云计算时代,容器底层cgroup如何实现资源分组?
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云计算时代,容器底层cgroup如何实现资源分组?相关的知识,希望对你有一定的参考价值。
《精通Linux内核—智能设备开发核心技术》已经出版了,但五年不间断地写作已经养成了习惯,或者说是书写完了,但我意犹未尽。
写书的时候需要考虑的因素太多,哪些重点讨论,哪些一笔带过,要不要讨论硬件原理,要不要贴代码等等,甚至在写作的初期,称呼上“我”、“我们”、“大家”选哪个都要纠结一下。太难,曲高和寡,不实用;太易,形同注水,多此一举。这些问题一一克服之后,写作顺畅了,写作水平有所提高,不能就此打住。
内核很复杂,写书也不可能面面俱到,有一些内容没有在书里讨论,另外技术在更新,我也在不断学习,把这些内容总结下也有必要。
偶然间翻起了之前的博客,13 年在 cu 写过两篇博客之后,虽然已经荒废掉了,到现在博客浏览量 25000,帖子浏览量也八九千了,也被转载了几次,看来博客还是有人看的(手动狗头哈哈)。
于是我又有了继续写博客的冲动,感谢 OSC 提供了这个交流平台,接下来我会陆续更新《Linux 内核出家指南》系列文章。
整个系列大概会涉及以下内容:
1.cgroup 概述:包括 cgroup 的数据结构、初始化和使用等,3篇。
2.如何梳理内核代码:面向应用工程师和驱动工程师,2篇。
3.内存管理:内存回收等,3篇以上。
4.进程通信:socket通信等,3篇。
5.内核更新:核心模块在新版本内核上的变化,3篇。
6.大家感兴趣的其他话题(欢迎留言,私信),n篇。
有些内容比如内存管理、进程通信,书里面已经讨论很多了,这个系列集中讨论书以外的内容。手头有书的同学可以参考,没有的也不会影响理解。
一、cgroup 概述
云计算和虚拟化想必大家多少都有些了解,一个大型的系统支持多个用户使用,每个用户能够使用的资源是有限制的(多半是付费越多资源越多)。如何限制资源的使用呢,容器可以做到(比如 Docker)。至于容器的底层实现,就要说到本章的主角——cgroup 了。
测试环境版本信息:
本文以及接下来的系列文章中,代码测试环境均为 Ubuntu 系统 + 5.5.5 内核,首先声明我本人并不抽烟(如果你不明白 555 和抽烟的关系,值得恭喜),选这个版本纯属巧合。如果几年后选择了 6.6.6版本,可能就真是有意的了。另外,在没有特指的情况下,“书”指的是《精通Linux内核—智能设备开发核心技术》这本书,我们讨论的内容集中于书外,但内容上会呼应起来。接下来还会有一系列的讨论,可以算是这本书的续作吧,有感兴趣的话题欢迎留言。
1.1简介
cgroup 的名称源自 “control group”,是 Linux 内核中的一个重要功能,用来控制进程组的资源。cgroup 支持多种资源的管理,管理不同的资源使用的操作有所不同,但原理上都是一样的,本文我们以限制进程只能在限定的 cpu 上运行为例展开讨论。
cgroup 底层是由文件系统实现的,文件系统名是 cgroup 和 cgroup2,分别对应 cgroup v1 和 v2 两个版本,本章分析 v1,有需要的话后续分析 v2。
既然是文件系统,那我们就从 mount 开始,mount cgroup 文件系统时使用 -o 参数指定我们将要使用哪种(也可以是多种,逗号隔开)cgroup 子系统(限制某种资源使用的系统)即可。
这里简单说明一下,一个文件系统首先要挂载到系统中才能被看到,这就是第一个操作 mount 。用户空间可以调用 mount 函数挂载文件系统。mount 本身是一个系统调用,入口为 sys_mount,将参数从用户空间复制到内核,然后调用 do_mount 实现。
很多 Linux 操作系统已经为我们 mount 好了,这从侧面说明系统默认的 mount 已经可以满足大多数需求了,一般不需要更改,如下。
//自行mount:mount -t cgroup -o subsys_name name dir …
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (…,net_cls,net_prio)
cgroup on /sys/fs/cgroup/blkio type cgroup (…,blkio)
cgroup on /sys/fs/cgroup/rdma type cgroup (…,rdma)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (…,hugetlb)
cgroup on /sys/fs/cgroup/pids type cgroup (…,pids)
cgroup on /sys/fs/cgroup/devices type cgroup (…,devices)
cgroup on /sys/fs/cgroup/cpuset type cgroup (…,cpuset)
cgroup on /sys/fs/cgroup/freezer type cgroup (…,freezer)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (…,cpu,cpuacct)
cgroup on /sys/fs/cgroup/perf_event type cgroup (…,perf_event)
cgroup on /sys/fs/cgroup/memory type cgroup (…,memory)
我们要分析的“限制进程只能在限定的cpu上运行”使用的是 cpuset 子系统,也就是 /sys/fs/cgroup/cpuset 目录。
love_cc@yahua:~$ cd /sys/fs/cgroup/cpuset
love_cc@yahua:/sys/fs/cgroup/cpuset$ ls
cgroup.clone_children cpuset.cpus cpuset.mem_hardwall cpuset.memory_spread_page cpuset.sched_relax_domain_level
cgroup.procs cpuset.effective_cpus cpuset.memory_migrate cpuset.memory_spread_slab notify_on_release
cgroup.sane_behavior cpuset.effective_mems cpuset.memory_pressure cpuset.mems release_agent
cpuset.cpu_exclusive cpuset.mem_exclusive cpuset.memory_pressure_enabled cpuset.sched_load_balance tasks
(PS:emm,看到“love_cc”,可能有人会问 cc 是谁,本着认真负责的原则回答下,love_cc 其实就是我的昵称“二如公子”,爱码如痴,爱猫如醉,cc就是猫和码。)
继续正题,mount 后,使用 list 命令我们可以发现目录下多了很多文件,这些文件是在mount 的时候 cgroup 创建的,这可能跟一般的文件系统有所不同。cgroup 确实是一个文件系统,但事实上如果有人说 cgroup 只是借 VFS 的壳实现自身的逻辑,也是可以理解的,完全可以采用其他的方式实现(比如 ioctl)。从这个角度来讲,它简直是一只披着羊皮的狼。
ioctl (IO Control), 顾名思义,它可以用来控制设备的 IO 等操作,它也是内核提供的系统调用,入口是 sys_ioctl。sys_ioctl 调用 do_vfs_ioctl 实现,它先处理内核定义的普遍适用的 cmd,比如 FIOCLEX 将文件描述符的 close_on_exec 置位;然后调用 vfs_ioctl 处理文件的 ioctl 定义专属的命令。
另外,在这些多出来的文件中,看名字可以发现有些与 cpu 有关,有些与 memory 有关。的确,cpuset 除了我们本章要讲的功能外,还有限制进程使用特定 memory node的能力。
节点(node)与 NUMA(Non Uniform Memory Access Architecture,非统一内存访问)架构有密切联系,传统的 SMP 架构中,所有的 CPU 共享系统总线,限制了内存的访问能力,NUMA 的引入一定程度上解决了该瓶颈。NUMA 的节点通常由一组CPU 和本地内存组成,系统中会存在多个节点,每一个节点都有自己的 zone 。这也是 cgroup 将 cpu 和 memory node 放在同一个子系统中的原因。
第二步是创建一个组(cgroup),使用的是 mkdir 操作,如下:
love_cc@yahua:/sys/fs/cgroup/cpuset$ sudo mkdir cpuset0
love_cc@yahua:/sys/fs/cgroup/cpuset$ cd cpuset0/
love_cc@yahua:/sys/fs/cgroup/cpuset/cpuset0$ ls
cgroup.clone_children cpuset.cpus cpuset.mem_exclusive cpuset.memory_pressure cpuset.mems notify_on_release
cgroup.procs cpuset.effective_cpus cpuset.mem_hardwall cpuset.memory_spread_page cpuset.sched_load_balance tasks
cpuset.cpu_exclusive cpuset.effective_mems cpuset.memory_migrate cpuset.memory_spread_slab cpuset.sched_relax_domain_level
插一句,即便是自己的系统,也尽量不要直接使用 root 用户进行操作,防止在不经意间犯错,养成好的习惯对职业生涯帮助很大。
接下来就是将进程纳入组内了,写文件即可,如下:
love_cc@yahua:/sys/fs/cgroup/cpuset$ pwd #注意,是cpuset目录
/sys/fs/cgroup/cpuset
love_cc@yahua:/sys/fs/cgroup/cpuset$ cat cpuset.cpus
0-3 #我的系统,cpu 0-3,4个cpu
root@yahua:/sys/fs/cgroup/cpuset # cat /proc/self/cgroup
…
3:cpuset:/
…
love_cc@yahua:/sys/fs/cgroup/cpuset$ cd cpuset0/
root@yahua:/sys/fs/cgroup/cpuset/cpuset0# echo 0-2 > cpuset.cpus
root@yahua:/sys/fs/cgroup/cpuset/cpuset0# echo 0 > cpuset.mems
root@yahua:/sys/fs/cgroup/cpuset/cpuset0# echo $$ > tasks
root@yahua:/sys/fs/cgroup/cpuset/cpuset0# cat /proc/self/cgroup
…
3:cpuset:/cpuset0
…
root@yahua:/sys/fs/cgroup/cpuset/cpuset0# cat /proc/self/status
…
Cpus_allowed: 07
Cpus_allowed_list: 0-2
…
1.2 数据结构
cgroup 文件系统 mount 的时候指定了子系统,由 cgroup_subsys 结构体表示(以下简称为ss),主要字段如下:
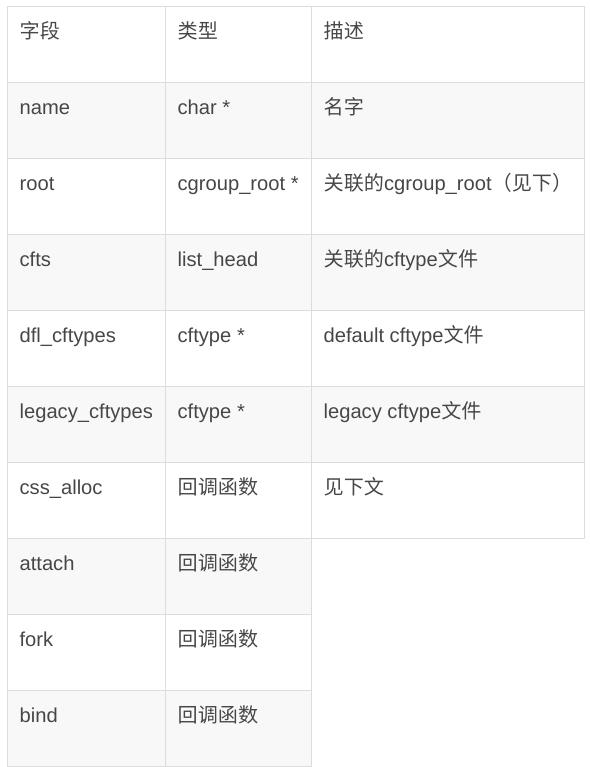
内核中支持的 ss 是有限的,不支持动态创建新的 ss,最多(支持的种类与 CONFIG 有关)支持 cpu、cpuset、memory 等十几种,实际支持的种类数量由CGROUP_SUBSYS_COUNT 表示。
系统启动的过程中会初始化系统支持的所有的 ss,其中最重要的是它关联的 cftype 文件。mount 和 mkdir 的时候创建的一系列文件实际上就是它们,稍后详解。
我们使用 mount 和 mkdir 建立了一个层级结构,尝试创建更多目录,比如 cpuset 目录下继续创建 cpuset2,cpuset1 目录下创建 cpuset1_1 目录。在这个层级结构中,每一个目录都有限制进程使用 cpu 的功能。在内核中它们背后都有一个 cgroup 对象与之对应,这个目录层级结构其实也是一个 cgroup 层级结构。cgroup 结构体的主要字段如下:
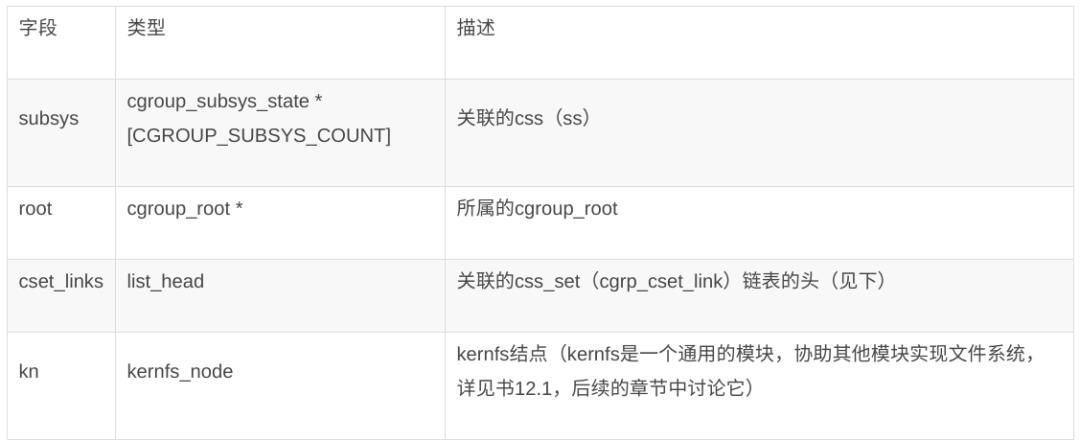
mount 的时候可以指定多个 ss,一个 ss 与整个层级结构中的 cgroup 都有关联,二者显然是多对多的关系。值得注意的是,ss 的数量是有限的,而且一个类型的 ss 最多只能与一个 cgroup 层级结构绑定(见下),所以使用 subsys 字段表示与某 cgroup 关联的所有 ss 即可,类型为 cgroup_subsys_state(以下简称css)指针数组。
cgroup->subsys 定位与之关联的 ss,那 ss 是如何知道哪些 cgroup 与它关联呢?答案就在 ss 的 root 字段中,类型为 cgroup_root 指针。
顾名思义,cgroup_root 就是 cgroup 的 root,它是整个 cgroup 层级结构的根,通过它可以找到与 ss 相关的 cgroup。而 cgroup_root 内嵌了一个 cgroup,字段名为 cgrp,它本身也是一个 cgroup,只不过自身同时也是 root。另外,指针的指向是唯一的,这也说明一个 ss 最终只能绑定一个 cgroup 层级结构。
既然 cgroup 也是层级结构,那么它们的层级关系是如何维护的呢?是通过 css 实现的,所以 css 有两方面作用,一是辅助实现 ss 和 cgroup 之间的多对多关系,二是维护cgroup 之间的层级结构,主要字段如下:
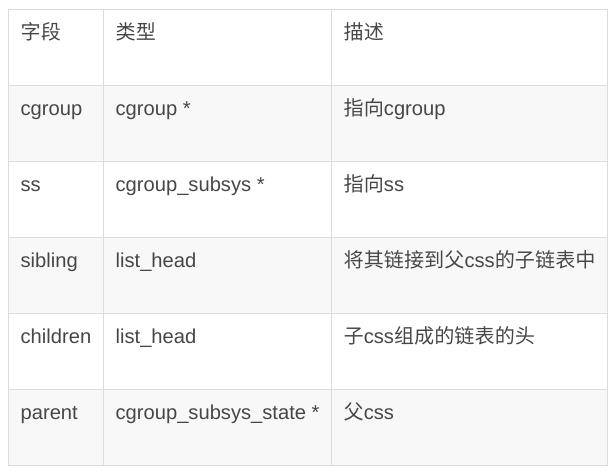
cgroup 和 ss 两个字段辅助实现二者的多对多关系,其余几个字段用来维护 cgroup 的层级结构。需要强调的是,ss 可以关联多个 cgroup,指的是一个层次结构中的cgroup,并不是多个层级结构,ss 最终只能关联一个层级结构的原则不变,别混淆了。
在我们的例子中,ss、cgroup 和 css 的关系如下图:
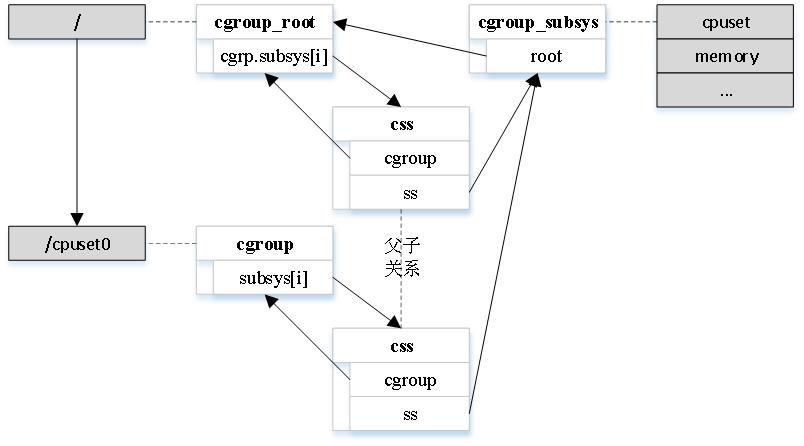
cgroup 最终要作用到进程上面,进程和 cgroup 的关系是如何维护的呢?最直接的反应就是进程维护一组和它关联的 css,css 维护它的进程链表。这种方案是可行的,但实际使用过程中,多个进程有可能关联同一组 css,那么维护一组组 css,让与之关联的进程直接指向某一组 css,会是更好的方案。一方面可以节省内存,另一方面可以加速进程创建的过程。
于是乎,css_set 结构体登场了,这里的“set”是集合的意思,也就是一组 css,进程描述符 task_struct 的 cgroups 字段就是 css_set 指针类型,也就是进程指向一个 css_set 对象(某一组 css)。
Linux 内核定义了 task_struct 结构体表示一个进程,它的字段非常多,有些是用来表示进程状态和标志的,还有一些表示进程使用的资源,还有的涉及进程调度、信号处理和进程通信等。
这么做是有前提的,对一个系统而言,ss 的种类固定,cgroup 层级结构和 cgroup 本身的数量也不是无限多的,所以 css_set 的数量也不会太多。脱离了这个前提,节省内存也无从谈起。
css_set 的主要字段如下:
一个 css_set 可以关联多个 cgroup 层级结构,也就是多个 cgroup,这点容易理解。一个 cgroup 也可以关联多个 css_set,比如 /cpuset0 和 /memory0 等组成一个 css_set,也可以和 /memory1 组成一个 css_set,如下图:
所以,css_set 和 cgroup 也是多对多的关系,该关系由 cgrp_cset_link 结构体辅助实现。(标准的多对多关系实现,两个实体,加上一个辅助结构体。)
cgroup 存在两种多对多的关系,cgroup 与 ss,cgroup 与 css_set,前者是 cgroup 内部实现,后者解决了进程和 cgroup 关联的问题,不要混淆。以上结构体省略了一些与cgroup v2 有关的字段,cgroup 的实现将 v1 和 v2 交织在了一起,增加了理解难度。后文中讨论代码逻辑的时候也会做类似处理。
第一篇到此结束,虽然意犹未尽。熟悉了整体结构之后,留几个问题供大家思考,我们在接下来的篇章中揭晓答案。
cgroup 的使用有诸多限制,举几个例子:
cpuset 目录下不能修改 cpu、memory 资源的限制,逻辑上理应如此,因为它是所有子 cpuset 类的 cgroup 的根,把它改了就没有进程可以使用所有资源了。
子 cgroup 对资源的限制范围只能是父 cgroup 的子集,比如我们在 /cpuset0 限制cpu 为 0-2,在 cpuset0 目录下创建一个子目录 cpuset0_1,尝试限制 cpu 为 2-3,会失败。
root@yahua:/sys/fs/cgroup/cpuset/cpuset0/cpuset0_1# echo 2-3 > cpuset.cpus
bash: echo: write error: Permission denied
这些限制可以怎么实现?
我们在 mount 和 mkdir 的时候,cgroup 为我们创建了一系列文件,上文已经说了它们对应了 cftype 结构体,大体过程是怎样的(送分题)?
作者介绍:
姜亚华(@二如公子 ),一直从事与 Linux 内核和 Linux 编程相关的工作,研究内核代码十多年,对多数模块的细节如数家珍。曾负责华为手机 Touch、Sensor 的驱动和软件优化(包括 Mate、荣耀等系列),以及 Intel 安卓平台 Camera 和 Sensor 的驱动开发(包括 Baytrail、Cherrytrail、Cherrytrail CR、Sofia 等)。现负责 DMA、Interrupt、Semaphore 等模块的优化与验证(包括 Vega、Navi 系列和多款 APU 产品)。
以上是关于云计算时代,容器底层cgroup如何实现资源分组?的主要内容,如果未能解决你的问题,请参考以下文章
centos7下安装docker(10容器底层--cgroup和namespace)
实现容器的底层技术 - 每天5分钟玩转 Docker 容器技术(30)