在datatable中能把某字段按照首字母拼音顺序排列么?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在datatable中能把某字段按照首字母拼音顺序排列么?相关的知识,希望对你有一定的参考价值。
谢谢。
参考技术A datatable.select() 参考技术B 一、排序1 获取DataTable的默认视图
2 对视图设置排序表达式
3 用排序后的视图导出的新DataTable替换就DataTable
(Asc升序可省略,多列排序用","隔开)
一、重生法
dstaset.Tables.Add(dt)
dataset.Tables(0).DefaultView.Sort = "id desc"
二、直接法
dv = New DataView(dt)
dv.Sort = "id desc"
dt = dv.ToTable();
三、间接法
dv = New DataView(ds.Tables[0])
dv.Sort = "id desc"
dt = dv.ToTable();本回答被提问者采纳
C# 获取汉字拼音首字母
最近悟出来一个道理,在这儿分享给大家:学历代表你的过去,能力代表你的现在,学习代表你的将来。
十年河东十年河西,莫欺少年穷
学无止境,精益求精
本节探讨C#获取汉字拼音首字母的方法:
代码类东西,直接上代码:
/// <summary> /// 在指定的字符串列表CnStr中检索符合拼音索引字符串 /// </summary> /// <param name="CnStr">汉字字符串</param> /// <returns>相对应的汉语拼音首字母串</returns> public static string GetSpellCode(string CnStr) { string strTemp = ""; int iLen = CnStr.Length; int i = 0; for (i = 0; i <= iLen - 1; i++) { strTemp += GetCharSpellCode(CnStr.Substring(i, 1)); break; } return strTemp; } /// <summary> /// 得到一个汉字的拼音第一个字母,如果是一个英文字母则直接返回大写字母 /// </summary> /// <param name="CnChar">单个汉字</param> /// <returns>单个大写字母</returns> private static string GetCharSpellCode(string CnChar) { long iCnChar; byte[] ZW = System.Text.Encoding.Default.GetBytes(CnChar); //如果是字母,则直接返回首字母 if (ZW.Length == 1) { return CommonMethod.CutString(CnChar.ToUpper(),1); } else { // get the array of byte from the single char int i1 = (short)(ZW[0]); int i2 = (short)(ZW[1]); iCnChar = i1 * 256 + i2; } // iCnChar match the constant if ((iCnChar >= 45217) && (iCnChar <= 45252)) { return "A"; } else if ((iCnChar >= 45253) && (iCnChar <= 45760)) { return "B"; } else if ((iCnChar >= 45761) && (iCnChar <= 46317)) { return "C"; } else if ((iCnChar >= 46318) && (iCnChar <= 46825)) { return "D"; } else if ((iCnChar >= 46826) && (iCnChar <= 47009)) { return "E"; } else if ((iCnChar >= 47010) && (iCnChar <= 47296)) { return "F"; } else if ((iCnChar >= 47297) && (iCnChar <= 47613)) { return "G"; } else if ((iCnChar >= 47614) && (iCnChar <= 48118)) { return "H"; } else if ((iCnChar >= 48119) && (iCnChar <= 49061)) { return "J"; } else if ((iCnChar >= 49062) && (iCnChar <= 49323)) { return "K"; } else if ((iCnChar >= 49324) && (iCnChar <= 49895)) { return "L"; } else if ((iCnChar >= 49896) && (iCnChar <= 50370)) { return "M"; } else if ((iCnChar >= 50371) && (iCnChar <= 50613)) { return "N"; } else if ((iCnChar >= 50614) && (iCnChar <= 50621)) { return "O"; } else if ((iCnChar >= 50622) && (iCnChar <= 50905)) { return "P"; } else if ((iCnChar >= 50906) && (iCnChar <= 51386)) { return "Q"; } else if ((iCnChar >= 51387) && (iCnChar <= 51445)) { return "R"; } else if ((iCnChar >= 51446) && (iCnChar <= 52217)) { return "S"; } else if ((iCnChar >= 52218) && (iCnChar <= 52697)) { return "T"; } else if ((iCnChar >= 52698) && (iCnChar <= 52979)) { return "W"; } else if ((iCnChar >= 52980) && (iCnChar <= 53640)) { return "X"; } else if ((iCnChar >= 53689) && (iCnChar <= 54480)) { return "Y"; } else if ((iCnChar >= 54481) && (iCnChar <= 55289)) { return "Z"; } else return ("?"); }
截取字符串的方法:
#region 截取字符长度 static string CutString(string str, int len) /// <summary> /// 截取字符长度 /// </summary> /// <param name="str">被截取的字符串</param> /// <param name="len">所截取的长度</param> /// <returns>子字符串</returns> public static string CutString(string str, int len) { if (str == null || str.Length == 0 || len <= 0) { return string.Empty; } int l = str.Length; #region 计算长度 int clen = 0; while (clen < len && clen < l) { //每遇到一个中文,则将目标长度减一。 if ((int)str[clen] > 128) { len--; } clen++; } #endregion if (clen < l) { return str.Substring(0, clen) + "..."; } else { return str; } } /// <summary> /// //截取字符串中文 字母 /// </summary> /// <param name="content">源字符串</param> /// <param name="length">截取长度!</param> /// <returns></returns> public static string SubTrueString(object content, int length) { string strContent = NoHTML(content.ToString()); bool isConvert = false; int splitLength = 0; int currLength = 0; int code = 0; int chfrom = Convert.ToInt32("4e00", 16); //范围(0x4e00~0x9fff)转换成int(chfrom~chend) int chend = Convert.ToInt32("9fff", 16); for (int i = 0; i < strContent.Length; i++) { code = Char.ConvertToUtf32(strContent, i); if (code >= chfrom && code <= chend) { currLength += 2; //中文 } else { currLength += 1;//非中文 } splitLength = i + 1; if (currLength >= length) { isConvert = true; break; } } if (isConvert) { return strContent.Substring(0, splitLength); } else { return strContent; } } public static int GetStringLenth(object content) { string strContent = NoHTML(content.ToString()); int currLength = 0; int code = 0; int chfrom = Convert.ToInt32("4e00", 16); //范围(0x4e00~0x9fff)转换成int(chfrom~chend) int chend = Convert.ToInt32("9fff", 16); for (int i = 0; i < strContent.Length; i++) { code = Char.ConvertToUtf32(strContent, i); if (code >= chfrom && code <= chend) { currLength += 2; //中文 } else { currLength += 1;//非中文 } } return currLength; } #endregion
以上便是完整代码,谢谢!
在此,顺便说下数据库按照汉字首字母进行排序的方法:
oracle :
在oracle9i中新增了按照拼音、部首、笔画排序功能。设置NLS_SORT值
SCHINESE_RADICAL_M 按照部首(第一顺序)、笔划(第二顺序)排序
SCHINESE_STROKE_M 按照笔划(第一顺序)、部首(第二顺序)排序
SCHINESE_PINYIN_M 按照拼音排序,系统的默认排序方式为拼音排序
举例如下:
表名为 dept ,其中name字段是中文,下面分别实现按照单位名称的笔划、部首和拼音排序。
//按照笔划排序
select * from dept order by nlssort(name,\'NLS_SORT=SCHINESE_STROKE_M\');
//按照部首排序
select * from dept order by nlssort(name,\'NLS_SORT=SCHINESE_RADICAL_M\');
//按照拼音排序,此为系统的默认排序方式
select * from dept order by nlssort(name,\'NLS_SORT=SCHINESE_PINYIN_M\');
sqlserver
select * from table order by name collate Chinese_PRC_CS_AS_KS_WS
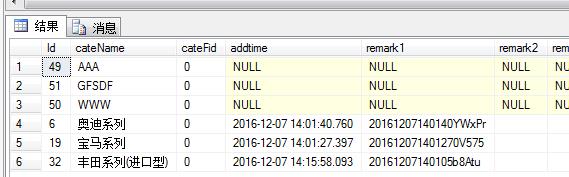
执行结果:select * from Table where cateFid=0 order by cateName collate Chinese_PRC_CS_AS_KS_WS
public static string GetSpellAllCode(string CnStr) { return NPinyin.Pinyin.GetPinyin(CnStr); }
上述代码获取的全拼有空格分隔,如果你不需要空格,可采用:.Replace(" ", "") 把空格替换掉!
但是有个问题需要完善下:
如果上述获取首字母的方法得到的结果中包含‘?’号,这就说明上述方法存在不能翻译的汉字,这时候我们可以将二者相结合,如下:
string szm = PingYinHelper.GetSpellCode(smSupplierModel.SupplierName); if (szm.Contains("?")) { szm = string.Empty; var ary = PingYinHelper.GetSpellAllCode(smSupplierModel.SupplierName).Split(\' \'); foreach (var py in ary) { szm += py.Substring(0, 1); } } string supplierSZM = szm.ToUpper() + "_" + PingYinHelper.GetSpellAllCode(smSupplierModel.SupplierName).Replace(" ", ""); smSupplierEntity.Relatcpyno = supplierSZM;
@陈卧龙的博客
以上是关于在datatable中能把某字段按照首字母拼音顺序排列么?的主要内容,如果未能解决你的问题,请参考以下文章