DB诊断日 | 99%的DBA都想深入了解的MySQL故障 Posted 2021-04-29 腾讯云数据库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DB诊断日 | 99%的DBA都想深入了解的MySQL故障相关的知识,希望对你有一定的参考价值。
为更好的帮助DBA运维数据库,腾讯云将在每月12日开展DBbrain诊断日,腾讯云高级产品经理迪B哥直播解析经典数据库运维难题,结合腾讯云数据库智能管家DBbrain的能力,为大家提供问题优化思路和方法,玩转数据库!
工作中遇到棘手故障不知道怎么办? 欢迎投稿到诊断日,被选中的案例将由腾讯云资深专家“会诊”,并在DB诊断日在线分析教学,帮您提供解决方案。 投稿即有机会获得企鹅公仔,问题被选中即得腾讯云数据库千元代金券~投稿请关注“腾讯云数据库”官方微信后,回复“投稿”即可 。
本期诊断日分享的案例是mysql
大家好,我是腾讯云数据库高级产品经理刘迪,网名迪B哥。 我们都知道在数据库运维过程中,很多问题都需要靠人力来及时发现和处理,我之前也是一名DBA,可以说我做DBA的那段时间基本没有拥有过完整的属于自己的休息时间,全天候Online。 现在AI技术已经广泛运用到了各个领域,数据库运维其实也是同样的,AI可以成为DBA的得力助手,有问题第一时间告警,甚至给出成熟的解决方案,DBA可以用更多的时间去完成高阶的任务。 我现在主要负责的产品是DBbrian,是腾讯云推出的一款数据库智能运维工具。 今天就以咱们MySQL运维过程中典型的主从延时故障来作为案例,告诉大家可以如何借助智能运维服务更好的发现和解决这类问题。
MySQL主从复制可以简单解释为数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。
MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库或者特定的表。
MySQL 主从复制主要用途包括读写分离、 数据实时备份(当系统中某个节点发生故障时,可以方便的故障切换)、 架构扩展、高可以用HA等。
MySQL 主从复制的主要形式包括:
一主多从、多主一从、双主复制、级联复制(部分slave的数据同步不连接master节点,而是连接slave节点。
因为如果master节点有太多的从节点,就会损耗一部分性能用于replication,那么可以让一些slave节点连接主节点,其它从节点作为二级或者三级与slave节点连接)等。
MySQL主从复制涉及到三个线程,一个运行在master节点(log dump thread),其余两个(I/O thread, SQL thread)运行在slave节点,如下图所示:
master节点 binary log dump 线程
当salve节点连接master节点时,master节点会创建一个log dump 线程,用于发送binlog的内容。
在读取binlog中的操作时,此线程会对主节点上的binlog加锁,当读取完成,在发送给slave节点之前,锁会被释放。
当slave节点上执行start slave命令之后,slave节点会创建一个I/O线程用来连接master节点,请求master节点中更新的binlog。
I/O线程接收到master节点binlog dump 进程发来的更新之后,保存在本地relay-log中。
SQL线程负责读取relay log中的内容,解析成具体的操作并执行,最终保证主从数据的一致性。
要实现主从复制,必须打开Master 节点的binary log功能。
因为整个复制过程实际上就是Slave 节点从Master 节点获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。
slave节点上的I/O 进程连接主节点,并请求从指定日志文件的指定位置之后的日志内容;
master节点接收到slave节点的I/O请求后,通过复制的I/O进程根据请求信息读取指定日志指定位置之后的日志信息,返回给slave节点。
返回信息中除了日志所包含的信息之外,还包括本次返回的信息的binlog file 的以及binlog position。
slave节点的I/O进程接收到内容后,将接收到的日志内容更新到本机的relay log中,并将读取到的binary log文件名和位置保存到master-info 文件中,在下一次读取的时能告诉master节点需要从某个binlog的哪个位置开始往后的日志;
slave节点 的 SQL线程检测到relay-log 中新增加了内容后,会将relay-log的内容解析成在master节点上实际执行过的操作,并在本数据库中执行。
MySQL 主从复制模式分为异步模式、半同步模式、全同步模式。
master节点不会主动push binlog到slave节点,有可能导致fail over情况下,也许slave节点没有即时地将最新的binlog同步到本地。
半同步复制模式可以确保至少有一个slave节点(可配置)在接受完master节点发送的binlog日志文件并写入到中relay log后,返回给主节点一个ack信号,告诉master节点已经接收完日志,这时主节点线程才返回给当前session提交信息。
全同步模式是指slave节点接收到master节点发送的binlog日志文件并写入到中relay log,并且完成回放之后,返回给主节点一个ack信号,master节点才会向客户端返回成功。
从前面讲到的的主从复制原理中不难发现,MySQL在使用“异步”和“半同步”的复制模式下可能会出现主从延时。
MySQL数据库复制延迟会给业务带来一系列严重问题:
读写分离架构不利于高实时一致性业务;
高可靠架构设计中也难以确定RTO/RPO指标。
检测,定位和解决MySQL主从复制延迟问题一直是DBA重点工作之一。
数据库智能管家DBbrain为云上用户提供了7*24小时数据库智能运维服务,对于“主从复制”延迟的故障,DBbrain又是怎么诊断的呢?
接下来就为大家一起揭秘这一问题。
那么,首先简要的介绍一下主从延迟(复制延迟)是如何发生的。
MySQL备库复制会启动两类线程:
IO线程负责连接主库读取binlog事件,然后将其写入本地binlog文件;
SQL线程则从复制得到的binlog文件中读取事件apply到备库。
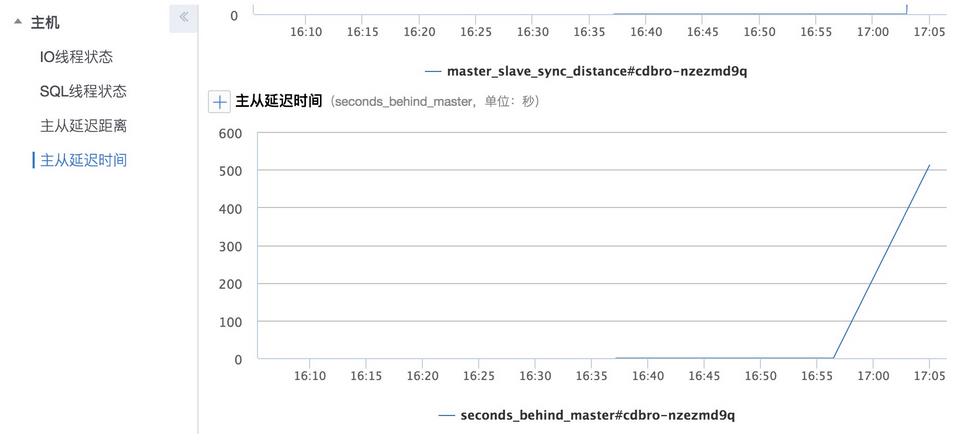
可以通过 "show slave status" 查看备库的复制状态。
其中 SecondsBehindMaster 值表示延迟时间,单位为秒。
将主库执行SQL语句时刻标记为T1,备库执行SQL的时刻标记为T2,这两个时刻之间的差值就是主备延迟时间。
不过仅仅从 "show slave status" 结果看到的延迟时间可能”不准“。
该值除精度问题外,还和主库事务相关。
如果在主库开启事务执行了IUD操作,但是commit有一分钟滞后,那么这个时间差也会在备库复制延迟状态中体现出来。
我们通常看到备库延迟性能曲线始终存在1,2秒的延迟波动,大概率是主库事务导致的;
若从事务提交的时间点算,大延迟并不存在;
在主备切换时为了确保主备数据一致,需要确认主备binlog日志文件和和位点一致后才能操作。
数据库智能管家DBbrain针对主从延迟(复制延迟)的异常场景采用的发现机制和方式主要可以分为以下三种:
①利用seconds_ behind_ master的值
在show slave status结果里的seconds_ behind_ master(In essence, this field measures the time difference in seconds between the slave SQL thread and the slave I/O thread.)的值可以用来衡量主备延迟时间的长短(单位是秒)。
判断seconds_ behind_ master 是否已经等于0,如果这个参数等于0,表示主从复制基本上无延迟。
seconds_ behind__master是通过比较sql_thread执行的event的timestamp和io_thread复制好的event的timestamp进行比较,而得到的差值。
在某些场景中也会出现seconds_ behind_ master对复制延迟表征不准确的情况,例如:
在网络环境特别差的情况下,I/O thread同步很慢,每次同步过来,SQL thread就能立即执行,这样,在slave上查看到的seconds_ behind__master是0,而真正的,slave已经落后master有一定距离。
有一段时间没有数据提交,slave I/O thread time和slave SQL thread time都保持在旧值,比如T(但事实上master上的时间已经到T+I了),这个时候主库出现提交,slave I/O开始去和master同步binlog,slave I/O thread time更新到T+I,但是slave SQL thread time保持在T值,这时的seconds_behind_master=I,但其实是否出现延迟是不确定的。
Master_Log_File和Read_Master_Log_Pos,表示的是读到的主库的最新位点。
Relay_Master_Log_File和Exec_Master_Log_Pos,表示的是备库执行的最新位点。
如果Master_Log_File和Relay_Master_Log_File、Read_Master_Log_Pos和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成。
对于开启GTID的数据库实例,DBbrain会使用对比GTID集合的方式来检测复制延迟是否存在。
(Auto_Position=1,表示这对主备关系使用了GTID协议)
Retrieved_Gtid_Set,是备库收到的所有日志的GTID集合;
Executed_Gtid_Set, 是备库所有已经执行完成的GTID集合。
如果这两个集合相同,也表示备库接收到的日志都已经同步完成。
比判断seconds_ behind_ master 是否为0更准确。
通常IO线程不会引起数据复制的较大延迟,除非网络问题导致连接断开,又或者网络延迟以及带宽存在瓶颈。
自动化环境中主库binlog被删除或损坏也是导致IO线程断开的一种原因。
在这里主要对SQL线程应用event的延迟问题展开分析:
备库/只读实例资源不够:
备库/只读实例除了需要应用数据变更之外,在承担查询任务时,可能需要更多的资源。
当发现备库存在延迟后,需要首先确认备库的资源使用情况。
主库高并发数据更新:
业务高峰期,主库大量并发的插入、删除和更新操作,QPS明显增加,产生大量的binlog文件。
这个时候备库应用event的速度跟不,延迟产生。
备库应用event的方式从最初的单线程演变和优化成当前的并行复制。
其中并行复制的实现方式在不同版本以及厂商之间存在差异,比如基于Schema并行复制,基于表并行复制,基于commit-parent的并行复制,基于lock-interval的并行复制等。
在备库开启组提交的并行复制,可以提高回放binlog性能减少延迟。
主库单表大量更新:
在row模式下,主库一个sql语句的数据库更改,会变成多个event复制到备库。
建议开发人员尽量分解大事务为小事务,并及时提交。
另外也见过一个用户在主库循环更新单个表数10万条数据的时间戳。
这种场景备库延迟会越来越大,备库始终追不上主库。
最后只能建议用户更改应用设计。
主库DDL操作:
大表DDL语句复制到备库执行时,会导致并行复制失效,后续事件无法更新,从而延迟累积。
这种场景会看到监控曲线成45度斜率增长。
在这里重点提一下,很多开发人员喜欢在主库频繁的使用optimize table操作,但是忽视了该语句容易导致备库延迟的问题。
由于DDL导致备库延迟的问题比较容易定位:
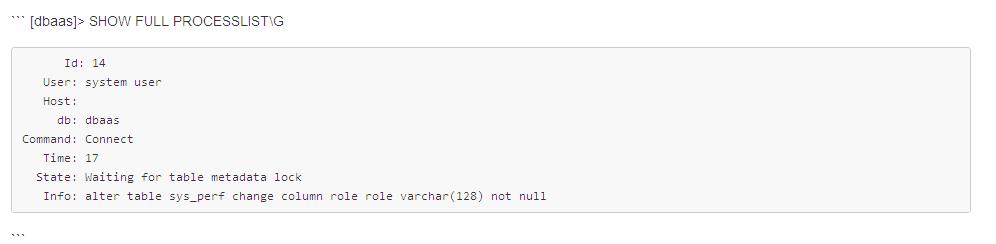
通过 "show processlist" 会话快照可以看到正在执行的DDL语句。
针对大表DDL导致延迟问题,有经验的DBA会选择关闭SQLLOGBIN参数后,备库手工执行DDL语句。
备库执行SQL语句慢:
在row模式下,缺少主键或适当的索引是导致SQL执行慢的主要原因。
线上云环境中,若用户创建表时未指定主键,数据库通常会自动引入隐式主键来避免该问题。
备库事务阻塞复制:
备库/只读实例长事务或未提交事务导致复制延迟或中止的情况容易被忽视。
比如备库开启事务,执行查询后并未提交;
这个时候主库过来的DDL语句会等待MDL锁;
而DDL语句会继续阻塞后续过来的其它事件执行。
下面选取其中一类问题通过场景化的描述简单的还原整个优化过程的逻辑。
针对只读实例开启事务执行查询后,不提交事务。
(注意:
开始事务只做查询是常见的错误使用方式。
这种操作不一定是开发人员显示的写在代码中,是所使用的框架导致的。
)
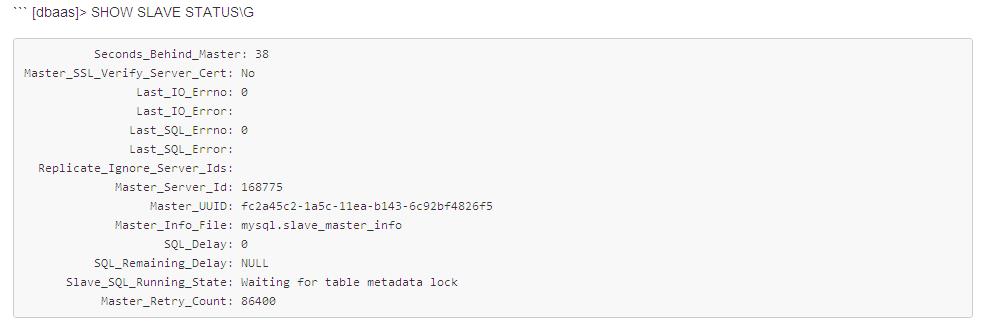
在只读实例上,我们可以通过一系列命令查看到复制延迟的原因。
备库复制状态信息中,可以看到当前SQL执行状态为 "Waiting for table metadata lock"。
另外通过会话快照也可以直接看到当前被阻塞的DDL语句:
数据库智能管家DBbrain会主动发现原因,提交或kill会话后,延迟立即消失:
主从延迟(复制延迟)虽然出现在大多数场景中对业务都会带来消极影响,但是在一些场景,人为手动设置“延迟”,能够完美的解决一些特殊的业务需求。
比如在将日志及时复制到备库,但有意的不立即应用的实现方式在容灾系统中经常采用。
容灾切换概率很低,但是可以利用现有的资源及时“回滚”误操作。
复制延迟是非常有价值的“撤消”选项。
例如,如果有人意外删除了MySQL数据库或表,则可以轻松地从延迟的MySQL从站恢复这些数据库和表。
MySQL已经支持 MASTER_DELAY 参数来实现类似功能。
MySQL在同步复制下耗时主要包含三个部分。
第一个是SQL部分,第二是存储引擎,第三部分是复制。
和异步相比,我们重点优化第三部分的延时。
复制延时主要有两部分:
第一部分是binlog网络传输过去的耗时,第二部分是slave落地binlog的延时。
binlog传输耗时取决于网络RTT值。
我们的优化重要集中在slave落地binlog的延时上。
在这次优化过程中,做了一个测试进行定量分析。
在全Cache下MySQL异步的情况下,单事务耗时是3.37ms,也就是说它的SQL加引擎一共耗时3.37ms,但是我们发现在半同步的情况下延时就变成了8.33ms,发现RTT是2.6ms,那么slave落地binlog就花费了1.9ms,那1.9ms是否合理呢?接着做了一个测试,模拟slave落地binlog的操作,发现只需要0.13ms,这里面其实有接近1.8ms的优化空间。
第二个就是如何提升系统吞吐。
当单个事务的延时降下来后,是不是就意味着整个系统的吞吐就上来了?这也未必,整个吞吐来说取决于两个因素,一个是支持的并发数,另外一个就是单个事务的延时。
假如有一些公共资源存在很大的竞争,那就可能存在并发数上不来了的问题,我们发现master的binlog发送/响应线程是有很大的优化空间的。
所以我们就基于这两个方面去做了系统吞吐的优化。
如何解决slave落地binlog的耗时呢?我们当时分析MySQL slave的IO线程接收binlog耗时的主要瓶颈有三个:
第一个就是锁冲突,IO/SQL线程间的锁冲突,如元数据文件锁;第二部分就是小IO消耗,IO线程离散小磁盘IO消耗过多的IOPS;第三个问题是串行化,IO线程接收和落盘操作串行。
迪B哥往期课程,请关注“腾讯云数据库 ”官方微信后,回复“迪B课堂”即可查看~
以上是关于DB诊断日 | 99%的DBA都想深入了解的MySQL故障的主要内容,如果未能解决你的问题,请参考以下文章