有APM工具,那么作为DBA你可能需要花更多的精力去发现问题。甚至还有一种可能是,压根不是数据库的问题,而是应用服务器出现了问题,从而导致了系统的问题。这种情况下,DBA需要了解业务部门反馈的较慢的业务都调用了哪些SQL,然后去分析这些SQL的调用基线,执行次数/平均每次CPU和IO的开销,执行计划是否变化等。如果你很幸运,能找到可对比的基线数据,那么如果是某条SQL出现问题,你也可以很快的定位了。如果很不幸你没有发现问题,你也可以很轻松的告诉应用和中间件的管理人员,数据库没发现啥异常,你们先查查吧。
轮到IT民工就比较惨了,没有可比对的历史数据,只能埋头苦干。上来先采集一把AWR报告,这是很专业的做法。然后找到TOP SQL,一顿分析,看着几十行的SQL执行计划一阵阵头晕。好不容易分析完了,发现这条SQL和业务没任何关系。也有可能你费尽千辛万苦,最后终于找到了业务相关的SQL ,通过分析,你发现Oracle没任何问题。这时候中间件管理员笑嘻嘻的走过来,兄弟我已经搞定了问题了,刚才重启了一下应用服务器,现在一切OK了。这种场景可能是我们经常会遇到的,每次遇到这样的场景,当时的心情是不是会有一群羊驼滚滚而过呢。
不管怎么样,从这个例子我们可以看到基线的作用是十分巨大的,那么到底什么是基线呢?基线不是一个IT方面的专用于,甚至在IT领域,基线也被首先应用在软件开发的配置管理里面。那么对于DBA而言,什么是基线呢?
对于数据库或者运维方面的基线老白总结了几点。首先对于系统而言,从运维的角度来说,基线-BASELINE是某个运行状态在某个时间上的快照;对于DBA来说,基线是用来判断某个指标是否正常的参考条件;某个指标、某个运维经验、某个现象都可以成为运维基线;对DBA来说,有价值的基线往往来自于长期运维的经验,而不是简单的某个指标。
上面的几条概念性的东西可能还有点抽象,我们先通过几个例子来看看对于DBA而言什么是基线:
可能有人已经发现了,老白所说的基线,根本不是什么基线,只是一些运维人员的经验。如果你发现了这一点,那么太好了,你已经理会了基线的精髓了。从真正运维人员的角度来看,基线不是一个个苍白的指标,而是活生生的运维经验。只有能总结成运维经验的基线指标才是有价值的,否则再多的指标都无法帮助你运维。
第一个基线的案例是老白在DBA优化日记里面所提到的,当时客户发现平常时候活跃会话数量一般会在100左右,如果超过150,说明系统有问题了,如果超过200,系统就变得比较卡了,超过300,系统有可能就会HANG死。于是用户定义了一个基线,当系统的活跃会话数接近200就开始杀会话。这样能保持系统正常运行。靠着这个小技巧,客户把系统维持到了扩容,在这段时间里基本上保证了系统的可用。
第二个基线的案例是某个快递公司,当查单业务的SQL同时有超过100个并发访问的时候,系统资源很快就会出现瓶颈了。于是当DBA发现查单的SQL在V$SESSION中出现超过100的时候,就开始啥查单会话,直到系统恢复正常。
第三个案例是一个运营商客户,他们的某条SQL经常因为统计数据不准确而导致走错执行计划,虽然系统没有因此出现大的问题,运维人员有时候无法及时掌握系统出现了问题。不过该业务变慢会导致投诉增加,业务部门会用这个考核IT部门。通过这个指标,运维部门可以及时发现有SQL执行计划出现偏差,及时更新统计数据。
最后一个案例是一个银行,最初时LOG FILE SYNC的平均等待时间是2-3毫秒,突然变成5毫秒了。下一季度巡检时候变成7毫秒了,我们就给客户提出预警,希望他们检查下存储。客户检查了存储,告知我们,存储一切正常。再下一次巡检时,这个指标变成9毫秒了,我们再次预警,客户还是没发现存储的问题。过了半个月,突然有一天客户的核心业务出现了卡顿,时间超过5分钟,于是立即要求我们帮助协查。检查结果发现,系统的主要等待事件是LOG FILE SYNC,而该等待的平均响应时间已经超过15毫秒。这回用户真的用心做了排查,发现存储本身没问题,不过有一条同城复制的同步复制链路不稳定,经常切换,影响了整个存储的写性能。而以前检查的主要是读,发现读的性能都没问题。经过这件事后,客户设定了对LOG FILE SYNC的日常检查,大于10毫秒就要进行细致的存储检查了。
后续,我们将介绍老白对基线的私家解释,敬请期待......
扫码关注哦!
以上是关于DBA眼中的基线与容量(上)的主要内容,如果未能解决你的问题,请参考以下文章