JDK10源码阅读--String
Posted 程序员灯塔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK10源码阅读--String相关的知识,希望对你有一定的参考价值。
String
jdk源码里对String的介绍:
String 是不可变的,一旦被创建其值不能被改变. String buffers 支持可变String.
因为String是不可变的, 所以它们可以被共享.
例如: String str = "abc";
等价于
char data[] = {'a', 'b', 'c'};String str = new String(data);源码中提供的其他使用String的例子:
System.out.println("abc");String cde = "cde";System.out.println("abc" + cde);String c = "abc".substring(2,3);String d = cde.substring(1, 2);String的方法包括检查字符串里的单个字符,比较字符串,搜索字符串,提取子字符串,创建字符串副本等.实例映射是基于Character中指定的Unicode标准.
Java语言为String的字符串连接符 + 提供特殊的支持, +也可以用于转换其他类型的对象为String.
除非另有说明,否则将null作为参数传递给构造方法或者方法会抛出NullPointerException异常.
String表示一个字符串通过UTF-16(unicode)格式,补充字符通过代理对(参见Character类的 Unicode Character Representations 获取更多的信息)表示。
索引值参考字符编码单元,所以补充字符在String中占两个位置。
1. String的定义
String不能被继承,因为String类有final修饰符.
同时String实现了3个接口:
java.io.Serializable:String类可序列化(白话解释: 把原本在内存中的对象状态 变成可存储或传输的过程称之为序列化。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上. )Comparable<String>:实现compareTo方法,String的对象列表(和数组)可以通过 Collections.sort(和 Arrays.sort )进行自动排序CharSequence:char值的一个可读字符序列.java public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
2. String的属性
所有属性如下图:

value[]
@Stableprivate final byte[] value;value 用来存储字符.(记得jdk8的这个value还是 char数组 不是byte数组. 特意下jdk9看了下,发现jdk9已经是byte数组了.)
从final关键字也可以看出,String一旦被初始化了就不能被更改.@Stable表示:表示此字段存储在字段中的第一个非null(相应,非零)值永远不会改变。( value不可能为null,从构造方法可以看出~ )
coder
private final byte coder;code是value中字节的编码标识符,现实中支持的是 LATIN1/UTF16
static final byte LATIN1 = 0;
static final byte UTF16 = 1;hash
private int hash;
缓存字符串的hashcode, 默认值为0
序列化serialVersionUID
private static final long serialVersionUID = -6849794470754667710L;private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0];String实现了Serializable接口,所以支持序列化和反序列化支持。Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常(InvalidCastException)。
COMPACT_STRINGS
static final boolean COMPACT_STRINGS;static {
COMPACT_STRINGS = true;}字符串压缩,该字段值由JVM注入.
3. String的构造方法
String作为java中最长用到的类,有很多重载的构造方法,如下图:

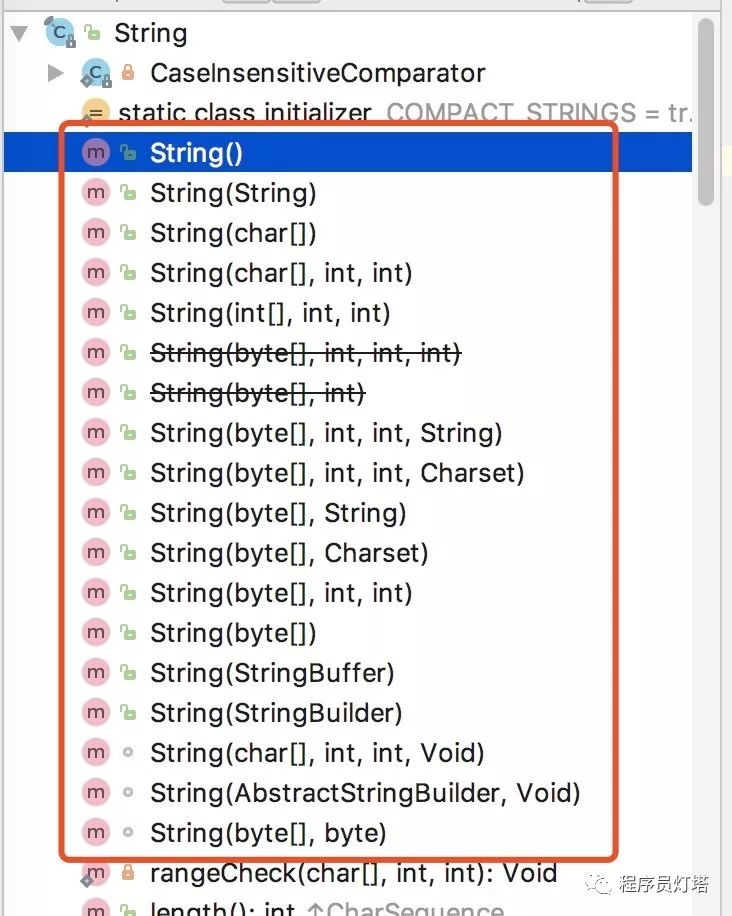
无参构造方法
构造一个空字符串,值得注意的是:因为String是不可变的,所以不必要使用这个构造方法
public String() {
this.value = "".value;
this.coder = "".coder;}以String为参数
初始化新创建的String对象,与其参数相同.(其实就是参数字符串的副本)
public String(String original) {
this.value = original.value;
this.coder = original.coder;
this.hash = original.hash;}使用字符数组组构造String
public String(char value[]) {
this(value, 0, value.length, null);}String(char[] value, int off, int len, Void sig) {
if (len == 0) {
this.value = "".value;
this.coder = "".coder;
return;
}
if (COMPACT_STRINGS) {
// compressedCopy char[] -> byte[]
byte[] val = StringUTF16.compress(value, off, len);
if (val != null) {
this.value = val;
this.coder = LATIN1;
return;
}
}
this.coder = UTF16;
this.value = StringUTF16.toBytes(value, off, len);
}String(char[] value, int off, int len, Void sig) 是私有构造方法 Void sig为了消除其他共有构造方法的歧义.
将char[]值存储到byte[]中.如果char[] 中仅包含latin1字符,则每个字节代表相应字符的8个低位. 或者是由一个byte[]存储StringUTF16中定义的字节序列中的所有字符.
在使用字符数组来创建一个新的String对象的时候,不仅可以使用整个字符数组,也可以使用字符数组的一部分,只要多传入两个参数int offset和int count就可以了,如下:
public String(char value[], int offset, int count) {
this(value, offset, count, rangeCheck(value, offset, count));
}offset是第一个字符的索引count是子数组的长度.
通过字节数组构造String
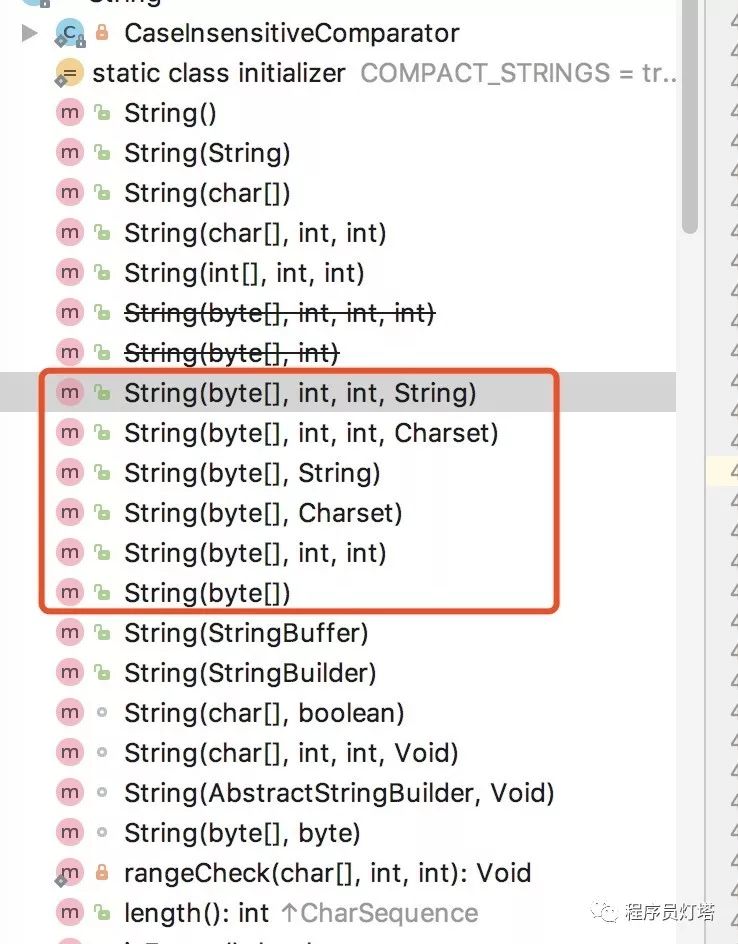

jdk10中,String内部就是用byte[]存储,上图红框中的构造方法中大同小异,
都是以byte[]为参数,两个int分别是:其实位置和子byte[]长度.
参数byte[]保存到String的byte[]中需要再次进行解码.String参数或者Charset参数是指定的字符集.
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBoundsOffCount(offset, length, bytes.length);
StringCoding.Result ret =
StringCoding.decode(charsetName, bytes, offset, length);
this.value = ret.value;
this.coder = ret.coder;
}如果没有指定字符集,默认使用ISO-8859-1进行解码.
static Result decode(byte[] ba, int off, int len) {
String csn = Charset.defaultCharset().name();
try {
// use charset name decode() variant which provides caching.
return decode(csn, ba, off, len);
} catch (UnsupportedEncodingException x) {
warnUnsupportedCharset(csn);
}
try {
return decode("ISO-8859-1", ba, off, len);
} catch (UnsupportedEncodingException x) {
// If this code is hit during VM initialization, err(String) is
// the only way we will be able to get any kind of error message.
err("ISO-8859-1 charset not available: " + x.toString() + "\n");
// If we can not find ISO-8859-1 (a required encoding) then things
// are seriously wrong with the installation.
System.exit(1);
return null;
}
}还有用StringBuilder和StringBuffer作为参数构造String, 但是基本不这样用,因为StringBuilder和StringBuffer都有.toString()方法.
4. String的一些方法
length
返回字符串的长度
public int length() {
return value.length >> coder();
}isEmpty
判断字符串是否为空
public boolean isEmpty() {
return value.length == 0;
}charAt
返回索引处的char值,范围为 0到length()-1,
序列第一位为0,下一位为1,依此类推
public char charAt(int index) {
if (isLatin1()) {
return StringLatin1.charAt(value, index);
} else {
return StringUTF16.charAt(value, index);
}
}equals
字符串与指定对象比较,结果为true表示参数是String对象并且与此对象有相同的字符序列.
public boolean equals(Object anObject) {
//同一个对象,为真
if (this == anObject) {
return true;
}
if (anObject instanceof String) {//String类型
String aString = (String)anObject;
if (coder() == aString.coder()) {//并且编码相同
//不同的编码,不同的比较方式
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}codePointAt
返回指定索引处的字符(Unicode code值.范围为 0到length()-1,
序列第一位为0,下一位为1,依此类推
public int codePointAt(int index) {
//latin1字符集
if (isLatin1()) {
checkIndex(index, value.length);
return value[index] & 0xff;
}
int length = value.length >> 1;
checkIndex(index, length);
// utf16字符集
return StringUTF16.codePointAt(value, index, length);
}
//例如:
System.out.println("A".codePointAt(0)); //结果为 65offsetByCodePoints
通过Unicode code值返回索引偏移位置
public int offsetByCodePoints(int index, int codePointOffset) {
if (index < 0 || index > length()) {
throw new IndexOutOfBoundsException();
}
return Character.offsetByCodePoints(this, index, codePointOffset);
}getChars
将此字符串中的字符复制到目标字符数组中.
/** * @param srcBegin要复制的字符串中第一个字符的索引。 * @param srcEnd索引要复制的字符串中的最后一个字符。 * @param dst目标数组。 * @param dstBegin目标数组中的起始偏移量。 * */public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
checkBoundsBeginEnd(srcBegin, srcEnd, length());
checkBoundsOffCount(dstBegin, srcEnd - srcBegin, dst.length);
if (isLatin1()) {
StringLatin1.getChars(value, srcBegin, srcEnd, dst, dstBegin);
} else {
StringUTF16.getChars(value, srcBegin, srcEnd, dst, dstBegin);
}
}getBytes
按照指定的字符集把String转成字节数组返回.
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, coder(), value);
}参数也可以是java.nio.charset.Charset 或者无参使用默认字符集


contentEquals
字符串与指定的CharSequence进行比较,只有当此字符串与参数有相同的char值序列是返回true.
可以看到方法中根据参数的类型不同而采用不同的比较方法,AbstractStringBuilder,String 都实现了CharSequence接口.
这个方法包含了equals(String)方法,当参数类型为String时,复用equals方法.
public boolean contentEquals(StringBuffer sb) {
return contentEquals((CharSequence)sb);
}
public boolean contentEquals(CharSequence cs) {
// Argument is a StringBuffer, StringBuilder
if (cs instanceof AbstractStringBuilder) {
if (cs instanceof StringBuffer) {
synchronized(cs) {
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
} else {
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
}
// Argument is a String
if (cs instanceof String) {
return equals(cs);
}
// Argument is a generic CharSequence
int n = cs.length();
if (n != length()) {
return false;
}
byte[] val = this.value;
if (isLatin1()) {
for (int i = 0; i < n; i++) {
if ((val[i] & 0xff) != cs.charAt(i)) {
return false;
}
}
} else {
if (!StringUTF16.contentEquals(val, cs, n)) {
return false;
}
}
return true;
}comepareTo
按字典顺序比较两个字符串。比较基于字符串中每个字符的Unicode值.
如果当前String对象按照字典顺序在参数字符串之前,则结果为负整数.
反之为负整数.
public int compareTo(String anotherString) {
byte v1[] = value;
byte v2[] = anotherString.value;
if (coder() == anotherString.coder()) {
return isLatin1() ? StringLatin1.compareTo(v1, v2)
: StringUTF16.compareTo(v1, v2);
}
return isLatin1() ? StringLatin1.compareToUTF16(v1, v2)
: StringUTF16.compareToLatin1(v1, v2);
}@param toffset此字符串中子区域的起始偏移量。
@param其他字符串参数。
@param ooffset字符串中子区域的起始偏移量
论据。
@param len要比较的字符数。
@return 如果指定该字符串的子区域完全匹配字符串参数的指定子区域返回true,否则返回false;public boolean regionMatches(int toffset, String other, int ooffset, int len)
从索引toffset开始的当前字符串的子串 是否以制定的prefix前缀开头. public boolean startsWith(String prefix, int toffset)
返回指定子字符串第一次出现的字符串中的索引。
public int indexOf(String str)
返回当前字符串的子串,从索引处开始直到字符串结尾.public String substring(int beginIndex)
例如:
"unhappy".substring(2) 返回 "happy"
"Harbison".substring(3) 返回 "bison"
"emptiness".substring(9) 返回 "" (an empty string)
返回一个子字符串,子字符串从指定的beginIndex开始,并扩展到索引endIndex-1处的字符。 因此子串的长度是endIndex-beginIndex
public String substring(int beginIndex, int endIndex) {
int length = length();
checkBoundsBeginEnd(beginIndex, endIndex, length);
int subLen = endIndex - beginIndex;
if (beginIndex == 0 && endIndex == length) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
```
例如:
"hamburger".substring(4, 8) 返回 "urge"
"smiles".substring(1, 5) 返回 "mile"
-----将参数字符串连接到此字符串的末尾
`public String concat(String str)`
例如:
"cares".concat("s") 返回 "caress"
"to".concat("get").concat("her") 返回 "together"-----返回替换所有出现的字符串.如果当前字符串中未出现oldChar,则返回当前字符串.`每次`出现的`oldChar` 都会被`newChar`替换.`public String replace(char oldChar, char newChar)`
例如:"the war of baronets".replace('r', 'y')返回 "the way of bayonets"-----判断此字符串是否与指定字符串匹配
`public boolean matches(String regex)`-----把当前字符串按照`regex`参数拆分,返回一个`String`数组.数组中的子串按它们在此字符串中出现的顺序排列.如果匹配不到`regex`则数组中只有一个元素,就是该字符串.limit 参数控制模式应用的次数,因此影响所得数组的长度。如果该限制 n 大于 0,则模式将被最多应用 n - 1 次,数组的长度将不会大于 n,而且数组的最后一项将包含所有超出最后匹配的定界符的输入。如果 n 为非正,那么模式将被应用尽可能多的次数,而且数组可以是任何长度。如果 n 为 0,那么模式将被应用尽可能多的次数,数组可以是任何长度,并且结尾空字符串将被丢弃。
`public String[] split(String regex, int limit) `
例如:``` java
String ss = "1,,5,6";String sss[] = ss.split(",",3);System.out.println(sss.length);//返回数组长度3,后面的5,6会被合并为一项把字符串所有字符转成(大写/小写) 返回新的字符串.java
public String toLowerCase()
public String toUpperCase()
其他对象转成String
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}
public static String valueOf(char data[]) {
return new String(data);
}
public static String valueOf(char data[], int offset, int count) {
return new String(data, offset, count);
}
public static String valueOf(boolean b) {
return b ? "true" : "false";
}
public static String valueOf(char c) {
if (COMPACT_STRINGS && StringLatin1.canEncode(c)) {
return new String(StringLatin1.toBytes(c), LATIN1);
}
return new String(StringUTF16.toBytes(c), UTF16);
}
public static String valueOf(int i) {
return Integer.toString(i);
}
public static String valueOf(long l) {
return Long.toString(l);
}
public static String valueOf(float f) {
return Float.toString(f);
}
public static String valueOf(double d) {
return Double.toString(d);
} 最近公司和家里的事情都比较多,抽时间看了下String的源码,并不是非常的细致. 其实可以发现,因为String内部两种不同的编码集, 好多主要的代码都在StringLatin1中和StringUTF16中.
END
©程序员灯塔

关注互联网+大数据相关技术
share-面试进阶+技术干货
以上是关于JDK10源码阅读--String的主要内容,如果未能解决你的问题,请参考以下文章