十步大法--DBA碰到数据库故障后如何迅速定位
Posted 架构师小跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十步大法--DBA碰到数据库故障后如何迅速定位相关的知识,希望对你有一定的参考价值。
概述
遇到此类问题,首先是心态,一定不能慌,要沉着冷静、胆大心细,而另外一个非常重要的就是诊断思路和辅助脚本,今天主要介绍碰到问题时的通用处理思路,分享用到的一些脚本,帮助大家快速定位问题并解决,减少业务的中断事件。
1、查看操作系统负载
登上数据库服务器后,第一个就是通过系统命令确认下CPU、内存、I/O是否异常,每个系统的命令不一样,常见的有top、topas、vmstat、iostat。
2、查看等待事件
查看活动的等待事件,这是监控、巡检、诊断数据库最基本的手段,通常81%的问题都可以通过等待事件初步定为原因,它是数据库运行情况最直接的体现,如下脚本是查看每个等待事件的个数、等待时长,并排除了一些常见的IDLE等待事件。
SELECT inst_id,EVENT, SUM(DECODE(WAIT_TIME, 0, 0, 1)) "Prev", SUM(DECODE(WAIT_TIME, 0, 1, 0)) "Curr", COUNT(*) "Tot" , sum(SECONDS_IN_WAIT) SECONDS_IN_WAITFROM GV$SESSION_WAITWHERE event NOTIN ('smon timer','pmon timer','rdbms ipc message','SQL*Net message from client','gcs remote message')AND event NOT LIKE '%idle%'AND event NOT LIKE '%Idle%'AND event NOT LIKE '%Streams AQ%'GROUP BY inst_id,EVENTORDER BY 1,5 desc;
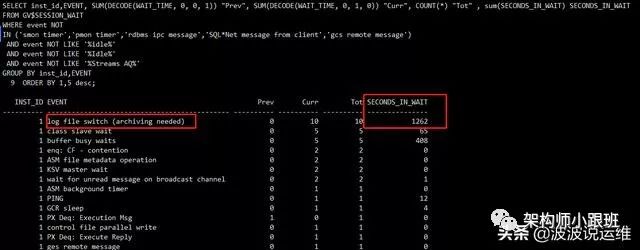
这里就需要掌握一些常见异常等待事件的原因,并形成条件反射,比如library cache lock、read by other session、row cache lock、buffer busy waits、latch:shared pool、gc buffer busy、cursor: pin S on X、direct path read、log file sync、enq: TX - index contention、PX Deq Credit: send blkd、latch free、enq: TX - row lock contention等等,如果异常等待事件的个数和等待时间很长,那么排查原因的入口就在这里。
3、根据等待事件查会话
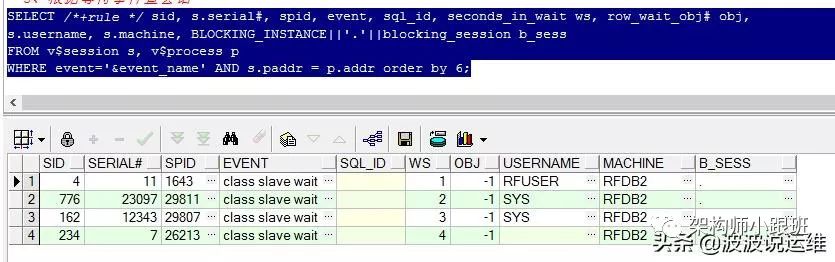
得到异常等待事件之后,我们就根据等待事件去查会话详情,也就是查看哪些会话执行哪些SQL在等待,另外还查出来用户名和机器名称,以及是否被阻塞。另外如下脚本可改写成根据用户查会话、根据SQL_ID查会话等等。
SELECT /*+rule */ sid, s.serial#, spid, event, sql_id, seconds_in_wait ws, row_wait_obj# obj,s.username, s.machine, BLOCKING_INSTANCE||'.'||blocking_session b_sessFROM v$session s, v$process pWHERE event='&event_name' AND s.paddr = p.addr order by 6;
4、查询某个会话详情
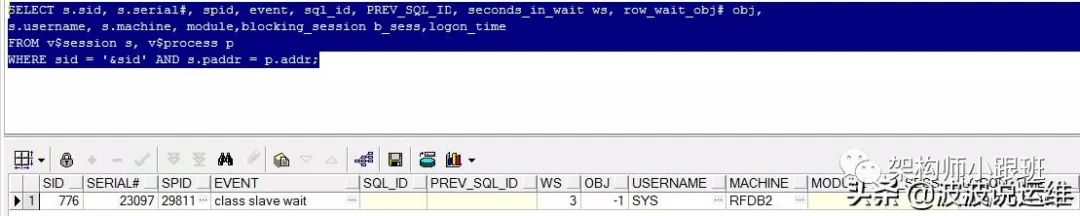
得到会话列表之后,可以根据如下SQL查询某个会话的详细信息,如上次个执行的SQL_ID,登录时间等,该SQL也可改写成多个。
SELECT s.sid, s.serial#, spid, event, sql_id, PREV_SQL_ID, seconds_in_wait ws, row_wait_obj# obj,s.username, s.machine, module,blocking_session b_sess,logon_timeFROM v$session s, v$process pWHERE sid = '&sid' AND s.paddr = p.addr;
5、查询对象信息
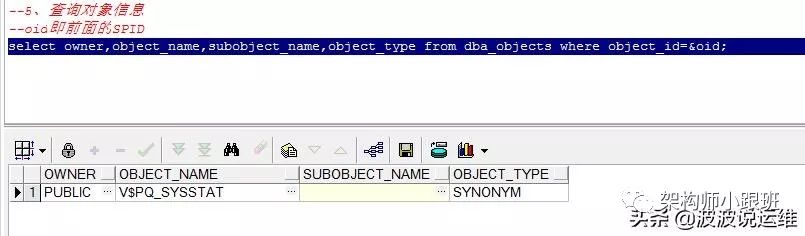
从前面两个SQL都可以看到会话等待的对象ID,可以通过如下SQL查询对象的详细信息
col OBJECT_NAME for a30select owner,object_name,subobject_name,object_type from dba_objectswhere object_id=&oid;
6、查询SQL语句
根据SQL_ID、HASH_VALUE查询SQL语句。如果v$sqlarea中查不到,可以尝试DBA_HIST_SQLTEXT视图中查询。
select sql_id,SQL_fullTEXT from v$sqlarea where (sql_id='&sqlid' or hash_value=to_number('&hashvale') ) and rownum<27、查询会话阻塞情况
通过如下SQL查询某个会话阻塞了多少个会话。
select count(*),blocking_session from v$sessionwhere blocking_session is not nullgroup by blocking_session;

8、查询数据库的锁
通过如下SQL查询某个会话的锁,有哪些TM、TX锁,以及会话和锁关联查询的SQL,注意这里指定了ctime大于100秒,30%的情况是人为误操作锁表,导致应用SQL被阻塞,无法运行。
--查询某个会话的锁select /*+rule*/SESSION_ID,OBJECT_ID,ORACLE_USERNAME,OS_USER_NAME,PROCESS,LOCKED_MODEfrom gv$locked_object where session_id=&sid;--查询TM、TX锁select /*+rule*/* from v$lockwhere ctime >100 and type in ('TX','TM') order by 3,9;--查询数据库中的锁select /*+rule*/s.sid,p.spid,l.type,round(max(l.ctime)/60,0) lock_min,s.sql_id,s.USERNAME,b.owner,b.object_type,b.object_namefrom v$session s, v$process p,v$lock l,v$locked_object o,dba_objects bwhere o.SESSION_ID=s.sid and s.sid=l.sid and o.OBJECT_ID=b.OBJECT_IDand s.paddr = p.addr and l.ctime >100 and l.type in ('TX','TM','FB')group by s.sid,p.spid,l.type,s.sql_id,s.USERNAME,b.owner,b.object_type,b.object_nameorder by 9,1,3
9、杀会话
通常情况下,初步定为问题后为了快速恢复业务,需要去杀掉某些会话,特别是批量杀会话,有时还会直接kill所有LOCAL=NO的进程,再杀会话时一定要检查确认,更不能在别的节点或者别的服务器上执行。
--杀某个SID会话SELECT /*+ rule */ sid, s.serial#, 'kill -9 '||spid, event, blocking_session b_sessFROM v$session s, v$process p WHERE sid='&sid' AND s.paddr = p.addr order by 1;--根据SQL_ID杀会话SELECT /*+ rule */ sid, s.serial#, 'kill -9 '||spid, event, blocking_session b_sessFROM v$session s, v$process p WHERE sql_id='&sql_id' AND s.paddr = p.addr order by 1;--根据等待事件杀会话SELECT /*+ rule */ sid, s.serial#, 'kill -9 '||spid, event, blocking_session b_sessFROM v$session s, v$process p WHERE event='&event' AND s.paddr = p.addr order by 1;--根据用户杀会话SELECT /*+ rule */ sid, s.serial#, 'kill -9 '||spid, event, blocking_session b_sessFROM v$session s, v$process p WHERE username='&username' AND s.paddr = p.addr order by 1;--kill所有LOCAL=NO进程ps -ef|grep LOCAL=NO|grep $ORACLE_SID|grep -v grep|awk '{print $2}' |xargs kill -9
10、重启大法
如需要修改静态参数、内存等问题,需要重启数据库,千万不要在这个时候死磕问题原因、当作课题研究,我们的首要任务是恢复业务。
tail -f alert_.logalter system checkpoint;alter system switch logfile;shutdown immediate;startup
以上就是遇到数据库问题用到的一些脚本,特别是应用反应慢、卡的情况,另外建议首先对脚本足够熟悉然后再使用,还可以根据自己的环境改写。后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注一下~
以上是关于十步大法--DBA碰到数据库故障后如何迅速定位的主要内容,如果未能解决你的问题,请参考以下文章