KOA实战系列之MongoDB篇
Posted 西厂XUX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KOA实战系列之MongoDB篇相关的知识,希望对你有一定的参考价值。
MongoDB的大名想必大家都耳熟能详了,特别是MongoDB本身文档型存储和javascript Shell的特性,对于前端攻城师来说就是天生好拍档啊。背靠Node.js生态圈,加上MongoDB,从前到后一把搞定那真是感觉爽爽的!
网上这个主题的文章已经太多太多了,本文仅从实战的角度出发,结合有详细代码的Github示例工程 ( ),说说koa如何搭配mongoose来操作MongoDB数据库,内容略长,如果有兴趣的话就请接着往下看吧!
安装MongoDB
安装和启动MongoDB服务不是本文重点,具体步骤也比较简单,请参考官方文档 ( )。如果你希望把MongoDB服务部署到生产环境,那就相对复杂了,这里推荐我觉得质量较高的几篇博文,仅供参考(文章是1-2年前的了,可能部分命令和配置与最新版本不符,但大体没啥问题,具体有需求自己查文档吧):
高可用的MongoDB集群 ( )
搭建高可用mongodb集群 ( )
模拟需求场景
既然是实战,肯定需要从现实的需求出发,那么我们来假定你目前在编写一个杂志出版方面的系统,有一个用来存储用户信息的表,主要包含以下信息:
用户名,含义不用说,在系统中不允许重复
密码,含义不用说,不能明文存储
角色,指当前用户在系统中的角色,一个用户可以同时有多种角色,可能的角色有:读者、作者、编辑、评论家
杂志,指和当前用户有关系的杂志列表,一个用户可以关联多本杂志,杂志需要存储名称和类型
创建时间,当前用户数据的创建时间
更新时间,当前用户数据最后一次被更新的时间
下面我们的所有需求就将围绕这个数据场景一一展开,后面将有一个冰(yu)雪(qiu)聪(bu)明(man)的PD妹子出现哦!!!
准备工作
首先建立Node工程,并在package.json中指定项目依赖的npm包,安装依赖包,具体过程不再赘述,仅说明一下示范项目依赖的包信息:
koa: 1.2.0 应用基础框架,koa当然是不二之选,因为v2并未作为当前默认的发布版,因此还是选择了1.x的最新版
koa-route: 2.4.2 koa的路由处理中间件,必不可少
mongoose: 4.4.19 本文的主角,基于Node.js的MongoDB的对象建模lib
既然mongoose是主角,那少不了要啰嗦几句。如果对传统数据库稍有了解(例如mysql),你可以简单的将mongoose理解为项目中的ORM中间层,TA负责将MongoDB的数据翻译成Javascript能够处理的对象,同时也将Javascript操作转换为MongoDB能够处理的命令。简单的说,有了TA,操作MongoDB数据库就简单多了!( )
连上MongoDB
要操作MongoDB,我们当然首先要与TA建立连接,这里我们简单处理,直接在应用入口脚本index.js中增加以下代码,在启动服务时就把连接建好,具体如下:
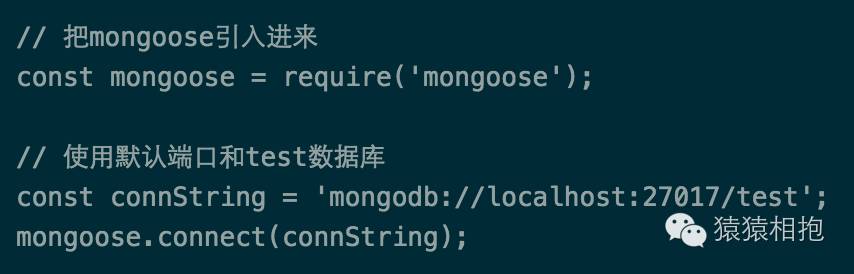
对于建立MongoDB连接,mongoose提供2种方式,一种就是上面的mongoose.connect,另外一种是mongoose.createConnection。那么这两种有什么不同呢?mongoose.connect方式创建的连接,是整个mongoose实例共享一个连接,所有的Model操作在会默认使用这个连接,不用显示的传递,在一般业务不复杂的情况下建议使用。而mongoose.createConnection则刚好相反,它会直接返回新创建的连接,该连接不会直接通过mongoose实例共享,而是需要自己显示的传递给Model后才能使用,这种方式一般在部署比较复杂,比如有多个MongoDB服务,不同的服务要采用不用的读写配置等等的情况下才需要使用。本文下述行文都基于mongoose.connect这种连接方式来展开。
建立用户表的模型
使用Mongoose,一切对MongoDB的操作都应该从Schema开始展开,每一个Schema都对应MongoDB数据库中的一个collection(集合),并且用来定义该collection中存储的文档结构。所以我们首先要做的就是在项目的models目录下新建模型文件user.js,目前内容如下,后面随着需求的增加我们将不断丰富这个Model脚本:
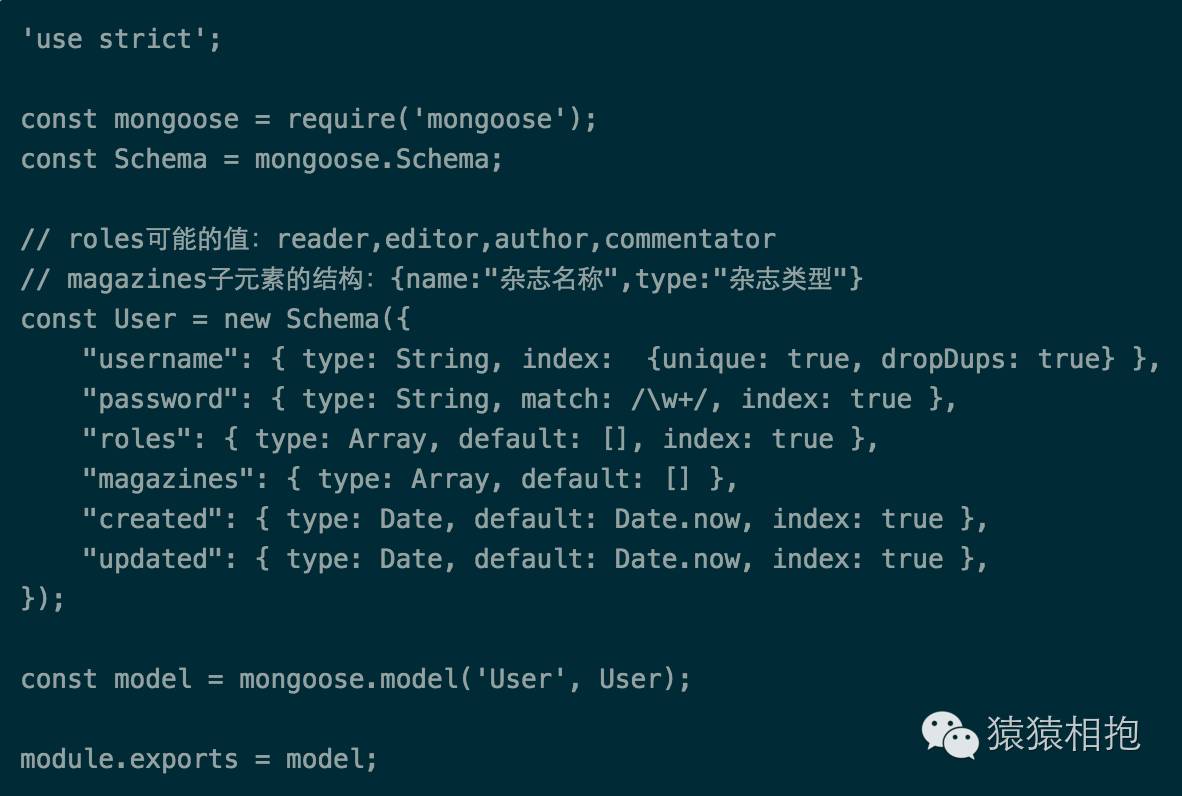
针对上述代码,主要说明5点:
Schema结构中的type,即该属性(称字段也可以)的数据类型,包含以下几种:String,Number,Date,Buffer,Boolean,Mixed,ObjectId,Array。其中ObjectId比较特殊,是MongoDB定义的一种类型,用来保存单个文档的唯一ID;
Schema结构中的index,即对属性索引的定义,true为加索引,false为不加索引,其中唯一索引的结构是一个对象
{unique: true, dropDups: true}。和传统数据库一样,索引是为了提高查询效率,是否需要索引根据具体查询需求而定。这里将username加了唯一索引,是为了从数据库层面就保证值得唯一性。index定义为可选,默认是false;Schema结构中的default,即属性的默认值,当新保存一个文档时如果Schema中已定义的属性的值为undefined,则会用default的值来填充。default的定义是可选的,如果保存时没有某个Schema中定义的属性且Schema中对该属性也没定义default,那么数据库中得该文档该属性就直接不会存在;
最后的
mongoose.model('User', User),Schema只是定义,最终要进行操作前必须用mongoose.model方法将Schema转换为Model才行;MongoDB存储的实际是一个大的JSON,因此collection下面的文档属性实际可以层层嵌套,内部无限复杂(当然实际应用中为了平衡效率,也不建议搞的太复杂),因此Schema的定义也是支持往下一层去定义的(有兴趣的可以了解Sub-documents),本文只规范和定义顶层属性。
开始接需求
下面就是真正的操作数据了,PD妹子将不断的给我们增加需求,来看看我们怎么利用mongoose把需求一个个搞定吧!!!
要新建用户(这个需求不要太合理哦~)
新建数据就是insert,一般都是给用户一个表单页面,用户填写完成提交,我们校验一下数据然后持久化存储,本文对这些前置处理就置之不理啦,主要来看看如果将数据持久化插入到MongoDB中:“翠花,上代码~”

关键点说明:
yield是啥? 额,问这个问题肯定是完全没接触过koa或者generator啊,赶快去补习吧!这里说明一下的是mongoose从v4开始就默认返回promise了(也就是yieldable啦),不用自己thunkify真幸福啊
新建文档的话,需要
new一个UserModel的新实例哦,就不是直接使用Model的静态方法操作了咦,说好的密码不能明文存储呢?不要做坑爹的程序员哦!哈哈,Schema setter大杀器出场啦,请看代码:

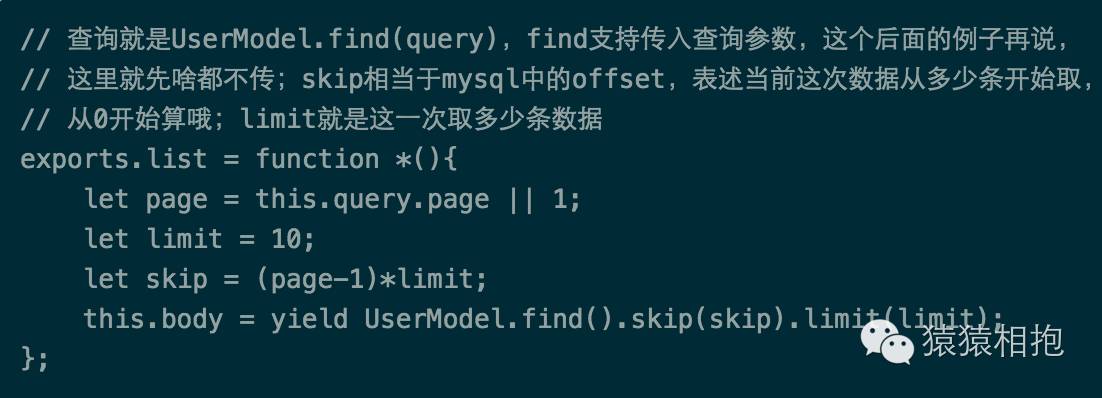
把现在所有的用户列出来(这个需求必须有!)
这个就是简单的读取数据啦,简直再简单不过了~ 哦,对了,现在不需要支持查询条件吧?先简单做,OK?
我要把所有的编辑列出来

早说嘛,这个小菜一碟
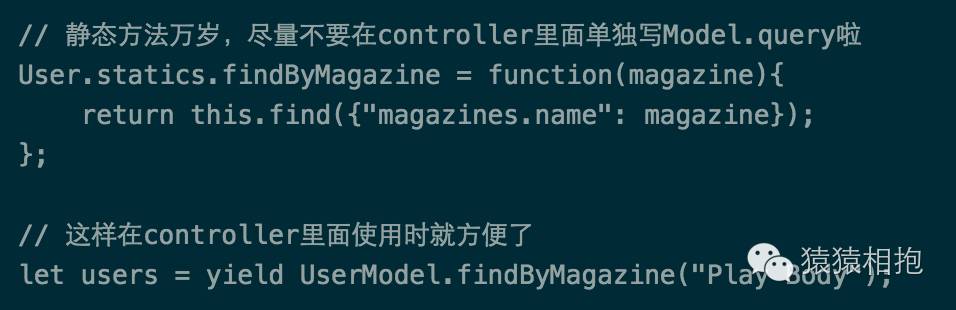
编辑是一种角色,我们是以数组的形式存储的,应该怎么判断呢?解决这个问题,首先要介绍一下Schema的另外一大特性,那就是静态方法。就是在定义Schema时可以通过statics属性定义很多方法,这些方法最终可以通过Model.functionName的方式静态调用,这样做的好处是,如果你得Model将来要在多个controllers中使用到的话,相应的代码逻辑你就只需要编写一次啦。不多说了,上代码:
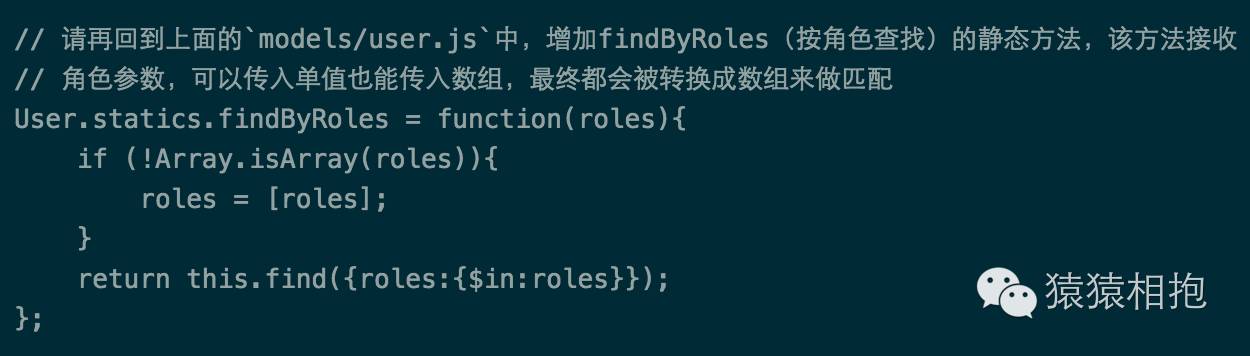
针对上述代码,说2个要点:
静态方法中,可以直接使用
this指针进行Model的各种操作对于数组的匹配方式,可以使用$in或$nin操作,$in只要字段值和传入的条件有交集(即1个子元素相同)就返回true,$nin正好相反,是完全没有重合的元素才返回true。关于$nin操作详情可以看实例项目中的
findJobless
要查找跟指定杂志有关系的用户

这个…
这个有点困难了,我们来回忆一下新建用户时杂志信息是怎么存储的magazines: [{name:"Play Boy", type:"entertainment"}]。magazines本身是一个数组,里面有包了一层对象,我们最终需要匹配子元素的name属性才能满足这一需求,这个咋整呢?哈哈,MongoDB的查询设计已经考虑到了,子集的属性可以直接用作为父对象的属性来匹配,是不是太抽象了?直接看代码吧,一看就明白!
新需求来啦!要变身
PD:有个用户最近转行,开始当编辑了,能不能在后台直接点个按钮就把身份和签约的杂志更新掉?
攻城师:这个,没有什么不可以!
数据更新是最基本的需求,那么使用mongoose应该怎么做呢?首先通过唯一的KEY查到需要更新的用户,然后更新属性并保存,so easy!

还记的我们最开始的需求吗?用户数据有个updated字段,需要每次数据变动后都要保存最后一次更新时间哦,这个需求里我们改变了用户数据,就需要做这个事情了,那该怎么做呢?你可能会想,那还不简单,直接user.updated = Date.now()然后再save不久可以了?对,这样是可以,但是不够通用哦,而且存在多种更新场景时很容易忘记对不对?下面祭出Schema的大杀器Middleware,请看代码:
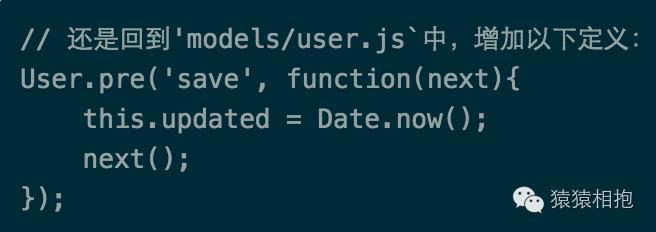
中间件机制其实很简单,看上去跟之前的express框架中间件玩法一模一样。首先,在Schema定义中使用pre方法,接收的第一个参数就是这个中间件的运行时机,pre当然就是在这个时间点之前的意思了,所以这里完整的含义就是在save方法执行前,请先执行我传的这个方法。需要注意的是,中间件方法中,this指代的是当前被save的文档对象,可以直接对其进行修改。其次,必须显示调用next方法,否则后续的操作就会被挂起了。
我保证这是最后一个需求!

终于可以做完收工啦
PD:现在,我要针对编辑在用户列表页面增加一个ICON显示,前端说接口要是能给一个boolean型的标记就方便了~,另外任何关联杂志都没有的,我们视为垃圾用户,就不要返回了。。。
工程师:我就是做前端的,我当然知道~(≧▽≦)/~啦啦啦,开挂!!!
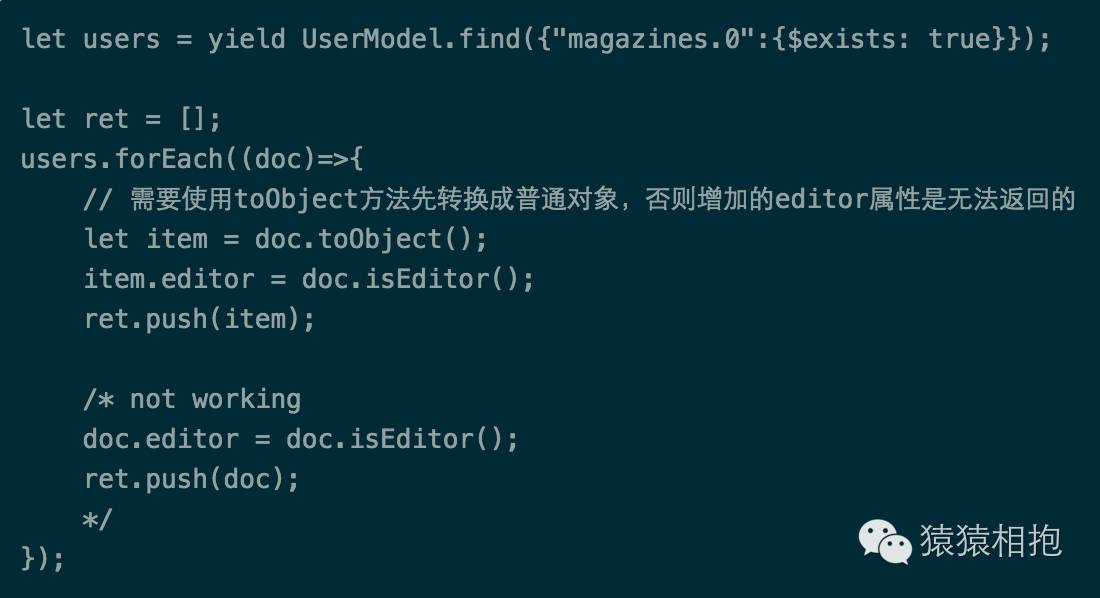
上述代码需要说明的问题有3个:
如何判断有没有关联杂志呢?我们最容易想到的是判断数组magazines的length属性,但是MongoDB不支持,不过TA提供了另外的方式,即$exists语法,所以我们可以通过判断数组magazines的第0个元素是否存在达到同样的效果;
toObject()方法,这个是文档对象的一个实例方法,使用此方法可以将文档对象转成一个普通对象。这个点需要特别注意,如果你在返回数据给前端之前需要修改文档的某些属性,是不能直接使用
doc.attr = newValue的方式来做的,因为文档对象不是一个Plain Object,而是mongoose内部对象。这个时候,你必须先使用toObject()方法将文档对象转换成普通对象,再修改这个普通对象的属性并将其返回;isEditor()方法,这个方法是我们自定义的一个Model的实例方法(注意哦,不再是静态方法了哦),具体定义方式如下:
好啦,我知道这篇文章确实太长了,估计很多人已经早就不耐烦了,能读到最后的我真是感激涕零,如果你有什么意见或建议,欢迎留言告诉我!
参考文献
以上是关于KOA实战系列之MongoDB篇的主要内容,如果未能解决你的问题,请参考以下文章