还好DBA给力!记“一次自动恢复的支付故障”根本解法
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了还好DBA给力!记“一次自动恢复的支付故障”根本解法相关的知识,希望对你有一定的参考价值。
一、故障描述
作为一个老牌OTA公司,公司早些年订单主要来源是PC网站和呼叫中心。我在入职公司大约半年后,遇到一次非常诡异的故障。
有一天早上,大概也是这个季节,阳光明媚,程序猿刚起床,洗洗涮涮,准备去迎接初恋般的工作日,却突然收到一大堆报警,线上消息队列大量积压。
当然,我还是一如既往的非常勤奋地在9点之前就到公司的;但是作为一名新员工,环视四周,组内其他员工都还没到公司,运维也都在路上,故障就这样突然降临了。
我赶紧开机登录堡垒机,连接线上机器,tail 错误日志。但是线上10几个系统,我看了好几个系统,都没有发现有什么错误,这就尴尬了。
统计消息队列,超过好几千的消息待消费。我当时就在想,这些消息都是什么鬼。截图如下:
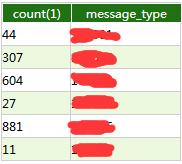
看到这里,你一定会问数量为604和881个的消息是做什么?知道这些消息的逻辑不就解决问题了么?
话说当时我也是这么想的,可是当时我作为一名新人,才开始接触业务不到3个月,还完全没有这么深的业务积累(这个时候知道业务是多么重要)。
既然系统看不到任何错误,我也没有什么办法了,当时因为刚入职没多久,还有点寄希望于领导来解决。
转眼间半个小时已经过去,故障仍然没有恢复,从业务反馈来看,微信支付宝等支付方式不受影响。
受影响的只是信用卡支付(其实当时信用卡量占比挺高)和分销支付(后来了解到,其实这两种模式都是信用卡支付模式)。
领导还在堵车,运维也只是到了几个小兵,我找运维把几个机器的stack打印了一下,也没有发现什么问题;运维也陆续到岗,运维准备出大招,重启系统。
但是就在此时,突然系统自动恢复了。所有积压的消息自动被消费,信用卡支付也可以了。
好,系统竟然有自我修复功能,佩服!
二、故障原因分析
后来,经过一番努力,还是找到一点蛛丝马迹,我发现系统的一个消费消息的定时任务,在故障期间一直在报错,因为是高可用的job机制,4台机器,只有抢占到锁的服务器才能获取到访问数据库消息权利,所以报错信息比较分散,4台机器都有。

可以判定,这个sql一直异常导致job根本无法获取到消息,而另外的生产者又不断的往队列放消息,进而导致消息积压。
两个系统关系如下:
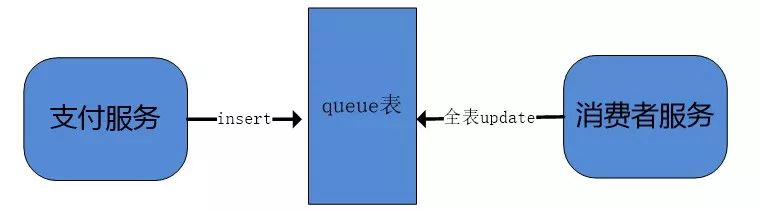
虽然故障总结了,但是我们心里也不踏实,如何找到系统故障的根本原因,以防止以后再次出现这种故障呢?
方法有两种:
去查代码,所有跟这个表相关的sql,都需要仔细review一下,但是你也不一定能查到原因,因为这个场景肯定是不好复现的,要不然早就发现这个问题了。
借助外力,从DB层面查导致这个sql无法执行成功的原因;
方法1看似简单,其实非常不可行。
首先,虽然跟这个表相关的sql,只有几十个,但是都是正常的sql,没有使用for update锁死表的sql。也没有存在未关闭的事务,因为事务是通过AOP配置的。
所以只能寄希望于方法2了,让DBA去查。
好歹我们的DBA足够给力,只用了1天多的时间就查出来了。DBA回复如下:
有事务没有及时提交,且连接也没有关闭,导致该事务一直处于开启状态并持有锁,后续update操作是全表扫描,因此会有锁等待。
最后该连接后续一直没有操作,达到空闲超时3600秒(我们的故障时间正好也是1小时)后被mysql server断开,锁才被释放。(mysql设置:wait_timeout = 3600)
最牛的是DBA贴出了没有提交事务的SQL;SQL我就不贴出来了,我们根据DBA提供的线索,找到了代码的问题。
三、故障根本原因
后来我们查看代码,如上面DBA所说,消息没有被消费处理,是因为有一个mysql客户端,即我们的支付应用程序,在进行快捷支付的时候,向队列插入一条记录,然后在事务中向第三方发起了调用。
使用的是httpclient工具发起的调用,但是设置超时时,只设置了连接超时时间(connectionTimeout)为30秒,没有设置响应超时时间(soTimeout),这样当出现网络问题时,程序就会一直等第三方响应,然后事务也一直没有提交。
而在job程序中,需要将这个queue的所有记录给更新,但是又取不到表锁(见图三),就不断的报lock wait timeout的错误;其实对使用spring AOP框架的研发,很容易犯这种错误。
美团支付也在这块也栽过坑:
参考链接:
https://tech.meituan.com/2018/04/19/trade-high-availability-in-action.html

到这里,其实故障原因已经很清楚了,我们在代码层面也确实查到了问题。
因为DBA提供的SQL中,连insert sql的主机名也列了出来,并且现场没有被破坏,我们使用jstack应该还能找到正在等待的线程才对。
于是在时隔故障2天后,我们又让运维把那台机器的jvm stack给打印了一下,果然发现等待的线程仍然存在。
堆栈如下:
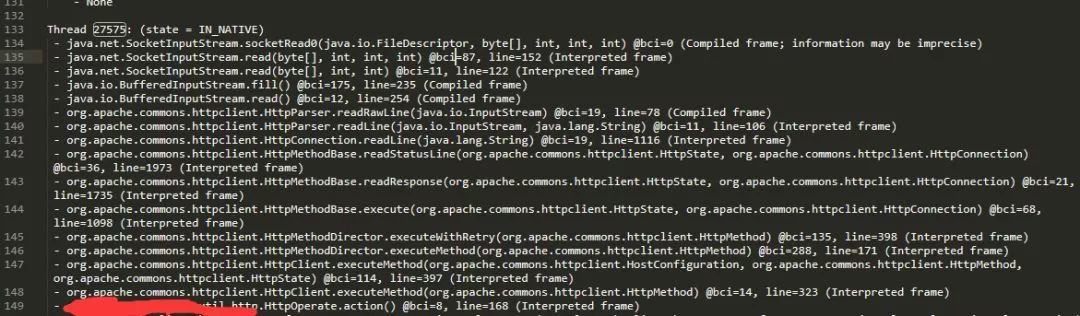
与之对应的代码,我就不贴了。
解决方法:
临时解决方法:将响应超时时间设置上,但这无法根除问题,只是降低再次出现问题的概率;
长久解决方案:修改框架,使用编程式事务,将所有远程调用从事务中剥离出来。
事务,spring AOP
httpclient,超时设置
来源:https://www.cnblogs.com/donlianli/p/10837869.html
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn
想了解更多运维实操演练
灵活解决项目实施疑难?
不妨来DAMS学点独家技能
↓↓扫码可了解更多详情及报名↓↓
2019 DAMS中国数据智能管理峰会-上海站
以上是关于还好DBA给力!记“一次自动恢复的支付故障”根本解法的主要内容,如果未能解决你的问题,请参考以下文章