数据库表的设计用 自增长int类型字段做主键,插入数据时怎么保证这条记录在表中是唯一的呢
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库表的设计用 自增长int类型字段做主键,插入数据时怎么保证这条记录在表中是唯一的呢相关的知识,希望对你有一定的参考价值。
SQL Server 通过 IDENTITY 来设置
参数有2个,一个是“初始值” 一个是“增量”。
默认情况下 INSERT 语句中,不能对 IDENTITY 的字段进行赋值。
对于 IDENTITY 的列 SQL Server 在 INSERT 的时候,会自动忽略掉。
2> id INT IDENTITY(1, 1) PRIMARY KEY,
3> val VARCHAR(10)
4> );
5> go
1> INSERT INTO test_create_tab2(val) VALUES ('NO id');
2> go
(1 行受影响)
1> INSERT INTO test_create_tab2(id, val) VALUES (6, 'id no use');
2> go
消息 544,级别 16,状态 1,服务器 HOME-BED592453C\\SQLEXPRESS,第 1 行
当 IDENTITY_INSERT 设置为 OFF 时,不能为表 'test_create_tab2' 中的标识列插入显式值。
1> INSERT INTO test_create_tab2(val) VALUES ('A');
2> INSERT INTO test_create_tab2(val) VALUES ('B');
3> INSERT INTO test_create_tab2 VALUES ('C');
4> INSERT INTO test_create_tab2 VALUES ('D');
5> go
1> SELECT * FROM test_create_tab2;
2> go
id val
----------- ----------
1 NO id
2 A
3 B
4 C
5 D
(5 行受影响)追问
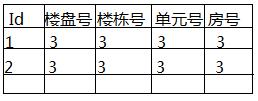
我的问题是如何保证除主键外其他的字段的信息不重复,例如下图。
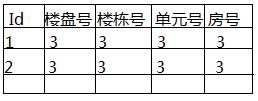
除了使用unique(’楼盘号‘,'楼栋号','单元号',’房号‘)这种笨拙的办法,还有其他更好的方法吗?以为如果一个表有上百个字段时,这样干是很不现实的。
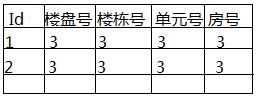
我的问题是如何保证除主键外其他的字段的信息不重复,例如下图。
除了使用unique(’楼盘号‘,'楼栋号','单元号',’房号‘)这种笨拙的办法,还有其他更好的方法吗?以为如果一个表有上百个字段时,这样干是很不现实的。
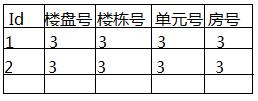
可以用触发器
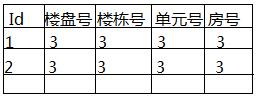
本回答被提问者采纳 参考技术B 插入数据时,这个字段不需要赋值的,数据库会自动计算好下一条数据的ID。追问我的问题是如何保证除主键外其他的字段的信息不重复,例如下图。
除了使用unique(’楼盘号‘,'楼栋号','单元号',’房号‘)这种笨拙的办法,还有其他更好的方法吗?以为如果一个表有上百个字段时,这样干是很不现实的。
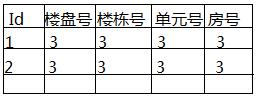
方法一:将(’楼盘号‘,'楼栋号','单元号',’房号‘)设置为唯一索引;
方法二:将(’楼盘号‘,'楼栋号','单元号',’房号‘)和Id设置为联合主键;
方法三:插入新记录前,先检索一下数据库,若有重复记录,则不插入。
数据库主键到底是用自增长(INT)好还是UUID好
其实针对使用自增长还是UUID,大家讨论最多的就是速度和存储空间,这里我加入了安全性和分布式,具体对比如下:
使用自增长做主键的优点:
1、很小的数据存储空间
2、性能最好
3、容易记忆
使用自增长做主键的缺点:
1、如果存在大量的数据,可能会超出自增长的取值范围
2、很难(并不是不能)处理分布式存储的数据表,尤其是需要合并表的情况下
3、安全性低,因为是有规律的,容易被非法获取数据
使用GUID做主键的优点:
1、它是独一无二的,出现重复的机会少
2、适合大量数据中的插入和更新操作,尤其是在高并发和分布式环境下
3、跨服务器数据合并非常方便
4、安全性较高
使用GUID做主键的缺点:
1、存储空间大(16 byte),因此它将会占用更多的磁盘空间
2、会降低性能
3、很难记忆
结合每个项目的实际应用,我们应该怎么选择呢?如下:
1、项目是单机版的,并且数据量比较大(百万级)时,用自增长的,此时最好能考虑下安全性,做些安全措施。
2、项目是单机版的,并且数据量没那么大,对速度和存储要求不高时,用UUID。
3、项目是分布式的,那么首选UUID,分布式一般对速度和存储要求不高。
4、项目是分布式的,并且数据量达到千万级别可更高时,对速度和存储有要求时,可以用自增长。
现在有人就会问了,为什么不直接用第4种方案,它满足前面三种方案的所有要求?就是因为在用自增长时分布式处理会很复杂(具体方案可以百度),在资源有限的情况可以采用前面三种简单的实现方案。
那么,为什么一定要使用自增长或UUID作为数据库主键呢?有没有更好的解决方案呢?肯定有:snowflake
其实大部分项目可以使用twitter的snowflake来生成主键,snowflake生成的主键就是介于自增长和UUID之间的一种主键(存储空间小、速度快、分布式、时间序列)。据说snowflake每秒能够产生26万个ID,最多可以部署在1024个节点上,研发团队可以将snowflake作为底层的数据库主键工具类供团队成员使用。
我自己的观点是:对于项目中涉及到的业务名称表的主键用UUID,而业务与业务之间的关系表的主键用自增;
转载至: http://www.yyjjssnn.cn/articles/754.html
以上是关于数据库表的设计用 自增长int类型字段做主键,插入数据时怎么保证这条记录在表中是唯一的呢的主要内容,如果未能解决你的问题,请参考以下文章